29 déc. 2025·8 min
Outils d'administration qui préviennent la perte de données : actions en masse plus sûres
Les outils d'administration qui préviennent la perte de données utilisent des actions en masse plus sûres, des confirmations explicites, des suppressions douces, des journaux d'audit et des limites de rôle pour éviter les erreurs coûteuses.
Où la perte de données survient dans les outils d'administration
Les outils d'administration internes semblent plus sûrs parce que « seulement le personnel » peut les utiliser. C'est justement cette confiance qui les rend à haut risque. Les personnes qui les utilisent ont du pouvoir, travaillent vite et répètent souvent les mêmes actions plusieurs fois par jour. Une erreur peut toucher des milliers d'enregistrements.
La plupart des accidents ne proviennent pas d'une mauvaise intention. Ils viennent de moments « oups » : un filtre trop large, un terme de recherche qui correspond à plus de cas que prévu, ou un menu déroulant resté sur le mauvais tenant. Un classique est l'environnement : quelqu'un pense être en staging, mais regarde la production parce que l'interface se ressemble presque.
La vitesse et la répétition aggravent cela. Quand un outil est conçu pour aller vite, les utilisateurs développent une mémoire musculaire : cliquer, confirmer, suivant. Si l'écran rame, ils cliquent deux fois. Si une action en masse prend du temps, ils ouvrent un second onglet. Ces habitudes sont normales, mais elles créent les conditions d'erreurs.
« Détruire des données » ne signifie pas seulement appuyer sur un bouton supprimer. En pratique, cela peut vouloir dire :
- Supprimer des enregistrements (y compris suppressions en cascade)
- Écraser des champs (par exemple définir le statut sur « closed » pour le mauvais ensemble)
- Détacher des relations (délier un utilisateur d'un compte, retirer des permissions)
- Purger l'historique (vider les logs, supprimer des messages, tronquer des tables)
- Exportations ou synchronisations irréversibles (pousser de mauvaises données vers un autre système)
Pour les équipes qui construisent des outils d'administration qui préviennent la perte de données, « assez sûr » doit être un accord clair, pas une impression. Une définition simple : un opérateur pressé doit pouvoir récupérer d'une erreur courante sans aide de l'équipe d'ingénierie, et une action rare et irréversible doit requérir une friction supplémentaire, une preuve d'intention claire, et un enregistrement consultable ultérieurement.
Même si vous construisez des apps rapidement avec une plateforme comme Koder.ai, ces risques restent. La différence tient à savoir si vous concevez des garde-fous dès le premier jour ou si vous attendez le premier incident pour apprendre.
Commencez par une cartographie simple des risques
Avant de changer l'UI, clarifiez ce qui peut réellement mal tourner. Une cartographie des risques est une courte liste d'actions pouvant causer un vrai dommage, plus les règles qui doivent les entourer. Cette étape sépare les outils d'administration qui préviennent la perte de données de ceux qui n'en ont que l'apparence.
Commencez par écrire vos actions les plus dangereuses. Ce ne sont généralement pas les modifications quotidiennes. Ce sont les opérations qui modifient beaucoup d'enregistrements rapidement ou touchent des données sensibles.
Un premier tri utile :
- Supprimer, fusionner, fermer ou désactiver définitivement des comptes
- Réaffecter la propriété (clients, factures, tickets, leads)
- Imports et mises à jour en masse (CSV, jobs API, migrations)
- Actions de facturation (remboursements, crédits, annulations)
- Changements de permissions (rôles, accès aux PII)
Ensuite, marquez chaque action comme réversible ou irréversible. Soyez strict. Si vous ne pouvez la renverser qu'en restaurant depuis une sauvegarde, traitez-la comme irréversible pour l'opérateur qui effectue l'action.
Puis décidez de ce qui doit être protégé par la politique, pas seulement par le design. Les règles légales et de confidentialité s'appliquent souvent aux PII (noms, emails, adresses), aux enregistrements de facturation et aux journaux d'audit. Même si un outil peut techniquement supprimer quelque chose, votre politique peut exiger une conservation ou une revue à deux personnes.
Séparez les opérations routinières des opérations exceptionnelles. Le travail routinier doit être rapide et sûr (petites modifications, annulation claire). Le travail exceptionnel doit être délibérément plus lent (vérifications supplémentaires, approbations, limites plus strictes).
Enfin, mettez-vous d'accord sur des termes simples de « portée d'impact » pour que tout le monde parle le même langage : un enregistrement, plusieurs enregistrements, tous les enregistrements. Par exemple, « réaffecter ce client » n'est pas la même chose que « réaffecter tous les clients de ce commercial ». Cette étiquette guidera plus tard vos valeurs par défaut, confirmations et limites de rôle.
Exemple : dans un projet vibe-coding sur Koder.ai, vous pourriez taguer « import massif d'utilisateurs » comme plusieurs-enregistrements, réversible seulement si vous loggez chaque ID créé, et protégé par la politique parce que cela touche des PII.
Modèles pour des actions en masse plus sûres
Les actions en masse sont le moment où de bons outils d'administration deviennent risqués. Si vous construisez des outils d'administration qui préviennent la perte de données, traitez chaque bouton « appliquer à plusieurs » comme un outil électrique : utile, mais conçu pour éviter les glissements de doigt.
Un bon défaut est d'abord un aperçu, puis l'exécution. Au lieu d'exécuter tout de suite, montrez ce qui changerait et laissez l'opérateur confirmer après avoir vu l'étendue.
Rendez la portée explicite et difficile à mal interpréter. N'acceptez pas « tout » comme idée vague. Forcez l'opérateur à définir des filtres comme le tenant, le statut et une plage de dates, puis affichez le nombre exact d'enregistrements correspondants. Une petite liste d'exemples (même 10 éléments) aide à repérer des erreurs comme « mauvaise région » ou « archives incluses ».
Un modèle pratique qui fonctionne bien :
- Commencer par un écran de simulation (dry run) qui affiche le nombre, les filtres et un court échantillon d'enregistrements affectés
- Exiger un choix de portée explicite (par exemple : « uniquement clients actifs dans Tenant A, créés avant 2024-01-01 »)
- Limiter chaque exécution (par exemple 1 000 enregistrements) et demander de relancer pour le lot suivant
- Limiter le débit pour qu'un mauvais clic n'écrase pas la base de données ou les systèmes en aval
- Lancer en tant que job en file d'attente avec progression, journaux et une option claire d'annulation
Les jobs en file d'attente sont préférables au « tirer-et-oublier » parce qu'ils créent une trace et donnent à l'opérateur la possibilité d'arrêter l'action s'il remarque un problème à 5 % d'exécution.
Exemple : un opérateur veut désactiver des comptes utilisateurs en masse après un pic de fraude. L'aperçu affiche 842 comptes, mais l'échantillon inclut des clients VIP. Ce petit indice empêche souvent l'erreur réelle : un filtre manquant « fraud_flag = true ».
Si vous assemblez rapidement une console interne (même avec une plateforme de type build-by-chat comme Koder.ai), intégrez ces modèles dès le départ. Ils font gagner plus de temps qu'ils n'en prennent.
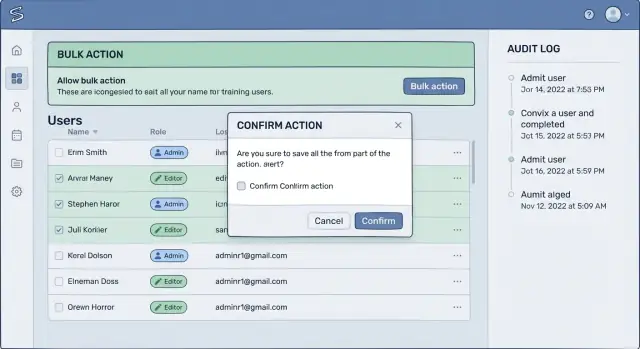
Des flux de confirmation que les gens lisent réellement
La plupart des confirmations échouent parce qu'elles sont trop génériques. Si l'écran dit « Êtes-vous sûr ? », les gens cliquent machinalement. Une confirmation efficace utilise les mêmes mots que l'utilisateur utiliserait pour expliquer la conséquence à un collègue.
Remplacez des libellés vagues comme « Supprimer » ou « Appliquer » par l'impact réel : « Désactiver 38 comptes », « Retirer l'accès pour ce tenant », ou « Annuler 12 factures ». C'est l'une des améliorations les plus simples pour des outils d'administration sûrs, car cela transforme un clic réflexe en un moment de reconnaissance.
Faire confirmer la portée par l'utilisateur
Un bon flux force une vérification mentale rapide : « Est-ce la bonne chose, sur le bon ensemble d'enregistrements ? » Mettez la portée dans la confirmation, pas seulement sur la page en arrière-plan. Incluez le nom du tenant ou de l'espace de travail, le nombre d'enregistrements et les filtres comme la plage de dates ou le statut.
Par exemple : « Fermer les comptes pour Tenant : Acme Retail. Nombre : 38. Filtre : dernière connexion avant 2024-01-01. » Si l'une de ces valeurs semble incorrecte, l'utilisateur l'aperçoit avant que le dommage survienne.
Quand l'action est vraiment destructrice, exigez un acte petit mais délibéré. Les confirmations saisies fonctionnent bien quand le coût d'une erreur est élevé.
- Demandez une courte phrase comme SUPPRIMER 38 COMPTES
- Ou demandez de taper exactement le nom du tenant
- Ou exigez de retaper le nombre affiché à l'écran
N'utiliser deux étapes que lorsque l'impact est élevé
Les confirmations en deux étapes doivent rester rares, sinon les utilisateurs les ignorent. Réservez-les aux actions difficiles à récupérer, qui traversent des tenants, ou qui affectent de l'argent. L'étape 1 confirme l'intention et la portée. L'étape 2 confirme le timing, comme « Exécuter maintenant » vs « Planifier », ou requiert une approbation avec des permissions supérieures.
Enfin, évitez les boutons « OK/Annuler ». Les boutons devraient indiquer ce qui se passe : « Désactiver les comptes » et « Revenir en arrière ». Cela réduit les mauvais clics et rend la décision concrète.
Suppressions douces, restaurations et règles de rétention
Rendre les suppressions réversibles
Implémentez des soft deletes et des restaurations avec fenêtres de rétention claires pour des opérations plus sûres.
Le soft delete est la valeur par défaut la plus sûre pour la plupart des objets visibles par l'utilisateur : comptes, commandes, tickets, publications, et même paiements. Au lieu de supprimer la ligne, marquez-la comme supprimée et cachez-la des vues normales. C'est l'un des modèles les plus simples derrière les outils d'administration qui préviennent la perte de données, car les erreurs deviennent réversibles.
Une politique de soft delete nécessite une fenêtre de rétention claire et une responsabilité définie. Décidez combien de temps les éléments supprimés restent restaurables (par exemple 30 ou 90 jours), et qui est autorisé à les restaurer. Attachez les droits de restauration aux rôles, pas aux individus, et traitez les restaurations comme des changements en production.
Rendre la restauration évidente (et journalisée)
Restaurer doit être simple à trouver quand quelqu'un consulte un enregistrement supprimé, pas enfoui dans un écran séparé. Ajoutez un statut visible comme « Supprimé », affichez la date et l'auteur. Lors d'une restauration, consignez-la comme un événement à part entière, pas comme une modification de la suppression initiale.
Une manière rapide de définir vos règles de rétention est de répondre à ces questions :
- Quelle est la période de rétention par défaut par type d'objet ?
- Quel rôle peut restaurer, et doit-il fournir une raison ?
- Que se passe-t-il après l'expiration de la période de rétention ?
- Qui peut prolonger la rétention pour des cas juridiques ou de facturation ?
- Comment gérez-vous les demandes « supprimer mes données » ?
Cas limites qui cassent les restaurations
Le soft delete semble simple jusqu'au moment où vous restaurez dans un monde qui a évolué. Des contraintes d'unicité peuvent entrer en collision (un nom d'utilisateur a été réutilisé), des références peuvent manquer (un parent a été supprimé), et l'historique de facturation doit rester cohérent même si l'utilisateur est « parti ». Une approche pratique consiste à garder les registres immuables (factures, événements de paiement) séparés des données de profil utilisateur, et à restaurer les relations avec prudence, en affichant des avertissements clairs quand une restauration complète n'est pas possible.
La suppression définitive (hard delete) doit être rare et explicite. Si vous l'autorisez, faites-en une exception ressentie avec un chemin d'approbation court :
- Exiger un rôle supérieur à celui de soft delete
- Demander une confirmation saisie et une raison
- Mettre la suppression en file d'attente avec un délai (par exemple 24 heures)
- Notifier un propriétaire ou l'astreinte
- Conserver un enregistrement d'audit final même après la suppression
Si vous construisez votre administration sur une plateforme comme Koder.ai, définissez le soft delete, la restauration et la rétention comme actions de première classe dès le début, pour qu'ils soient cohérents sur chaque écran et workflow générés.
Auditabilité : rendre les actions explicables après coup
Les accidents arrivent dans les panneaux d'administration, mais le vrai dommage survient souvent plus tard : personne ne peut répondre à ce qui a changé, qui l'a fait et pourquoi. Si vous voulez des outils d'administration qui préviennent la perte de données, considérez les journaux d'audit comme une partie du produit, pas comme un ajout pour le débogage.
Commencez par journaliser les actions d'une façon lisible par un humain. « Utilisateur 183 a mis à jour l'enregistrement 992 » n'est pas suffisant quand un client est mécontent et que la personne en astreinte tente de réparer vite. De bons logs capturent l'identité, le moment, la portée et l'intention, plus assez de détails pour annuler ou au moins comprendre l'impact.
Que consigner (pour que ce soit utile plus tard)
Une base pratique :
- Qui l'a fait (utilisateur, rôle, et info d'usurpation si utilisée)
- Quoi et où (nom de l'action, tenant/compte, types d'objets affectés)
- Quand et d'où (timestamp, fuseau horaire, IP ou ID de session/appareil)
- Ce qui a changé (avant/après pour les champs clés, ou un diff pour les gros objets)
- Pourquoi cela est arrivé (raison en texte libre et ID de ticket/référence optionnel)
Les actions en masse méritent un traitement spécial. Enregistrez-les comme un seul « job » avec un résumé clair (combien sélectionnés, combien réussis, combien échoués), et stockez aussi les résultats par élément. Cela permet de répondre facilement à « Avons-nous remboursé 200 commandes ou seulement 173 ? » sans fouiller des milliers d'entrées.
Rendez les logs faciles à rechercher : par administrateur, tenant, type d'action et plage temporelle. Incluez des filtres pour « jobs en masse seulement » et « actions à haut risque » pour que les relecteurs repèrent des tendances.
N'imposez pas de lourde bureaucratie. Un court champ « raison » avec des modèles (« Demande client de clôture », « Enquête fraude ») est rempli plus souvent qu'un long formulaire. Si un ticket support existe, laissez coller l'ID.
Enfin, prévoyez les accès en lecture. Beaucoup d'utilisateurs internes doivent consulter les logs, mais un petit groupe seulement devrait voir les champs sensibles (comme les valeurs complètes avant/après). Séparez « peut voir les résumés d'audit » de « peut voir les détails » pour réduire l'exposition.
Limites et garde-fous basés sur les rôles
La plupart des accidents surviennent parce que les permissions sont trop larges. Si tout le monde est effectivement administrateur, un opérateur fatigué peut faire un dommage permanent en un clic. L'objectif est simple : rendre le chemin sûr par défaut, et faire que les actions risquées exigent une intention supplémentaire.
Concevez les rôles autour de tâches réelles, pas des titres. Un agent support qui répond aux tickets n'a pas besoin du même accès que quelqu'un qui gère les règles de facturation.
Construire des rôles autour des tâches
Commencez par séparer ce que les gens peuvent voir de ce qu'ils peuvent modifier. Un ensemble pratique de rôles internes pourrait ressembler à :
- Lecture seule : voir utilisateurs, commandes et logs
- Opérateur : modifier profils et réinitialiser des mots de passe
- Opérateur facturation : émettre des remboursements dans une limite
- Responsable des données : fusionner des enregistrements et exécuter des corrections en masse
- Admin sécurité : désactiver des comptes et gérer les rôles
Cela maintient « supprimer » hors du travail quotidien et réduit la portée d'impact lorsqu'une erreur survient.
Pour les actions les plus dangereuses, ajoutez un mode élevé. Pensez-y comme une clé temporaire. Pour entrer en mode élevé, exigez une étape plus forte (ré-authentification, approbation d'un manager, ou une seconde personne) et retombez automatiquement après 10 à 30 minutes.
Des garde-fous d'environnement économisent aussi des équipes. L'UI doit rendre difficile la confusion entre staging et production. Utilisez des indicateurs visuels marquants, affichez le nom de l'environnement dans chaque en-tête, et désactivez les actions destructrices en non-production à moins qu'on ne les active explicitement.
Enfin, protégez les tenants entre eux. Dans les systèmes multi-tenant, les changements inter-tenants doivent être bloqués par défaut et seulement autorisés pour des rôles spécifiques avec un basculement explicite de tenant et une confirmation claire à l'écran.
Si vous construisez sur une plateforme comme Koder.ai, traitez ces garde-fous comme des fonctionnalités produit, pas des ajouts. Les outils d'administration qui préviennent la perte de données sont souvent juste un bon design de permissions plus quelques ralentisseurs bien placés.
Un scénario réaliste : remboursements en masse et clôtures de comptes
Garder le contrôle du code
Exportez le code source à tout moment pour le revoir, l'étendre ou l'intégrer à votre pipeline.
Un agent support doit gérer une panne de paiement. Le plan est simple : rembourser les commandes affectées, puis clôturer les comptes qui ont demandé l'annulation. C'est exactement là que les outils d'administration qui préviennent la perte de données font leur preuve, car l'agent est sur le point d'exécuter deux actions en masse à fort impact l'une après l'autre.
Le risque se cache dans un tout petit détail : le filtre. L'agent sélectionne « Commandes créées ces dernières 24 heures » au lieu de « Commandes payées pendant la fenêtre de panne ». Lors d'une journée chargée, cela peut inclure des milliers de clients normaux, déclenchant des remboursements non demandés. Si l'étape suivante est « Clôturer les comptes pour les commandes remboursées », les dégâts se propagent vite.
Avant que l'outil n'exécute quoi que ce soit, l'UI doit forcer une pause avec un aperçu clair qui correspond à la façon dont les gens pensent, pas à la façon dont la base de données pense. Par exemple, elle devrait afficher :
- Total des comptes qui seront clôturés (et combien sont déjà clôturés)
- Montant total des remboursements, plus montants min/max
- Un petit échantillon défilable des clients affectés (noms, emails, IDs de commande)
- Exceptions et omissions (paiements échoués, déjà remboursés, commandes disputées)
- Le résumé exact du filtre en langage clair, avec un bouton évident « Modifier le filtre »
Ajoutez ensuite une seconde confirmation séparée pour la clôture de comptes, car c'est un type de dommage différent. Un bon modèle est d'exiger la saisie d'une courte phrase comme « FERMER 127 COMPTES » afin que l'agent remarque si le nombre semble incorrect.
Si « fermer le compte » est un soft delete, la récupération est réaliste. Vous pouvez restaurer les comptes, garder les connexions bloquées, et définir une règle de rétention (par exemple purge automatique après 30 jours) pour que cela ne devienne pas une poubelle permanente.
Les journaux d'audit permettent le nettoyage et l'investigation après coup. Le manager doit voir qui a exécuté l'action, le filtre exact, les totaux montrés à l'époque et la liste des enregistrements affectés. Les limites de rôle comptent aussi : les agents peuvent émettre des remboursements jusqu'à un plafond quotidien, mais seul un manager peut clôturer des comptes, ou approuver des clôtures au-delà d'un seuil.
Si vous construisez ce type de console dans Koder.ai, des fonctionnalités comme les snapshots et le rollback sont des garde-fous utiles supplémentaires, mais la première ligne de défense reste l'aperçu, les confirmations et les rôles.
Étape par étape : ajouter la sécurité à une administration existante
Rétrofiter la sécurité fonctionne mieux quand vous traitez votre administration comme un produit, pas un ensemble de pages internes. Choisissez d'abord un flux à haut risque (comme la désactivation en masse d'utilisateurs), puis avancez étape par étape.
Un plan de retrofit pratique
Commencez par lister les écrans et endpoints qui peuvent supprimer, écraser ou déclencher des mouvements d'argent. Incluez les risques « cachés » comme les imports CSV, les éditions en masse et les scripts que les opérateurs lancent depuis l'UI.
Puis rendez les actions en masse plus sûres en forçant la portée et l'aperçu. Montrez exactement quels enregistrements correspondent aux filtres, combien vont changer, et un petit échantillon d'IDs avant l'exécution.
Ensuite, remplacez les suppressions définitives par des soft deletes quand c'est possible. Stockez un flag supprimé, qui l'a fait et quand. Ajoutez un chemin de restauration aussi facile à utiliser que la suppression, plus des règles de rétention claires (par exemple « restaurable pendant 30 jours »).
Après cela, ajoutez un journal d'audit et asseyez-vous avec les opérateurs pour revoir de vraies entrées. Si une ligne de log ne peut pas répondre à « quoi a changé, de quoi à quoi, et pourquoi », elle ne servira pas pendant un incident.
Enfin, resserrez les rôles et ajoutez des approbations pour les actions à fort impact. Par exemple, permettez au support d'émettre des remboursements jusqu'à une petite limite, mais exigez une seconde personne pour les montants importants ou les clôtures de compte. C'est ainsi que des outils d'administration qui préviennent la perte de données restent utilisables sans devenir effrayants.
Exemple rapide
Un opérateur doit clôturer 200 comptes inactifs. Avant le changement, il clique sur « Supprimer » et espère que les filtres sont corrects. Après le retrofit, il doit confirmer la requête exacte (« status=inactive, last_login>365d »), revoir le nombre et la liste d'échantillons, choisir « Fermer (restaurable) » au lieu de supprimer, et saisir une raison.
Un bon standard « fini » est :
- Vous pouvez prévisualiser et exporter l'ensemble affecté avant exécution.
- Vous pouvez annuler (restaurer ou rollback) dans une fenêtre définie.
- Chaque action est attribuée à une personne et à une raison.
- Les actions à fort impact sont limitées par rôle ou nécessitent une approbation.
Si vous construisez des outils internes dans une plateforme pilotée par chat comme Koder.ai, ajoutez ces garde-fous comme composants réutilisables pour que les nouvelles pages admin héritent de valeurs par défaut plus sûres.
Erreurs courantes qui conduisent encore aux accidents
Lancer en production en confiance
Déployez votre outil interne quand vous êtes prêt, avec hébergement et domaines personnalisés pris en charge.
Beaucoup d'équipes conçoivent des outils d'administration qui préviennent la perte de données en théorie, puis perdent des données en pratique parce que les fonctionnalités de sécurité sont faciles à ignorer ou difficiles à utiliser.
Le piège le plus fréquent est la confirmation universelle. Si chaque action affiche le même message « Êtes-vous sûr ? », les gens cessent de le lire. Pire, les équipes ajoutent souvent plus de confirmations pour « réparer » les erreurs, ce qui entraîne les opérateurs à cliquer plus vite.
Un autre problème est le manque de contexte au moment où il compte. Une action destructrice doit clairement montrer dans quel tenant ou workspace vous êtes, si c'est la production ou un test, et combien d'enregistrements seront touchés. Lorsque cette information est enfouie sur un autre écran, l'outil incite silencieusement à une mauvaise journée.
Les actions en masse sont aussi dangereuses quand elles s'exécutent instantanément sans suivi. Les opérateurs ont besoin d'un historique clair de job : ce qui a tourné, quel filtre, qui l'a lancé, et ce que le système a fait en cas d'erreur. Sans cela, vous ne pouvez ni mettre en pause, ni annuler, ni expliquer ce qui s'est passé.
Voici des erreurs qui reviennent souvent :
- Utiliser le même texte de confirmation pour suppressions, remboursements et changements de permissions
- Ajouter des confirmations si souvent que les gens cliquent automatiquement
- Ne pas afficher le nombre d'enregistrements, le tenant et l'environnement sur l'écran de confirmation
- Exécuter des actions en masse immédiatement sans aperçu, page de job et possibilité d'arrêt
- Tenir des logs d'audit mais ne pas les rendre consultables par utilisateur, enregistrement ou période
Un exemple concret : un opérateur veut désactiver 12 comptes dans un tenant sandbox, mais l'outil reste sur le dernier tenant utilisé et le cache dans l'en-tête. Il lance une action en masse, elle s'exécute instantanément, et le seul « log » est une entrée vague « mise à jour en masse terminée ». Quand quelqu'un s'en aperçoit, il est difficile de savoir ce qui a changé ou de restaurer.
Une bonne sécurité n'est pas plus de popups. C'est du contexte clair, des confirmations significatives et des actions traçables et réversibles.
Checklist rapide et prochaines étapes
Avant de déployer une action destructive, faites un dernier contrôle avec un regard neuf. La plupart des incidents d'administration arrivent quand un outil permet d'agir sur la mauvaise portée, cache l'impact réel ou n'offre aucun moyen clair de revenir en arrière.
Voici une checklist pré-vol pour des outils d'administration qui préviennent la perte de données :
- Scope + aperçu : montrer exactement ce qui changera (qui, quoi, où). Inclure un aperçu lisible et un échantillon d'enregistrements.
- Comptes + limites : afficher le nombre total d'items et appliquer des plafonds sensés (et des limites de débit) pour qu'un clic ne touche pas « tout ».
- Vérifications de contexte : faire confirmer le tenant/compte, l'environnement (prod vs test), et ajouter une courte raison qui apparaîtra dans les logs.
- Chemin de récupération : privilégier le soft delete quand c'est possible, vérifier que la restauration fonctionne, et définir la rétention (durée de possibilité de récupération).
- Responsabilité : journaliser qui a fait quoi, quand, d'où et avec quels filtres. Rendre les logs consultables et aligner les rôles sur les responsabilités réelles.
Si vous êtes opérateur, faites une pause de dix secondes et relisez l'outil : « J'agis sur le tenant X, je change N enregistrements, en production, pour la raison Y. » Si un élément est flou, arrêtez-vous et demandez une UI plus sûre avant d'exécuter.
Prochaines étapes : prototypez rapidement des flux plus sûrs dans Koder.ai en utilisant Planning Mode pour dessiner d'abord les écrans et les garde-fous. Pendant les tests, utilisez les snapshots et le rollback pour tester des cas limites réels sans crainte. Quand le flux est solide, exportez le code source et déployez quand vous êtes prêts.