Mise à l’échelle en langage clair
Mise à l’échelle signifie « traiter plus sans s’effondrer ». Ce « plus » peut être :
- Plus d’utilisateurs utilisant le produit en même temps
- Plus de requêtes API par seconde
- Plus de données stockées et interrogées
- Plus de tâches en arrière-plan (emails, traitement vidéo, rapports)
Quand on parle de mise à l’échelle, on cherche généralement à améliorer un ou plusieurs de ces points :
- Capacité : combien de trafic ou de données le système peut gérer.
- Vitesse : la rapidité de réponse sous charge.
- Fiabilité : la capacité à rester opérationnel quand quelque chose casse.
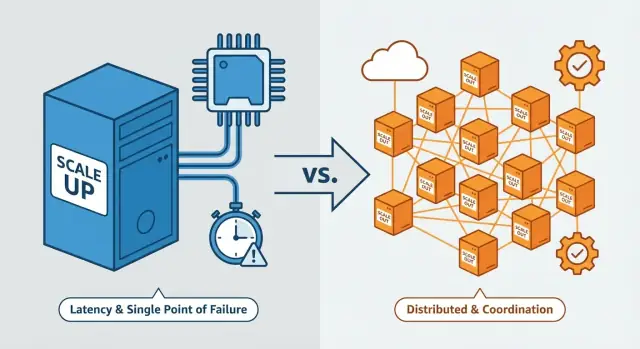
Tout cela revient à un thème central : monter en puissance (scale up) préserve la sensation d’un “système unique”, tandis que la mise à l’échelle horizontale transforme votre système en un groupe coordonné de machines indépendantes — et c’est la coordination qui fait exploser la difficulté.
Vertical vs. Horizontal (définitions rapides)
Mise à l’échelle verticale (scale up)
La mise à l’échelle verticale consiste à rendre une machine plus puissante. Vous conservez la même architecture de base, mais vous mettez à niveau le serveur (ou la VM) : plus de cœurs CPU, plus de RAM, des disques plus rapides, un débit réseau supérieur.
Pensez-y comme acheter un plus gros camion : un seul conducteur et un seul véhicule, mais qui transporte plus.
Mise à l’échelle horizontale (scale out)
La mise à l’échelle horizontale consiste à ajouter plus de machines ou d’instances et à répartir le travail entre elles — souvent derrière un équilibreur de charge. Au lieu d’un seul serveur plus puissant, vous exécutez plusieurs serveurs qui coopèrent.
C’est comme utiliser plusieurs camions : vous pouvez déplacer plus de marchandise, mais vous devez gérer la planification, l’acheminement et la coordination.
Qu’est-ce qui déclenche généralement la question ?
Déclencheurs courants :
- Pics de trafic (campagnes marketing, saisonnalité, croissance virale)
- Croissance soutenue du produit sur plusieurs mois ou années
- Jeux de données plus volumineux (plus de clients, plus d’événements, plus d’historique à stocker)
Une nuance importante : la plupart des systèmes réels utilisent les deux
Les équipes montent souvent en puissance d’abord parce que c’est rapide (upgrader la machine), puis passent à l’horizontal quand une seule machine atteint ses limites ou qu’elles ont besoin d’une disponibilité plus élevée. Les architectures matures combinent généralement les deux : des nœuds plus gros et plus nombreux, selon le goulot.