22 sept. 2025·7 min
Conserver le code généré maintenable : la règle de l'architecture sobre
Apprenez à garder le code généré maintenable avec la règle de l'architecture sobre : frontières de dossiers claires, conventions de nommage cohérentes et valeurs par défaut simples qui réduisent le travail futur.
Pourquoi la maintenabilité est plus difficile avec du code généré
Le code généré change la routine. Vous ne faites plus que développer des fonctionnalités : vous guidez un système capable de créer beaucoup de fichiers rapidement. La vitesse est réelle, mais de petites incohérences se multiplient vite.
Le résultat généré peut sembler correct isolément. Les coûts apparaissent lors du deuxième ou troisième changement : on ne sait plus où une partie appartient, on corrige le même comportement à deux endroits, ou on évite de toucher un fichier par peur d'impacter autre chose.
La « créativité » structurelle coûte cher parce qu’elle est imprévisible. Des patterns personnalisés, de la magie cachée et de l’abstraction poussent font sens le premier jour. À la sixième semaine, la modification suivante ralenti parce qu’il faut réapprendre l’astuce avant de la modifier en toute sécurité. Avec la génération assistée par IA, cette complexité peut aussi embrouiller les générations futures et conduire à de la logique dupliquée ou à des couches empilées.
L’architecture sobre est l’inverse : des frontières claires, des noms simples et des valeurs par défaut évidentes. Il ne s’agit pas de perfection, mais de choisir une organisation que même un coéquipier fatigué (ou vous dans le futur) comprendra en 30 secondes.
Un objectif simple : rendre la prochaine modification facile, pas impressionnante. Concrètement, cela signifie souvent un seul emplacement clair pour chaque type de code (UI, API, données, utilitaires partagés), des noms prévisibles qui décrivent la fonction d’un fichier, et un minimum de « magie » comme de l’auto-wiring, des globals cachés ou de la métaprogrammation.
Par exemple : si vous demandez à Koder.ai d’ajouter les « invitations d’équipe », vous voulez qu’il place l’UI dans la zone UI, ajoute une route API dans la zone API, et stocke les données d’invitation dans la couche données, sans inventer un nouveau dossier ou pattern juste pour cette fonctionnalité. Cette cohérence « ennuyeuse » est ce qui rend les modifications futures peu coûteuses.
La règle de l’architecture sobre
Le code généré devient coûteux quand il offre plusieurs façons de faire la même chose. La règle est simple : rendez la prochaine modification prévisible, même si la première version paraît moins « astucieuse ».
Vous devriez pouvoir répondre rapidement à ces questions :
- Où vit cette fonctionnalité ?
- Où je place un nouveau fichier ?
- Comment dois‑je le nommer ?
- Quel est le chemin le plus simple de l’UI aux données ?
La règle
Choisissez une structure simple et appliquez‑la partout. Quand un outil (ou un coéquipier) propose un pattern sophistiqué, la réponse par défaut est « non », sauf si ça supprime une vraie douleur.
Valeurs par défaut pratiques qui tiennent dans le temps :
- Une responsabilité par dossier et par fichier. Si un fichier a deux raisons de changer, séparez‑le.
- La prévisibilité vaut mieux que la flexibilité. Le même type de chose va au même endroit, à chaque fois.
- Préférez l’approche standard de votre stack plutôt que des mini‑frameworks personnalisés.
- Rendez le chemin heureux évident. Les nouveaux contributeurs doivent deviner l’emplacement correct sans demander.
- Rejetez la « magie ». Évitez les comportements cachés, les astuces reposant sur la réflexion et les abstractions trop sophistiquées.
Un petit test mental
Imaginez qu’un nouveau développeur ouvre votre dépôt et doit ajouter un bouton « Annuler l’abonnement ». Il ne doit pas avoir à apprendre une architecture personnalisée d’abord. Il doit trouver une zone fonction claire, un composant UI, un client API unique et un chemin d’accès aux données unique.
Cette règle fonctionne particulièrement bien avec des outils de « vibe‑coding » comme Koder.ai : vous pouvez générer vite, mais vous guidez toujours la sortie pour qu’elle respecte les mêmes frontières sobres à chaque fois.
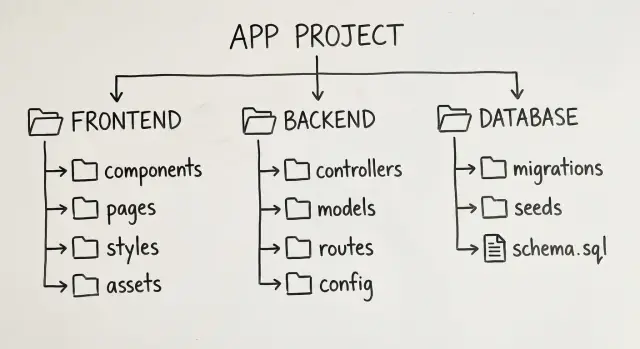
Frontières de dossiers simples qui montent en charge
Le code généré a tendance à grossir vite. La façon la plus sûre de le garder maintenable est une carte de dossiers ennuyeuse où n’importe qui peut deviner où placer un changement.
Une petite mise en page top‑niveau qui convient à beaucoup d’apps web :
app/écrans, routage et état au niveau pagecomponents/pièces UI réutilisablesfeatures/un dossier par fonctionnalité (billing, projects, settings)api/code client API et helpers de requêteserver/handlers backend, services et règles métier
Cela rend les frontières évidentes : l’UI vit dans app/ et components/, les appels API dans api/ et la logique backend dans server/.
L’accès aux données doit aussi rester ennuyeux. Gardez les requêtes SQL et le code des repositories côté backend, pas éparpillés dans des fichiers UI. Dans un setup Go + PostgreSQL, une règle simple est : les handlers HTTP appellent des services, les services appellent des repositories, les repositories parlent à la base de données.
Les types partagés et utilitaires méritent une maison claire, mais restez concis. Mettez les types transverses dans types/ (DTOs, enums, interfaces partagées) et les petits helpers dans utils/ (formatage de date, validateurs simples). Si utils/ commence à ressembler à une seconde application, le code appartient probablement plutôt à un dossier de fonctionnalité.
Généré vs écrit à la main
Traitez les dossiers générés comme remplaçables.
- Placez la sortie générée dans
generated/(ougen/) et évitez de l’éditer directement. - Gardez la logique custom dans
features/ouserver/pour que la régénération ne l’écrase pas. - Si vous devez patcher un comportement généré, encapsulez‑le (fichier adaptateur) plutôt que de modifier la source.
Exemple : si Koder.ai génère un client API, stockez‑le sous generated/api/, puis écrivez de minces wrappers dans api/ où vous pouvez ajouter des retries, du logging ou des messages d’erreur plus clairs sans toucher aux fichiers générés.
Conventions de nommage qui évitent la confusion
Le code généré se crée et s’empile facilement. Le nommage le rend lisible un mois plus tard.
Choisissez un style de nommage et ne le mélangez pas :
- Dossiers et fichiers :
kebab-case(user-profile-card.tsx,billing-settings) - Composants React :
PascalCase(UserProfileCard) - Fonctions et variables :
camelCase(getUserProfile) - Constantes :
SCREAMING_SNAKE_CASE(MAX_RETRY_COUNT)
Nommez par rôle, pas par implémentation actuelle. user-repository.ts décrit le rôle. postgres-user-repository.ts est un détail d’implémentation qui peut changer. N’utilisez un suffixe d’implémentation que quand vous avez vraiment plusieurs implémentations.
Évitez les tiroirs fourre‑tout comme misc, helpers ou un énorme utils. Si une fonction n’est utilisée que par une fonctionnalité, laissez‑la près de cette fonctionnalité. Si elle est partagée, faites que le nom décrive la capacité (date-format.ts, money-format.ts, id-generator.ts) et gardez le module petit.
Conventions qui accélèrent la navigation
Quand routes, handlers et composants suivent un pattern, vous trouvez les choses sans chercher :
- Routes :
routes/users.tsavec des chemins comme/users/:userId - Handlers (HTTP) :
handlers/users.get.ts,handlers/users.update.ts - Services (règles métier) :
services/user-profile-service.ts - Accès aux données :
repositories/user-repository.ts - Composants UI :
components/user/UserProfileCard.tsx
Si vous utilisez Koder.ai (ou tout générateur), mettez ces règles dans le prompt et gardez‑les cohérentes pendant les modifications. L’idée est la prévisibilité : si vous pouvez deviner le nom du fichier, les changements futurs restent peu coûteux.
Defaults sans astuce (règles pratiques)
Lancez sur votre propre domaine
Simplifiez les releases en publiant votre appli sur un domaine personnalisé une fois la structure stable.
Le code généré peut impressionner le premier jour et devenir pénible le trente‑ième. Choisissez des defaults qui rendent le code évident, même s’il est un peu répétitif.
Commencez par réduire la magie. Évitez le chargement dynamique, les astuces de style réflexion et l’auto‑wiring sauf besoin mesuré. Ces fonctionnalités cachent d’où viennent les choses, ce qui ralentit le debug et le refactor.
Privilégiez les imports explicites et des dépendances claires. Si un fichier a besoin de quelque chose, importez‑le directement. Si des modules doivent être câblés, faites‑le en un seul endroit visible (par exemple un fichier de composition). Un lecteur ne devrait pas avoir à deviner ce qui s’exécute en premier.
Centralisez la configuration et gardez‑la ennuyeuse. Placez variables d’environnement, feature flags et paramètres globaux dans un module unique avec un schéma de nommage clair. Ne dispersez pas la config dans des fichiers aléatoires parce que c’était pratique.
Règles pratiques pour garder l’équipe alignée :
- Choisir l’explicite plutôt que l’implicite (imports, routing, DI, effets secondaires).
- Si ça économise 10 lignes mais ajoute un nouveau concept, évitez‑le.
- Gardez une seule façon de faire les choses (un outil de logging, un module de config).
- Préférez un flux de données simple plutôt que des observers cachés ou des chaînes d’événements.
- Lors du debug, supprimez d’abord le code « astucieux ».
La gestion des erreurs est l’endroit où la créativité nuit le plus. Choisissez un pattern et appliquez‑le partout : retournez des erreurs structurées depuis la couche données, mappez‑les en réponses HTTP en un seul endroit, puis traduisez‑les en messages utilisateurs à la frontière UI. N’utilisez pas trois types d’erreurs différents selon le fichier.
Si vous générez une app avec Koder.ai, demandez ces defaults dès le départ : câblage explicite des modules, config centralisée et un seul pattern d’erreurs.
Frontières entre UI, API et données
Des lignes claires entre UI, API et données gardent les modifications contenues. La plupart des bugs mystérieux surviennent quand une couche commence à faire le travail d’une autre.
UI : afficher l’état, collecter les entrées
Traitez l’UI (souvent React) comme un endroit pour rendre des écrans et gérer l’état propre à l’interface : onglet ouvert, erreurs de formulaire, spinners de chargement et gestion basique des saisies.
Séparez l’état serveur : listes récupérées, profils en cache et tout ce qui doit correspondre au backend. Quand des composants UI commencent à calculer des totaux, valider des règles complexes ou décider des permissions, la logique se disperse et devient coûteuse à changer.
API : formes fines et stables
Gardez la couche API prévisible. Elle doit traduire les requêtes HTTP en appels au code métier, puis traduire les résultats en formes request/response stables. Évitez d’envoyer des modèles de base de données directement sur le réseau. Des réponses stables vous permettent de refactorer l’intérieur sans casser l’UI.
Un chemin simple qui marche bien :
- L’UI appelle un client API avec des objets request/response typés.
- Les handlers API valident l’entrée et appellent une méthode de service.
- Les services contiennent les règles métier et les workflows.
- Les repositories cachent les requêtes DB derrière de petites méthodes.
Données : cachez les requêtes derrière des repositories
Mettez le SQL (ou la logique ORM) derrière une frontière repository pour que le reste de l’app ne « sache » pas comment les données sont stockées. En Go + PostgreSQL, cela signifie généralement des repositories comme UserRepo ou InvoiceRepo avec de petites méthodes claires (GetByID, ListByAccount, Save).
Exemple concret : ajout de codes de réduction. L’UI affiche un champ et met à jour le prix. L’API accepte code et renvoie {total, discount}. Le service décide si le code est valide et comment les remises se cumulent. Le repository va chercher et persiste les lignes nécessaires.
Étape par étape : préparer du code généré maintenable
Les apps générées peuvent sembler « finies » rapidement, mais c’est la structure qui maintient les changements peu coûteux. Décidez d’abord des règles ennuyeuses, puis générez juste assez de code pour les prouver.
Un flux de mise en place pratique
Commencez par une courte étape de planification. Si vous utilisez Koder.ai, le Planning Mode est un bon endroit pour écrire une carte de dossiers et quelques règles de nommage avant de générer quoi que ce soit.
Ensuite suivez cette séquence :
- Définissez la carte et les règles par écrit. Choisissez les frontières (par exemple :
ui/,api/,data/,features/) et quelques règles de nommage. - Générez une fine tranche verticale. Choisissez une petite fonctionnalité qui touche UI, API et stockage, comme « créer un contact ». L’objectif est le chemin de bout en bout, pas l’exhaustivité.
- Refactorez immédiatement pour respecter les frontières. Déplacez le code dans les dossiers planifiés, renommez les fichiers peu clairs et supprimez les doublons. Séparez les fonctions polyvalentes en UI, handler et accès aux données.
- Ajoutez une deuxième fonctionnalité pour tester la forme. Choisissez quelque chose de similaire, comme « lister les contacts ». Si vous êtes forcé de casser vos règles, les frontières sont probablement mal choisies.
- Verrouillez les conventions tôt. Ajoutez un court
CONVENTIONS.mdet considérez‑le comme un contrat. Une fois la base de code grande, changer noms et map de dossiers devient coûteux.
Contrôle réalité : si une nouvelle personne ne peut pas deviner où placer « modifier un contact » sans demander, l’architecture n’est pas encore assez sobre.
Scénario d’exemple : ajouter une fonctionnalité sans faire de bazar
Refactorez sans crainte
Expérimentez la structure en toute sécurité avec des snapshots et un rollback si un refactor tourne mal.
Imaginez un CRM simple : une page liste de contacts et un formulaire d’édition de contact. Vous construisez la première version vite, puis une semaine plus tard vous devez ajouter des « tags » aux contacts.
Traitez l’app comme trois boîtes sobres : UI, API et données. Chaque boîte a des frontières claires et des noms littéraux pour que le changement « tags » reste petit.
Une mise en page propre pourrait ressembler à :
web/src/pages/ContactsPage.tsxetweb/src/components/ContactForm.tsxserver/internal/http/contacts_handlers.goserver/internal/service/contacts_service.goserver/internal/repo/contacts_repo.goserver/migrations/
Maintenant « tags » devient prévisible. Mettez à jour le schéma (nouvelle table contact_tags ou une colonne tags), puis touchez couche par couche : le repo lit/écrit les tags, le service valide, le handler expose le champ, l’UI l’affiche et l’édite. Ne glissez pas de SQL dans les handlers ni de règles métier dans les composants React.
Pour les tests et fixtures, gardez‑les petits et proches du code :
server/internal/service/contacts_service_test.gopour des règles comme « les noms de tag doivent être uniques par contact »server/internal/repo/testdata/pour des fixtures minimalesweb/src/components/__tests__/ContactForm.test.tsxpour le comportement du formulaire
Si vous générez cela avec Koder.ai, la même règle s’applique après export : gardez les dossiers ennuyeux, gardez les noms littéraux, et les modifications ne ressemblent plus à de l’archéologie.
Erreurs courantes qui rendent les changements futurs coûteux
Le code généré peut sembler propre le premier jour et rester coûteux plus tard. Le coupable habituel n’est pas le « mauvais code », mais l’incohérence.
Une habitude coûteuse est de laisser le générateur inventer la structure à chaque fois. Une fonctionnalité débarque avec ses propres dossiers, style de nommage et helpers, et vous vous retrouvez avec trois façons de faire la même chose. Choisissez un pattern, écrivez‑le et traitez tout nouveau pattern comme un changement conscient, pas comme la valeur par défaut.
Un autre piège est le mélange des couches. Quand un composant UI parle à la base de données, ou qu’un handler API construit du SQL, les petits changements deviennent des éditions risquées sur toute l’app. Gardez la frontière : l’UI appelle une API, l’API appelle un service, le service appelle l’accès aux données.
Abuser des abstractions génériques trop tôt ajoute aussi du coût. Un « BaseService » universel ou un framework de Repository semble propre, mais les abstractions précoces sont des suppositions. Quand la réalité change, vous vous battez contre votre propre framework au lieu d’expédier.
Le renommage et la réorganisation constants sont une dette plus discrète. Si les fichiers bougent chaque semaine, les gens cessent de faire confiance à la structure et des fix rapides atterrissent n’importe où. Stabilisez la carte de dossiers d’abord, puis refactorez par étapes planifiées.
Enfin, méfiez‑vous du « code plateforme » sans réel utilisateur. Les bibliothèques partagées et outils maison ne valent le coup que si vous avez des besoins répétés et prouvés. Jusqu’à là, gardez les defaults directs.
Une checklist rapide avant de livrer
Créez une fondation CRM sobre
Transformez un cahier des charges clair en une application React avec backend Go + PostgreSQL dans Koder.ai.
Si quelqu’un de neuf ouvre le repo, il doit pouvoir répondre rapidement à la question : « Où j’ajoute ça ? »
Test de navigation en 2 minutes
Donnez le projet à un coéquipier (ou au vous du futur) et demandez‑lui d’ajouter une petite fonctionnalité, comme « ajouter un champ au formulaire d’inscription ». S’il ne trouve pas rapidement l’emplacement, la structure ne fait pas son travail.
Vérifiez trois maisons claires :
- Les changements UI vivent dans un endroit évident.
- Les routes/handlers API sont faciles à retrouver depuis l’UI.
- Le modèle de données et les changements DB ont un emplacement clair.
Règles à faire respecter en review
- UI, API et données ont chacun un domicile, et les exceptions sont rares.
- Les noms se lisent comme des étiquettes, pas des puzzles.
- Les ruptures de couche sont signalées (par exemple UI qui accède à la DB).
- Les raccourcis astucieux sont rejetés par défaut.
Si votre plateforme le permet, maintenez une voie de rollback. Les snapshots et le rollback sont particulièrement utiles quand vous expérimentez la structure et que vous voulez un moyen sûr de revenir en arrière.
Prochaines étapes : restez sobre, gardez le coût bas
La maintenabilité s’améliore le plus quand vous cessez de débattre du style et commencez à prendre quelques décisions qui tiennent. Écrivez un petit ensemble de conventions qui suppriment l’hésitation quotidienne : où vont les fichiers, comment ils sont nommés, et comment gérer erreurs et config. Gardez‑le court, lisible en une minute.
Faites ensuite une passe de nettoyage pour aligner le code sur ces règles et arrêtez de remanier chaque semaine. Réorganiser constamment ralentit la prochaine modification, même si le code semble plus joli.
Si vous construisez avec Koder.ai (koder.ai), sauvegardez ces conventions comme prompt de départ pour que chaque génération atterrisse dans la même structure. L’outil peut aller vite, mais ce sont les frontières sobres qui rendent le code facile à changer.