31 अग॰ 2025·7 मिनट
Expand/contract पैटर्न से बिना-डाउनटाइम स्कीमा बदलाव
Expand/contract पैटर्न से बिना डाउनटाइम के स्कीमा बदलाव सीखें: सुरक्षित रूप से कॉलम जोड़ें, बैचों में बैकफिल करें, कम्पैटिबल कोड डिप्लॉय करें, फिर पुराने रास्तों को हटाएँ।
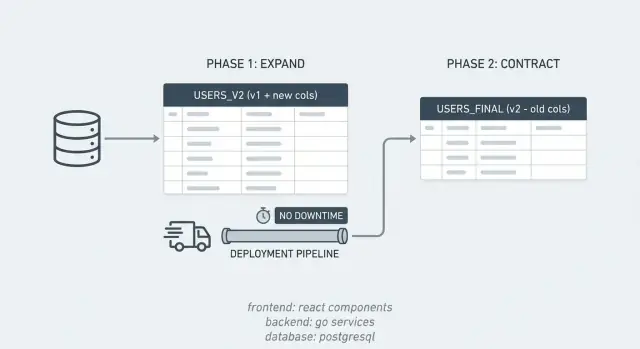
Expand/contract पैटर्न से बिना डाउनटाइम के स्कीमा बदलाव सीखें: सुरक्षित रूप से कॉलम जोड़ें, बैचों में बैकफिल करें, कम्पैटिबल कोड डिप्लॉय करें, फिर पुराने रास्तों को हटाएँ।
डेटाबेस बदलाव से होने वाला डाउनटाइम हमेशा एक साफ़, स्पष्ट आउटेज नहीं होता। उपयोगकर्ताओं के लिए यह ऐसा दिख सकता है जैसे पेज अनंत समय तक लोड हो रहा हो, चेकआउट फेल हो रहा हो, या ऐप अचानक "किसी त्रुटि हुई" दिखा रहा हो। टीम के लिए यह अलर्ट, बढ़ती एरर दरें, और असफल लिखनों का ब्याकलॉग के रूप में सामने आता है जिसे साफ़ करना पड़ता है।
स्कीमा बदलना जोखिम भरा इसलिए होता है क्योंकि डेटाबेस आपकी ऐप के हर चल रहे वर्शन द्वारा साझा होता है। रिलीज़ के दौरान अक्सर पुराने और नए कोड एक साथ चले हुए होते हैं (रोलिंग डिप्लॉय, कई इंस्टेंस, बैकग्राउंड जॉब्स)। एक ऐसा माइग्रेशन जो सही दिखता है, फिर भी उन वर्शन्स में से किसी एक को तोड़ सकता है।
आम विफलता के तरीके शामिल हैं:
यह अतिरिक्त प्रयास तब तक सार्थक है जब आपका ट्रैफिक असली हो, सख्त SLA हो, या बहुत से ऐप इंस्टेंस और वर्कर्स हों। एक छोटे अंदरूनी टूल के लिए जहाँ डेटाबेस शांत है, एक नियोजित मेंटेनेंस विंडो सरल हो सकती है।
डेटाबेस काम से होने वाले ज़्यादातर घटनाक्रम इसलिए होते हैं क्योंकि ऐप डेटाबेस को तुरन्त बदलने की उम्मीद करता है, जबकि डेटाबेस बदलाव में समय लगता है। expand/contract पैटर्न इसे रोकता है क्योंकि यह एक रिस्की बदलाव को छोटे, सुरक्षित स्टेप्स में तोड़ देता है।
एक छोटे समय के लिए आपकी सिस्टम दो "डायलक्ट" का समर्थन करता है। आप पहले नई संरचना जोड़ते हैं, पुरानी काम करती रहती है, डेटा धीरे-धीरे मूव करते हैं, और फिर क्लीनअप करते हैं।
पैटर्न सरल है:
यह रोलिंग डिप्लॉय के साथ अच्छी तरह काम करता है। यदि आप 10 सर्वर एक-एक करके अपडेट करते हैं, तो आप थोड़ी देर के लिए पुराने और नए वर्शन एक साथ चलाएँगे। expand/contract उसी overlap के दौरान दोनों के लिए डेटाबेस को कम्पैटिबल रखता है।
यह रोलबैक को भी कम डरावना बनाता है। अगर नए रिलीज़ में बग है, तो आप ऐप को रोलबैक कर सकते हैं बिना डेटाबेस रोलबैक किए, क्योंकि expand विंडो के दौरान पुरानी संरचनाएँ मौजूद रहती हैं।
उदाहरण: आप PostgreSQL कॉलम full_name को first_name और last_name में विभाजित करना चाहते हैं। आप नए कॉलम जोड़ते हैं (expand), ऐसा कोड भेजते हैं जो दोनों रूपों को पढ़ और लिख सकता है, पुराने rows को बैकफिल करते हैं, और जब आप भरोसा कर लें कि कुछ भी उपयोग नहीं कर रहा, तो full_name हटाते हैं (contract)।
Expand चरण नए विकल्प जोड़ने के बारे में है, पुराना हटाने के बारे में नहीं।
आमतौर पर पहला कदम नया कॉलम जोड़ना होता है। PostgreSQL में इसे सामान्यत: nullable और बिना default के जोड़ना सबसे सुरक्षित होता है। Non-null कॉलम default के साथ जोड़ने पर तालिका rewrite या भारी लॉक हो सकती है, यह आपके Postgres वर्शन और बदलाव पर निर्भर करता है। एक सुरक्षित अनुक्रम है: nullable जोड़ें, सहनशील कोड डिप्लॉय करें, बैकफिल करें, फिर बाद में NOT NULL लागू करें।
इंडेक्सेस को भी सतर्कता चाहिए। सामान्य इंडेक्स बनाना लिखनों को आप जितना सोचते हैं उससे ज़्यादा समय के लिए ब्लॉक कर सकता है। जहाँ संभव हो, concurrent index creation का उपयोग करें ताकि पढ़ाई और लिखाई जारी रहे। यह अधिक समय लेता है, लेकिन रिलीज़ रोकने वाले लॉक से बचाता है।
Expand का मतलब नए टेबल जोड़ना भी हो सकता है। अगर आप एक सिंगल कॉलम से many-to-many रिश्ते पर जा रहे हैं, तो आप एक join table जोड़ सकते हैं जबकि पुराना कॉलम भी बने रह सकता है। पुराना रास्ता काम करता रहता है जबकि नई संरचना डेटा इकट्ठा करना शुरू कर देती है।
व्यवहार में, expand अक्सर शामिल करता है:
Expand के बाद, पुराने और नए ऐप वर्शन बिना आश्चर्य के एक साथ चलने योग्य होने चाहिए।
ज्यादातर रिलीज़ की परेशानी बीच में होती है: कुछ सर्वर नया कोड चला रहे हैं, कुछ अभी भी पुराना, जबकि डेटाबेस पहले ही बदल रहा है। आपका लक्ष्य सीधा है: रोलआउट में किसी भी वर्शन को पुराने और विस्तारित दोनों स्कीमा के साथ काम करना चाहिए।
एक सामान्य तरीका है dual-write। अगर आप नया कॉलम जोड़ते हैं, तो नया ऐप दोनों—पुराने और नए—कॉलम में लिखे। पुराने वर्शन सिर्फ पुराने में लिखना जारी रखते हैं, जो ठीक है क्योंकि वह अभी भी मौजूद है। पहले नए कॉलम को optional रखें, और तब तक सख्त constraints बाद में लागू करें जब आप सुनिश्चित हों कि सभी writers अपग्रेड हो चुके हैं।
पढ़ाई आमतौर पर लिखाई की तुलना में सावधानी से स्विच होती है। कुछ समय के लिए पुराने कॉलम पर पढ़ना रखें (जिसे आप पूरी तरह से populated जानते हैं)। बैकफिल और सत्यापन के बाद, पढ़ाई को नया कॉलम प्राथमिकता देने के लिए बदलें, और अगर नया NULL हो तो fallback पुराने पर करें।
API आउटपुट को भी स्थिर रखें जबकि डेटाबेस के नीचे बदल रहा हो। भले ही आप एक नया internal फ़ील्ड जोड़ें, response shapes तब तक बदलने से बचें जब तक सभी consumers (वेब, मोबाइल, इंटीग्रेशन) तैयार न हों।
एक rollback-friendly रोलआउट अक्सर ऐसे दिखता है:
मूल विचार यह है कि पहला irreversible कदम पुरानी संरचना को हटाना है, इसलिए आप उसे अंत तक टालते हैं।
बैकफिल वही जगह है जहाँ कई "बिना-डाउनटाइम स्कीमा बदलाव" गलत हो जाते हैं। आप चाहते हैं कि नए कॉलम को पुरानी पंक्तियों के लिए भरें बिना लंबे लॉक, धीमी क्वेरीज़, या अचानक लोड स्पाइक्स के।
बॅचिंग मायने रखता है। ऐसे बैच लक्षित करें जो जल्दी खत्म हों (सेकंड्स में, मिनटों में नहीं)। यदि हर बैच छोटा है, तो आप नौकरी को रोक, पुनः आरंभ और ट्यून कर सकते हैं बिना रिलीज़ को ब्लॉक किए।
प्रगति का ट्रैक रखने के लिए एक स्थिर कर्सर का उपयोग करें। PostgreSQL में यह अक्सर प्राथमिक कुंजी होती है। पंक्तियों को क्रम में प्रोसेस करें और आखिरी पूरा किया गया id स्टोर करें, या id रेंजों में काम करें। यह नौकरी को रिस्टार्ट करने पर महंगी फुल-टेबल स्कैन से बचाता है।
यहां एक साधारण पैटर्न है:
UPDATE my_table
SET new_col = ...
WHERE new_col IS NULL
AND id > $last_id
ORDER BY id
LIMIT 1000;
अपडेट को conditional बनाएं (उदाहरण के लिए, WHERE new_col IS NULL) ताकि नौकरी idempotent हो। दोबारा चलाने पर केवल वे पंक्तियाँ टच होंगी जिन्हें अभी भी काम की ज़रूरत है, जो अनावश्यक लिखों को कम करती है।
बैकफिल के दौरान आने वाले नए डेटा की योजना बनाएं। सामान्य क्रम यह है:
एक अच्छा बैकफिल नीरस होता है: स्थिर, मापने योग्य, और अगर डेटाबेस गर्म हो तो आसानी से रोकने योग्य।
सबसे जोखिम भरा क्षण नया कॉलम जोड़ना नहीं है। यह तय करना है कि आप उस पर निर्भर हो सकते हैं।
Contract पर जाने से पहले दो चीज़ें साबित करें: नया डेटा पूरा है, और प्रोडक्शन उसे सुरक्षित रूप से पढ़ रहा है।
तेज़ और दोहराने योग्य completeness चेक से शुरू करें:
यदि आप dual-writing कर रहे हैं, तो छिपे हुए बग पकड़ने के लिए consistency चेक जोड़ें। उदाहरण के लिए, हर घंटे एक क्वेरी चलाएं जो उन पंक्तियों को खोजे जहाँ old_value <> new_value और यदि यह शून्य नहीं है तो अलर्ट करें। यह अक्सर यह खोजने का तेज़ तरीका होता है कि कोई writer अभी भी केवल पुराने कॉलम को अपडेट कर रहा है।
माइग्रेशन के दौरान बुनियादी प्रोडक्शन संकेतों पर नज़र रखें। अगर क्वेरी समय या लॉक वेट्स spike होते हैं, तो आपकी "सुरक्षित" सत्यापन क्वेरीज भी लोड जोड़ सकती हैं। उन कोड पाथ्स के लिए error rates देखिए जो नए कॉलम को पढ़ते हैं, खासकर डिप्लॉय के ठीक बाद।
दोनों रास्ते कितनी देर रखें? कम से कम एक पूरा रिलीज़ सायकल और एक बैकफिल rerun टिकने तक। कई टीमें 1-2 हफ्ते उपयोग करती हैं, या जब तक वे आश्वस्त न हों कि कोई पुराना ऐप वर्शन चल रहा नहीं है।
Contract वह जगह है जहाँ टीमें नर्वस हो जाती हैं क्योंकि यह irreversible महसूस होता है। अगर expand सही तरीके से किया गया था, तो contract ज़्यादातर क्लीनअप है, और आप इसे छोटे, कम-जोखिम स्टेप्स में कर सकते हैं।
क्षण का चयन समझदारी से करें। किसी बैकफिल के ठीक बाद कुछ भी न हटाएँ। कम से कम एक पूरा रिलीज़ सायकल इंतज़ार करें ताकि देरी वाले जॉब्स और किनारे के केस सामने आ सकें।
एक सुरक्षित contract अनुक्रम आम तौर पर ऐसा दिखता है:
यदि संभव हो, contract को दो रिलीज़ में बाँटें: एक जो कोड रेफरेंसेज़ हटाए (अतिरिक्त लॉगिंग के साथ), और बाद में जो डेटाबेस ऑब्जेक्ट्स हटाए। यह अलगाव रोलबैक और ट्रबलशूटिंग को बहुत आसान बनाता है।
PostgreSQL विशिष्टताएँ यहाँ महत्वपूर्ण हैं। कॉलम ड्रॉप करना सामान्यत: metadata परिवर्तन है, पर यह भी थोड़ी ACCESS EXCLUSIVE लॉक ले सकता है। शांत समय की योजना बनाएं और माइग्रेशन को तेज रखें। यदि आपने अतिरिक्त इंडेक्स बनाये थे, तो onları DROP INDEX CONCURRENTLY के साथ हटाने को प्राथमिकता दें ताकि लिखाई ब्लॉक न हो (यह transaction block के अंदर नहीं चल सकता, तो आपका माइग्रेशन टूलिंग इसे सपोर्ट करे)।
बिना-डाउनटाइम माइग्रेशन तब विफल होते हैं जब डेटाबेस और ऐप क्या अनुमति है इस पर सहमत होना बंद कर देते हैं। पैटर्न तभी काम करता है जब हर मध्यवर्ती स्थिति पुराने और नए कोड दोनों के लिए सुरक्षित हो।
ये गलतियाँ अक्सर दिखती हैं:
एक वास्तविक परिदृश्य: आप API से full_name लिखना शुरू कर देते हैं, लेकिन एक बैकग्राउंड जॉब जो यूज़र्स बनाता है वह अभी भी सिर्फ first_name और last_name सेट करता है। वह रात में चला, rows insert किए जिनमें full_name = NULL था, और बाद में कोड यह मानने लगा कि full_name हमेशा मौजूद है।
हर स्टेप को ऐसे समझें मानो वह कई दिनों तक चलेगा:
एक दोहराने योग्य चेकलिस्ट आपको उस कोड को शिप करने से बचाती है जो केवल एक डेटाबेस स्थिति में काम करता है।
डिप्लॉय से पहले पुष्टि करें कि डेटाबेस में पहले ही expanded हिस्से मौजूद हैं (नए कॉलम/टेबल, low-lock तरीके से बनाए गए इंडेक्स)। फिर पुष्टि करें कि ऐप सहनशील है: यह पुराने आकार, विस्तारित आकार, और आधा-बैकफिल्ड स्थिति के साथ काम करे।
चेकलिस्ट को छोटा रखें:
एक माइग्रेशन तभी पूरी मानी जाती है जब पढ़ाई नए डेटा का उपयोग करती है, लिखाई पुराना डेटा बनाए रखना बंद कर देती है, और आपने बैकफिल कम से कम एक सरल चेक (काउंट या सैम्पलिंग) से सत्यापित कर लिया है।
मान लें आपके पास PostgreSQL तालिका customers है जिसमें कॉलम phone है जो गंदा डेटा रखता है (विभिन्न फॉर्मैट, कभी-कभी खाली)। आप इसे phone_e164 से बदलना चाहते हैं, पर आप रिलीज़ ब्लॉक नहीं कर सकते या ऐप बंद नहीं कर सकते।
एक साफ़ expand/contract अनुक्रम ऐसा दिखेगा:
phone_e164 को nullable और बिना default के जोड़ें, और अभी कड़े constraints न लगाएँ।phone और phone_e164 में लिखा जाए, पर पढ़ाई phone पर ही रहे ताकि उपयोगकर्ताओं के लिए कुछ न बदले।phone_e164 पढ़े, और अगर वह NULL हो तो phone पर fallback करे।phone_e164 इस्तेमाल कर रहा है, तो fallback हटाएँ, phone ड्रॉप करें, और यदि ज़रूरत हो तो कड़े constraints फिर लगाएँ।यदि हर स्टेप backward compatible हो तो रोलबैक सरल रहता है। अगर read switch समस्या करता है तो ऐप रोलबैक करें और डेटाबेस में दोनों कॉलम मौजूद हैं। अगर बैकफिल लोड स्पाइक्स करता है तो नौकरी रोकें, बैच साइज घटाएँ, और बाद में जारी रखें।
टीम को संरेखित रखने के लिए योजना को एक जगह दस्तावेज़ करें: सटीक SQL, कौन-सा रिलीज़ पढ़ाई फ़्लिप करता है, पूर्णता कैसे मापेंगे (जैसे percent non-NULL phone_e164), और कौन हर स्टेप का मालिक है।
Expand/contract तब सबसे अच्छा काम करता है जब यह नियमित लगे। अपनी टीम के लिए एक छोटा रनबुक लिखें जिसे आप हर स्कीमा बदलाव के लिए फिर से उपयोग कर सकें — एक पृष्ठ और इतना विशिष्ट कि कोई नया सदस्य इसे फॉलो कर सके।
एक व्यावहारिक टेम्पलेट में शामिल करें:
पहले से ownership तय करें। “सबने सोचा कोई और करेगा” ही वह कारण है जिससे पुराने कॉलम और feature flags महीनों तक रहते हैं।
भले ही बैकफिल ऑनलाइन चले, इसे तब शेड्यूल करें जब ट्रैफिक कम हो। बैच छोटे रखने, DB लोड देखने, और latency बढ़ने पर जल्दी रोकने में यह आसान होता है।
यदि आप Koder.ai (koder.ai) के साथ बना और डिप्लॉय कर रहे हैं, तो Planning Mode माइग्रेशन से पहले चरणों और चेकपॉइंट्स को मैप करने का उपयोगी तरीका हो सकता है। वही compatibility नियम लागू होते हैं, पर चरणों को लिखित में रखने से वो बोरिंग हिस्से छूटना मुश्किल हो जाता है जो आउटेज से बचाते हैं।
क्योंकि आपका डेटाबेस आपकी ऐप के हर चल रहे वर्शन द्वारा साझा होता है। रोलिंग डिप्लॉय और बैकग्राउंड जॉब्स के दौरान पुराने और नए कोड एक साथ रन कर सकते हैं, और जो माइग्रेशन नाम बदलता है, कॉलम ड्रॉप करता है, या constraints जोड़ता है वह उसी सटीक स्कीमा स्थिति के लिए न लिखे गए किसी वर्शन को तोड़ सकता है।
इसका मतलब है कि आप माइग्रेशन इस तरह डिज़ाइन करें कि हर मध्यवर्ती डेटाबेस स्थिति पुराने और नए कोड दोनों के लिए काम करे। आप पहले नई संरचनाएँ जोड़ते हैं, कुछ समय दोनों रास्ते चलाते हैं, फिर पुराने रास्तों को तभी हटाते हैं जब कुछ भी उन पर निर्भर न हो।
Expand नए कॉलम, टेबल या इंडेक्स जोड़ने का चरण है बिना कुछ भी हटाए जो वर्तमान ऐप को चाहिए। Contract क्लीनअप चरण है जहाँ आप पुराने कॉलम, पुराने रीड/राइट और अस्थायी सिंक लॉजिक हटाते हैं जब नए रास्ते पूरी तरह से काम कर रहे हों।
आमतौर पर सबसे सुरक्षित शुरुआत यह है कि नया कॉलम nullable और बिना default के जोड़ा जाए, क्योंकि इससे भारी लॉक से बचा जा सकता है और पुराना कोड काम करता रहता है। फिर आप ऐसा कोड डिप्लॉय करें जो उस कॉलम के गायब या NULL होने को संभाले, धीरे-धीरे बैकफिल करें, और तभी constraints जैसे NOT NULL लागू करें जब आप सुनिश्चित हों।
यह तब उपयोगी होता है जब ट्रांज़िशन के दौरान नया ऐप वर्शन दोनों—पुराने और नए—फील्ड में लिखता है। इससे डेटा संगत रहता है जबकि आपके पास पुराने ऐप इंस्टेंस और जॉब्स भी चल रहे होते हैं जो केवल पुराने फील्ड को जानते हैं।
छोटे बैचों में बैकफिल करें ताकि हर बैच जल्दी खत्म हो (सेकंड में, मिनटों में नहीं)। हर बैच idempotent रखें ताकि दोबारा चलाने पर केवल जिन पंक्तियों को अभी भी काम की ज़रूरत है ही अपडेट हों। क्वेरी समय, लॉक वेट्स और replication lag पर नजर रखें और अगर डेटाबेस गर्म हो तो नौकरी रोकने या बैच साइज घटाने के लिए तैयार रहें।
सबसे पहले completeness चेक करें — कितना NULL बचा है। फिर old और new वैल्यू की तुलना से consistency चेक करें (नमूना या लगातार, यदि आसान हो)। और डिप्लॉय्स के ठीक बाद प्रोडक्शन एरर्स़ पर नजर रखें ताकि कोई कोड पाथ गलत स्कीमा उपयोग कर रहा हो तो पकड़ा जा सके।
NOT NULL या नए constraints जल्दी लागू कर देना जबकि पुराने वर्शन अभी भी NULL लिख सकते हैं, बहुत बड़ी टेबल को एक ट्रांज़ैक्शन में बैकफिल करना, और बिना सोचे समझे defaults मान लेना (क्योंकि कुछ defaults table rewrite ट्रिगर कर सकते हैं) आम गल्तियाँ हैं। इंडेक्स बनाते समय भी लॉकिंग का ध्यान रखें।
जब आप पुराने फील्ड में लिखना बंद कर दें, पढ़ाई (reads) को नए फील्ड पर स्विच कर लें बिना fallback के, और यकीन कर लें कि कोई पुराना ऐप वर्शन या वर्कर बाकी नहीं जो अब भी पुराने रास्ते को इस्तेमाल कर रहा हो। कई टीमें इसे अलग रिलीज़ के रूप में करती हैं ताकि रोलबैक सरल रहे।
यदि आप एक मेंटेनेंस विंडो बर्दाश्त कर सकते हैं और ट्रैफिक बहुत कम है तो एक साधारण वेन-शॉट माइग्रेशन ठीक हो सकता है। लेकिन अगर असली उपयोगकर्ता, कई ऐप इंस्टेंस, बैकग्राउंड वर्कर्स या SLA है, तो expand/contract सामान्यतः बेहतर होता है क्योंकि यह रोलआउट और रोलबैक को सुरक्षित रखता है; Koder.ai Planning Mode में पहले से चरण और चेक लिख लेने से अक्सर वे “बोरिंग” कदम नहीं छूटते जो आउटेज रोकते हैं।