Quand la base de données est sous tension, qu’est-ce qui casse en premier ?
Quand votre base de données est surchargée, les utilisateurs voient rarement un message "hors service" propre. Ils voient des timeouts, des pages qui se chargent à moitié, des boutons qui tournent indéfiniment et des actions qui marchent parfois puis échouent. Un enregistrement peut être sauvegardé une fois, puis renvoyer une erreur la fois suivante avec "Quelque chose s’est mal passé." Cette incertitude rend les incidents chaotiques.
Les premières choses à lâcher sont généralement les chemins gourmands en écritures : modification d’enregistrements, flux de paiement, envois de formulaires, mises à jour en arrière-plan, et tout ce qui nécessite une transaction et des verrous. Sous tension, les écritures ralentissent, se bloquent mutuellement et peuvent aussi ralentir les lectures en tenant des verrous ou en déclenchant du travail supplémentaire.
Les erreurs aléatoires sont pires qu’une limitation contrôlée parce que les utilisateurs ne savent pas quoi faire ensuite. Ils réessaient, rafraîchissent, cliquent encore, et créent encore plus de charge. Les tickets support augmentent parce que le système "fonctionne un peu", mais personne ne peut lui faire confiance.
Le but du mode lecture seule pendant un incident n’est pas la perfection. C’est de garder les parties les plus importantes utilisables : consulter des enregistrements clés, rechercher, vérifier des statuts et télécharger ce dont les gens ont besoin pour continuer. Vous interrompez ou retardez volontairement les actions risquées (les écritures) pour que la base puisse récupérer et que les lectures restantes restent réactives.
Fixez les attentes clairement. C’est une limite temporaire et cela ne signifie pas que des données sont supprimées. Dans la plupart des cas, les données existantes de l’utilisateur sont toujours là et en sécurité — le système met simplement les changements en pause jusqu’à ce que la base redevienne saine.
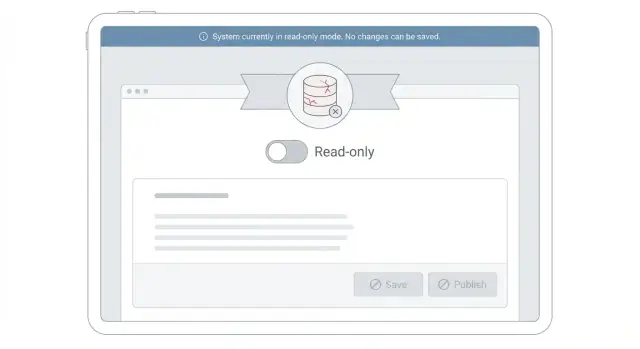
Ce que signifie réellement le mode lecture seule
Le mode lecture seule pendant un incident est un état temporaire où votre produit reste utilisable pour consulter, mais refuse tout ce qui modifierait les données. L’objectif est simple : garder le service utile tout en protégeant la base de données d’un travail supplémentaire.
Concrètement, on peut toujours consulter des informations, mais pas effectuer d’opérations qui déclenchent des écritures. En pratique, parcourir les pages, rechercher, filtrer et ouvrir des enregistrements fonctionne encore. En revanche, sauvegarder des formulaires, modifier des paramètres, poster des commentaires, téléverser des fichiers ou créer de nouveaux comptes sont bloqués.
Une façon pratique d’y penser : si une action met à jour une ligne, crée une ligne, supprime une ligne ou écrit dans une file, elle n’est pas autorisée. Beaucoup d’équipes bloquent aussi les « écritures cachées » comme les événements analytiques stockés dans la base principale, les logs d’audit écrits de façon synchrone et les horodatages « last seen ».
Le mode lecture seule est le bon choix quand les lectures fonctionnent encore en grande partie, mais que la latence d’écriture augmente, la contention de verrous grandit ou un arriéré d’opérations lourdes en écriture ralentit tout. Passez complètement hors ligne lorsque même les lectures de base timeout, que votre cache ne peut plus fournir l’essentiel, ou que le système n’est plus capable d’indiquer clairement ce qu’il est sûr de faire.
Pourquoi ça aide : une écriture coûte souvent bien plus qu’une simple lecture. Une écriture peut déclencher des index, des contraintes, des verrous et des requêtes de suivi. Bloquer les écritures empêche aussi les tempêtes de réessais, où les clients renvoient sans cesse des sauvegardes échouées et multiplient les dégâts.
Exemple : pendant un incident CRM, les utilisateurs peuvent toujours rechercher des comptes, ouvrir les fiches de contacts et voir les affaires récentes, mais les actions Éditer, Créer et Importer sont désactivées et toute requête de sauvegarde est rejetée immédiatement avec un message clair.
Choisissez les lectures à garder et les écritures à stopper
Quand vous passez en lecture seule pendant un incident, l’objectif n’est pas « tout fonctionne ». L’objectif est que les écrans les plus importants se chargent encore, tandis que tout ce qui crée plus de pression sur la base s’arrête rapidement et en sécurité.
Commencez par nommer les quelques actions utilisateur qui doivent rester disponibles même par mauvais temps. Ce sont habituellement des lectures courtes qui débloquent des décisions : consulter le dernier enregistrement, vérifier un statut, rechercher une petite liste ou télécharger un rapport déjà mis en cache.
Décidez ensuite ce que vous pouvez mettre en pause sans causer de dommages majeurs. La plupart des chemins d’écriture sont « agréables à avoir » durant un incident : modifications, mises à jour en masse, imports, commentaires, pièces jointes, événements analytiques et tout ce qui déclenche des requêtes supplémentaires.
Une façon simple de trancher est de classer les actions en trois catégories :
- Doit rester : lectures petites et rapides qui débloquent immédiatement les utilisateurs
- Peut être mis en pause : écritures et lectures lourdes qui ajoutent de la charge ou verrouillent des lignes
- Peut se dégrader : fonctionnalités montrant des données en cache ou une vue partielle
Fixez aussi un horizon temporel. Si vous attendez quelques minutes, vous pouvez être strict et bloquer presque toutes les écritures. Si vous attendez des heures, envisagez d’autoriser un très petit ensemble d’écritures sûres (par exemple réinitialisations de mot de passe ou mises à jour de statut critiques) et mettez tout le reste en file.
Mettez-vous d’accord sur la priorité dès le départ : sécurité avant exhaustivité. Il vaut mieux afficher clairement « les modifications sont en pause » que d’autoriser une écriture qui réussit à moitié et laisse les données incohérentes.
Passer en lecture seule est un compromis : moins de fonctionnalités maintenant, mais un produit utilisable et une base en meilleure santé. L’objectif est d’agir avant que les utilisateurs ne déclenchent une spirale de réessais, timeouts et connexions bloquées.
Surveillez un petit ensemble de signaux que vous pouvez résumer en une phrase. Si deux ou plusieurs apparaissent en même temps, considérez cela comme un avertissement précoce :
- Requêtes en timeout ou franchissant un seuil de latence clair (par exemple, p95 de 300 ms à 3 s)
- CPU de la base de données saturé plusieurs minutes, pas seulement un pic court
- Épuisement du pool de connexions (requêtes en file faute de connexions libres)
- Log des requêtes lentes remplit soudainement avec quelques mêmes requêtes
- Taux d’erreur en hausse dû aux attentes sur verrous, deadlocks ou transactions échouées
Les métriques seules ne doivent pas être l’unique déclencheur. Ajoutez une décision humaine : la personne on-call déclare l’état d’incident et active la lecture seule. Cela évite les débats sous pression et rend l’action auditable.
Rendez les seuils faciles à retenir et à communiquer. « Les écritures sont en pause car la base est surchargée » est plus clair que « nous avons atteint la saturation ». Définissez aussi qui peut basculer le bouton et où il est contrôlé.
Évitez les oscillations entre modes. Ajoutez une simple hystérésis : une fois en lecture seule, restez-y pour une fenêtre minimale (par exemple 10 à 15 minutes) et ne revenez en écriture que lorsque les signaux clés sont normaux depuis un moment. Cela évite aux utilisateurs de voir un formulaire qui marche une minute et échoue la suivante.
Étape par étape : activer la lecture seule en sécurité
Considérez la lecture seule comme un changement contrôlé, pas une improvisation. L’objectif est de protéger la base en arrêtant les écritures tout en gardant les lectures les plus utiles actives.
Une séquence de déploiement sûre
Si possible, livrez le chemin applicatif avant d’actionner l’interrupteur. Ainsi, activer la lecture seule devient un simple toggle, pas une modification en direct.
- Créez un seul interrupteur d’incident (feature flag ou config) que tout le système consulte. Gardez-le global et terne :
READ_ONLY=true. Évitez plusieurs flags qui peuvent diverger.
- Mettez à jour l’UI pour empêcher les tentatives d’écriture. Désactivez les boutons Enregistrer, cachez les formulaires d’édition et transformez les champs en texte simple. Affichez toujours les données pour que les gens puissent travailler (lecture, recherche, export).
- Faites appliquer la règle côté serveur, pas seulement l’UI. Bloquez les écritures en un seul endroit (middleware, garde dans le contrôleur ou couche de service) pour couvrir tous les clients, y compris mobiles, API et automatisations.
- Renvoyez une erreur claire et cohérente pour les écritures bloquées. Utilisez un code d’état et un message dédiés du type : « L’édition est temporairement désactivée pendant que nous stabilisons le système. Vos données sont en sécurité. Réessayez plus tard. » N’envoyez pas un 500 générique qui pourrait laisser croire à une perte de données.
- Journalisez chaque tentative d’écriture bloquée. Capturez l’utilisateur, l’endpoint et le type d’action. Gardez la charge utile minimale pour éviter de mettre des données sensibles dans les logs. Ces entrées vous aident à combler les lacunes UX et à rejouer des actions critiques si nécessaire.
Un petit détail qui évite les récidives
Quand la lecture seule est active, échouez vite avant d’atteindre la base. N’exécutez pas des requêtes de validation puis bloquez l’écriture. La requête bloquée la plus rapide est celle qui ne touche jamais votre base surchargée.
Messages UI qui réduisent la confusion et les tickets
Diffuser des messages calmes pour les incidents
Créez des bannières claires et des messages pour les écritures bloquées qui reflètent le comportement de votre backend.
Quand vous activez la lecture seule, l’UI devient une partie de la solution. Si les gens continuent de cliquer sur Enregistrer en obtenant des erreurs vagues, ils réessaient, rafraîchissent et ouvrent des tickets. Un message clair réduit la charge et la frustration.
Un bon pattern est une bannière visible et persistante en haut de l’application. Restez bref et factuel : ce qui se passe, à quoi s’attendre et ce qu’ils peuvent faire maintenant. Ne le cachez pas dans une notification éphémère.
Indiquez ce qui marche, ce qui est en pause et la suite
Les utilisateurs veulent surtout savoir s’ils peuvent continuer à travailler. Énoncez-le en langage simple. Pour la plupart des produits, cela veut dire :
- Toujours disponible : consulter des enregistrements, chercher, télécharger, lire des tableaux de bord
- En pause : créer, modifier, supprimer, téléversements, paiements, envoi de messages
- À faire à la place : copier les infos importantes, exporter une vue, réessayer plus tard
- Mises à jour : « Nous publierons une mise à jour ici dans 15 minutes. »
Un libellé de statut simple aide aussi les gens à comprendre l’avancement sans deviner. « Investigating » (en cours d’examen) signifie que vous cherchez la cause. « Stabilizing » (stabilisation) signifie que vous réduisez la charge et protégez les données. « Recovering » (rétablissement) signifie que les écritures reviendront bientôt, mais peuvent rester lentes.
Gardez un ton calme et précis
Évitez les textes accusateurs ou vagues comme « Quelque chose s’est mal passé » ou « Vous n’avez pas la permission. » Si un bouton est désactivé, indiquez-le : « L’édition est temporairement en pause pendant que nous stabilisons le système. »
Petit exemple : dans un CRM, gardez les pages contact et affaire consultables, mais désactivez Éditer, Ajouter une note et Nouvelle affaire. Si quelqu’un insiste, affichez un court dialogue : « Les modifications sont en pause pour le moment. Vous pouvez copier cette fiche ou exporter la liste, puis réessayer plus tard. »
Préserver les lectures essentielles sans augmenter la charge
Le but n’est pas « garder tout visible », mais « garder les quelques pages sur lesquelles les gens comptent » sans ajouter de pression à la base.
Commencez par alléger les écrans les plus lourds. Les tableaux longs avec beaucoup de filtres, la recherche en texte libre sur plusieurs champs et les tris sophistiqués déclenchent souvent des requêtes lentes. En lecture seule, simplifiez ces écrans : moins d’options de filtre, un tri par défaut sûr et une plage de dates limitée.
Privilégiez les vues mises en cache ou pré-calculées pour les pages importantes. Un simple « aperçu du compte » lisant depuis un cache ou une table de résumé est souvent plus sûr que charger des journaux bruts ou faire de nombreuses jointures.
Moyens concrets pour garder les lectures vivantes sans alourdir la base :
- Utiliser des pages avec moins d’éléments et supprimer « tout afficher »
- Remplacer les tris complexes par un ordre par défaut (par ex. « les plus récents d’abord »)
- Différer les lectures non essentielles comme l’analytics, les recommandations et les graphiques d’activité
- Préférer des résumés en cache aux historiques bruts
- Autoriser des données légèrement périmées si cela maintient la réactivité des pages clés
Exemple concret : lors d’un incident CRM, gardez Consulter contact, Consulter statut d’affaire et Voir la dernière note. Masquez temporairement Recherche avancée, graphique de revenus et timeline complète des e-mails, et indiquez que les données peuvent être âgées de quelques minutes.
Que faire des jobs, webhooks et intégrations
Déployer en toute confiance
Déployez et hébergez votre application pour que l’interrupteur lecture seule soit toujours accessible en on-call.
Le plus souvent, la surprise n’est pas l’UI mais les écrivains invisibles : jobs en arrière-plan, synchros planifiées, actions admin en masse et intégrations tierces qui continuent de marteler la base.
Commencez par arrêter le travail en arrière-plan qui crée ou met à jour des enregistrements. Les coupables fréquents sont les imports, synchronisations nocturnes, envois d’e-mails qui écrivent des logs de livraison, rollups analytiques et boucles de réessai qui retentent la même mise à jour échouée. Les mettre en pause réduit rapidement la pression et évite une seconde vague de charge.
Par défaut, mettez en pause ou bridez les jobs lourds en écriture et les consommateurs de queue qui persistent des résultats, désactivez les actions admin massives (mises à jour en masse, suppressions groupées, réindexations importantes) et échouez vite sur les endpoints d’écriture avec une réponse temporaire claire plutôt que de laisser timeout.
Pour les webhooks et intégrations, la clarté vaut mieux que l’optimisme. Si vous acceptez un webhook mais ne pouvez pas le traiter, vous créerez des décalages et du support à gérer. Quand les écritures sont en pause, renvoyez un échec temporaire qui indique à l’émetteur de réessayer plus tard, et assurez-vous que les messages UI reflètent ce qui se passe en coulisses.
Soyez prudent avec le buffering « mettre en file pour plus tard ». Ça paraît amical, mais peut créer un arriéré qui inonde le système dès que vous réactivez les écritures. Ne mettez en file les écritures utilisateurs que si vous pouvez garantir l’idempotence, limitez la taille de la file et montrez à l’utilisateur l’état réel (en attente vs enregistré).
Enfin, auditez les écrivains en masse cachés dans votre produit. Si une automation peut mettre à jour des milliers de lignes, elle doit être forcée hors service en lecture seule même si le reste de l’app se charge.
Erreurs courantes qui aggravent les incidents
La manière la plus rapide d’empirer un incident est de traiter le mode lecture seule comme un gadget cosmétique. Si vous ne faites que désactiver les boutons dans l’UI, des écritures passeront encore par les APIs, onglets ouverts, applis mobiles et jobs en arrière-plan. La base reste sous pression, et vous perdez la confiance car les utilisateurs voient « enregistré » à un endroit et des changements manquants ailleurs.
Un vrai mode lecture seule exige une règle claire : le serveur refuse les écritures, à chaque fois, pour tous les clients.
Erreurs à surveiller
Ces patterns reviennent souvent lors d’une surcharge :
- Bloquer les modifications uniquement dans l’UI alors que le backend accepte encore POST, PUT, PATCH et DELETE
- Oublier des chemins cachés : panels admin, outils internes, endpoints d’import et APIs publiques utilisées par des intégrations
- Laisser le système osciller entre normal et lecture seule toutes les minutes
- Afficher des messages vagues comme « Quelque chose s’est mal passé »
- Autoriser des écritures partielles qui laissent des données incohérentes
Faites en sorte que le système se comporte de façon prévisible. Implementez un unique interrupteur côté serveur qui rejette les écritures avec une réponse claire. Ajoutez un cooldown : une fois en lecture seule, restez-y un temps défini (par ex. 10–15 minutes) sauf si un opérateur change l’état.
Soyez strict sur l’intégrité des données. Si une écriture ne peut pas se compléter, échouez toute l’opération et indiquez à l’utilisateur la marche à suivre. Un message simple comme « Mode lecture seule : la consultation fonctionne, les changements sont en pause. Réessayez plus tard. » réduit les réessais répétés.
Vérifications rapides avant et pendant un incident
Le mode lecture seule n’aide que s’il est facile à activer et se comporte identiquement partout. Avant les problèmes, assurez-vous d’avoir un unique toggle (feature flag, config, switch admin) que l’on-call peut activer en quelques secondes, sans déploiement.
Quand vous suspectez une surcharge, faites une passe rapide pour confirmer les bases :
- Activez le toggle dans un environnement sûr et confirmez qu’il prend effet immédiatement
- Testez quelques actions d’écriture (enregistrer, supprimer, importer) et confirmez que tous les endpoints d’écriture renvoient la même réponse bloquée et le même code d’état
- Vérifiez que le texte de la bannière est prêt, court et visible sur les écrans clés
- Chargez vos 3 pages prioritaires (ex. : login, tableau de bord, vue d’enregistrement) et confirmez qu’elles se rendent sous charge
- Assurez-vous que le support dispose d’un script d’une phrase expliquant ce qui marche, ce qui est en pause et où suivre les mises à jour
Pendant l’incident, gardez une personne dédiée à vérifier l’expérience utilisateur, pas seulement les tableaux de bord. Un contrôle rapide en mode navigation privée repère des problèmes comme des bannières cachées, formulaires cassés ou spinners infinis qui provoquent des rafraîchissements supplémentaires.
Planifiez la sortie avant d’activer la lecture seule. Définissez ce que « sain » signifie (latence, taux d’erreur, retard de réplication) et faites une vérification courte après la remise en marche : créez un enregistrement test, modifiez-le et confirmez que les comptes et l’activité récente sont cohérents.
Exemple d’incident : garder un CRM utilisable tout en bloquant les éditions
Répéter les changements en sécurité
Validez les changements de comportement en incident avec des snapshots et des rollback sans risque.
Il est 10h20. Votre CRM est lent et la CPU de la base est saturée. Les tickets support arrivent : les utilisateurs ne peuvent pas sauvegarder les modifications de contacts et d’affaires. Mais l’équipe a encore besoin de retrouver des numéros, voir les étapes d’affaires et lire les dernières notes avant les appels.
Vous choisissez une règle simple : geler tout ce qui écrit, garder les lectures les plus utiles. En pratique, la recherche de contacts, la fiche contact et la vue pipeline restent accessibles. La modification d’un contact, la création d’une affaire, l’ajout de notes et les imports en masse sont bloqués.
Dans l’UI, le changement doit être visible et calme. Sur les écrans d’édition, le bouton Enregistrer est désactivé et le formulaire reste visible pour que les gens puissent copier ce qu’ils ont saisi. Une bannière en haut indique : « Mode lecture seule activé en raison d’une forte charge. La consultation est disponible. Les modifications sont en pause. Merci de réessayer plus tard. » Si un utilisateur déclenche quand même une écriture (par exemple via une API), renvoyez un message clair et évitez les réessais automatiques qui martèleraient la base.
Opérationnellement, gardez le flux court et reproductible. Activez la lecture seule et vérifiez que tous les endpoints d’écriture la respectent. Mettez en pause les jobs d’arrière-plan qui écrivent (syncs, imports, logging d’e-mails, rollups analytiques). Bridez ou arrêtez webhooks et intégrations qui créent des mises à jour. Surveillez la charge DB, le taux d’erreur et les requêtes lentes. Publiez une mise à jour d’état indiquant ce qui est affecté (modifications) et ce qui fonctionne encore (recherche et consultation).
La récupération n’est pas juste un coup d’interrupteur. Réactivez les écritures progressivement, vérifiez les logs d’erreur pour les sauvegardes échouées et surveillez une possible tempête d’écritures issue des jobs mis en file. Puis communiquez clairement : « Le mode lecture seule est désactivé. La sauvegarde est rétablie. Si vous avez tenté d’enregistrer entre 10h20 et 10h55, merci de vérifier vos derniers changements. »
Étapes suivantes : intégrer le mode lecture seule à votre playbook
Le mode lecture seule fonctionne mieux quand il est terne et répétable. L’objectif est de suivre un script court avec des rôles et des vérifications clairs.
Construisez un petit playbook exploitable
Tenez-le sur une page. Incluez vos déclencheurs (les quelques signaux qui justifient la bascule), l’interrupteur exact que vous actionnez et comment confirmer que les écritures sont bloquées, une liste courte de lectures clés qui doivent rester actives, des rôles clairs (qui bascule, qui surveille les métriques, qui gère le support) et des critères de sortie (ce qui doit être vrai avant de réactiver les écritures et comment vidanger les arriérés).
Préparez les textes UI avant d’en avoir besoin
Rédigez et validez les messages maintenant pour éviter les débats pendant une panne. Un petit ensemble couvre la plupart des cas :
- Bannière : « Nous sommes en mode lecture seule pendant que nous rétablissons les performances. Vous pouvez consulter les données, mais les modifications sont temporairement désactivées. »
- Actions bloquées : « L’enregistrement est mis en pause pour le moment. Vos changements n’ont pas été appliqués. Merci de réessayer dans quelques minutes. »
- Détail du statut : « Dernière mise à jour à HH:MM. Prochaine mise à jour dans 10 minutes. »
Exercez la bascule en staging et mesurez le temps. Assurez-vous que le support et l’on-call trouvent vite l’interrupteur et que les logs montrent clairement les écritures bloquées. Après chaque incident, revoyez quelles lectures étaient vraiment critiques, lesquelles étaient « agréables à avoir » et lesquelles ont accidentellement créé de la charge, puis mettez à jour la checklist.
Si vous développez des produits sur Koder.ai (koder.ai), il peut être utile de traiter le mode lecture seule comme un interrupteur de première classe dans votre app générée afin que l’UI et les gardes côté serveur restent cohérents quand vous en avez le plus besoin.