14 oct. 2025·8 min
RLS PostgreSQL pour SaaS : des politiques qui fonctionnent
Le RLS de PostgreSQL pour SaaS permet d'imposer l'isolation des tenants dans la base. Apprenez quand l'utiliser, comment écrire des politiques et quoi éviter.
Le RLS de PostgreSQL pour SaaS permet d'imposer l'isolation des tenants dans la base. Apprenez quand l'utiliser, comment écrire des politiques et quoi éviter.
Dans une application SaaS, le bug de sécurité le plus dangereux est celui qui apparaît après la mise à l'échelle. Vous commencez avec une règle simple comme « les utilisateurs ne peuvent voir que les données de leur tenant », puis vous publiez rapidement un nouvel endpoint, ajoutez une requête de rapport ou introduisez une jointure qui saute discrètement la vérification.
L'autorisation uniquement côté application lâche sous la pression parce que les règles se retrouvent dispersées. Un contrôleur vérifie tenant_id, un autre vérifie l'appartenance, un job en arrière-plan oublie, et un chemin « export admin » reste « temporaire » pendant des mois. Même les équipes prudentes ratent un endroit.
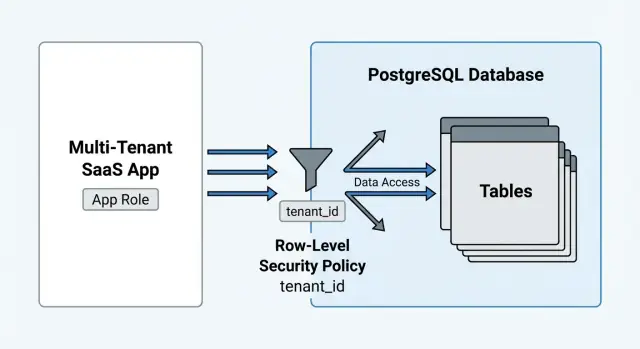
Le Row-Level Security de PostgreSQL (RLS) résout un problème précis : il fait en sorte que la base de données impose quelles lignes sont visibles pour une requête donnée. Le modèle mental est simple : chaque SELECT, UPDATE et DELETE est automatiquement filtré par des politiques, comme chaque requête est filtrée par le middleware d'authentification.
Le « lignes » a son importance. RLS ne protège pas tout :
Un exemple concret : vous ajoutez un endpoint qui liste les projets avec une jointure vers les factures pour un tableau de bord. Avec une autorisation uniquement côté app, il est facile de filtrer projects par tenant mais d'oublier de filtrer invoices, ou de joindre sur une clé qui traverse les tenants. Avec RLS, les deux tables peuvent imposer l'isolation par tenant, donc la requête échouera en mode sûr plutôt que de fuir des données.
L'échange est réel. Vous écrivez moins de code d'autorisation répété et réduisez le nombre d'endroits susceptibles de fuir. Mais vous prenez aussi du travail supplémentaire : vous devez concevoir les politiques soigneusement, les tester tôt, et accepter qu'une politique puisse bloquer une requête que vous pensiez fonctionner.
RLS peut sembler un travail en plus jusqu'à ce que votre app dépasse une poignée d'endpoints. Si vous avez des frontières de tenant strictes et beaucoup de chemins de requête (écrans de liste, recherche, exports, outils admin), placer la règle dans la base de données fait que vous n'avez pas à vous souvenir d'ajouter le même filtre partout.
RLS convient fortement quand la règle est ennuyeuse et universelle : « un utilisateur ne peut voir que les lignes de son tenant » ou « un utilisateur ne voit que les projets dont il est membre ». Dans ces configurations, les politiques réduisent les erreurs parce que chaque SELECT, UPDATE et DELETE passe par la même barrière, même si une requête est ajoutée plus tard.
Cela aide aussi dans les applications majoritairement en lecture où la logique de filtrage reste cohérente. Si votre API a 15 façons différentes de charger des factures (par statut, par date, par client, par recherche), RLS vous permet d'arrêter de réimplémenter le filtrage par tenant sur chaque requête et de vous concentrer sur la fonctionnalité.
RLS ajoute de la douleur quand les règles ne sont pas basées sur les lignes. Les règles par‑champ comme « vous pouvez voir le salaire mais pas la prime » ou « masquer cette colonne sauf pour les RH » se transforment souvent en SQL maladroit et en exceptions difficiles à maintenir.
C'est aussi mal adapté pour du reporting lourd qui a réellement besoin d'un accès large. Les équipes créent souvent des rôles de contournement pour « juste ce job », et c'est là que les erreurs s'accumulent.
Avant de vous engager, décidez si vous souhaitez que la base de données soit le gardien final. Si oui, prévoyez la discipline : testez le comportement de la base (pas seulement les réponses API), traitez les migrations comme des changements de sécurité, évitez les contournements rapides, décidez comment les jobs en arrière-plan s'authentifient et gardez les politiques petites et réutilisables.
Si vous utilisez des outils qui génèrent des backends, cela peut accélérer la livraison, mais ça n'enlève pas le besoin de rôles clairs, de tests et d'un modèle de tenant simple. (Par exemple, Koder.ai utilise Go et PostgreSQL pour des backends générés, et vous voulez quand même concevoir RLS délibérément plutôt que « l'ajouter plus tard ». )
RLS est le plus simple quand votre schéma indique déjà clairement qui possède quoi. Si vous partez d'un modèle flou et tentez de « le corriger avec des politiques », vous obtenez généralement des requêtes lentes et des bugs déroutants.
Choisissez une clé tenant (comme org_id) et utilisez-la de manière cohérente. La plupart des tables appartenant à un tenant devraient l'avoir, même si elles référencent une autre table qui la possède. Ceci évite les jointures à l'intérieur des politiques et garde les vérifications USING simples.
Une règle pratique : si une ligne doit disparaître quand un client annule, elle a probablement besoin de org_id.
Les politiques RLS répondent généralement à une question : « Cet utilisateur est‑il membre de cette org, et que peut‑il faire ? » C'est difficile à déduire à partir de colonnes ad hoc.
Gardez les tables centrales petites et sobres :
users (une ligne par personne)orgs (une ligne par tenant)org_memberships (user_id, org_id, role, status)project_memberships pour l'accès par projetAvec cela en place, vos politiques peuvent vérifier l'appartenance avec une seule recherche indexée.
Tout n'a pas besoin de org_id. Les tables de référence comme pays, catégories produits ou types de plan sont souvent partagées entre tous les tenants. Rendez-les en lecture seule pour la plupart des rôles et ne les liez pas à un org.
Les données appartenant au tenant (projets, factures, tickets) doivent éviter de récupérer des détails spécifiques au tenant via des tables partagées. Gardez les tables partagées minimales et stables.
Les clés étrangères fonctionnent toujours avec RLS, mais les suppressions peuvent vous surprendre si le rôle qui supprime ne « voit » pas les lignes dépendantes. Planifiez les cascades soigneusement et testez les vrais flux de suppression.
Indexez les colonnes sur lesquelles vos politiques filtrent, en particulier org_id et les clés d'appartenance. Une politique qui ressemble à WHERE org_id = ... ne doit pas devenir un scan de table complète quand la table atteint des millions de lignes.
RLS est un interrupteur par table. Une fois activé, PostgreSQL cesse de faire confiance à votre code applicatif pour se souvenir du filtre tenant. Chaque SELECT, UPDATE et DELETE est filtré par des politiques, et chaque INSERT et UPDATE est validé par des politiques.
Le plus grand changement mental : avec RLS activé, des requêtes qui renvoyaient des données peuvent commencer à renvoyer zéro ligne sans erreurs. C'est PostgreSQL qui applique le contrôle d'accès.
Les politiques sont de petites règles attachées à une table. Elles utilisent deux vérifications :
USING est le filtre de lecture. Si une ligne ne correspond pas à USING, elle est invisible pour SELECT et ne peut pas être ciblée par UPDATE ou DELETE.WITH CHECK est la barrière d'écriture. Elle décide quelles nouvelles ou modifiées lignes sont autorisées pour INSERT ou UPDATE.Un schéma SaaS courant : USING garantit que vous ne voyez que les lignes de votre tenant, et WITH CHECK empêche d'insérer une ligne dans le tenant d'un autre en devinant un tenant_id.
Quand vous ajoutez d'autres politiques plus tard, cela compte :
PERMISSIVE (par défaut) : une ligne est autorisée si n'importe quelle politique l'autorise.RESTRICTIVE : une ligne est autorisée seulement si toutes les politiques restrictives l'autorisent (en plus du comportement permissif).Si vous prévoyez de superposer des règles comme correspondance de tenant + vérifications de rôle + appartenance à un projet, les politiques restrictives peuvent clarifier l'intention, mais elles rendent aussi plus facile de se verrouiller dehors si vous oubliez une condition.
RLS a besoin d'une valeur « qui appelle » fiable. Options courantes :
app.user_id et app.tenant_id).SET ROLE ...) par requête, qui peut fonctionner mais ajoute une complexité opérationnelle.Choisissez une approche et appliquez‑la partout. Mixer des sources d'identité entre services est un chemin rapide vers des bugs déroutants.
Utilisez une convention prévisible pour que les dumps de schéma et les logs restent lisibles. Par exemple : {table}__{action}__{rule}, comme projects__select__tenant_match.
Si vous débutez avec RLS, commencez par une table et une petite preuve. L'objectif n'est pas une couverture parfaite. L'objectif est que la base de données refuse l'accès cross-tenant même si un bug applicatif survient.
Supposons une table projects simple. Ajoutez d'abord tenant_id d'une manière qui ne casse pas les écritures.
ALTER TABLE projects ADD COLUMN tenant_id uuid;
-- Backfill existing rows (example: everyone belongs to a default tenant)
UPDATE projects SET tenant_id = '11111111-1111-1111-1111-111111111111'::uuid
WHERE tenant_id IS NULL;
ALTER TABLE projects ALTER COLUMN tenant_id SET NOT NULL;
Ensuite, séparez la propriété de l'accès. Un schéma courant est : un rôle possède les tables (app_owner), un autre rôle est utilisé par l'API (app_user). Le rôle API ne doit pas être le propriétaire des tables, sinon il peut contourner les politiques.
ALTER TABLE projects OWNER TO app_owner;
REVOKE ALL ON projects FROM PUBLIC;
GRANT SELECT, INSERT, UPDATE, DELETE ON projects TO app_user;
Décidez ensuite comment la requête indique à Postgres quel tenant elle sert. Une approche simple est un paramètre de session lié à la requête. Votre app le définit juste après l'ouverture d'une transaction.
-- inside the same transaction as the request
SELECT set_config('app.current_tenant', '22222222-2222-2222-2222-222222222222', true);
Activez RLS et commencez par l'accès en lecture.
ALTER TABLE projects ENABLE ROW LEVEL SECURITY;
CREATE POLICY projects_tenant_select
ON projects
FOR SELECT
TO app_user
USING (tenant_id = current_setting('app.current_tenant')::uuid);
Prouvez que ça marche en essayant deux tenants différents et en vérifiant que le compte de lignes change.
Les politiques de lecture ne protègent pas les écritures. Ajoutez WITH CHECK pour que les inserts et updates ne puissent pas introduire des lignes dans le mauvais tenant.
CREATE POLICY projects_tenant_write
ON projects
FOR INSERT, UPDATE
TO app_user
WITH CHECK (tenant_id = current_setting('app.current_tenant')::uuid);
Une manière rapide de vérifier le comportement (y compris les échecs) est de garder un petit script SQL que vous pouvez relancer après chaque migration :
BEGIN; SET LOCAL ROLE app_user;SELECT set_config('app.current_tenant', '\u003ctenant A\u003e', true); SELECT count(*) FROM projects;INSERT INTO projects(id, tenant_id, name) VALUES (gen_random_uuid(), '\u003ctenant B\u003e', 'bad'); (doit échouer)UPDATE projects SET tenant_id = '\u003ctenant B\u003e' WHERE ...; (doit échouer)ROLLBACK;Si vous pouvez exécuter ce script et obtenir les mêmes résultats à chaque fois, vous avez une base fiable avant d'étendre RLS à d'autres tables.
La plupart des équipes adoptent RLS après en avoir assez de répéter les mêmes vérifications d'autorisation dans chaque requête. La bonne nouvelle : les formes de politiques dont vous avez besoin sont généralement cohérentes.
Certaines tables sont naturellement possédées par un seul utilisateur (notes, tokens API). D'autres appartiennent à un tenant où l'accès dépend de l'appartenance. Traitez ces cas différemment.
Pour les données « propriétaire », les politiques vérifient souvent created_by = app_user_id(). Pour les données tenant, les politiques vérifient souvent si l'utilisateur a une ligne d'appartenance pour l'org.
Un moyen pratique pour garder les politiques lisibles est de centraliser l'identité dans de petits helpers SQL et de les réutiliser :
-- Example helpers
create function app_user_id() returns uuid
language sql stable as $$
select current_setting('app.user_id', true)::uuid
$$;
create function app_is_admin() returns boolean
language sql stable as $$
select current_setting('app.is_admin', true) = 'true'
$$;
Les lectures sont souvent plus larges que les écritures. Par exemple, tout membre d'une org peut SELECT des projets, mais seuls les éditeurs peuvent UPDATE, et seuls les propriétaires peuvent DELETE.
Rendez cela explicite : une politique pour SELECT (appartenance), une pour INSERT/UPDATE avec WITH CHECK (rôle), et une pour DELETE (souvent plus stricte que update).
Évitez de « désactiver RLS pour les admins ». Ajoutez plutôt une sortie d'urgence dans les politiques, comme app_is_admin(), afin de ne pas accorder accidentellement un accès total à un rôle de service partagé.
Si vous utilisez deleted_at ou status, intégrez‑les dans la politique SELECT (deleted_at is null). Sinon, quelqu'un peut « ressusciter » des lignes en changeant des flags que l'app considérait comme finaux.
WITH CHECK compatibleINSERT ... ON CONFLICT DO UPDATE doit satisfaire WITH CHECK pour la ligne après l'écriture. Si votre politique exige created_by = app_user_id(), assurez‑vous que votre upsert définit created_by à l'insertion et ne l'écrase pas lors de la mise à jour.
Si vous générez du code backend, ces schémas valent la peine d'être transformés en templates internes pour que les nouvelles tables démarrent avec des valeurs sûres par défaut au lieu d'une ardoise vierge.
RLS est génial jusqu'à ce qu'un petit détail fasse ressembler PostgreSQL à « maculer » ou afficher des données de façon aléatoire. Les erreurs ci‑dessous font perdre le plus de temps.
Le premier piège est d'oublier WITH CHECK sur insert et update. USING contrôle ce que vous pouvez voir, pas ce que vous êtes autorisé à créer ou modifier. Sans WITH CHECK, un bug applicatif peut écrire une ligne dans le mauvais tenant, et vous ne le remarquez peut‑être pas parce que cet utilisateur ne peut pas relire la ligne.
Un autre fuite commune est la « jointure qui fuit ». Vous filtrez correctement projects, puis joignez invoices, notes ou files qui ne sont pas protégés de la même manière. La solution est stricte mais simple : chaque table qui peut révéler des données tenant a besoin de sa propre politique, et les vues ne doivent pas dépendre du fait qu'une seule table soit sûre.
Les schémas d'échec fréquents apparaissent tôt :
WITH CHECK.Les politiques qui référencent la même table (directement ou via une vue) peuvent créer des surprises de récursion. Une politique peut vérifier l'appartenance en interrogeant une vue qui lit de nouveau la table protégée, provoquant des erreurs, des requêtes lentes ou une politique qui ne correspond jamais.
La configuration des rôles est une autre source de confusion. Les propriétaires de table et les rôles élevés peuvent contourner RLS, donc vos tests passent tandis que les utilisateurs réels échouent (ou inversement). Testez toujours avec le même rôle faiblement privilégié que votre app utilise.
Soyez prudent avec les fonctions SECURITY DEFINER. Elles s'exécutent avec les privilèges du propriétaire de la fonction, donc un helper comme current_tenant_id() peut aller, mais une « fonction de commodité » qui lit des données peut accidentellement lire à travers les tenants à moins que vous la conceviez pour respecter RLS.
Définissez aussi un search_path sûr à l'intérieur des fonctions security definer. Sinon, la fonction peut utiliser un objet différent avec le même nom, et votre logique de politique peut pointer silencieusement sur la mauvaise chose selon l'état de la session.
Les bugs RLS sont généralement dus à un contexte manquant, pas à du « mauvais SQL ». Une politique peut être correcte sur le papier et échouer parce que le rôle de session est différent de ce que vous pensez, ou parce que la requête n'a jamais défini les valeurs tenant et utilisateur sur lesquelles la politique compte.
Une façon fiable de reproduire un rapport de production est de reproduire la même configuration de session localement et d'exécuter la requête exacte. Cela signifie généralement :
SET ROLE app_user; (ou le vrai rôle API)SELECT set_config('app.tenant_id', 't_123', true); et SELECT set_config('app.user_id', 'u_456', true);SELECT current_user, current_setting('app.tenant_id', true), current_setting('app.user_id', true);Quand vous ne savez pas quelle politique est appliquée, inspectez le catalogue au lieu de deviner. pg_policies montre chaque politique, la commande et les expressions USING et WITH CHECK. Associez cela à pg_class pour confirmer que RLS est activé sur la table et non contourné.
Les problèmes de performance peuvent ressembler à des problèmes d'auth. Une politique qui joint une table d'appartenance ou appelle une fonction peut être correcte mais lente une fois que la table grandit. Utilisez EXPLAIN (ANALYZE, BUFFERS) sur la requête reproduite et cherchez des scans séquentiels, des nested loops inattendus ou des filtres appliqués tardivement. Les index manquants sur (tenant_id, user_id) et sur les tables d'appartenance sont des causes courantes.
Il aide aussi de logger trois valeurs par requête au niveau applicatif : l'id du tenant, l'id de l'utilisateur et le rôle DB utilisé pour la requête. Quand ces valeurs ne correspondent pas à ce que vous pensez avoir défini, RLS se comportera « mal » parce que les entrées sont fausses.
Pour les tests, gardez quelques tenants seedés et rendez les échecs explicites. Un petit jeu de tests inclut généralement : « Tenant A ne peut pas lire Tenant B », « un utilisateur sans appartenance ne voit pas le projet », « le propriétaire peut mettre à jour, le viewer ne peut pas », « l'insert est bloqué à moins que tenant_id corresponde au contexte », et « l'override admin s'applique seulement là où prévu ».
Traitez RLS comme une ceinture de sécurité, pas comme un toggle. De petites erreurs se transforment en « tout le monde voit les données de tout le monde » ou « tout renvoie zéro ligne ».
Assurez‑vous que le design des tables et les règles de politique correspondent à votre modèle de tenant.
tenant_id). Si ce n'est pas le cas, notez pourquoi (par exemple tables de référence globales).FORCE ROW LEVEL SECURITY sur ces tables.USING. Les écritures doivent avoir WITH CHECK pour empêcher l'insertion/mise à jour dans un autre tenant.tenant_id ou joignent des tables d'appartenance, ajoutez les index correspondants.Un scénario de sanity simple : un utilisateur du tenant A peut lire ses propres factures, peut insérer une facture seulement pour le tenant A, et ne peut pas mettre à jour une facture pour changer tenant_id.
RLS n'est aussi fort que les rôles que votre app utilise.
bypassrls.Imaginez une app B2B où des entreprises (orgs) ont des projets, et les projets ont des tâches. Les utilisateurs peuvent appartenir à plusieurs orgs, et un utilisateur peut être membre de certains projets mais pas d'autres. C'est un bon cas pour RLS car la base de données peut imposer l'isolation des tenants même si un endpoint oublie un filtre.
Un modèle simple : orgs, users, org_memberships (org_id, user_id, role), projects (id, org_id), project_memberships (project_id, user_id), tasks (id, project_id, org_id, ...). Ce org_id sur tasks est intentionnel. Il garde les politiques simples et réduit les surprises lors des jointures.
Une fuite classique arrive quand tasks n'a que project_id, et votre politique vérifie l'accès via une jointure sur projects. Une erreur (une politique permissive sur projects, une jointure qui supprime une condition, ou une vue qui change le contexte) peut exposer des tasks d'une autre org.
Un chemin de migration plus sûr évite de casser le trafic de production :
org_id à tasks, ajoutez les tables d'appartenance).tasks.org_id depuis projects.org_id, puis ajoutez NOT NULL.L'accès support est généralement mieux géré avec un rôle étroit de break‑glass, pas en désactivant RLS. Gardez‑le séparé des comptes support normaux et rendez explicite son utilisation.
Documentez les règles pour éviter la dérive des politiques : quelles variables de session doivent être définies (user_id, org_id), quelles tables doivent porter org_id, ce que signifie « membre », et quelques exemples SQL qui doivent renvoyer 0 lignes lorsqu'ils sont exécutés avec le mauvais org.
RLS est plus facile à vivre quand vous le traitez comme un changement produit. Déployez par petits pas, prouvez le comportement avec des tests, et conservez un historique clair des raisons de chaque politique.
Un plan de déploiement qui fonctionne souvent :
projects) et verrouillez‑la.Après que la première table soit stable, rendez les changements de politiques délibérés. Ajoutez une étape de revue des politiques aux migrations, et incluez une courte note d'intention (qui doit accéder à quoi et pourquoi) plus la mise à jour du test correspondant. Cela empêche les politiques du type « ajoutez un OR de plus » qui se transforment lentement en trou.
Si vous avancez vite, des outils comme Koder.ai (koder.ai) peuvent vous aider à générer une base Go + PostgreSQL via chat, puis vous superposez des politiques RLS et des tests avec la même discipline qu'un backend fait main.
Enfin, gardez des garde‑fous pendant le déploiement : prenez des snapshots avant les migrations de politique, entraînez les rollbacks jusqu'à ce que ce soit routinier, et conservez un petit chemin de break‑glass pour le support qui n'opère pas en désactivant RLS pour tout le système.
RLS fait en sorte que PostgreSQL impose quelles lignes sont visibles ou modifiables pour une requête, de sorte que l'isolation des tenants ne dépende pas de chaque endpoint qui se souvienne du bon filtre WHERE tenant_id = .... L'avantage principal est de réduire les bugs du type « un contrôle oublié » lorsque votre application grandit et que les requêtes se multiplient.
Ça vaut le coup lorsque les règles d'accès sont cohérentes et basées sur les lignes, comme l'isolation par tenant ou l'accès basé sur l'appartenance, et que vous avez beaucoup de chemins de requête (recherche, exports, écrans admin, jobs). Ce n'est généralement pas recommandé si la plupart des règles sont par-champ, très exceptionnelles, ou dominées par des rapports larges nécessitant des lectures cross-tenant.
Utilisez RLS pour la visibilité au niveau des lignes et le contrôle d'écriture de base, puis complétez avec d'autres outils pour le reste. La confidentialité des colonnes nécessite généralement des vues et des privilèges de colonne, et les règles métier complexes (ex. propriété de facturation ou processus d'approbation) restent du ressort de la logique applicative ou de contraintes de base de données bien conçues.
Créez un rôle faiblement privilégié pour l'API (pas le propriétaire de table), activez RLS, puis ajoutez une politique SELECT et une politique INSERT/UPDATE avec WITH CHECK. Définissez une valeur de session par requête (comme app.current_tenant) et vérifiez que la bascule change les lignes visibles et modifiables.
Un choix courant est une variable de session par requête, définie au début de la transaction, par exemple app.tenant_id et app.user_id. L'important est la cohérence : tous les chemins de code (requêtes web, jobs, scripts) doivent définir les mêmes valeurs que les politiques attendent, sinon vous aurez des comportements « zéro ligne » déroutants.
USING contrôle le filtre en lecture. Si une ligne ne correspond pas à USING, elle est invisible pour SELECT et ne peut pas être ciblée par UPDATE ou DELETE. WITH CHECK est la barrière d'écriture : elle décide quelles nouvelles ou modifiées lignes sont autorisées lors d'un ou , empêchant notamment d'injecter une ligne dans un autre tenant.
Parce que si vous n'ajoutez que USING, un endpoint bogué peut toujours insérer ou mettre à jour des lignes dans le mauvais tenant, et vous ne le remarquerez peut‑être pas puisque le même utilisateur ne pourra pas relire la ligne erronée. Associez toujours les règles de lecture par tenant à une règle WITH CHECK correspondante pour les écritures afin d'empêcher les mauvaises données à la source.
Évitez les jointures dans les politiques en plaçant la clé tenant (ex. org_id) directement sur les tables appartenant au tenant, même si elles référencent une autre table qui la contient. Ajoutez des tables d'appartenance explicites (org_memberships, éventuellement project_memberships) afin que les politiques puissent faire une seule recherche indexée plutôt qu'une inférence compliquée.
Reproduisez d'abord le même contexte de session que votre application en définissant le même rôle et les mêmes paramètres de session, puis exécutez exactement la même requête SQL. Ensuite, confirmez que RLS est activé et inspectez pg_policies pour voir quelles expressions USING et WITH CHECK sont appliquées : les problèmes RLS viennent souvent d'un contexte d'identité manquant plutôt que d'un « mauvais SQL ». Pour la performance, utilisez EXPLAIN (ANALYZE, BUFFERS) pour détecter des scans séquentiels ou des boucles inattendues.
Oui, mais considérez le code généré comme un point de départ, pas comme un système de sécurité complet. Si vous utilisez Koder.ai pour générer un backend Go + PostgreSQL, vous devez toujours définir votre modèle de tenant, définir l'identité de session de façon cohérente, et ajouter politiques et tests délibérément pour que les nouvelles tables ne soient pas livrées sans protections appropriées.
INSERTUPDATE