Pourquoi les clients se sentent perdus face aux limites
Les rate limits et les quotas semblent proches, donc souvent les gens les confondent. Un rate limit définit la vitesse d'appels à une API (requêtes par seconde ou par minute). Un quota définit combien vous pouvez consommer sur une période plus longue (par jour, par mois, ou par cycle de facturation). Les deux sont normaux, mais ils paraissent aléatoires quand les règles ne sont pas visibles.
La plainte classique est : « ça fonctionnait hier. » L’utilisation est rarement stable. Un pic court peut faire dépasser quelqu’un même si son total journalier semble correct. Imaginez un client qui lance un rapport une fois par jour, mais aujourd’hui le job réessaie après un timeout et effectue 10× plus d’appels en 2 minutes. L’API le bloque, et tout ce qu’il voit, c’est une panne soudaine.
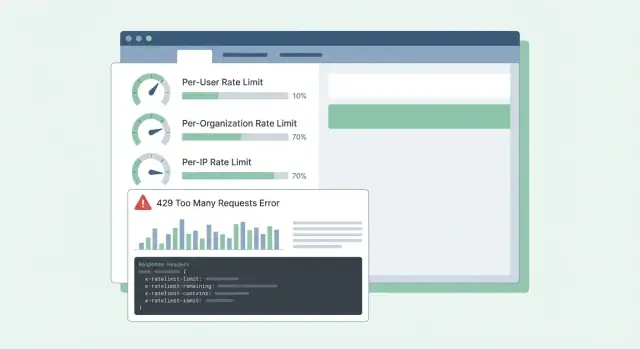
La confusion s’aggrave quand les erreurs sont vagues. Si l’API renvoie un 500 ou un message générique, les clients supposent que votre service est en panne, pas qu’ils ont atteint une limite. Ils ouvrent des tickets urgents, construisent des contournements, ou changent de fournisseur. Même un 429 Too Many Requests peut être frustrant s’il n’indique pas quoi faire ensuite.
La plupart des API SaaS limitent le trafic pour deux raisons différentes :
- Stopper les abus : protéger le système contre le scraping, le brute force ou les scripts hors contrôle.
- Modeler l’utilisation normale : garder une performance stable pour tout le monde, surtout aux heures de pointe.
Mélanger ces objectifs conduit à de mauvaises conceptions. Les contrôles anti‑abus sont souvent par IP ou par token et peuvent être stricts. Le modelage de l’usage normal est généralement par utilisateur ou par organisation et devrait s’accompagner d’instructions claires : quelle limite a été atteinte, quand elle se réinitialise, et comment l’éviter.
Quand les clients peuvent prévoir les limites, ils s’organisent. Quand ils ne le peuvent pas, chaque pic ressemble à une API cassée.
Décidez ce que vous protégez
Les rate limits ne sont pas seulement un régulateur. Ce sont un système de sécurité. Avant de choisir des chiffres, soyez clair sur ce que vous essayez de protéger, car chaque objectif mène à des limites et des attentes différentes.
La disponibilité vient généralement en premier. Si quelques clients peuvent provoquer des rafales de trafic et pousser votre API vers des timeouts, tout le monde en pâtit. Les limites ici doivent garder les serveurs réactifs pendant les pics et échouer rapidement plutôt que de laisser les requêtes s’accumuler.
Le coût est souvent le moteur discret derrière de nombreuses API. Certaines requêtes sont bon marché, d’autres coûteuses (appels LLM, traitement de fichiers, écritures de stockage, requêtes payantes tierces). Par exemple, sur une plateforme comme Koder.ai, un seul utilisateur peut déclencher de nombreux appels de modèles via une génération d’apps par chat. Des limites qui suivent les actions coûteuses peuvent prévenir des surprises sur la facture.
L’abus se manifeste différemment d’une forte utilisation légitime. Le credential stuffing, la devinette de tokens et le scraping apparaissent souvent comme beaucoup de petites requêtes depuis un ensemble restreint d’IP ou de comptes. Là, vous voulez des limites strictes et un blocage rapide.
L’équité compte dans les systèmes multitenants. Un client bruyant ne doit pas dégrader tout le monde. En pratique, cela signifie souvent empiler des contrôles : une garde contre les rafales pour la minute à minute, un garde coût pour les endpoints coûteux, un garde anti‑abus centré sur l’auth et des motifs suspects, et un garde d’équité pour empêcher qu’une organisation n’écrase les autres.
Un test simple aide : choisissez un endpoint et demandez-vous « si cette requête augmente de 10×, qu’est-ce qui casse en premier ? » La réponse vous indique quel objectif de protection prioriser, et quelle dimension (utilisateur, org, IP) devrait porter la limite.
Choisissez les bonnes dimensions de limitation
La plupart des équipes commencent par une limite et découvrent ensuite qu’elle pénalise les mauvaises personnes. L’objectif est de choisir des dimensions qui correspondent à l’usage réel : qui appelle, qui paie, et ce qui ressemble à un abus.
Les dimensions communes en SaaS ressemblent à ceci :
- Par utilisateur : empêche un utilisateur intensif de ralentir les autres au sein du même compte.
- Par org/workspace : impose un plafond clair à l’usage total d’un tenant (souvent ce que les plans facturent réellement).
- Par IP : détecte les bots, le credential stuffing et les clients mal configurés qui frappent depuis une même adresse.
- Par clé API/token : utile pour les partenaires et intégrations où « utilisateur » n’a pas de sens ou est partagé.
Les limites par utilisateur concernent l’équité à l’intérieur d’un tenant. Si une personne lance un gros export, elle doit ressentir le ralentissement plus que le reste de l’équipe.
Les limites par organisation concernent le budget et la capacité. Même si dix utilisateurs lancent des jobs en même temps, l’organisation ne devrait pas monter à un niveau qui casse votre service ou vos hypothèses de tarification.
Les limites par IP doivent être vues comme un filet de sécurité, pas un outil de facturation. Les IP peuvent être partagées (NAT de bureau, opérateurs mobiles), gardez ces limites généreuses et comptez sur elles surtout pour arrêter les abus évidents.
Quand vous combinez des dimensions, décidez laquelle « gagne » quand plusieurs limites s’appliquent. Une règle pratique : rejetez la requête si une limite pertinente est dépassée, et retournez la raison la plus exploitable. Si un workspace dépasse son quota org, ne rejetez pas en accusant l’utilisateur ou l’IP.
Exemple : un workspace Koder.ai en plan Pro peut autoriser un flux constant de requêtes de build par org, tout en limitant un seul utilisateur qui envoie des centaines de requêtes par minute. Si une intégration partenaire utilise un token partagé, une limite par token peut l’empêcher d’étouffer les utilisateurs interactifs.
Algorithmes efficaces en production
La plupart des problèmes de limitation ne sont pas des problèmes mathématiques. Ce sont des problèmes de comportement : choisir une réponse qui correspond à la façon dont les clients appellent votre API, puis la garder prévisible sous charge.
Le Token Bucket est un choix courant parce qu’il permet de courtes rafales tout en appliquant une moyenne sur le long terme. Un utilisateur qui rafraîchit un tableau de bord peut déclencher 10 requêtes rapides. Token Bucket le permet s’il a accumulé des jetons, puis le ralentit.
Le Leaky Bucket est plus strict. Il lisse le trafic en un débit constant, ce qui aide quand votre backend ne supporte pas les pics (par exemple pour la génération de rapports coûteuse). Le compromis : les clients le ressentent plus vite, car les rafales deviennent des mises en file ou des rejets.
Les compteurs basés sur des fenêtres sont simples, mais les détails comptent. Les fenêtres fixes créent des arêtes nettes à la frontière (un utilisateur peut exploser à 12:00:59 puis de nouveau à 12:01:00). Les fenêtres glissantes semblent plus justes et réduisent les spikes de frontière, mais exigent plus d’état ou de meilleures structures de données.
Une autre catégorie est la limite de concurrence (requêtes en vol). Cela vous protège des connexions clientes lentes et des endpoints long-running. Un client peut rester dans 60 requêtes/minute mais vous surcharger en gardant 200 requêtes ouvertes en même temps.
Dans les systèmes réels, les équipes combinent souvent un petit ensemble de contrôles : un token bucket pour le débit général, un plafond de concurrence pour les endpoints lents ou lourds, et des budgets séparés par groupe d’endpoints (lectures bon marché vs exports coûteux). Si vous ne limitez que par nombre de requêtes, un endpoint coûteux peut tout drainer et faire paraître l’API aléatoirement cassée.
Concevoir des quotas qui correspondent à la tarification et à l’utilisation
Rédigez votre spécification de limitation de débit
Décrivez votre API et vos paliers, et Koder.ai aide à définir les limites, les en-têtes et les règles de réinitialisation.
De bons quotas sont justes et prévisibles. Les clients ne devraient pas découvrir les règles seulement après avoir été bloqués.
Gardez la séparation claire :
- Les limites court terme (par ex. 10 requêtes/seconde) protègent votre service des rafales.
- Les quotas long terme (quotidien/mensuel) protègent les coûts et rendent les paliers de tarification comparables.
Beaucoup d’équipes SaaS utilisent les deux : une limite courte pour stopper les rafales plus un quota mensuel lié à la tarification.
Hard vs soft limits est surtout un choix de support. Une limite hard bloque immédiatement. Une limite soft avertit d’abord, puis bloque plus tard. Les limites soft réduisent les tickets en donnant le temps de corriger un bug ou d’upgrader avant qu’une intégration ne casse.
Quand quelqu’un dépasse, le comportement doit correspondre à ce que vous protégez. Bloquer fonctionne quand la surconsommation pourrait nuire aux autres tenants ou exploser les coûts. Dégrader (traitement plus lent ou priorité plus basse) fonctionne quand vous préférez que les choses continuent à avancer. « Facturer plus tard » peut fonctionner quand l’usage est prévisible et que vous avez déjà un flux de facturation.
Les limites par palier fonctionnent mieux quand chaque palier a une « forme d’usage attendue » claire. Un palier gratuit peut autoriser de petits quotas mensuels et de faibles rafales, tandis que les paliers Business et Enterprise obtiennent des quotas et rafales plus élevés pour que les jobs en arrière-plan puissent finir rapidement. C’est similaire à la façon dont les paliers Free, Pro, Business et Enterprise de Koder.ai fixent différentes attentes sur ce qu’il est possible de faire avant de monter de palier.
Les limites personnalisées valent la peine d’être supportées tôt, surtout pour l’entreprise. Une approche propre : « valeurs par défaut par plan, overrides par client ». Stockez un override défini par un admin par org (et parfois par endpoint) et assurez-vous qu’il survive aux changements de plan. Décidez aussi qui peut demander des changements et la rapidité de leur prise d’effet.
Exemple : un client importe 50 000 enregistrements le dernier jour du mois. Si son quota mensuel est presque consommé, un avertissement soft à 80–90% lui laisse le temps de suspendre. Une limite courte par seconde empêche l’import de submerger l’API. Un override approuvé par l’organisation (temporaire ou permanent) maintient l’activité commerciale.
Implémentation pas à pas : ajouter des limites dans une API SaaS
Commencez par écrire ce que vous allez compter et à qui cela appartient. La plupart des équipes finissent avec trois identités : l’utilisateur connecté, l’org client (ou workspace), et l’IP cliente.
Un plan pratique :
- Définir les règles d’identité : user ID depuis l’auth, org ID depuis le token ou la clé API, IP depuis le premier saut de proxy de confiance (soyez explicite sur quel header vous faites confiance).
- Grouper les endpoints par coût : lectures, écritures, exports lourds, flux d’auth. Donnez à chaque groupe des limites différentes pour qu’un endpoint coûteux ne draine pas tout le budget.
- Choisir où stocker les compteurs : en mémoire pour une instance unique, Redis pour des limites partagées entre serveurs, et une base de données seulement pour des quotas d’audit plus lents. Utilisez des TTL qui correspondent à la fenêtre (par ex. 60 secondes pour des limites par minute).
- Appliquer de façon cohérente : faites un blocage grossier à la frontière (gateway/CDN) pour les inondations par IP, puis des vérifications plus fines par user/org dans le middleware applicatif où vous voyez la route et le tenant.
- Instrumenter tout : suivez le taux de blocage (429), la latence ajoutée par le limiteur et les clés les plus bloquées. Alertez quand les blocages augmentent ou quand des erreurs Redis forcent un « fail open/closed ».
Quand vous définissez des limites, pensez en paliers et groupes d’endpoints, pas en un seul nombre global. Une erreur courante est de compter sur des compteurs en mémoire répartis sur plusieurs serveurs d’app. Les compteurs divergent et les utilisateurs voient des 429 « aléatoires ». Un store partagé comme Redis stabilise les limites entre instances, et les TTL gardent les données petites.
Le déploiement est important. Commencez en mode « report only » (journaliser ce qui aurait été bloqué), puis appliquez un groupe d’endpoints, puis élargissez. C’est ainsi que vous évitez de vous réveiller avec une avalanche de tickets de support.
Rendre les limites compréhensibles avec des réponses et des en-têtes
Quand un client atteint une limite, le pire est la confusion : « Votre API est-elle en panne, ou ai-je fait une erreur ? » Des réponses claires et cohérentes réduisent les tickets et aident à corriger le comportement client.
Utilisez HTTP 429 Too Many Requests quand vous bloquez activement des appels. Gardez le corps de réponse prévisible pour que les SDKs et tableaux de bord puissent le lire.
Voici une forme JSON simple qui marche bien pour des limites par utilisateur, org et IP :
{
"error": {
"code": "rate_limit_exceeded",
"message": "Rate limit exceeded for org. Try again later.",
"limit_scope": "org",
"reset_at": "2026-01-17T12:34:56Z",
"request_id": "req_01H..."
}
}
Les en-têtes doivent expliquer la fenêtre courante et ce que le client peut faire ensuite. Si vous n’ajoutez que quelques en-têtes, commencez par : RateLimit-Limit, RateLimit-Remaining, RateLimit-Reset, Retry-After, et X-Request-Id.
Exemple : le cron d’un client s’exécute chaque minute et commence soudainement à échouer. Avec un 429 plus RateLimit-Remaining: 0 et Retry-After: 20, il sait immédiatement que c’est une limite, pas une panne, et il peut retarder les retries de 20 secondes. S’il partage X-Request-Id avec le support, vous retrouverez l’événement rapidement.
Un détail de plus : retournez les mêmes en-têtes sur les réponses réussies aussi. Les clients peuvent voir qu’ils s’approchent du bord avant de l’atteindre.
Comportement côté client : retries, backoff et écritures sûres
Prototypez un throttling en couches
Concevez une protection IP à la frontière et des vérifications org et user au niveau applicatif qui concordent entre serveurs.
De bons clients rendent les limites plus acceptables. De mauvais clients transforment une limite temporaire en panne en appuyant plus fort.
Quand vous recevez un 429, considérez-le comme un signal pour ralentir. Si la réponse indique quand réessayer (par exemple via Retry-After), attendez au moins ce délai. Sinon, utilisez un backoff exponentiel et ajoutez du jitter (aléa) pour éviter que des milliers de clients ne retentent en même temps.
Limitez les retries : plafonnez le délai entre tentatives (par ex. 30–60s) et le temps total de retry (par ex. arrêter après 2 minutes et exposer une erreur). Enregistrez aussi l’événement avec les détails de la limite afin que les devs puissent ajuster plus tard.
Ne retentez pas tout. Beaucoup d’erreurs ne réussiront pas sans modification ou intervention utilisateur : 400 erreurs de validation, 401/403 erreurs d’auth, 404 not found, et 409 conflicts qui reflètent une règle métier.
Les retries sont risqués sur les endpoints d’écriture (create, charge, send email). Si un timeout se produit et que le client retente, vous pouvez créer des doublons. Utilisez des idempotency keys : le client envoie une clé unique par action logique, et le serveur retourne le même résultat pour les répétitions de cette clé.
De bons SDKs facilitent cela en exposant ce dont les développeurs ont besoin : le statut (429), combien attendre, si la requête est sûre à retenter, et un message du type « Rate limit exceeded for org. Retry after 8s or reduce concurrency. »
Erreurs courantes qui créent des tickets en colère
La plupart des tickets de support au sujet des limites ne portent pas sur la limite elle‑même. Ils portent sur les surprises. Si les utilisateurs ne peuvent pas prévoir ce qui va se passer ensuite, ils supposent que l’API est cassée ou injuste.
Utiliser uniquement des limites basées sur l’IP est une erreur fréquente. Beaucoup d’équipes sont derrière une IP publique (Wi‑Fi de bureau, opérateurs mobiles, NAT cloud). Si vous plafonnez par IP, un client occupé peut bloquer tout le monde sur le même réseau. Préférez les limites par utilisateur et par org, et utilisez la limite par IP principalement comme filet anti‑abus.
Un autre problème est de traiter tous les endpoints de la même manière. Un GET bon marché et un export lourd ne devraient pas partager le même budget. Sinon, les clients consomment leur allocation en navigation normale, puis se retrouvent bloqués pour une vraie tâche. Séparez les buckets par groupe d’endpoints ou pondérez les requêtes selon leur coût.
Le timing des réinitialisations doit aussi être explicite. « Réinitialise quotidiennement » n’est pas suffisant. Quel fuseau horaire ? Fenêtre glissante ou réinitialisation à minuit ? Si vous faites des réinitialisations calendaire, indiquez le fuseau horaire. Si vous faites des fenêtres glissantes, indiquez la durée.
Enfin, des erreurs vagues créent le chaos. Renvoyer un 500 ou du JSON générique pousse les gens à retenter plus fort. Utilisez 429 et incluez des en-têtes RateLimit pour que les clients puissent rétrograder intelligemment.
Exemple : si une équipe construit une intégration Koder.ai depuis un réseau d’entreprise partagé, une limite uniquement IP peut bloquer toute leur org et ressembler à des pannes aléatoires. Des dimensions claires et des réponses 429 explicites évitent cela.
Checklist rapide avant de déployer
Ajoutez des réponses 429 claires
Laissez Koder.ai rédiger des corps 429 cohérents ainsi que Retry-After et les en-têtes RateLimit.
Avant d’activer les limites pour tout le monde, faites un dernier passage axé sur la prévisibilité :
- Définissez des limites par palier de tarification et groupe d’endpoints (auth, lectures, écritures, exports). Gardez une petite marge de sécurité pour l’essentiel comme la connexion et le refresh de token.
- Rendre les règles d’identité déterministes et documentées. Décidez exactement comment vous comptez (user, org, API key, IP) et ce qui a la priorité.
- Faites des réponses 429 auto‑explicatives. Incluez
Retry-After plus des en-têtes RateLimit (Limit, Remaining, Reset). Dans le corps JSON, incluez un message court, quelle limite a été atteinte, et quand retenter.
- Surveillez à la fois les pics et les faux positifs. Suivez le taux de 429 par groupe d’endpoints, les principaux callers et les chutes soudaines des requêtes réussies. Alertez quand les blocages augmentent.
- Ayez un plan d’exceptions : whitelists, augmentations temporaires, overrides d’urgence et qui peut les approuver.
Un test instinctif : si votre produit a des paliers comme Free, Pro, Business et Enterprise (comme Koder.ai), vous devriez pouvoir expliquer en langage simple ce qu’un client normal peut faire par minute et par jour, et quels endpoints sont traités différemment.
Si vous ne pouvez pas expliquer clairement un 429, les clients supposeront que l’API est cassée, pas qu’elle protège le service.
Exemple de plan de déploiement et prochaines étapes
Imaginez un SaaS B2B où les gens travaillent dans un workspace (org). Quelques power users lancent de gros exports, et beaucoup d’employés sont derrière une IP d’entreprise partagée. Si vous ne limitez que par IP, vous bloquez des sociétés entières. Si vous ne limitez que par user, un script unique peut toujours nuire à tout le workspace.
Un mélange pratique est :
- Limite de rafale par utilisateur pour les pics courts.
- Limite soutenue par org pour garder le workspace équitable sur la durée.
- Garde anti‑abus par IP pour attraper tokens compromis, bots et réseaux bruyants.
Quand quelqu’un atteint une limite, votre message doit expliquer ce qui s’est passé, quoi faire ensuite et quand retenter. Le support doit pouvoir s’appuyer sur un texte du type :
“Request rate exceeded for workspace ACME. You can retry after 23 seconds. If you are running an export, reduce concurrency to 2 or schedule it off-peak. If this blocks normal use, reply with your workspace ID and timestamp and we can review your quota.”
Associez ce message à Retry-After et des en-têtes RateLimit cohérents pour que les clients n’aient pas à deviner.
Un déploiement qui évite les surprises : observer d’abord, puis avertir (en-têtes et warnings soft), puis appliquer (429s avec un timing clair pour retenter), puis ajuster les seuils par palier, et enfin revoir après de grands lancements et intégrations clients.
Si vous voulez une façon rapide de transformer ces idées en code opérationnel, une plateforme vibe‑coding comme Koder.ai (koder.ai) peut vous aider à rédiger une spec de rate limit et à générer du middleware Go qui l’applique de manière cohérente à travers vos services.