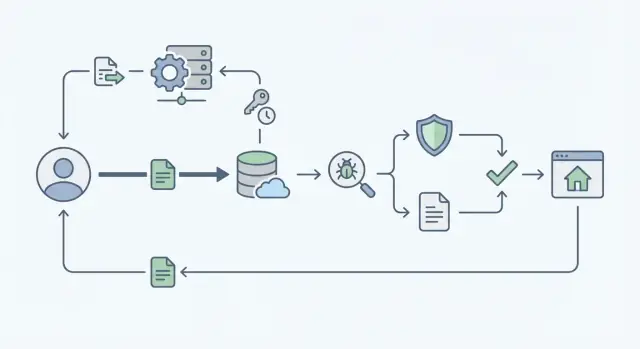
Pourquoi les téléversements de fichiers sont difficiles à grande échelle
Les uploads semblent simples... jusqu'à l'arrivée des vrais utilisateurs. Une personne charge une photo de profil. Puis dix mille personnes téléversent des PDFs, des vidéos et des feuilles de calcul en même temps. Soudain l'application devient lente, les coûts de stockage augmentent et les tickets de support s'accumulent.
Les modes de panne courants sont prévisibles. Les pages d'upload bloquent ou expirent quand votre serveur essaie de transférer les octets au lieu de laisser le stockage d'objets faire le travail. Les permissions dérivent et quelqu'un devine une URL d'objet et voit ce qu'il ne devrait pas. Des fichiers « inoffensifs » arrivent avec des malwares ou des formats tordus qui plantent les outils en aval. Et les logs sont incomplets, donc vous ne pouvez pas répondre à des questions basiques comme qui a uploadé quoi et quand.
Ce que vous voulez, c'est ennuyeux et fiable : des uploads rapides, des règles claires (types et tailles autorisées) et une piste d'audit qui facilite les enquêtes en cas d'incident.
Le compromis le plus difficile est vitesse vs sécurité. Si vous exécutez toutes les vérifications avant que l'utilisateur ait fini, il attend et relance, ce qui augmente la charge. Si vous repoussez trop les contrôles, des fichiers dangereux ou non autorisés peuvent se propager avant que vous ne les attrapiez. Une approche pratique consiste à séparer l'upload des vérifications et à garder chaque étape rapide et mesurable.
Soyez aussi précis sur la notion de « scale ». Notez vos chiffres : fichiers par jour, pics d'uploads par minute, taille max par fichier, et où se trouvent vos utilisateurs. Les régions comptent pour la latence et les règles de confidentialité.
Si vous construisez une appli sur une plateforme comme Koder.ai, il est utile de décider ces limites tôt, car elles influencent la conception des permissions, du stockage et du workflow d'analyse en arrière‑plan.
Un modèle de menace simple pour les uploads
Avant de choisir des outils, clarifiez ce qui peut mal tourner. Un modèle de menace n'a pas besoin d'être un gros document. C'est une compréhension courte et partagée de ce que vous devez empêcher, ce que vous pouvez détecter plus tard et quels compromis vous acceptez.
Les attaquants essaient généralement de passer par quelques points prévisibles : le client (modification des métadonnées ou falsification du MIME type), le périmètre réseau (replays et abus de rate limit), le stockage (deviner des noms d'objets, écraser), et le téléchargement/aperçu (déclencher des rendus risqués ou voler des fichiers via un accès partagé).
À partir de là, mappez les menaces à des contrôles simples :
Les fichiers surdimensionnés sont le mauvais usage le plus simple. Ils font grimper les coûts et ralentissent les vrais utilisateurs. Arrêtez‑les tôt avec des limites en octets strictes et un rejet rapide.
Les faux types de fichiers arrivent ensuite. Un fichier nommé invoice.pdf peut être autre chose. Ne faites pas confiance aux extensions ou aux contrôles UI. Vérifiez d'après les octets réels après upload.
Le malware est différent. En général, vous ne pouvez pas scanner tout avant la fin de l'upload sans rendre l'expérience pénible. Le schéma usuel est de détecter de façon asynchrone, mettre en quarantaine les éléments suspects et bloquer l'accès jusqu'à ce que le scan soit passé.
L'accès non autorisé est souvent le plus dommageable. Traitez chaque upload et chaque téléchargement comme une décision d'autorisation. Un utilisateur doit uniquement uploader dans un emplacement qu'il possède (ou où il a le droit d'écrire) et ne télécharger que ce qu'il est autorisé à voir.
Pour de nombreuses applis, une bonne politique v1 est :
- Appliquer une taille max et des catégories autorisées (images, PDFs, etc.)
- Vérifier le type réel serveur‑side après l'upload
- Scanner de façon asynchrone et mettre en quarantaine jusqu'à propreté
- Exiger une autorisation explicite pour upload et download
- Logger et alerter sur les échecs répétés (taille, type, auth)
Une architecture d'upload pratique qui reste rapide
La façon la plus rapide de gérer les uploads est de tenir votre serveur applicatif à l'écart du « business des octets ». Plutôt que d'envoyer chaque fichier via votre backend, laissez le client uploader directement vers le stockage d'objets en utilisant une URL signée courte. Votre backend reste concentré sur les décisions et les enregistrements, pas sur le transfert de gigaoctets.
La séparation est simple : le backend répond à « qui peut uploader quoi, et où », tandis que le stockage reçoit les données. Cela élimine un goulot fréquent : des serveurs applicatifs qui refont deux fois le travail (auth + proxy du fichier) et qui atteignent leurs limites CPU, mémoire ou réseau sous charge.
Les composants minimaux
Gardez un petit enregistrement d'upload dans votre base (par exemple PostgreSQL) pour que chaque fichier ait un propriétaire clair et un cycle de vie défini. Créez cet enregistrement avant le début de l'upload, puis mettez‑le à jour au fil des événements.
Les champs qui paient souvent incluent l'owner et les identifiants tenant/workspace, la clé d'objet de stockage, un statut, la taille et le MIME revendiqués, et un checksum que vous pouvez vérifier.
Planifiez les états d'upload à l'avance
Traitez les uploads comme une machine à états pour que les contrôles d'autorisation restent corrects même en cas de retries.
Un jeu d'états pratique est :
- requested
- uploaded
- scanned
- approved
- rejected
N'autorisez le client à utiliser l'URL signée qu'après que le backend ait créé un enregistrement requested. Après que le stockage confirme l'upload, passez à uploaded, lancez le scan antivirus en arrière‑plan et n'exposez le fichier qu'une fois approved.
Étape par étape : uploads par URL signée sans goulots
On commence quand l'utilisateur clique sur Upload. Votre appli appelle le backend pour démarrer un upload avec des détails basiques comme le nom de fichier, la taille prévue et l'usage (avatar, facture, pièce jointe). Le backend vérifie l'autorisation pour cette cible spécifique, crée un enregistrement d'upload et renvoie une URL signée courte.
L'URL signée doit être finement limitée. Idéalement elle n'autorise qu'un seul upload vers une clé d'objet exacte, avec une courte échéance et des conditions claires (limite de taille, type de contenu autorisé, checksum optionnel).
Le navigateur upload directement vers le stockage en utilisant cette URL. Quand c'est fini, le navigateur appelle à nouveau le backend pour finaliser. À la finalisation, re‑vérifiez l'autorisation (les accès peuvent changer) et vérifiez ce qui a vraiment atterri dans le stockage : taille, type détecté et checksum si vous en utilisez un. Faites de la finalisation une opération idempotente pour que les retries n'engendrent pas de duplicata.
Marquez ensuite l'enregistrement uploaded et déclenchez le scan en arrière‑plan (queue/job). L'UI peut afficher « En cours de traitement » pendant l'analyse.
Validation de type et taille sur laquelle vous pouvez compter
Déployer des permissions multi-tenant
Générez des règles claires d'upload et de téléchargement par workspace ou tenant.
Quoi valider, et où
Se fier à une extension, c'est ainsi que invoice.pdf.exe finit dans votre bucket. Traitez la validation comme un ensemble de contrôles répétables qui se produisent à plusieurs endroits.
Commencez par les limites de taille. Placez la taille maximale dans la politique de l'URL signée (ou dans les conditions du POST pré-signé) pour que le stockage puisse rejeter les uploads trop gros dès le départ. Faites appliquer la même limite lorsque votre backend enregistre les métadonnées, car les clients peuvent tenter de contourner l'UI.
Les contrôles de type doivent se baser sur le contenu, pas sur le nom de fichier. Inspectez les premiers octets du fichier (magic bytes) pour confirmer qu'ils correspondent à ce que vous attendez. Un vrai PDF commence par %PDF, et les PNG ont une signature fixe. Si le contenu ne correspond pas à votre allowlist, rejetez‑le même si l'extension semble correcte.
Gardez des allowlists spécifiques à chaque fonctionnalité. Un upload d'avatar peut n'accepter que JPEG et PNG. Une fonctionnalité de documents peut autoriser PDF et DOCX. Cela réduit le risque et rend vos règles plus simples à expliquer.
Checksums et noms de fichiers
Ne faites jamais confiance au nom original comme clé de stockage. Normalisez‑le pour l'affichage (retirez les caractères bizarres, tronquez), mais stockez votre propre clé d'objet sûre, comme un UUID plus une extension que vous assignez après détection du type.
Stockez un checksum (par exemple SHA‑256) dans votre base et comparez‑le plus tard pendant le traitement ou le scan. Cela aide à détecter la corruption, les uploads partiels ou la manipulation, surtout quand des retries se produisent sous charge.
Analyse antivirus qui ne fait pas attendre les utilisateurs
L'analyse malware est importante, mais elle ne doit pas bloquer le chemin critique. Acceptez rapidement l'upload, puis traitez le fichier comme bloqué jusqu'à ce qu'il soit passé au scan.
Le schéma asynchrone
Créez un enregistrement d'upload avec un statut comme pending_scan. L'UI peut afficher le fichier, mais il ne doit pas être utilisable.
Le scan est généralement déclenché par un événement de stockage quand l'objet est créé, par la publication d'un job dans une queue juste après la fin de l'upload, ou par les deux (queue + événement de stockage comme filet de sécurité).
Le worker de scan télécharge ou stream l'objet, exécute les scanners, puis écrit le résultat dans votre base. Conservez l'essentiel : statut du scan, version du scanner, timestamps et qui a demandé l'upload. Cette piste d'audit facilite grandement le support quand quelqu'un demande « Pourquoi mon fichier est‑il bloqué ? »
Que faire quand un fichier échoue
Ne laissez pas les fichiers échoués mélangés aux propres. Choisissez une politique et appliquez‑la de façon cohérente : mettre en quarantaine et retirer l'accès, ou supprimer si vous n'avez pas besoin du fichier pour l'enquête.
Quelle que soit la décision, gardez le message utilisateur calme et précis. Dites ce qui s'est passé et quoi faire ensuite (ré‑uploader, contacter le support). Alertez votre équipe si beaucoup d'échecs surviennent en peu de temps.
Surtout, imposez une règle stricte pour les téléchargements et aperçus : seuls les fichiers marqués approved peuvent être servis. Tout le reste retourne une réponse sûre du type « Le fichier est toujours en cours de vérification. »
Vérifications d'autorisation qui restent correctes sous charge
Les uploads rapides, c'est bien, mais si la mauvaise personne peut attacher un fichier au mauvais workspace, vous avez un problème plus grave que des requêtes lentes. La règle la plus simple est aussi la plus forte : chaque enregistrement de fichier appartient exactement à un tenant (workspace/org/projet) et a un owner/créateur clair.
Faites les contrôles d'autorisation deux fois : quand vous émettez l'URL signée, et à nouveau quand quelqu'un tente de télécharger ou voir le fichier. Le premier contrôle arrête les uploads non autorisés. Le second vous protège si l'accès est révoqué, une URL fuit ou le rôle d'un utilisateur change après l'upload.
Le principe du moindre privilège rend la sécurité et la performance prévisibles. Plutôt que d'avoir une permission globale « files », séparez des rôles comme « peut uploader », « peut voir », et « peut gérer (supprimer/partager) ». Beaucoup de requêtes deviennent alors de simples lectures rapides (user, tenant, action) au lieu d'une logique personnalisée coûteuse.
Pour éviter le guessing d'ID, évitez les IDs séquentiels dans les URLs et APIs. Utilisez des identifiants opaques et des clés de stockage non devinables. Les URL signées sont le transport, pas votre système d'autorisation.
Les fichiers partagés rendent souvent les systèmes lents et confus. Traitez le partage comme des données explicites, pas comme un accès implicite. Une approche simple est une table de partage séparée qui accorde à un utilisateur ou un groupe la permission sur un fichier, éventuellement avec une date d'expiration.
Garder les uploads rapides quand le trafic et la taille augmentent
Gagnez des crédits en livrant
Partagez votre build ou parrainez un ami et obtenez des crédits pour Koder.ai.
Quand on parle d'échelle pour des uploads sécurisés, on se concentre souvent sur les contrôles de sécurité et on oublie l'essentiel : déplacer des octets est la partie lente. L'objectif est de garder le trafic des gros fichiers hors de vos serveurs applicatifs, limiter les retries et éviter que les contrôles de sécurité ne deviennent une file d'attente non bornée.
Rendre les gros fichiers prévisibles
Pour les gros fichiers, utilisez l'upload multipart ou en chunks pour qu'une connexion instable n'oblige pas à repartir de zéro. Les chunks aident aussi à appliquer des limites claires : taille totale max, taille maximale par chunk et durée maximale d'upload.
Fixez des timeouts et des retries intentionnels côté client. Quelques retries peuvent sauver de vrais utilisateurs ; des retries illimités peuvent faire exploser les coûts, surtout sur réseaux mobiles. Visez des timeouts courts par chunk, un petit nombre de retries et une échéance dure pour l'ensemble de l'upload.
Contrôler l'étape « create upload »
Les URL signées gardent le chemin lourd rapide, mais la requête qui les crée reste un point chaud. Protégez‑la pour qu'elle reste réactive :
- Rate‑limitez la création d'upload par utilisateur et par IP
- Faites appliquer les limites de taille avant d'émettre l'URL signée
- Utilisez un TTL court pour que les URL inutilisées expirent vite
- Suivez les uploads en cours pour qu'un utilisateur ne puisse pas en démarrer des centaines
- Utilisez des clés d'idempotence pour que les rafraîchissements n'engendrent pas de duplicatas
La latence dépend aussi de la géographie. Placez votre appli, stockage et workers de scan dans la même région quand c'est possible. Si vous avez besoin d'hébergement par pays pour la conformité, planifiez le routage tôt pour que les uploads ne fassent pas des allers‑retours inter‑continentaux. Les plateformes qui tournent globalement sur AWS (comme Koder.ai) peuvent rapprocher les workloads des utilisateurs quand la résidence des données importe.
Enfin, planifiez les téléchargements, pas seulement les uploads. Servez les fichiers avec des URL de téléchargement signées et définissez des règles de cache en fonction du type de fichier et du niveau de confidentialité. Les assets publics peuvent être mis en cache plus longuement ; les reçus privés doivent rester à courte durée et vérifiés en autorisation.
Scénario d'exemple : factures et reçus dans une appli multi‑utilisateurs
Imaginez une appli pour petites entreprises où des employés uploadent factures et photos de reçus, et un manager les approuve pour remboursement. Ici le design d'upload cesse d'être académique : vous avez beaucoup d'utilisateurs, de grosses images et de l'argent en jeu.
Un bon flux utilise des statuts clairs pour que tout le monde sache ce qui se passe et que vous puissiez automatiser les parties ennuyeuses : le fichier arrive dans le stockage d'objets et vous sauvegardez un enregistrement lié à l'utilisateur/workspace/dépense ; un job en arrière‑plan scanne le fichier et extrait des métadonnées basiques (type MIME réel) ; ensuite l'élément est approuvé et devient utilisable dans les rapports, ou rejeté et bloqué.
Les utilisateurs ont besoin d'un retour rapide et précis. Si le fichier est trop gros, affichez la limite et la taille actuelle (par exemple : « Le fichier fait 18 Mo. Max 10 Mo. »). Si le type est incorrect, dites ce qui est autorisé (« Chargez un PDF, JPG ou PNG »). Si l'analyse échoue, restez calme et actionnable (« Ce fichier pourrait être dangereux. Veuillez charger une nouvelle copie. »).
Les équipes de support ont besoin d'une piste qui les aide à déboguer sans ouvrir le fichier : upload ID, user ID, workspace ID, timestamps created/uploaded/scan started/scan finished, codes de résultat (trop volumineux, type non conforme, scan échoué, permission refusée), plus la clé de stockage et le checksum.
Les ré‑uploads et remplacements sont fréquents. Traitez‑les comme de nouveaux uploads, attachez‑les à la même dépense comme une nouvelle version, conservez l'historique (qui a remplacé et quand) et ne marquez que la version la plus récente comme active. Si vous construisez cette appli sur Koder.ai, cela se mappe proprement à une table uploads plus une table expense_attachments avec un champ de version.
Erreurs courantes et corrections faciles
Changer les limites en toute confiance
Testez de nouvelles limites et règles, puis revenez en arrière rapidement si nécessaire.
La plupart des bugs d'upload ne sont pas des hacks sophistiqués. Ce sont de petits raccourcis qui se transforment en risques réels quand le trafic augmente.
Les cinq erreurs qui reviennent le plus
- Se fier uniquement aux contrôles côté client. Correctif : validez à nouveau côté serveur en utilisant les octets réels (magic bytes) et appliquez les limites de taille via les métadonnées du stockage, pas seulement via le rapport du navigateur.
- Faire durer trop longtemps les URL signées. Correctif : gardez‑les courtes (minutes), à usage unique et scellées sur une clé d'objet. Rotatez les credentials et loggez chaque émission.
- Autoriser le téléchargement avant la fin du scan. Correctif : uploadez dans un emplacement de quarantaine, scannez de façon asynchrone, puis promouvez ou servez après résultat propre.
- Utiliser des noms ou chemins fournis par l'utilisateur comme clés de stockage. Correctif : générez vos propres clés d'objet (UUID) et stockez le nom original uniquement comme métadonnée d'affichage.
- Sauter les vérifications d'autorisation au téléchargement. Correctif : traitez le téléchargement comme une décision à part et re‑vérifiez ownership, appartenance au workspace et règles de partage chaque fois que vous créez une URL de téléchargement.
Corrections simples qui évitent les goulots
Plus de contrôles n'ont pas à ralentir les uploads. Séparez le chemin rapide du chemin lourd.
Faites des vérifications rapides de façon synchrone (auth, taille, type autorisé, rate limits), puis déléguez le scan et l'inspection approfondie à un worker en arrière‑plan. Les utilisateurs peuvent continuer à travailler pendant que le fichier passe de « uploaded » à « ready ». Si vous construisez avec un builder basé chat comme Koder.ai, gardez le même état d'esprit : rendez l'endpoint d'upload petit et strict, et poussez l'analyse et le post‑traitement dans des jobs.
Checklist rapide et prochaines étapes
Avant d'envoyer les uploads en production, définissez ce que « suffisamment sûr pour v1 » signifie. Les équipes se mettent généralement en difficulté en mélangeant des règles trop strictes (qui bloquent de vrais utilisateurs) avec des règles manquantes (qui invitent l'abus). Commencez petit, mais assurez‑vous que chaque upload a un chemin clair de « reçu » à « autorisé au téléchargement ».
Une checklist serrée avant lancement :
- Appliquer une limite stricte de taille tôt (avant que les coûts de stockage ne grimpent)
- Utiliser une allowlist de types, validée par le contenu (magic bytes), pas seulement par le nom
- Verrouiller l'accès via le scan : ne servez pas les fichiers aux autres tant que le scan n'est pas terminé
- Exiger des vérifications d'autorisation à chaque téléchargement
- Conserver des logs d'audit pour l'upload, le résultat du scan et les tentatives de téléchargement
Si vous avez besoin d'une politique minimale viable, restez simple : limite de taille, allowlist stricte, upload par URL signée et « quarantaine jusqu'à passage du scan ». Ajoutez des fonctionnalités plus ergonomiques ensuite (aperçus, plus de types, retraitements en arrière‑plan) une fois le chemin principal stable.
La surveillance est ce qui empêche le « rapide » de devenir « mystérieusement lent » à mesure que vous grandissez. Suivez le taux d'échec d'upload (client vs serveur/stockage), le taux d'échec des scans et la latence des scans, le temps moyen d'upload par bucket de taille, les refus d'autorisation au téléchargement et les patterns d'egress de stockage.
Faites un petit load test avec des tailles de fichiers réalistes et des réseaux réels (le mobile se comporte différemment du Wi‑Fi de bureau). Corrigez timeouts et retries avant le lancement.
Si vous implémentez cela dans Koder.ai (koder.ai), Planning Mode est un bon endroit pour cartographier vos états d'upload et vos endpoints d'abord, puis générer le backend et l'UI autour de ce flux. Les snapshots et rollback aident aussi quand vous ajustez des limites ou des règles de scan.