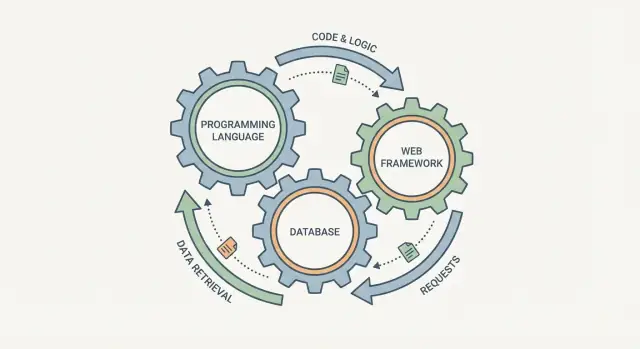
ये अलग विकल्प क्यों नहीं हैं
यह लुभावना है कि आप प्रोग्रामिंग भाषा, डेटाबेस, और वेब फ्रेमवर्क को तीन स्वतंत्र चेकबॉक्स की तरह चुन लें। असलियत में वे ज़्यादा कनेक्टेड गियर्स की तरह व्यवहार करते हैं: एक को बदलो, और बाकी को उसका असर मिलता है।
एक वेब फ्रेमवर्क यह तय करता है कि रिक्वेस्ट कैसे हैंडल होती है, डेटा कैसे वैलिडेट होता है, और एरर्स कैसे surfaced होते हैं। डेटाबेस यह तय करता है कि "असान स्टोर करने" जैसा क्या दिखता है, आप जानकारी कैसे क्वेरी करते हैं, और एक साथ कई यूज़र्स के अक्शन्स पर कौन से गारन्टीज़ मिलती हैं। भाषा बीच में बैठती है: यह बताती है कि आप नियम कितनी सुरक्षित तरह से व्यक्त कर सकते हैं, concurrency कैसे मैनेज करते हैं, और किन लाइब्रेरीज़ व टूलिंग पर भरोसा कर सकते हैं।
“एक प्रणाली” का क्या मतलब है
स्टैक को एकल प्रणाली की तरह ट्रीट करने का मतलब है कि आप हर हिस्से को अलग-थलग ऑप्टिमाइज़ न करें। आप एक ऐसा कॉम्बिनेशन चुनते हैं जो:
- आपके डेटा को नेचुरली प्रतिनिधित्व करे (ताकि आप बार-बार कनवर्ज़न से न लड़ें)
- आपकी consistency ज़रूरतों का समर्थन करे (ताकि बग एज-केस में छिप न जाएँ)
- आपकी टीम के वर्कफ़्लो में फिट हो (ताकि शिपिंग और मेंटेनेंस प्रेडिक्टेबल रहे)
यह लेख व्यावहारिक और जानबूझकर कम-टेक्निकल है। आपको डेटाबेस थ्योरी या भाषा के इंटर्नल्स याद रखने की ज़रूरत नहीं—सिर्फ़ देखें कि विकल्प पूरे एप्लिकेशन पर कैसे लहराते हैं।
एक तेज़ उदाहरण: उच्च-संरचित, रिपोर्ट-हेवी बिज़नेस डेटा के लिए schema-less डेटाबेस का उपयोग अक्सर एप्लिकेशन कोड में बिखरे नियम और बाद में भ्रमित एनालिटिक्स पैदा करता है। बेहतर फिट है उसी डोमेन को एक रिलेशनल डेटाबेस और एक ऐसे फ्रेमवर्क के साथ जोड़ना जो कॉन्सिस्टेंट वैलिडेशन और माइग्रेशन्स को प्रोत्साहित करे, ताकि आपका डेटा प्रोडक्ट के विकास के साथ coherent रहे।
जब आप स्टैक को साथ में योजना बनाते हैं, तो आप तीन अलग दांव नहीं बल्कि ट्रेडऑफ़ का एक सेट डिज़ाइन कर रहे होते हैं।
एक सरल मानसिक मॉडल: रिक्वेस्ट इन, डेटा आउट
स्टैक को समझने का मददगार तरीका है इसे एक पाइपलाइन के रूप में देखना: एक यूज़र रिक्वेस्ट आपके सिस्टम में आती है, और एक रिस्पॉन्स (प्लस सेव्ड डेटा) बाहर आता है। प्रोग्रामिंग भाषा, वेब फ्रेमवर्क, और डेटाबेस स्वतंत्र चुनाव नहीं हैं—वे उसी यात्रा के तीन हिस्से हैं।
एक रिक्वेस्ट की यात्रा
एक ग्राहक अपने शिपिंग पते को अपडेट करता है, कल्पना करें।
- Request in: फ्रेमवर्क एक HTTP रिक्वेस्ट प्राप्त करता है। Routing तय करता है कौन सा हैंडलर चलेगा (उदा.,
/account/address)। Validation जांचती है कि इनपुट पूरा और ठीक है।
- Work happens: आपका एप्लिकेशन कोड (आपकी चुनी हुई भाषा में लिखा) बिज़नेस नियम चलाता है: “क्या यूज़र लॉग इन है?”, “क्या यह पता फॉर्मैट स्वीकृत है?”, “क्या हमें इस ऑर्डर को री-चेक के लिए मार्क करना चाहिए?”
- Data out: डेटाबेस लेयर रिकॉर्ड्स पढ़ता/लिखता है—अक्सर एक ट्रांज़ैक्शन के भीतर—तो अपडेट या तो पूरी तरह लागू होता है या बिलकुल नहीं होता।
- Response out: फ्रेमवर्क परिणाम (HTML/JSON) फ़ॉर्मैट करता है, स्टेटस कोड सेट करता है, और उसे यूज़र को रिटर्न करता है।
- Afterwards: बैकग्राउंड जॉब्स चल सकते हैं (कन्फर्मेशन ईमेल भेजना, सर्च इंडेक्स अपडेट करना, वेयरहाउस को नोटिफाई करना)।
वास्तव में हर चुनाव किसके लिए ज़िम्मेदार है
- भाषा: कोड कैसे चलता है (runtime/concurrency model), टेस्ट और डिबग कितना आसान है, और क्या आपकी टीम की स्किल्स और टूलिंग बदलावों को सुरक्षित और तेज़ बनाती हैं।
- फ्रेमवर्क: रिक्वेस्ट के लिए “ट्रैफ़िक कंट्रोल”—routing, validation, authentication hooks, error handling, और बैकग्राउंड जॉब्स के लिए बिल्ट-इन पैटर्न।
- डेटाबेस: डेटा कैसे स्टोर और क्वेरी होता है, कौन से constraints खराब डेटा को रोकते हैं, और ट्रांज़ैक्शन्स संबंधित अपडेट्स को कैसे कॉन्सिस्टेंट रखते हैं।
जब ये तीनों मेल खाते हैं, एक रिक्वेस्ट साफ़-सुथरे तरीके से फ्लो करती है। जब वे मेल नहीं खाते, तो आपको friction मिलता है: अजीब डेटा एक्सेस, लीक होने वाली वैलिडेशन, और सूक्ष्म consistency बग्स।
डेटा मॉडल पहले: स्टैक फिट का छुपा ड्राइवर
अधिकांश स्टैक बहसें भाषा या डेटाबेस ब्रांड से शुरू होती हैं। बेहतर शुरुआत आपकी डेटा मॉडल से होनी चाहिए—क्योंकि वही चुपचाप तय करती है कि क्या नेचुरल (या दर्दनाक) लगेगा: वैलिडेशन, क्वेरीज, APIs, माइग्रेशन्स, और यहां तक कि टीम वर्कफ़्लो।
डेटा के आकार: ऑब्जेक्ट्स, रोज़, डॉक्यूमेंट्स, इवेंट्स
एप्लिकेशन आमतौर पर एक साथ चार शेप्स संभालते हैं:
- कोड में Objects (क्लासेस, structs, typed records)
- रिलेशनल टेबल में Rows
- JSON-स्टाइल स्टोरेज या APIs में Documents
- लॉग्स/स्ट्रीम्स में Events ("OrderPlaced", "EmailSent")
अच्छा फिट वह है जब आप अपने दिन का बड़ा हिस्सा शेप्स के बीच translate करने में न बिताएँ। यदि आपका कोर डेटा बहुत जुड़ा हुआ है (users ↔ orders ↔ products), तो rows और joins लॉजिक को सरल रख सकते हैं। यदि आपका डेटा ज्यादातर "हर एंटिटी एक ब्लॉब" है जिसमें वैरिएबल फील्ड्स हैं, तो documents समारोह कम कर सकते हैं—जब तक कि आपको क्रॉस-एंटिटी रिपोर्टिंग की ज़रूरत न पड़े।
स्कीमा बनाम लचीला स्ट्रक्चर (और नियम कहाँ रहते हैं)
जब डेटाबेस में मजबूत स्कीमा होता है, तो कई नियम डेटा के पास रह सकते हैं: टाइप्स, constraints, foreign keys, uniqueness। इससे अक्सर सर्विस्स के बीच duplicated checks कम होते हैं।
लचीले स्ट्रक्चर के साथ, नियम ऊपर एप्लिकेशन की ओर शिफ्ट होते हैं: वैलिडेशन कोड, versioned payloads, backfills, और सावधान रीड लॉजिक ("यदि फील्ड मौजूद है, तब…")। यह तब अच्छा काम कर सकता है जब प्रोडक्ट आवश्यकताएँ साप्ताहिक रूप से बदलती हों, पर यह आपके फ्रेमवर्क और टेस्टिंग पर बोझ बढ़ाता है।
मॉडलिंग विकल्प कोड कॉम्प्लेक्सिटी को कैसे प्रभावित करते हैं
आपका मॉडल तय करता है कि आपका कोड ज्यादातर क्या करता है:
- Querying और joining (relational-heavy)
- Nested JSON को transform करना (document-heavy)
- Events को replay और aggregate करना (event-heavy)
यह बदले में भाषा और फ्रेमवर्क की जरूरतों को प्रभावित करता है: मजबूत टाइपिंग JSON फील्ड्स में subtle drift रोक सकती है, जबकि परिपक्व migration tooling उन मामलों में ज़्यादा मायने रखती है जब स्कीमा बार-बार बदलते हैं।
उदाहरण: user profile, orders, audit log
- User profile: अक्सर document-like (preferences, optional fields) होता है लेकिन identity और uniqueness के लिए relational constraints से फ़ायदा होता है।
- Orders: आमतौर पर relational (line items, totals, statuses) क्योंकि consistency और रिपोर्टिंग मायने रखती है।
- Audit log: नेचुरली event-shaped—append-only एंट्रीज़ जिन्हें आप ज़्यादातर अपडेट नहीं करते, समय, actor, या entity के हिसाब से क्वेरी करने के लिए ऑप्टिमाइज़्ड।
पहले मॉडल चुनें; “सही” फ्रेमवर्क और डेटाबेस विकल्प अक्सर उसके बाद स्पष्ट हो जाते हैं।
ट्रांज़ैक्शन्स और कंसिस्टेंसी: वहीं जहाँ बग अक्सर शुरू होते हैं
ट्रांज़ैक्शन्स वे "सब-या-कुछ नहीं" गारन्टीज़ हैं जिन पर आपका ऐप चुपचाप निर्भर करता है। जब एक चेकआउट सफल होता है, तो आप उम्मीद करते हैं कि order रिकॉर्ड, payment status, और inventory update या तो सभी हो जाएँ—या कोई नहीं। इस वादा के बिना आपको सबसे कठिन तरह के बग मिलते हैं: दुर्लभ, महंगे, और पुनरुत्पादन में कठिन।
ट्रांज़ैक्शन्स वास्तव में क्या करते हैं
एक ट्रांज़ैक्शन कई database ऑपरेशन्स को एक ही यूनिट में जोड़ता है। यदि बीच में कुछ फेल हो जाता है (वैलिडेशन एरर, टाइमआउट, क्रैश प्रोसेस), तो डेटाबेस पिछले सुरक्षित स्टेट पर रोल बैक कर सकता है।
यह पैसे के फ्लो से परे मायने रखता है: account creation (user row + profile row), कंटेंट पब्लिश करना (post + tags + search index pointers), या कोई भी वर्कफ़्लो जो एक से ज्यादा तालिकाओं को छूता है।
कंसिस्टेंसी बनाम स्पीड (साधे शब्दों में)
कंसिस्टेंसी का मतलब है "रीड्स असली राज्य से मेल खाते हैं"। स्पीड का मतलब है "कुछ जल्दी लौटाएँ"। कई सिस्टम यहाँ tradeoffs करते हैं:
- मजबूत कंसिस्टेंसी: यूज़र्स नवीनतम committed डेटा देखते हैं, कम आश्चर्य, अक्सर अधिक coordination लागत।
- eventual consistency: अपडेट समय के साथ फैलते हैं, आमतौर पर तेज़ और स्केल करने में आसान, पर आपके ऐप को अस्थायी mismatch संभालना होगा।
आम विफलता पैटर्न है एक eventually consistent सेटअप चुनना, फिर उसे ऐसे कोड करना जैसे वह strongly consistent हो।
फ्रेमवर्क और ORMs परिणामों को कैसे प्रभावित करते हैं
फ्रेमवर्क और ORMs अपने आप ट्रांज़ैक्शन्स नहीं बनाते बस इसलिए कि आपने कई “save” मेथड्स कॉल किए। कुछ explicit transaction blocks मांगते हैं; दूसरे प्रति रिक्वेस्ट ट्रांज़ैक्शन शुरू कर सकते हैं, जो प्रदर्शन मुद्दों को छुपा सकता है।
Retries भी जटिल हैं: ORMs deadlocks या अस्थायी फेलियर्स पर retry कर सकते हैं, पर आपका कोड दो बार चलाने के लिए सुरक्षित होना चाहिए।
सामान्य pitfalls
जब आप A अपडेट करते हैं और B अपडेट करने से पहले फेल हो जाते हैं तो partial writes होते हैं। duplicate actions तब होते हैं जब रिक्वेस्ट टाइमआउट के बाद retry किया जाता है—खासकर यदि आपने कार्ड चार्ज कर दिया या ईमेल भेज दिया हो इससे पहले कि ट्रांज़ैक्शन commit हुआ।
सरल नियम मदद करता है: साइड-इफेक्ट्स (ईमेल, वेबहुक) को डेटाबेस commit के बाद करें, और unique constraints या idempotency keys का उपयोग करके ऑपरेशन्स को idempotent बनाएं।
डेटाबेस एक्सेस लेयर: ORM, क्वेरीज, और माइग्रेशन्स
यह आपकी एप्लिकेशन कोड और डेटाबेस के बीच का “अनुवाद लेयर” है। यहाँ के विकल्प रोज़मर्रा के काम में अक्सर डेटाबेस ब्रांड से ज़्यादा मायने रखते हैं।
ORM बनाम query builder बनाम raw SQL (सरल शब्दों में)
एक ORM (Object-Relational Mapper) आपको टेबल्स को ऑब्जेक्ट्स की तरह ट्रीट करने देता है: User बनाएं, Post अपडेट करें, और ORM बैकग्राउंड में SQL जनरेट करता है। यह उत्पादक हो सकता है क्योंकि यह सामान्य कार्यों को स्टैण्डर्डाइज़ करता है और repetitive plumbing छिपाता है।
एक query builder ज़्यादा explicit है: आप कोड का उपयोग करके SQL-जैसा क्वेरी बनाते हैं (chains या functions)। आप फिर भी "joins, filters, groups" में सोचते हैं, पर आपको parameter safety और composability मिलती है।
Raw SQL वास्तव में SQL खुद लिखना है। जटिल रिपोर्टिंग क्वेरीज के लिए यह सबसे डायरेक्ट और अक्सर सबसे स्पष्ट होता है—बदले में अधिक मैनुअल काम और कन्वेंशंस की ज़रूरत होती है।
भाषा की सुविधाएँ एक्सेस पैटर्न को कैसे आकार देती हैं
मजबूत टाइपिंग वाली भाषाएँ (TypeScript, Kotlin, Rust) आपको टूल्स की ओर धकेलती हैं जो क्वेरीज और रिज़ल्ट शेप्स को पहले validate कर सकें। इससे रनटाइम सरप्राइज़ कम होती हैं, पर यह टीमों पर दबाव डालता है कि वे डेटा एक्सेस को सेंट्रलाइज़ रखें ताकि टाइप्स ड्रिफ्ट न हों।
मेटाप्रोग्रामिंग में लचीली भाषाएँ (Ruby, Python) अक्सर ORMs को नेचुरल और फास्टर इटरेट करने वाला बनाती हैं—जब तककि छिपी हुई क्वेरीज या इम्प्लिसिट व्यवहार समझने में कठिन न हो जाएँ।
माइग्रेशन्स: कोड और स्कीमा को सिंक में रखना
माइग्रेशन्स आपके स्कीमा के वर्शन-आधारित चेंज स्क्रिप्ट हैं: कॉलम जोड़ें, इंडेक्स बनाएं, डेटा बैकफिल करें। लक्ष्य सरल है: कोई भी ऐप डिप्लॉय कर सके और उसी डेटाबेस संरचना को पाए। माइग्रेशन्स को ऐसे ट्रीट करें जैसे कोड—review, टेस्ट, और rollback के साथ।
जब "आसान" एब्स्ट्रैक्शन्स नुकसान पहुंचाती हैं
ORMs चुपचाप N+1 क्वेरीज जनरेट कर सकते हैं, बड़ी rows फेच कर सकते हैं जिन्हें आप नहीं चाहिए, या joins को अजीब बना देते हैं। Query builders unreadable "chains" बन सकते हैं। Raw SQL duplicative और inconsistent हो सकता है।
एक अच्छा नियम: सबसे साधारण टूल का उपयोग करें जो इरादा स्पष्ट रखे—और critical path के लिए जो असल में रन हो रहा SQL है उसे जरूर inspect करें।
प्रदर्शन एक सिस्टम प्रॉपर्टी है, न कि सिर्फ़ डेटाबेस की
पहले दिन से मोबाइल शामिल करें
बैकएंड के साथ-साथ Flutter में मोबाइल वर्कफ़्लो का प्रोटोटाइप बनाएं ताकि डेटा शेप्स मैच रहें।
लोग अक्सर "डेटाबेस" को दोष देते हैं जब कोई पेज धीमा लगता है। पर अधिकांश यूज़र-देखने योग्य लेटेंसी पूरे रिक्वेस्ट पाथ के कई छोटे इंतज़ारों का योग होती है।
लेटेंसी वास्तव में कहाँ से आती है
एक सिंगल रिक्वेस्ट आमतौर पर इन इंतज़ारों का भुगतान करती है:
- नेटवर्क समय (क्लाइंट → लोड बैलेंसर → ऐप → डेटाबेस और वापस)
- क्वेरी समय (slow SQL, missing indexes, बहुत सारे round trips)
- Serialization/deserialization (JSON encoding, ORM object mapping, compression)
- ऐप लॉजिक (validation, permissions, टेम्पलेट रेंडरिंग, बाहरी API कॉल्स)
भले ही आपका डेटाबेस 5 ms में जवाब दे, एक ऐप जो प्रति रिक्वेस्ट 20 क्वेरीज बनाता है, I/O पर ब्लॉक होता है, और एक बड़ा रिस्पॉन्स सीरियलाइज़ करने में 30 ms खर्च करता है, तब भी यह सुस्त महसूस होगा।
कनेक्शन पूलिंग: शांत परफ़ॉर्मेंस गुणक
नई डेटाबेस कनेक्शन खोलना महँगा होता है और लोड के समय डेटाबेस को भारी कर सकता है। एक कनेक्शन पूल मौजूदा कनेक्शन्स को पुन: उपयोग करता है ताकि रिक्वेस्ट बार-बार उस सेटअप लागत का भुगतान न करें।
कबो-कच्चा: “सही” पूल साइज आपके runtime मॉडल पर निर्भर करता है। अत्यधिक concurrent async सर्वर बड़ी simultaneous मांग कर सकता है; बिना पूल लिमिट के आप queueing, timeouts, और noisy failures पाएंगे। बहुत कड़ी पूल लिमिट के साथ आपका ऐप ही बॉटलनेक बन सकता है।
कैशिंग: यह क्या ठीक करती है—और क्या नहीं
कैशिंग ब्राउज़र में, CDN पर, इन-प्रोसेस कैश में, या साझा कैश (जैसे Redis) में हो सकती है। यह तब मदद करती है जब कई रिक्वेस्टों को एक ही परिणाम चाहिए।
पर कैशिंग इन चीज़ों को ठीक नहीं करेगी:
- गैर-प्रभावी write paths
- बेहद पर्सनलाइज़्ड रिस्पॉन्सेज
- बाहरी API कॉल्स पर डॉमिनेटेड slow endpoints
रनटाइम मायने रखता है: थ्रेड्स बनाम async
आपकी प्रोग्रामिंग भाषा रनटाइम थ्रूपुट को आकार देती है। थ्रेड-पर-रिक्वेस्ट मॉडल I/O पर इंतज़ार करते समय संसाधन नष्ट कर सकता है; async मॉडल concurrency बढ़ा सकता है, पर यह backpressure (जैसे पूल लिमिट) को भी आवश्यक बनाता है। इसलिए परफ़ॉर्मेंस ट्यूनिंग एक स्टैक निर्णय है, न कि केवल डेटाबेस निर्णय।
सुरक्षा और विश्वसनीयता: स्टैक भर में साझा जिम्मेदारी
सिक्योरिटी कोई ऐसा चीज़ नहीं है जिसे आप सिर्फ़ फ्रेमवर्क प्लगइन या डेटाबेस सेटिंग से "जोड़ दें"। यह आपकी भाषा/runtime, वेब फ्रेमवर्क, और डेटाबेस के बीच एक समझौता है कि क्या चीज़ें हमेशा सच्ची रहेंगी—यहां तक कि तब भी जब कोई डेवेलपर गलती करे या नया एंडपॉइंट जोड़ा जाए।
ऑथेंटिकेशन बनाम ऑथराइजेशन: अलग लेयर्स, वही न्यूज़
Authentication (यह कौन है?) आमतौर पर फ्रेमवर्क के एज पर रहती है: sessions, JWTs, OAuth callbacks, middleware। Authorization (यह क्या करने की अनुमति है?) को दोनों ऐप लॉजिक और डेटा नियमों में सुसंगत रूप से लागू करना चाहिए।
एक सामान्य पैटर्न: ऐप इरादा तय करता है ("यूज़र इस प्रोजेक्ट को एडिट कर सकता है"), और डेटाबेस सीमाएँ लागू करता है (tenant IDs, ownership constraints, और जहाँ उचित हो row-level policies)। अगर authorization सिर्फ controllers में है, तो बैकग्राउंड जॉब्स और इंटरनल स्क्रिप्ट्स इसे आसानी से बायपास कर सकते हैं।
वैलिडेशन: फ्रेमवर्क, डेटाबेस, या दोनों?
फ्रेमवर्क वैलिडेशन तेज़ फीडबैक और अच्छे एरर मेसेज देती है। डेटाबेस constraints अंतिम सुरक्षा जाल प्रदान करते हैं।
महत्त्व की बात यह है कि दोनों का उपयोग करें:
- फ्रेमवर्क: required fields, formatting, दोस्ताना संदेश
- डेटाबेस: uniqueness, foreign keys,
CHECK constraints, NOT NULL
यह उन "असंभव राज्यों" को कम करता है जो तब प्रकट होते हैं जब दो रिक्वेस्ट रेस कर रहे हों या एक नया सर्विस डेटा अलग तरह से लिख रहा हो।
सीक्रेट्स, एन्क्रिप्शन, और ऑडिटिंग
सीक्रेट्स रनटाइम और deployment वर्कफ़्लो (env vars, secret managers) द्वारा हैंडल किए जाने चाहिए, कोड या माइग्रेशन्स में हार्डकोड नहीं। एन्क्रिप्शन ऐप में (field-level encryption) और/या डेटाबेस में (at-rest encryption, managed KMS) हो सकता है, पर यह स्पष्ट होना चाहिए कि कौन कुंजी रोटेट करता है और रिकवरी कैसे होगी।
ऑडिटिंग भी साझा है: ऐप को अर्थपूर्ण इवेंट्स emitir करने चाहिए; डेटाबेस को जहाँ उपयुक्त हो immutable logs रखना चाहिए (उदा., append-only audit tables, restricted access)।
सामान्य फ़ेल्योर मोड
ऐप लॉजिक पर ज़्यादा भरोसा करना क्लासिक है: गायब constraints, साइलेंट nulls, बिना checks के "admin" फ्लैग्स। समाधान सरल है: मान लें कि बग होंगे, और स्टैक को इस तरह डिज़ाइन करें कि डेटाबेस unsafe लिखावटें—even अपने ही कोड से—थुकरा सके।
स्केलिंग पाथ्स: प्रत्येक चुनाव क्या खोलता या बंद करता है
पूरी पाइपलाइन की योजना बनाएं
कोड से पहले रिक्वेस्ट, टेबल और नियम मैप करें ताकि आपका फ्रेमवर्क और डेटाबेस मेल खाएं।
स्केलिंग शायद ही इसलिए फेल होती है कि “डेटाबेस संभाल नहीं सकता।” यह इसलिए फेल होती है कि पूरा स्टैक लोड के रूप बदलने पर बुरी तरह प्रतिक्रिया देता है: एक एंडपॉइंट लोकप्रिय हो जाता है, एक क्वेरी हॉट हो जाती है, एक वर्कफ़्लो retry करना शुरू कर देता है।
जब ट्रैफ़िक बढ़ता है तो दर्द कहां दिखता है
अधिकांश टीम्स को वही शुरुआती बॉटलनेक्स मिलते हैं:
- Hot queries: एक "top page" या डैशबोर्ड क्वेरी लगातार चलती रहती है और CPU/IO पर हावी रहती है।
- Lock contention: अपडेट कुछ ही rows के पीछे पिघलते हैं (inventory counters, "last_seen", queue tables), सब कुछ धीमा पड़ जाता है।
- Connection pressure: ऐप workers बहुत सारी DB कनेक्शन्स खोलते हैं; डेटाबेस session मैनेज करने में समय खर्च करता है बजाय काम करने के।
आप कितनी तेज़ी से प्रतिक्रिया कर सकते हैं यह इस पर निर्भर करता है कि आपका फ्रेमवर्क और डेटाबेस टूलिंग क्वेरी प्लान्स, माइग्रेशन्स, कनेक्शन पूलिंग, और सुरक्षित कैशिंग पैटर्न को कितना खुलकर एक्सपोज़ करते हैं।
रीड रिप्लिकाज़, शार्डिंग, और क्यूज़: कब आते हैं
सामान्य स्केलिंग मूव्स आमतौर पर इस क्रम में आते हैं:
- Read replicas जब रीड्स writes से ज़्यादा हों और आप हल्का stale डेटा बर्दाश्त कर सकते हैं। आपका ORM/फ्रेमवर्क read/write splitting सपोर्ट करें या क्वेरी रूटिंग आसान हो।
- Queues/background jobs जब "अब ही करो" वर्क रिक्वेस्ट लेटेंसी को प्रभावित करने लगे (ईमेल्स, एक्सपोर्ट्स, बिलिंग कॉल्स)। यहाँ retries और deduplication असली जरूरत बन जाती है।
- Sharding/partitioning जब एक प्राइमरी write थ्रूपुट या स्टोरेज ग्रोथ सहन न कर सके। यह ध्यानपूर्ण डेटा मॉडलिंग मांगता है: shard keys, cross-shard queries, और ट्रांज़ैक्शन सीमाएँ।
बैकग्राउंड वर्क और idempotency फ्रेमवर्क फीचर्स हैं, बाद की बात नहीं
एक स्केलेबल स्टैक को बैकग्राउंड टास्क, शेड्यूलिंग, और सेफ retries के लिए first-class सपोर्ट चाहिए।
यदि आपका जॉब सिस्टम idempotency लागू नहीं कर सकता (एक ही जॉब दो बार चलने पर double-charging या double-sending न हो), तो आप "स्केल" करते हुए डेटा करप्शन की ओर बढ़ेंगे। शुरुआती चुनाव—जैसे इम्प्लिसिट ट्रांज़ैक्शन्स पर निर्भर रहना, कमजोर यूनिकनेस constraints, या opaque ORM व्यवहार—आउटबॉक्स पैटर्न्स या एक्सैक्टली-वन-इश वर्कफ़्लो के साफ़ परिचय में बाधा बन सकते हैं।
पहले संरेखण का लाभ मिलता है: ऐसा डेटाबेस चुनें जो आपकी कंसिस्टेंसी ज़रूरतों से मेल खाता हो, और ऐसा फ्रेमवर्क इकोसिस्टम चुनें जो अगला स्केलिंग कदम (replicas, queues, partitioning) को एक समर्थित पाथ बनाता हो न कि री-राइट।
डेवलपर अनुभव और ऑपरेशन्स: एक वर्कफ़्लो
स्टैक "आसान" महसूस तब करता है जब डेवलपमेंट और ऑपरेशन्स एक ही मान्यताओं को साझा करते हैं: आप ऐप कैसे शुरू करते हैं, डेटा कैसे बदलता है, टेस्ट कैसे चलते हैं, और जब कुछ टूटता है तो आप कैसे जानते हैं कि क्या हुआ। अगर ये हिस्से मेल नहीं खाते, टीम्स glue code, brittle scripts, और मैन्युअल रनबुक्स में समय गंवाती हैं।
लोकल डेवलपमेंट स्पीड
तेज़ लोकल सेटअप एक फीचर है। प्राथमिकता दें एक वर्कफ़्लो को जहाँ नया teammate क्लोन, इंस्टॉल, माइग्रेशन्स चलाकर और वास्तविक टेस्ट डेटा के साथ मिनटों में चल सके—not घंटों में।
आम तौर पर इसका मतलब है:
- एक कमांड से ऐप और डिपेंडेंसीज़ बूट हो (अक्सर कंटेनरों के माध्यम से)
- माइग्रेशन्स हर मशीन पर भरोसेमंद तरीके से चलें
- सीड डेटा प्रोडक्शन शेप से मेल खाता हो (सिर्फ़ "hello world" rows नहीं)
यदि आपका फ्रेमवर्क की माइग्रेशन टूलिंग आपके डेटाबेस विकल्प से लड़ती है, तो हर स्कीमा बदलाव एक छोटा प्रोजेक्ट बन जाता है।
आपके स्टैक के अनुरूप टेस्टिंग पिरामीड
आपके स्टैक को यह नेचुरल बनाना चाहिए कि आप लिखें:
- यूनिट टेस्ट्स जो डेटाबेस की आवश्यकता नहीं रखते
- इंटीग्रेशन टेस्ट्स जो वास्तविक डेटाबेस स्कीमा और क्वेरीज को हिट करते हैं
- एंड-टू-एंड टेस्ट्स जो पूरे रिक्वेस्ट पाथ को एक्सरसाइज़ करते हैं
एक आम फ़ेल्योर मोड यह है कि टीमें यूनिट टेस्ट्स पर ज़्यादा निर्भर हो जाती हैं क्योंकि इंटीग्रेशन टेस्ट्स सेटअप करने में धीमे या कष्टप्रद होते हैं। यह अक्सर स्टैक/ऑप्स mismatch होता है—टेस्ट डेटाबेस प्रोविज़निंग, माइग्रेशन्स, और फिक्स्चर्स streamline नहीं होते।
एप्लिकेशन और डेटाबेस में ऑब्जर्वेबिलिटी
जब लेटेंसी spike करे, आपको एक रिक्वेस्ट को फ्रेमवर्क से डेटाबेस तक ट्रेस करना चाहिए।
सुसंगत structured logs, बुनियादी मेट्रिक्स (रिक्वेस्ट दर, एरर्स, DB समय), और ट्रेसेस जो क्वेरी टाइमिंग शामिल करें—इनकी तलाश करें। यहाँ तक कि एक सरल correlation ID जो ऐप लॉग्स और डेटाबेस लॉग्स दोनों में दिखे, “guessing” को “finding” में बदल सकता है।
ऑपरेशनल फिट: सुरक्षित परिवर्तन और रिकवरी
ऑपरेशन्स डेवलपमेंट से अलग नहीं है; यह उसका जारी हिस्सा है।
ऐसे टूल्स चुनें जो सपोर्ट करें:
- बैकअप्स और restores जिन्हें आपने टेस्ट किया हुआ हो (केवल कॉन्फ़िगर नहीं)
- स्कीमा चेंजेस जो सुरक्षित रूप से आगे रोल कर सकें (और कभी-कभी रिवर्स भी)
- “deploy के दौरान क्या होता है” का स्पष्ट पाथ ताकि रिलीज़ tribal knowledge पर निर्भर न रहें
यदि आप लापरवाही से restore या माइग्रेशन लोकली rehears नहीं कर सकते, तो आप दबाव में अच्छा काम नहीं करेंगे।
एक व्यावहारिक चेकलिस्ट — कोहेरेंट स्टैक चुनने के लिए
स्टैक चुनना "बेस्ट" टूल चुनने से ज़्यादा इस बारे में है कि ऐसे टूल चुनें जो आपके रियल कन्स्ट्रेंट्स के भीतर एक-दूसरे से मेल खाएँ। इस चेकलिस्ट का उपयोग प्रारंभ में संरेखण मज़बूत करने के लिए करें।
1) त्वरित चेकलिस्ट (फ़ीचर्स से पहले फिट)
- टीम स्किल्स: आपकी टीम 12–24 महीनों के लिए क्या भरोसेमंद तरीके से शिप और मेंटेन कर सकती है?
- डोमेन शेप: ज्यादातर वर्कफ़्लो और रिकॉर्ड्स, या जटिल नियम, या भारी रिपोर्टिंग?
- डेटा ज़रूरतें: रिलेशनल इंटीग्रिटी, लचीले डॉक्यूमेंट्स, टाइम-सीरीज़, फुल-टेक्स्ट सर्च, एनालिटिक्स?
- सीमाएँ: अनुपालन, लेटेंसी टार्गेट्स, deployment मॉडल, बजट, मौजूदा इन्फ्रास्ट्रक्चर।
- फेल्योर सहिष्णुता: क्या आप eventual consistency स्वीकार कर सकते हैं, या आपको सख्त ट्रांज़ैक्शन्स चाहिए?
2) अपने प्रोडक्ट को सामान्य पैटर्न्स से मैप करें
- CRUD-heavy ऐप (internal tools, back office, early SaaS): पारंपरिक वेब फ्रेमवर्क + रिलेशनल DB आम तौर पर सबसे तेज़ पाथ होते हैं क्योंकि माइग्रेशन्स, ट्रांज़ैक्शन्स, और एडमिन वर्कफ़्लो सीधे रहते हैं।
- Analytics-heavy (dashboards, event tracking): जल्दी ही एक OLAP स्टोर या वेयरहाउस की योजना बनाएं; Postgres को BI सिस्टम बनाने की कोशिश दोनों को धीमा कर सकती है।
- Real-time (chat, collaboration, streaming): WebSocket सपोर्ट, pub/sub, और predictable concurrency को प्राथमिकता दें। आपकी भाषा/runtime यह तय करते हैं कि यह कितना दर्दनाक होगा।
- SaaS multi-tenant: पहले तय करें: अलग डेटाबेस, अलग स्कीमा, या row-level tenancy। यह चुनाव auth, माइग्रेशन्स, और सपोर्ट ऑपरेशन्स में cascades करेगा।
3) एक छोटा प्रूफ़-ऑफ़-कॉन्सेप्ट चलाएँ (ओवरबिल्ड न करें)
समय-निर्धारित रखें: 2–5 दिन। एक पतली वर्टिकल स्लाइस बनाएं: एक कोर वर्कफ़्लो, एक बैकग्राउंड जॉब, एक रिपोर्ट-जैसी क्वेरी, और बेसिक auth। डेवलपर फ्रिक्शन, माइग्रेशन की कार्यक्षमता, क्वेरी की स्पष्टता, और टेस्ट करने की आसानी को मापें।
यदि आप इस कदम को तेज़ करना चाहते हैं, तो एक vibe-coding टूल जैसे Koder.ai चैट-ड्रिवन स्पेक्ट से UI, API, और डेटाबेस का एक वर्किंग वर्टिकल स्लाइस जल्दी जेनरेट करने में मदद कर सकता है—फिर स्नैपशॉट/रोलबैक के साथ iterate करना और सोर्स कोड एक्सपोर्ट करना आसान होता है जब आप किसी दिशा में कमिट करना चाहें।
4) एक पेज का डिसीजन रिकॉर्ड लिखें
Title:
Date:
Context (what we’re building, constraints):
Options considered:
Decision (language/framework/database):
Why this fits (data model, consistency, ops, hiring):
Risks & mitigations:
When we’ll revisit:
सामान्य मिसमैचेस (और उन्हें कैसे टाला जाए)
एंड-टू-एंड प्रदर्शन देखें
होस्टेड वर्जन जल्दी शिप करें ताकि वास्तविक हालात में लैटेंसी, पूलिंग और क्वेरी समस्याएँ पकड़ सकें।
मजबूत टीमें भी स्टैक मिसमैचेस का शिकार होती हैं—ऐसे चुनाव जो अकेले में ठीक दिखते हैं पर सिस्टम बन जाने पर friction पैदा करते हैं। अच्छी खबर: अधिकांश पूर्वानुमेय हैं, और आप कुछ चेक्स के साथ उन्हें टाल सकते हैं।
सूंघने योग्य संकेत (smells) पर ध्यान दें
एक क्लासिक सूंग यह है कि आप डेटाबेस या फ्रेमवर्क को इसलिए चुन लें क्योंकि वह ट्रेंडिंग है जबकि आपका वास्तविक डेटा मॉडल अभी अस्थिर हो। दूसरा है premature scaling: लाखों उपयोगकर्ताओं के लिए ऑप्टिमाइज़ करना इससे पहले कि आप सैकड़ों को भरोसेमंद तरीके से संभाल सकें—यह अक्सर अतिरिक्त इन्फ्रा और अधिक फ़ेल्योर मोड लाता है।
इसके अलावा उन स्टैक्स पर ध्यान दें जहाँ टीम यह नहीं बता सकती कि हर प्रमुख भाग क्यों मौजूद है। अगर जवाब ज्यादातर "सब इसका उपयोग करते हैं" है, तो आप जोखिम इकट्ठा कर रहे हैं।
बाद में काटने वाले इंटीग्रेशन रिस्क
कई समस्याएँ सीमाओं पर दिखती हैं:
- Mismatch ड्राइवर्स और फीचर्स: आपकी भाषा ड्राइवर उस डेटाबेस फीचर को पूरी तरह सपोर्ट नहीं करता जिसकी आपने उम्मीद की थी (types, streaming, retries)।
- कमज़ोर माइग्रेशन्स: स्कीमा बदलाव मैन्युअल हैं, या माइग्रेशन टूल्स ऐप के विकास के तरीके से मेल नहीं खाते, जिससे पर्यावरणों में ड्रिफ्ट होता है।
- खराब कनेक्शन पूलिंग: फ्रेमवर्क बहुत सारी कनेक्शन्स खोलता है, या deployments प्रक्रियाओं/कंटेनरों के पार पूल्स को गुणा करते हैं, जिससे लोड के तहत टाइमआउट होते हैं।
ये “डेटाबेस इश्यूज़” नहीं हैं या “फ्रेमवर्क इश्यूज़” नहीं—ये सिस्टम इश्यूज़ हैं।
कैसे सरल करें (और जोखिम कम करें)
कम moving parts पसंद करें और सामान्य कार्यों के लिए एक स्पष्ट पाथ: एक माइग्रेशन अप्रोच, ज़्यादातर फीचर्स के लिए एक क्वेरी स्टाइल, और सेवाओं के बीच सुसंगत कन्वेंशंस। यदि आपका फ्रेमवर्क किसी पैटर्न (request lifecycle, dependency injection, job pipeline) को प्रोत्साहित करता है, तो उसमें झुकें बजाए कि शैलियों को मिलाएँ।
निर्णय कब पुनर्विचार करें—और सुरक्षित रूप से बदलें
जब आप recurring production incidents, लगातार डेवलपर फ्रिक्शन, या नई प्रोडक्ट आवश्यकताएँ देखें जो आपके डेटा एक्सेस पैटर्न को मौलिक रूप से बदल देती हैं तो निर्णय पुनर्विचार करें।
सुरक्षित रूप से बदलने के लिए सीम को अलग करें: एक adapter लेयर पेश करें, क्रमिक रूप से माइग्रेट करें (dual-write या बैकफिल जहाँ ज़रूरी), और ट्रैफ़िक फ़्लिप करने से पहले automated tests के साथ parity साबित करें।
समापन: स्टैक को एक प्रणाली के रूप में ट्रीट करें
प्रोग्रामिंग भाषा, वेब फ्रेमवर्क, और डेटाबेस चुनना तीन स्वतंत्र निर्णय नहीं है—यह तीन जगहों में एक्सप्रेस किया गया एक सिस्टम डिज़ाइन निर्णय है। "सबसे अच्छा" विकल्प वह कॉम्बिनेशन है जो आपके डेटा शेप, आपकी कंसिस्टेंसी ज़रूरतों, आपकी टीम के वर्कफ़्लो, और उस तरीके के अनुरूप हो जिससे आप अपेक्षा करते हैं कि प्रोडक्ट बढ़ेगा।
क्या लेकर जाएँ
- अपने कोर डेटा मॉडल और आप जो सबसे ज़्यादा ऑपरेशन करते हैं उसके चारों ओर स्टैक चुनें।
- कंसिस्टेंसी और ट्रांज़ैक्शन्स भी एप्लिकेशन चिंताएँ हैं—इन्हें end-to-end डिज़ाइन करें, सिर्फ़ डेटाबेस-ओनली नहीं।
- परफ़ॉर्मेंस बॉटलनेक्स अक्सर बॉउंड्रीज़ को पार करते हैं (स्कीमा, क्वेरीज़, कैशिंग, सीरियलाइज़ेशन, क्यूज़)।
- सुरक्षा और विश्वसनीयता कोड, कॉन्फ़िगरेशन, और ऑपरेशन्स में साझा जिम्मेदारी हैं।
- डेवलपर अनुभव मायने रखता है क्योंकि यह तय करता है कि आप कितनी तेज़ी से सुरक्षित तरीके से शिप कर सकते हैं।
मान्यताओं को दस्तावेज़ करें (उनके constraints बनने से पहले)
अपने चुनावों के पीछे के कारण लिखें: अपेक्षित ट्रैफ़िक पैटर्न, स्वीकार्य लेटेंसी, डेटा रिटेंशन नियम, वह फ़ेल्योर मोड जिसे आप सहन कर सकते हैं, और अभी आप किन चीज़ों को स्पष्ट रूप से ऑप्टिमाइज़ नहीं कर रहे हैं। यह ट्रेडऑफ़्स को दिखाता है, भविष्य के साथियों को “क्यों” समझने में मदद करता है, और जब आवश्यकताएँ बदलें तो आकस्मिक आर्किटेक्चर ड्रिफ्ट को रोकता है।
अगले कदम
अपने वर्तमान सेटअप को चेकलिस्ट सेक्शन के माध्यम से चलाएँ और नोट करें जहाँ निर्णय मेल नहीं खाते (उदाहरण के लिए, ऐसा स्कीमा जो ORM से लड़ता है, या ऐसा फ्रेमवर्क जो बैकग्राउंड वर्क को अजीब बनाता है)।
यदि आप नए दिशानिर्देश खोज रहे हैं, तो Koder.ai जैसे टूल भी मदद कर सकते हैं कि स्टैक मान्यताओं की जल्दी तुलना कैसे करें—यह एक बेसलाइन ऐप (आमतौर पर React वेब के लिए, Go सर्विसेज़ के साथ PostgreSQL, और मोबाइल के लिए Flutter) जेनरेट कर सकता है जिसे आप निरीक्षण, एक्सपोर्ट, और विकसित कर सकते हैं—बिना लंबे बिल्ड साइकिल के तुरंत कमिट किए।
गहराई से आगे बढ़ने के लिए /blog पर संबंधित गाइड ब्राउज़ करें, /docs में इम्प्लीमेंटेशन डिटेल्स देखें, या समर्थन और deployment विकल्पों की तुलना के लिए /pricing देखें।