27 août 2025·8 min
Pools de workers Go pour les tâches en arrière-plan : réessais, annulation et arrêt propre
Les worker pools Go aident les petites équipes à exécuter des tâches en arrière-plan avec réessais, annulation et arrêt propre en utilisant des patterns simples avant d’ajouter une infrastructure lourde.
Pourquoi les tâches en arrière-plan deviennent vite compliquées
Dans un petit service Go, le travail en arrière-plan commence souvent par un objectif simple : renvoyer la réponse HTTP rapidement, puis faire le travail lent après. Il peut s’agir d’envoyer des e-mails, de redimensionner des images, de synchroniser avec une autre API, de reconstruire des index de recherche ou de lancer des rapports nocturnes.
Le problème, c’est que ces tâches sont du vrai travail en production, simplement sans les protections dont bénéficie une requête HTTP. Une goroutine lancée depuis un handler semble suffisante jusqu’à ce qu’un déploiement survienne en plein milieu d’une tâche, qu’une API en amont ralentisse, ou que la même requête soit relancée et déclenche la tâche deux fois.
Les premières douleurs sont prévisibles :
- Tâches bloquées : un appel se fige et les workers ne progressent plus.
- Travail dupliqué : des réessais au niveau HTTP relancent la même tâche.
- Pas de plan d’arrêt : le processus se termine et le travail est perdu ou à moitié fait.
- Échecs silencieux : les erreurs sont loguées une fois (ou pas du tout) et disparaissent.
- Vagues de réessais : des tâches en échec se réessaient instantanément et surchargent les dépendances.
C’est là qu’un petit pattern explicite comme un worker pool Go devient utile. Il fait de la concurrence un choix (N workers), transforme « faire plus tard » en un type de tâche clair, et vous donne un seul endroit pour gérer les réessais, les timeouts et l’annulation.
Exemple : une application SaaS doit envoyer des factures. Vous ne voulez pas 500 envois simultanés après une importation par lot, ni renvoyer la même facture parce qu’une requête a été réessayée. Un worker pool vous permet de limiter le débit et de traiter « envoyer la facture #123 » comme une unité de travail suivie.
Un worker pool n’est pas l’outil adapté quand vous avez besoin de garanties durables et multi-processus. Si les tâches doivent survivre aux crashs, être planifiées pour plus tard, ou être traitées par plusieurs services, vous aurez probablement besoin d’une vraie file avec stockage persistant de l’état des tâches.
Le modèle du worker pool en clair
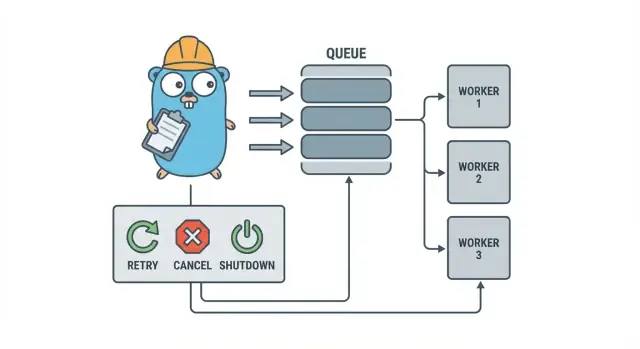
Un worker pool Go est volontairement simple : placez le travail dans une file, ayez un nombre fixe de workers qui le prennent, et assurez-vous que tout peut s’arrêter proprement.
Les termes de base :
- Job : une unité de travail, comme « redimensionner cette image » ou « envoyer cet e-mail de facture ».
- File (Queue) : où les jobs attendent.
- Worker : une goroutine qui prend un job et l’exécute en boucle.
- Dispatcher : la partie qui accepte les jobs et les met dans la file.
Dans de nombreuses architectures en processus, un canal Go (channel) sert de file. Un channel bufferisé peut contenir un nombre limité de jobs avant que les producteurs ne bloquent. Ce blocage est du backpressure, et c’est souvent ce qui empêche votre service d’accepter un travail illimité et d’épuiser la mémoire lors d’un pic de trafic.
La taille du buffer change la sensation du système. Un petit buffer rend la pression visible rapidement (les appelants attendent plus tôt). Un buffer plus grand lisse les pics courts mais peut masquer la surcharge jusqu’à plus tard. Il n’y a pas de nombre parfait, seulement un nombre qui correspond à la quantité d’attente que vous pouvez tolérer.
Vous choisissez aussi si la taille du pool est fixe ou peut varier. Les pools fixes sont plus faciles à comprendre et gardent l’utilisation des ressources prévisible. Des workers auto-scalés peuvent aider avec une charge irrégulière, mais ajoutent des décisions à maintenir (quand scaler, de combien, et quand réduire).
Enfin, « ack » dans un pool en processus signifie généralement « le worker a fini le job et n’a pas retourné d’erreur ». Il n’y a pas de broker externe pour confirmer la livraison, donc votre code définit ce que « terminé » signifie et ce qui arrive quand un job échoue ou est annulé.
Objectifs de conception : réessais, annulation et arrêt propre
Un worker pool est simple mécaniquement : lancer un nombre fixe de workers, leur fournir des jobs et les traiter. La valeur se situe dans le contrôle : une concurrence prévisible, une gestion claire des échecs et un chemin d’arrêt qui ne laisse pas de travail à moitié fait.
Trois objectifs aident les petites équipes à rester raisonnables :
- Limiter la concurrence pour qu’un pic ne grille pas votre base de données ou une API externe.
- Éviter de perdre du travail (ou au moins savoir exactement ce qui a été abandonné et pourquoi).
- Rester débogable : chaque job doit pouvoir être tracé via les logs et quelques compteurs.
La plupart des échecs sont ennuyeux, mais vous voulez tout de même les traiter différemment :
- Erreurs transitoires (coups de réseau, limites de débit) qui méritent un réessai.
- Erreurs permanentes (entrée invalide, enregistrement manquant) qui ne doivent pas être réessayées.
- Timeouts (une dépendance bloque) qui doivent être interrompus pour ne pas encombrer les workers.
L’annulation n’est pas la même chose qu’une « erreur ». C’est une décision : un utilisateur a annulé, un déploiement a remplacé votre processus, ou votre service est en arrêt. En Go, traitez l’annulation comme un signal de première classe via context cancellation, et faites en sorte que chaque job le vérifie avant de démarrer un travail coûteux et à quelques points sûrs pendant l’exécution.
L’arrêt propre est l’endroit où beaucoup de pools échouent. Décidez tôt de ce que « sûr » signifie pour vos jobs : terminez-vous le travail en cours, ou arrêtez-vous rapidement et ré-exécutez plus tard ? Un flux pratique est :
- Arrêter d’accepter de nouveaux jobs.
- Dire aux workers d’arrêter après leur job en cours (ou d’arrêter immédiatement).
- Attendre jusqu’à une échéance, puis forcer la sortie.
Si vous définissez ces règles tôt, réessais, annulation et arrêt restent petits et prévisibles au lieu de se transformer en un framework maison.
Pas à pas : construire un worker pool basique
Un worker pool n’est que des goroutines qui prennent des jobs depuis un channel et les exécutent. L’important est de rendre les fondamentaux prévisibles : à quoi ressemble un job, comment les workers s’arrêtent, et comment savoir quand tout le travail est terminé.
Commencez par un type Job simple. Donnez-lui un ID (pour les logs), une payload (ce qu’il faut traiter), un compteur d’essais (utile pour les réessais), des timestamps et un endroit pour stocker un contexte par job.
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := &Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i < size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case <-p.ctx.Done():
return
case job, ok := <-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case <-p.ctx.Done():
return context.Canceled
case p.jobs <- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
Quelques choix pratiques que vous ferez tout de suite :
- Choisir une taille de file selon ce que vous pouvez tolérer en attente.
- Décider ce que signifie le backpressure pour les appelants : bloquer, retourner une erreur ou abandonner.
- Garder
Stop()etWait()séparés pour pouvoir arrêter l’entrée d’abord, puis attendre la fin des travaux en cours.
Ajouter des réessais sans en faire un framework
Les réessais sont utiles, mais c’est aussi là que les worker pools deviennent confus. Gardez l’objectif étroit : ne réessayer que quand une nouvelle tentative a une vraie chance de réussir, et arrêter rapidement quand ce n’est pas le cas.
Commencez par décider ce qui est réessayable. Les problèmes temporaires (coups de réseau, timeouts, réponses « réessayer plus tard ») valent généralement un réessai. Les problèmes permanents (entrée invalide, enregistrement manquant, accès refusé) ne le sont pas.
Une petite politique de réessai suffit souvent :
- Marquer les erreurs comme réessayables ou non réessayables (par exemple, envelopper avec un helper
Retryable(err)). - Fixer un nombre maximal de tentatives (souvent 3 à 5). Passé ce seuil, vous perdez du temps.
- Utiliser un backoff exponentiel avec jitter pour éviter que les jobs ne se réessaient en synchro.
- Limiter le délai (par exemple, ne jamais dormir plus de 30 secondes).
- Logger les réessais avec le numéro de tentative, le délai suivant et l’ID du job.
Le backoff n’a pas besoin d’être compliqué. Une forme courante est : delay = min(base * 2^(attempt-1), max), puis ajouter du jitter (randomiser de +/- 20 %). Le jitter compte parce que sinon beaucoup de workers échouent ensemble et se réessaient ensemble.
Où mettre le délai ? Pour les petits systèmes, dormir dans le worker est acceptable, mais cela bloque un slot worker. Si les réessais sont rares, c’est tolérable. Si les réessais sont fréquents ou si les délais sont longs, envisagez de ré-enfiler le job avec un timestamp de « run after » pour que les workers restent occupés.
Sur l’échec final, soyez explicite. Conservez le job échoué (et la dernière erreur) pour examen, loggez suffisamment de contexte pour le rejouer, ou placez-le dans une liste morte que vous consultez régulièrement. Évitez les abandons silencieux. Un pool qui cache les échecs est pire que pas de réessais du tout.
Annulation et timeouts qui stoppent réellement le travail
Sauvegarder avant d'ajuster la concurrence
Sauvegardez un snapshot avant de changer les paramètres de concurrence, puis revenez en arrière en toute sécurité.
Les worker pools ne semblent sûrs que lorsque vous pouvez les arrêter. La règle la plus simple : passez un context.Context à chaque couche susceptible de bloquer. Cela signifie la soumission, l’exécution et le nettoyage.
Un arrangement pratique utilise deux limites temporelles :
- Un timeout par job pour qu’une tâche ne monopolisent pas un worker indéfiniment.
- Un timeout d’arrêt pour que le processus puisse quitter même si certaines tâches ne coopèrent pas.
Utiliser le context de bout en bout
Donnez à chaque job son propre contexte dérivé du contexte du worker. Ensuite, chaque appel lent (base de données, HTTP, files, I/O) doit utiliser ce contexte pour pouvoir retourner tôt.
func worker(ctx context.Context, jobs <-chan Job) {
for {
select {
case <-ctx.Done():
return
case job, ok := <-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
Si Run appelle votre base de données ou une API, transmettez le contexte à ces appels (par ex. QueryContext, NewRequestWithContext, ou des méthodes client acceptant context). Si vous l’ignorez à un endroit, l’annulation devient « best effort » et échoue généralement quand vous en avez le plus besoin.
Travail partiel et étapes « sûres à réessayer »
L’annulation peut arriver en milieu de job, donc supposez que le travail partiel est normal. Visez des étapes idempotentes pour que les reruns ne créent pas de doublons. Approches courantes : utiliser des clés uniques pour les insertions (ou upserts), écrire des marqueurs de progression (started/done), stocker les résultats avant de continuer, et vérifier ctx.Err() entre les étapes.
Traitez l’arrêt comme une échéance : arrêtez d’accepter de nouveaux jobs, annulez les contexts des workers, et attendez seulement jusqu’au timeout d’arrêt pour que les jobs en cours se terminent.
Arrêt propre : que faire quand le processus doit s’arrêter
Un arrêt propre a un objectif : arrêter d’accepter du nouveau travail, dire au travail en cours de s’arrêter, et sortir sans laisser le système dans un état bizarre.
Commencez par les signaux. Dans la plupart des déploiements vous verrez SIGINT localement et SIGTERM depuis le gestionnaire de processus ou le runtime de conteneur. Utilisez un contexte d’arrêt qui est annulé à l’arrivée d’un signal, et passez-le à votre pool et aux handlers des jobs.
Ensuite, arrêtez d’accepter de nouveaux jobs. Ne laissez pas les appelants bloquer indéfiniment en essayant de soumettre à un channel que personne ne lit. Gardez la soumission derrière une fonction unique qui vérifie un flag « fermé » ou qui sélectionne sur le contexte d’arrêt avant d’envoyer.
Puis décidez ce qu’il advient du travail en file :
- Drainer : finir ce qui est déjà en file, mais refuser les nouvelles soumissions.
- Jeter : ignorer tout ce qui n’a pas encore commencé.
Le drainage est plus sûr pour des choses comme les paiements et les e-mails. Jeter est acceptable pour des tâches « agréables à avoir » comme recalculer un cache.
Une séquence d’arrêt pratique :
- Capturer SIGINT/SIGTERM et annuler un contexte partagé.
- Arrêter les soumissions (fermer le chemin de soumission, pas nécessairement le channel de travail).
- Laisser les workers finir ou abandonner selon le contexte.
- Attendre les workers via un WaitGroup.
- Appliquer une échéance, puis sortir.
L’échéance compte. Par exemple, donner 10 secondes aux jobs en cours pour s’arrêter. Après cela, loggez ce qui tourne encore et sortez. Ça rend les déploiements prévisibles et évite les processus bloqués.
Logs et métriques simples pour les worker pools
Prototyper un pipeline de facturation
Générez la pipeline payée→facture et la boucle worker en arrière-plan à partir d’une seule spécification.
Quand un worker pool casse, il échoue rarement bruyamment. Les jobs ralentissent, les réessais s’accumulent, et quelqu’un signale que « rien ne se passe ». Des logs et quelques compteurs basiques transforment cela en une histoire claire.
Donnez à chaque job un ID stable (ou générez-en un à la soumission) et incluez-le dans chaque ligne de log. Gardez les logs cohérents : une ligne quand un job démarre, une quand il finit, et une quand il échoue. Si vous réessayez, loggez le numéro de tentative et le délai suivant.
Une forme de log simple :
- start : job_id, worker_id, attempt, kind
- finish : job_id, worker_id, attempt, duration_ms
- fail/retry : job_id, worker_id, attempt, err, next_delay_ms
Les métriques peuvent rester minimales et rapporter gros. Suivez la longueur de la file, les jobs en cours, le total des succès et échecs, et la latence des jobs (au moins moyenne et max). Si la longueur de la file augmente et que les in-flight restent au niveau du nombre de workers, vous êtes saturé. Si les submitters bloquent en envoyant dans le channel jobs, le backpressure atteint l’appelant. Ce n’est pas toujours mauvais, mais cela doit être intentionnel.
Quand « les jobs sont bloqués », vérifiez si le processus reçoit toujours des jobs, si la file grandit, si les workers sont vivants, et quels jobs tournent depuis le plus longtemps. Les durées longues pointent généralement vers des timeouts manquants, des dépendances lentes ou une boucle de réessai qui ne s’arrête jamais.
Un exemple réaliste : une petite file de background pour une SaaS
Imaginez une petite SaaS où une commande passe à PAID. Juste après le paiement, vous devez générer un PDF de facture, envoyer l’e-mail au client et notifier votre équipe interne. Vous ne voulez pas que ce travail bloque la requête web. C’est un bon cas pour un worker pool car le travail est réel, mais le système reste petit.
La payload du job peut être minimale : juste assez pour aller chercher le reste en base. Le handler API écrit une ligne comme jobs(status='queued', type='send_invoice', payload, attempts=0) dans la même transaction que la mise à jour de la commande, puis une boucle en arrière-plan interroge les jobs en file et les pousse dans le channel des workers.
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
Quand un worker le prend en charge, le chemin heureux est simple : charger la commande, générer la facture, appeler le fournisseur d’e-mail, puis marquer le job comme terminé.
Les réessais sont là où ça devient sérieux. Si votre fournisseur d’e-mail a une panne temporaire, vous ne voulez pas que 1 000 jobs échouent définitivement ou frappent le fournisseur toutes les secondes. Une approche pratique :
- Traiter les erreurs réseau et les réponses 5xx comme réessayables.
- Utiliser un backoff exponentiel avec un délai maximal (par ex. 5s, 15s, 45s, 2m).
- Limiter les tentatives (par ex. 10) puis marquer le job comme failed.
- Enregistrer la dernière erreur pour que le support voie ce qui s’est passé.
Pendant la panne, les jobs passent de queued à in_progress, puis retournent en queued avec un temps d’exécution futur. Quand le fournisseur revient, les workers vident naturellement l’arriéré.
Imaginez maintenant un déploiement. Vous envoyez SIGTERM. Le processus doit arrêter de prendre du travail mais finir ce qui est en vol. Arrêtez le polling, arrêtez d’alimenter le channel des workers, et attendez les workers avec une échéance. Les jobs qui finissent sont marqués done. Ceux encore en cours quand l’échéance arrive doivent être remis en queued (ou laissés in_progress avec un watchdog) pour qu’ils soient repris quand la nouvelle version démarre.
Erreurs courantes et pièges
La plupart des bugs dans le traitement en arrière-plan ne se trouvent pas dans la logique du job. Ils viennent de problèmes de coordination qui n’apparaissent qu’en charge ou pendant l’arrêt.
Un piège classique est de fermer un channel depuis plusieurs endroits. Le résultat est un panic difficile à reproduire. Choisissez un seul propriétaire pour chaque channel (généralement le producteur) et faites-en le seul à appeler close(jobs).
Les réessais sont un autre domaine où les bonnes intentions provoquent des incidents. Si vous réessayez tout, vous réessayerez aussi les échecs permanents. Cela gaspille du temps, augmente la charge et peut transformer un petit problème en incident. Classez les erreurs et limitez les réessais avec une politique claire.
Les doublons arriveront même avec un design soigné. Les workers peuvent planter en plein job, un timeout peut se déclencher après que le travail soit fini, ou vous pouvez ré-enfiler lors d’un déploiement. Si le job n’est pas idempotent, les doublons causent de vrais dégâts : deux factures, deux e-mails de bienvenue, deux remboursements.
Les erreurs les plus fréquentes :
- Fermer le même channel depuis plusieurs goroutines.
- Réessayer des erreurs permanentes au lieu de les remonter.
- Pas de clé d’idempotence, donc les doublons provoquent des effets secondaires en double.
- Files en mémoire non bornées qui grandissent jusqu’à un pic mémoire.
- Ignorer
context.Context, si bien que le travail continue après le début de l’arrêt.
Les files non bornées sont particulièrement sournoises. Un pic peut s’accumuler en RAM sans bruit. Préférez un buffer de channel borné et décidez quoi faire quand il est plein : bloquer, jeter ou retourner une erreur.
Liste de vérification rapide avant mise en production
Devenir propriétaire du code généré
Obtenez le code complet Go, React et base de données que vous pouvez posséder et étendre.
Avant de déployer un worker pool en production, vous devriez pouvoir décrire le cycle de vie d’un job à voix haute. Si quelqu’un demande « où est ce job maintenant ? », la réponse ne doit pas être un pari.
Une checklist pratique :
- Vous pouvez nommer chaque état et transition : queued, picked up, running, finished, failed (et ce qui les fait changer).
- La concurrence est un seul réglage (comme
workerCount), et le changer ne nécessite pas de réécrire le code. - Les réessais sont bornés : le nombre maximal d’essais est clair, le backoff augmente, et l’échec permanent va quelque part d’intentionnel.
- Le comportement d’arrêt est éprouvé : vous arrêtez l’entrée, laissez les jobs en vol finir, et avez un timeout dur.
- Les logs répondent aux bases : job ID, numéro de tentative, durée et raison de l’erreur.
Faites un test réaliste avant la release : enfilez 100 jobs « envoyer reçu par e-mail », forcez 20 à échouer, puis redémarrez le service en cours d’exécution. Vous devriez voir les réessais se comporter comme prévu, pas d’effets secondaires en double, et l’annulation arrêter réellement le travail quand l’échéance est atteinte.
Si un point est flou, renforcez-le maintenant. De petites corrections ici vous feront gagner des jours plus tard.
Prochaines étapes : quand ajouter une infrastructure plus lourde (et quand ne pas le faire)
Un simple pool en processus suffit souvent tant que le produit est jeune. Si vos tâches sont « agréables à avoir » (envoyer des e-mails, rafraîchir des caches, générer des rapports) et que vous pouvez les relancer, un worker pool garde le système facile à comprendre.
Signes que vous avez dépassé un pool en processus
Surveillez ces points de tension :
- Vous exécutez plusieurs instances de l’application et vous voulez qu’une seule d’entre elles prenne un job.
- Vous avez besoin de durabilité (les jobs doivent survivre aux crashs et déploiements).
- Vous avez besoin d’un audit : qui a créé la tâche, quand elle a été exécutée et quel a été le résultat exact.
- Vous avez besoin de contrôle de backpressure entre services, pas seulement à l’intérieur d’un processus.
- Vous avez besoin d’une planification stricte ou de délais longs (heures ou jours) avec réveil fiable.
Si aucun de ces points n’est vrai, des outils plus lourds peuvent ajouter plus de pièces mobiles que de valeur.
Migrer progressivement sans réécriture
La meilleure protection est une interface de job stable : un type de payload petit, un ID, et un handler qui retourne un résultat clair. Ainsi vous pouvez remplacer le backend de la file plus tard (d’un channel en mémoire à une table DB, puis à une file dédiée) sans changer le code métier.
Une étape intermédiaire pratique est un petit service Go qui lit les jobs depuis PostgreSQL, les réclame avec un verrou, et met à jour leur statut. Vous gagnez en durabilité et en audit tout en conservant la même logique de worker.
Si vous voulez prototyper rapidement, Koder.ai (koder.ai) peut générer un starter Go + PostgreSQL à partir d’une invite de chat, incluant une table de jobs en arrière-plan et une boucle worker, et ses snapshots et rollback peuvent aider pendant que vous ajustez les réessais et le comportement d’arrêt.