Pourquoi les identifiants de corrélation importent pour le support
Le support ne reçoit presque jamais un rapport de bug propre. Un utilisateur dit « j'ai cliqué sur Payer et ça a échoué », mais ce simple clic peut toucher le navigateur, une passerelle API, un service de paiement, une base de données et un job en arrière-plan. Chaque composant enregistre sa part de l'histoire à des moments différents, sur des machines différentes. Sans un même label partagé, on finit par deviner quelles lignes de log vont ensemble.
Un identifiant de corrélation est ce label partagé. C'est un identifiant attaché à une action utilisateur (ou à un workflow logique) et propagé à travers chaque requête, retry et saut entre services. Avec une couverture véritable de bout en bout, vous pouvez partir d'une plainte utilisateur et reconstituer la chronologie complète à travers les systèmes.
On confond souvent plusieurs identifiants similaires. Voici la séparation claire :
- Identifiant de corrélation : regroupe tout ce qui concerne une même action (par exemple, « Enregistrer les paramètres »).
- Request ID : identifie une requête HTTP unique. Les retries créent de nouveaux request IDs.
- Trace ID : utilisé par les outils de traçage distribué ; objectif similaire, souvent généré par les bibliothèques de traçage.
- Session ID : identifie une session utilisateur sur plusieurs actions ; trop large pour diagnostiquer un incident précis.
Le bon fonctionnement est simple : un utilisateur signale un problème, vous lui demandez l'identifiant de corrélation affiché dans l'UI (ou disponible dans un écran de support), et n'importe qui dans l'équipe peut retrouver l'histoire complète en quelques minutes. Vous voyez la requête frontend, la réponse API, les étapes backend et le résultat en base, tous liés entre eux.
Définissez vos conventions d'identifiants de corrélation
Avant de générer quoi que ce soit, mettez-vous d'accord sur quelques règles. Si chaque équipe choisit un nom d'en-tête ou un champ de log différent, le support devra encore deviner.
Commencez par un nom canonique et utilisez-le partout. Un choix courant est un en-tête HTTP comme X-Correlation-Id, plus un champ de log structuré comme correlation_id. Choisissez une orthographe et une casse, documentez-les, et assurez-vous que votre reverse proxy ou gateway ne renommera ni ne supprimera cet en-tête.
Choisissez un format facile à créer et sûr à partager dans les tickets et les chats. Les UUID fonctionnent bien car ils sont uniques et neutres. Gardez l'ID assez court pour le copier, mais pas trop court pour éviter les collisions. La consistance l'emporte sur l'originalité.
Décidez aussi où l'ID doit apparaître pour que les humains puissent réellement l'utiliser. Concrètement, cela signifie qu'il doit être présent dans les requêtes, les logs et les sorties d'erreur, et qu'il doit être consultable dans l'outil que votre équipe utilise.
Définissez la durée de vie d'un ID. Un bon défaut est « une action utilisateur », comme « a cliqué sur Payer » ou « a enregistré le profil ». Pour les workflows plus longs qui traversent services et files d'attente, gardez le même ID jusqu'à la fin du workflow, puis démarrez-en un nouveau pour l'action suivante. Évitez « un ID pour toute la session » car les recherches deviennent vite bruyantes.
Règle importante : ne jamais inclure de données personnelles dans l'ID. Pas d'emails, de numéros de téléphone, d'identifiants utilisateur ou de numéros de commande. Si vous avez besoin de ce contexte, consignez-le dans des champs séparés avec les contrôles de confidentialité appropriés.
Générer l'ID dans le frontend (approche pratique)
Le moyen le plus simple de démarrer un identifiant de corrélation est au moment où l'utilisateur commence une action importante : cliquer sur « Enregistrer », soumettre un formulaire ou lancer un flux qui déclenche plusieurs requêtes. Si vous attendez que le backend le crée, vous perdez souvent la première partie de l'histoire (erreurs UI, retries, requêtes annulées).
Utilisez un format aléatoire et unique. UUID v4 est un choix courant car il est facile à générer et peu susceptible de collisionner. Gardez-le opaque (pas de noms d'utilisateur, emails ou timestamps) pour ne pas divulguer de données personnelles dans les en-têtes et les logs.
Créer et conserver l'ID pour un workflow
Considérez un « workflow » comme une action utilisateur qui peut déclencher plusieurs requêtes : validation, upload, création d'enregistrement, puis rafraîchissement des listes. Créez un ID quand le workflow commence, puis conservez-le jusqu'à la fin du workflow (succès, échec ou annulation par l'utilisateur). Un pattern simple est de le stocker dans l'état d'un composant ou dans un objet de contexte de requête léger.
Si l'utilisateur lance la même action deux fois, générez un nouvel identifiant de corrélation pour la seconde tentative. Cela permet au support de distinguer « même clic réessayé » et « deux soumissions distinctes ».
L'attacher à chaque requête faite par ce workflow
Ajoutez l'ID à chaque appel API déclenché par le workflow, généralement via un en-tête comme X-Correlation-ID. Si vous utilisez un client API partagé (wrapper fetch, instance Axios, etc.), passez l'ID une fois et laissez le client l'injecter dans tous les appels.
const correlationId = crypto.randomUUID();
await api.post('/orders', payload, {
headers: { 'X-Correlation-ID': correlationId }
});
await api.get('/orders/summary', {
headers: { 'X-Correlation-ID': correlationId }
});
Si votre UI effectue des requêtes en arrière-plan non liées à l'action (polling, analytics, auto-refresh), ne réutilisez pas l'ID du workflow pour celles-ci. Gardez les identifiants de corrélation ciblés pour qu'un ID raconte une seule histoire.
Faire transiter l'ID de manière fiable à travers vos APIs
Une fois que vous générez un identifiant de corrélation dans le navigateur, la tâche est simple : il doit quitter le frontend à chaque requête et arriver inchangé à chaque frontière d'API. C'est ce qui casse le plus souvent quand les équipes ajoutent de nouveaux endpoints, de nouveaux clients ou du middleware.
Le défaut le plus sûr est un en-tête HTTP sur chaque appel (par exemple, X-Correlation-Id). Les en-têtes sont faciles à ajouter en un seul endroit (un wrapper fetch, un interceptor Axios, une couche réseau mobile) et n'exigent pas de modifier les payloads.
Si vous avez des requêtes cross-origin, assurez-vous que votre API autorise cet en-tête. Sinon le navigateur peut le bloquer silencieusement et vous penserez l'envoyer alors que ce n'est pas le cas.
Si vous devez mettre l'ID dans la query string ou le corps de la requête (certains outils tiers ou uploads de fichiers l'exigent), restez cohérent et documentez-le. Choisissez un nom de champ et utilisez-le partout. Ne mélangez pas correlationId, requestId et cid selon l'endpoint.
Les retries sont un autre piège fréquent. Un retry doit garder le même identifiant de corrélation s'il concerne toujours la même action utilisateur. Exemple : un utilisateur clique sur « Enregistrer », le réseau tombe, votre client réessaie le POST. Le support doit voir une seule trace connectée, pas trois indépendantes. Un nouveau clic utilisateur (ou un nouveau job en arrière-plan) doit obtenir un nouvel ID.
Pour les WebSockets, incluez l'ID dans l'enveloppe du message, pas uniquement lors du handshake initial. Une connexion peut porter de nombreuses actions utilisateur.
Pour un contrôle de fiabilité rapide, simplifiez :
- Un helper client partagé ajoute l'en-tête sur chaque requête.
- Les retries réutilisent le même ID pour la même action.
- Tout fallback body/query utilise un seul nom de champ documenté.
- Les messages WebSocket incluent un champ
correlationId explicite.
Comportement au point d'entrée API
Publiez des écrans d'erreur prêts pour le support
Créez des erreurs UI qui affichent un identifiant de corrélation copiable pour accélérer les tickets.
Votre bordure API (gateway, load balancer ou premier service qui reçoit le trafic) est l'endroit où les identifiants de corrélation deviennent fiables ou se transforment en devinettes. Traitez ce point d'entrée comme la source de vérité.
Acceptez un ID entrant si le client en envoie un, mais ne supposez pas qu'il sera toujours présent. S'il manque, générez-en un nouveau immédiatement et utilisez-le pour le reste de la requête. Cela maintient le fonctionnement même quand certains clients sont anciens ou mal configurés.
Faites une validation légère pour que de mauvaises valeurs ne polluent pas vos logs. Restez permissif : vérifiez la longueur et les caractères autorisés, mais évitez des formats stricts qui rejetteraient du trafic réel. Par exemple, autorisez 16-64 caractères et lettres, chiffres, tiret et underscore. Si la valeur échoue à la validation, remplacez-la par un ID frais et continuez.
Rendez l'ID visible pour l'appelant. Renvoyez-le toujours dans les en-têtes de réponse, et incluez-le dans les corps d'erreur. Ainsi un utilisateur peut le copier depuis l'UI, ou un agent support peut le demander et retrouver la piste exacte.
Une politique d'entrée pratique ressemble à ceci :
- Lire
X-Correlation-ID (ou l'en-tête choisi) depuis la requête.
- S'il est manquant ou invalide, créer un nouvel ID et l'attacher au contexte de requête.
- Ajouter
X-Correlation-ID à chaque réponse, y compris les erreurs.
- Lors du retour d'erreurs JSON, renvoyer l'ID dans le payload.
Exemple de payload d'erreur (ce que le support devrait voir dans les tickets et captures d'écran) :
{
"error": {
"code": "PAYMENT_FAILED",
"message": "We could not confirm the payment.",
"correlation_id": "c3a8f2d1-9b24-4c61-8c4a-2a7c1b9c2f61"
}
}
Une fois qu'une requête atteint votre backend, traitez l'identifiant de corrélation comme faisant partie du contexte de requête, pas comme quelque chose à stocker dans une variable globale. Les globals cassent dès que vous traitez deux requêtes simultanément, ou quand du travail asynchrone continue après la réponse.
Une règle qui scale : chaque fonction pouvant logger ou appeler un autre service doit recevoir le contexte contenant l'ID. Dans les services Go, cela signifie généralement passer context.Context à travers les handlers, la logique métier et le code client.
Quand le Service A appelle le Service B, recopiez le même ID dans la requête sortante. Ne générez pas un nouvel ID en cours de route sauf si vous conservez aussi l'original comme champ séparé (par exemple parent_correlation_id). Si vous changez les IDs, le support perd le fil unique qui relie l'histoire.
La propagation est souvent oubliée à quelques endroits prévisibles : jobs en arrière-plan déclenchés pendant la requête, retries internes des bibliothèques clients, webhooks déclenchés plus tard et appels en fan-out. Tout message asynchrone (queue/job) doit porter l'ID, et toute logique de retry doit le préserver.
Les logs doivent être structurés avec un nom de champ stable comme correlation_id. Choisissez une orthographe et conservez-la partout. Évitez de mélanger requestId, req_id et traceId sauf si vous définissez aussi un mapping clair.
Si possible, incluez l'ID dans la visibilité de la base de données aussi. Une approche pratique est de l'ajouter aux commentaires de requête ou aux métadonnées de session afin que les slow query logs puissent le montrer. Quand quelqu'un rapporte « le bouton Enregistrer a bloqué 10 secondes », le support peut chercher correlation_id=abc123 et voir le log API, l'appel service descendant et la requête SQL lente qui a causé le délai.
Inclure l'ID dans des logs exploitables par des humains
Un identifiant de corrélation n'aide que si les gens peuvent le trouver et le suivre. Faites-en un champ de log de première classe (pas enterré dans une chaîne message), et gardez le reste de l'entrée de log cohérent entre les services.
Champs de log qui rendent l'ID utile
Associez l'identifiant de corrélation à un petit ensemble de champs qui répondent : quand, où, quoi et qui (de façon sûre pour l'utilisateur). Pour la plupart des équipes, cela signifie :
timestamp (avec fuseau)service et env (api, worker, prod, staging)route (ou nom d'opération) et methodstatus et duration_ms- un identifiant utilisateur sûr (par exemple
account_id ou un id hashé, pas un email)
Avec cela, le support peut rechercher par ID, confirmer qu'il regarde la bonne requête et voir quel service l'a traitée.
Que logger au début, au succès et à l'échec
Visez quelques breadcrumbs pertinents par requête, pas une transcription intégrale.
- Début : correlation ID, route, identifiant utilisateur sûr, et entrées clés (résumées).
- Succès : correlation ID, statut, durée et un résultat court (par ex.
rows=12).
- Échec : correlation ID, type d'erreur, contexte sûr et où ça s'est produit (handler, dépendance).
Pour éviter le bruit, laissez les détails debug hors par défaut et ne promouvez que les événements qui aident à répondre « Où ça a échoué ? ». Si une ligne n'aide pas à localiser le problème ou mesurer l'impact, elle n'a probablement pas sa place au niveau info.
La redaction compte autant que la structure. Ne mettez jamais de PII dans l'identifiant de corrélation ou les logs : pas d'emails, de noms, de téléphones, d'adresses complètes ou de tokens bruts. Si vous devez identifier un utilisateur, loggez un ID interne ou un hash unidirectionnel.
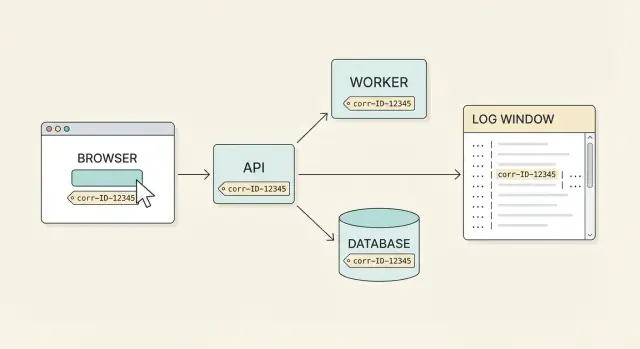
Exemple : tracer un signalement utilisateur de l'UI à la base
Tracer les workflows à travers les services
Concevez la propagation pour API, workers et files d'attente sans casser la chaîne de corrélation.
Un utilisateur contacte le support : « Le checkout a échoué quand j'ai cliqué sur Payer. » La meilleure question de suivi est simple : « Pouvez-vous coller l'identifiant de corrélation affiché sur l'écran d'erreur ? » Il répond cid=9f3c2b1f6a7a4c2f.
Le support a maintenant une poignée qui relie l'UI, l'API et la base. L'objectif est que chaque ligne de log pour cette action porte le même ID.
Le support cherche les logs pour 9f3c2b1f6a7a4c2f et voit le flux :
frontend INFO cid=9f3c2b1f6a7a4c2f event="checkout_submit" cart=3 items
api INFO cid=9f3c2b1f6a7a4c2f method=POST path=/api/checkout user=1842
api ERROR cid=9f3c2b1f6a7a4c2f msg="payment failed" provider=stripe status=502
De là, un ingénieur suit le même ID jusqu'au prochain saut. L'important est que les appels backend (et les jobs en file) transmettent aussi l'ID.
payments INFO cid=9f3c2b1f6a7a4c2f action="charge" amount=49.00 currency=USD
payments ERROR cid=9f3c2b1f6a7a4c2f err="timeout" upstream=stripe timeout_ms=3000
db INFO cid=9f3c2b1f6a7a4c2f query="insert into failed_payments" rows=1
Maintenant le problème est concret : le service de paiements a timeouté après 3 secondes, et un enregistrement d'échec a été écrit. L'ingénieur peut vérifier les déploiements récents, confirmer si les paramètres de timeout ont changé et voir si des retries se produisent.
Pour boucler la boucle, faites quatre vérifications :
- Corriger la cause (par exemple, ajuster le timeout et ajouter un retry sûr).
- S'assurer que les erreurs visibles par l'utilisateur incluent l'identifiant de corrélation.
- Surveiller l'apparition de nouveaux logs avec le même motif d'erreur et des IDs différents.
- Confirmer que l'ID survit à chaque saut (y compris workers et messages en file).
Le moyen le plus rapide de rendre les identifiants de corrélation inutiles est de casser la chaîne. La plupart des échecs viennent de petites décisions qui paraissent inoffensives pendant la construction, mais qui posent problème quand le support a besoin de réponses.
Une erreur classique est de générer un nouvel ID à chaque saut. Si le navigateur envoie un ID, votre API gateway doit le conserver, pas le remplacer. Si vous avez vraiment besoin d'un ID interne aussi (pour un message en queue ou un job en arrière-plan), conservez l'original comme champ parent afin que l'histoire reste connectée.
Un autre manque fréquent est la journalisation partielle. Les équipes ajoutent l'ID dans le premier API, mais l'oublient dans les processus worker, les jobs planifiés ou la couche d'accès à la base. Le résultat est une impasse : vous voyez la requête entrer dans le système, mais pas où elle est allée ensuite.
Évitez le problème de « chaos de nommage »
Même quand l'ID existe partout, il peut être difficile à rechercher si chaque service utilise un nom ou un format différent. Choisissez un nom et tenez-vous-y à travers frontend, APIs et logs (par exemple correlation_id). Choisissez aussi un format (souvent un UUID), et considérez-le comme sensible à la casse pour que le copier-coller fonctionne.
Ne perdez pas l'ID quand tout va mal. Si une API renvoie un 500 ou une erreur de validation, incluez l'ID de corrélation dans la réponse d'erreur (et idéalement dans un en-tête de réponse aussi). Ainsi un utilisateur peut le coller dans un chat de support, et votre équipe peut immédiatement tracer le chemin complet.
Un test rapide : un membre du support peut-il partir d'un ID et suivre chaque ligne de log impliquée, y compris les échecs ?
Liste de contrôle rapide pour vérifier la couverture de bout en bout
Déployez une appli traçable plus rapidement
Passez du plan à une appli en fonctionnement sans configurer vous-même les serveurs.
Utilisez ceci comme vérification avant de dire au support « il suffit de rechercher dans les logs ». Ça ne marche que quand chaque saut suit les mêmes règles.
Vérifications indispensables
- Vous avez un seul format d'ID et un seul nom d'en-tête, utilisés partout (frontend, gateway, APIs, workers).
- Le frontend crée (ou reprend) l'ID au début d'une action utilisateur et le conserve stable jusqu'à la fin de cette action.
- Le point d'entrée API crée un ID s'il manque et le renvoie toujours dans les en-têtes de réponse.
- Chaque service backend inclut
correlation_id dans les logs liés à une requête en tant que champ structuré.
- L'équipe on-call peut coller un ID dans la recherche de logs et voir tout le chemin en quelques minutes : requête edge, auth, appels de service, opération base et retries.
Si une vérification échoue, corrigez ainsi
Choisissez le plus petit changement qui maintient la chaîne intacte.
- Si les IDs changent en cours de route, arrêtez de générer de nouveaux IDs dans les services internes. Conservez l'original
correlation_id et ajoutez un span_id séparé si vous avez besoin de plus de détail.
- Si les logs manquent le champ, ajoutez un middleware de logging afin que les ingénieurs n'aient pas à se souvenir de l'inclure manuellement.
- Si le support ne peut pas obtenir l'ID, assurez-vous que l'UI l'affiche sur les écrans d'erreur et que la gateway le renvoie sur chaque réponse.
Un test rapide qui repère les lacunes : ouvrez les outils de dev, déclenchez une action, copiez l'identifiant de corrélation de la première requête, puis confirmez que vous voyez la même valeur dans chaque requête API liée et chaque ligne de log correspondante.
Prochaines étapes : intégrez-le à votre processus de livraison
Les identifiants de corrélation n'aident que si tout le monde les utilise de la même manière, tout le temps. Traitez le comportement des identifiants comme une partie requise du shipping, pas comme un tweak optionnel des logs.
Ajoutez une petite vérification de traçabilité à votre définition de done pour chaque nouvel endpoint ou action UI. Couvrez comment l'ID est créé (ou réutilisé), où il vit pendant le flux, quel en-tête le transporte et ce que fait chaque service quand l'en-tête est manquant.
Une checklist légère suffit généralement :
- Frontend : générer ou réutiliser un ID par action utilisateur et l'attacher à chaque appel API pour cette action.
- Point d'entrée API : accepter l'en-tête, valider ou générer, puis le renvoyer dans la réponse.
- Backend : le transmettre aux services et jobs en aval, et l'inclure dans les logs.
- Logging : garder le même nom de champ (par exemple
correlation_id) dans toutes les applis et services.
- Revues : rejeter les PR qui ajoutent des endpoints sans tests prouvant que l'ID apparaît dans les logs.
Le support a aussi besoin d'un script simple pour que le debug soit rapide et reproductible. Décidez où l'ID apparaît pour les utilisateurs (par exemple, un bouton « Copier l'ID de debug » sur les boîtes d'erreur), et documentez ce que le support doit demander et où chercher.
Avant de compter dessus en production, exécutez un flux en staging qui ressemble à l'usage réel : cliquez sur un bouton, provoquez une erreur de validation, puis complétez l'action. Confirmez que vous pouvez suivre le même ID depuis la requête navigateur, à travers les logs API, dans tout worker en arrière-plan et jusqu'aux logs de requête base si vous les enregistrez.
Si vous construisez des applis sur Koder.ai, il est utile d'écrire vos conventions d'en-tête et de logging dans Planning Mode afin que les frontends React et les services Go générés commencent cohérents par défaut.