Qu'est‑ce qui rend une application centrée sur le document
Une application est centrée sur le document quand le document lui‑même est le produit que les utilisateurs créent, examinent et dont ils dépendent. L'expérience est construite autour de fichiers comme des PDF, images, scans et reçus, pas autour d'un formulaire où le fichier est une simple pièce jointe.
Dans les workflows centrés sur le document, les gens travaillent réellement à l'intérieur du document : ils l'ouvrent, vérifient ce qui a changé, ajoutent du contexte et décident de la suite. Si le document n'est pas fiable, l'application devient inutile.
La plupart des applications centrées sur le document ont besoin de quelques écrans de base dès le départ :
- Une inbox pour les nouveaux uploads, les éléments assignés et tout ce qui nécessite de l'attention
- Une vue détail du document avec aperçu, métadonnées, commentaires et historique
- Un flux de révision pour approuver, rejeter ou demander des modifications
- Une zone d'export/partage pour transmettre à un autre système
Les problèmes apparaissent vite. Les utilisateurs uploadent deux fois le même reçu. Quelqu'un modifie un PDF et le ré‑upload sans expliquer pourquoi. Un scan n'a ni date ni fournisseur ni propriétaire. Des semaines plus tard, personne ne sait quelle version a été approuvée ni sur quelle base la décision a été prise.
Une bonne application centrée sur le document donne une impression de rapidité et de fiabilité. Les utilisateurs doivent pouvoir répondre à ces questions en quelques secondes :
- Est‑ce la version la plus récente, et qui l'a modifiée ?
- Puis‑je prévisualiser immédiatement sans télécharger ?
- Qu'est‑ce que c'est, décrit en quelques champs simples filtrables ?
- Quel est son état actuel, et quelle action est attendue ?
Cette clarté vient des définitions. Avant de construire les écrans, décidez ce que « version », « preview », « métadonnées » et « statut » signifient dans votre appli. Si ces termes sont flous, vous aurez des doublons, un historique confus et des flux de révision qui ne correspondent pas au travail réel.
Concepts clés à modéliser avant de construire l'UI
L'UI paraît souvent simple (une liste, un visualiseur, quelques boutons), mais le modèle de données porte la charge. Si les objets centraux sont corrects, l'historique d'audit, les aperçus rapides et les approbations fiables deviennent beaucoup plus faciles.
Commencez par séparer l'« enregistrement de document » du « contenu du fichier ». L'enregistrement est ce dont les utilisateurs parlent (Facture d'ACME, reçu de taxi). Le contenu sont les octets (PDF, JPG) qui peuvent être remplacés, retraités ou déplacés sans changer ce que le document signifie dans l'application.
Un ensemble pratique d'objets à modéliser :
- Document : l'entrée stable que les utilisateurs recherchent, commentent et approuvent
- File : un blob stocké (PDF/image) avec taille, checksum, clé de stockage et type MIME
- Version : un instantané du document à un moment donné, pointant vers un ou plusieurs Files
- Preview : des actifs dérivés (miniature, image de première page, extrait de texte) liés à un File ou une Version
- Metadata : champs structurés (vendeur, total, date) plus sortie brute d'extraction et score de confiance
- Status : l'état métier courant du travail (needs review, approved, rejected)
Décidez ce qui reçoit un ID immuable. Une règle utile : l'ID du Document vit pour toujours, tandis que les Files et Previews peuvent être régénérés. Les Versions ont aussi besoin d'IDs stables, parce que les gens se réfèrent à « à quoi ça ressemblait hier » et vous aurez besoin d'une piste d'audit.
Modélisez les relations explicitement. Un Document a plusieurs Versions. Chaque Version peut avoir plusieurs Previews (tailles ou formats différents). Cela garde les écrans de liste rapides car ils chargent des données de preview légères, tandis que les écrans de détail n'ouvrent le fichier complet que quand c'est nécessaire.
Exemple : un utilisateur upload une photo froissée d'un reçu. Vous créez un Document, stockez le File original, générez une miniature Preview et créez la Version 1. Plus tard, l'utilisateur upload un scan plus net. Cela devient la Version 2, sans casser les commentaires, approbations ou recherches liées au Document.
Les gens s'attendent à ce qu'un document évolue sans « se transformer » en un élément différent. La façon la plus simple d'y parvenir est de séparer l'identité (le Document) du contenu (la Version et les Files).
Commencez par un document_id stable qui ne change jamais. Même si l'utilisateur ré‑upload le même PDF, remplace une photo floue ou télécharge un scan corrigé, cela doit rester le même enregistrement Document. Commentaires, affectations et logs d'audit s'attachent proprement à cet ID durable.
Traitez chaque changement significatif comme une nouvelle ligne version. Chaque version doit capturer qui l'a créée et quand, plus des pointeurs de stockage (clé de fichier, checksum, taille, nombre de pages) et des artefacts dérivés (texte OCR, images de preview) liés à ce fichier exact. Évitez « l'édition en place ». Cela semble plus simple au départ, mais casse la traçabilité et rend les bugs difficiles à démêler.
Pour des lectures rapides, conservez un current_version_id sur le document. La plupart des écrans n'ont besoin que de « la plus récente », vous n'avez donc pas à trier les versions à chaque chargement. Quand vous avez besoin de l'historique, chargez les versions séparément et affichez une timeline claire.
Les rollbacks ne sont qu'un changement de pointeur. Plutôt que de supprimer quoi que ce soit, remettez current_version_id sur une version plus ancienne. C'est rapide, sûr et garde la piste d'audit intacte.
Pour que l'historique reste compréhensible, enregistrez pourquoi chaque version existe. Un petit champ reason cohérent (avec une note optionnelle) évite une timeline pleine de mises à jour mystérieuses. Raisons courantes : remplacement par re‑upload, nettoyage de scan, correction OCR, redaction, édition d'approbation.
Exemple : une équipe finance upload une photo de reçu, la remplace par un scan plus net, puis corrige l'OCR pour que le total soit lisible. Chaque étape est une nouvelle version, mais le document reste un seul élément dans l'inbox. Si la correction OCR est incorrecte, le rollback est un clic parce que vous changez seulement current_version_id.
Previews et miniatures qui restent rapides et fiables
Dans les workflows centrés sur le document, l'aperçu est souvent l'élément principal avec lequel les utilisateurs interagissent. Si les previews sont lentes ou instables, l'application entière paraît cassée.
Considérez la génération d'aperçus comme un job séparé, pas quelque chose que l'écran d'upload attend. Sauvegardez d'abord le fichier original, redonnez la main à l'utilisateur, puis générez les previews en arrière‑plan. Cela garde l'UI réactive et rend les reprises sûres.
Stockez plusieurs tailles d'aperçus. Une taille unique ne convient jamais à tous les écrans : une miniature pour les listes, une image moyenne pour les vues scindées et des images pleine‑page pour la revue détaillée (page par page pour les PDFs).
Suivez l'état de preview explicitement pour que l'UI sache toujours quoi afficher : pending, ready, failed et needs_retry. Gardez des libellés conviviaux pour l'UI, mais des états clairs dans les données.
Pour garder le rendu rapide, mettez en cache les valeurs dérivées avec l'enregistrement de preview plutôt que de les recalculer à chaque vue. Champs courants : nombre de pages, largeur/hauteur du preview, rotation (0/90/180/270) et une « meilleure page pour la miniature » optionnelle.
Concevez pour des fichiers lents et compliqués. Un PDF scanné de 200 pages ou une photo de reçu très froissée peut prendre du temps. Utilisez un chargement progressif : affichez la première page prête dès qu'elle existe, puis complétez le reste.
Exemple : un utilisateur upload 30 photos de reçus. La vue liste affiche des miniatures « pending », puis chaque carte passe en « ready » au fur et à mesure que son aperçu finit. Si quelques‑unes échouent à cause d'une image corrompue, elles restent visibles avec une action de retry claire au lieu de disparaître ou de bloquer le lot.
Possédez ce que vous construisez
Exportez le code source à tout moment pour garder le contrôle total de votre produit.
Les métadonnées transforment un amas de fichiers en quelque chose que vous pouvez rechercher, trier, vérifier et approuver. Elles aident à répondre rapidement : Qu'est‑ce que c'est ? Qui l'a envoyé ? Est‑ce valide ? Que doit‑on faire ensuite ?
Une façon pratique de garder les métadonnées propres est de les séparer selon leur origine :
- Métadonnées système : nom de fichier, taille, type MIME, nombre de pages, heure d'upload, checksum
- Métadonnées extraites : texte OCR, champs détectés (vendeur, date, total), valeurs de codes‑barres/QR
- Métadonnées saisies par l'utilisateur : corrections, tags, notes, catégorisation, commentaires d'approbation
Ces compartiments évitent les disputes ultérieures. Si un montant est erroné, vous verrez s'il vient de l'OCR ou d'une saisie humaine.
Pour les reçus et factures, un petit ensemble de champs paye s'il est utilisé de manière cohérente (mêmes noms, mêmes formats). Champs ancrés courants : vendor, date, total, currency et document_number. Gardez‑les optionnels au départ. Les gens uploadent des scans partiels et des photos floues, et bloquer le flux car un champ manque ralentit tout.
Traitez les valeurs inconnues comme des cas normaux. Utilisez des états explicites comme null/unknown, et ajoutez une raison quand utile (page manquante, illisible, non applicable). Cela permet au document d'avancer tout en montrant aux réviseurs ce qui nécessite de l'attention.
Stockez aussi la provenance et la confiance pour les champs extraits. La source peut être user, OCR, import ou API. La confiance peut être un score 0–1 ou une petite échelle comme high/medium/low. Si l'OCR lit “$18.70” avec une faible confiance parce que le dernier chiffre est maculé, l'UI peut le mettre en évidence et demander une confirmation rapide.
Les documents multipages nécessitent une décision supplémentaire : qu'est‑ce qui appartient au document entier vs. à une page unique. Les totaux et le vendeur appartiennent généralement au document. Les notes par page, les redactions, la rotation et la classification par page appartiennent souvent au niveau page.
États de statut qui correspondent au travail réel
Le statut répond à une question : « Où en est ce document dans le process ? » Gardez‑le petit et sans fantaisie. Si vous ajoutez un nouveau statut à chaque fois que quelqu'un le demande, vous vous retrouverez avec des filtres en qui personne ne fait confiance.
Un ensemble pratique d'états métier qui mappe des décisions réelles :
- Imported : le fichier existe, mais rien n'a encore été vérifié
- Needs review : une personne doit confirmer des champs clés ou la lisibilité
- Approved : prêt à être utilisé en aval (payer, archiver, publier ou exporter)
- Rejected : inutilisable, avec une raison
- Archived : conservé pour l'historique, hors du travail actif
Gardez le « processing » hors du statut métier. L'OCR en cours et la génération d'aperçu décrivent ce que le système fait, pas ce qu'une personne doit faire ensuite. Stockez‑les comme états de traitement séparés.
Séparez aussi l'assignation du statut (assignee_id, team_id, due_date). Un document peut être Approved mais toujours assigné pour un suivi, ou Needs review sans propriétaire.
Enregistrez l'historique des statuts, pas seulement la valeur courante. Un simple log (from_status, to_status, changed_at, changed_by, reason) rendra service quand quelqu'un demandera « Qui a rejeté ce reçu et pourquoi ? »
Enfin, décidez quelles actions sont autorisées pour chaque statut. Gardez les règles simples : Imported peut passer à Needs review ; Approved est en lecture seule sauf si une nouvelle version est créée ; Rejected peut être rouvert mais doit garder la raison précédente.
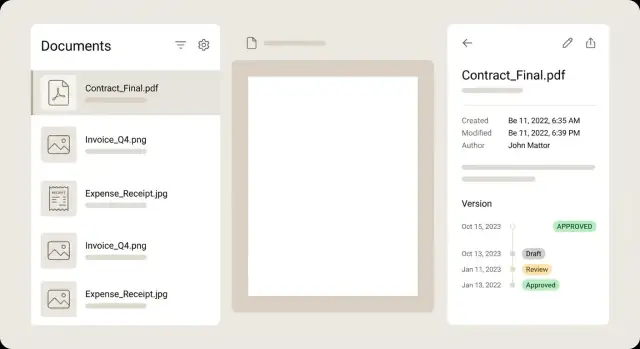
Patterns UI pour listes, vues détail et flux de révision
La plupart du temps se passe à parcourir une liste, ouvrir un élément, corriger quelques champs et passer au suivant. Une bonne UI rend ces étapes rapides et prévisibles.
Pour la liste de documents, traitez chaque ligne comme un résumé pour que les utilisateurs décident sans ouvrir chaque fichier. Une ligne forte montre une petite miniature, un titre clair, quelques champs clés (marchand, date, total), un badge de statut et un avertissement discret quand quelque chose nécessite de l'attention.
Gardez la vue détail calme et scannable. Une mise en page courante : aperçu à gauche et métadonnées à droite, avec contrôles d'édition à côté de chaque champ. Les utilisateurs doivent pouvoir zoomer, pivoter et feuilleter sans perdre leur place dans le formulaire. Si un champ est extrait par OCR, affichez un petit indice de confiance et, idéalement, mettez en surbrillance la zone source dans l'aperçu quand le champ est focalisé.
Les versions fonctionnent mieux en timeline, pas en dropdown. Montrez qui a changé quoi et quand, et laissez ouvrir toute version passée en lecture seule. Si vous proposez une comparaison, focalisez‑vous sur les différences de métadonnées (montant modifié, vendeur corrigé) plutôt que de forcer une comparaison pixel par pixel du PDF.
Le mode révision doit optimiser la vitesse. Un flux de triage axé clavier suffit souvent : actions rapides approuver/rejeter, corrections rapides pour les champs courants et une petite zone de commentaire pour les rejets.
Les états vides comptent car les documents sont souvent en cours de traitement. Au lieu d'un cadre vide, expliquez ce qui se passe : « Preview en cours », « OCR en cours » ou « Aucun aperçu pour ce type de fichier ».
Étape par étape : un workflow simple de l'upload à l'approbation
Planifiez clairement votre workflow
Définissez statuts, états de traitement et actions autorisées avant de générer les écrans.
Un workflow simple ressemble à « uploader, vérifier, approuver ». Sous le capot, cela marche mieux quand vous séparez le fichier lui‑même (versions et previews) du sens métier (métadonnées et statut).
1) L'upload arrive dans une inbox
L'utilisateur upload un PDF, une photo ou un scan de reçu et le voit immédiatement dans une inbox. N'attendez pas la fin du traitement. Affichez un nom de fichier, l'heure d'upload et un badge clair comme « Processing ». Si vous connaissez déjà la source (import email, appareil mobile, glisser‑déposer), affichez‑la aussi.
2) Créez Document + Version, la preview démarre en pending
À l'upload, créez un enregistrement Document (l'entité longue durée) et une Version (ce fichier spécifique). Mettez current_version_id sur la nouvelle version. Stockez preview_state = pending et extraction_state = pending pour que l'UI indique honnêtement ce qui est prêt.
La vue détail doit s'ouvrir immédiatement, mais montrer un visualiseur de remplacement et un message clair « Préparation de l'aperçu » au lieu d'un cadre cassé.
Un job en arrière‑plan crée des miniatures et un aperçu consultable (images de pages pour les PDFs, images redimensionnées pour les photos). Un autre job extrait les métadonnées (vendeur, date, total, currency, type de document). Quand chaque job finit, mettez à jour seulement son état et ses timestamps pour pouvoir relancer les échecs sans toucher au reste.
Gardez l'UI compacte : affichez l'état preview, l'état des données et mettez en évidence les champs à faible confiance.
4) Le réviseur corrige les champs, change le statut, ajoute des notes
Quand l'aperçu est prêt, les réviseurs corrigent les champs, ajoutent des notes et font avancer le document à travers les statuts métier comme Imported -> Needs review -> Approved (ou Rejected). Loggez qui a changé quoi et quand.
Si un réviseur upload un fichier corrigé, il devient une nouvelle Version et le document retourne automatiquement en Needs review.
5) L'aval lit la version courante et les métadonnées approuvées
Les exports, synchronisations comptables ou rapports internes doivent lire depuis current_version_id et le snapshot de métadonnées approuvées, pas « la dernière extraction ». Cela empêche un re‑upload à moitié traité de changer les chiffres.
Erreurs courantes et pièges à éviter
Les workflows centrés sur le document échouent pour des raisons banales : des raccourcis pris tôt deviennent des douleurs quotidiennes quand les gens uploadent des doublons, corrigent des erreurs ou demandent « Qui a changé ça et quand ? »
Traiter le nom de fichier comme identité du document est une erreur classique. Les noms changent, les utilisateurs ré‑uploadent et les appareils photo génèrent des duplicatas comme IMG_0001. Donnez à chaque document un ID stable, et traitez le nom de fichier comme une étiquette.
Écraser le fichier original quand quelqu'un upload un remplacement cause aussi des problèmes. Cela paraît plus simple, mais vous perdez la piste d'audit et vous ne pouvez plus répondre à des questions basiques (ce qui a été approuvé, ce qui a été édité, ce qui a été envoyé). Gardez le binaire immuable et ajoutez un nouvel enregistrement de version.
La confusion des statuts crée des bugs subtils. « OCR running » n'est pas la même chose que « Needs review ». Les états de traitement décrivent l'activité système ; le statut métier décrit l'action humaine suivante. Quand ils sont mélangés, les documents se retrouvent dans la mauvaise catégorie.
Les décisions UI peuvent aussi créer de la friction. Si vous bloquez l'écran jusqu'à ce que les previews soient générés, les gens perçoivent l'app comme lente même si l'upload a réussi. Affichez le document immédiatement avec un placeholder clair, puis remplacez par les miniatures quand elles sont prêtes.
Enfin, les métadonnées deviennent peu fiables si vous stockez des valeurs sans provenance. Si le total vient de l'OCR, indiquez‑le. Conservez les horodatages.
Une liste de contrôle rapide :
- ID de document stable séparé du nom de fichier
- Nouvelle version par remplacement, pas d'overwrite
- Statut métier séparé de l'état de traitement
- Chargement non bloquant des previews et miniatures
- Métadonnées avec source et timestamps
Exemple : dans une appli de reçus, un utilisateur ré‑upload une photo plus nette. Si vous versionnez, gardez l'ancienne image, marquez l'OCR en reprocessing, et conservez Needs review jusqu'à confirmation humaine du montant.
Vérification rapide avant le lancement
Faites de la gestion des versions une exigence
Ajoutez l'historique des versions et un pointeur current_version pour que les approbations restent traçables.
Les workflows centrés sur le document paraissent « prêts » seulement quand les gens peuvent faire confiance à ce qu'ils voient et récupérer quand ça plante. Avant le lancement, testez avec des documents réels et compliqués (reçus flous, PDFs pivotés, uploads répétés).
Cinq vérifications qui attrapent la plupart des surprises :
- La version courante est indubitable. Marquez la version active, montrez qui l'a modifiée en dernier et quand, et ajoutez un court motif comme « recadré » ou « re‑uploadé ».
- Les previews échouent en douceur. Si un aperçu est encore en génération, affichez un placeholder utile (nom de fichier, heure d'upload, nombre de pages si connu) et un état pending clair. Si la génération échoue, affichez une erreur et une option de retry.
- Les statuts correspondent aux actions. Chaque statut a un sens clair et un petit ensemble d'actions autorisées. Si Approved existe, rendez‑le en lecture seule.
- Les edits de métadonnées ne suppriment pas l'extraction. Laissez corriger l'OCR sans perdre la valeur extraite d'origine. Conservez les deux et montrez laquelle est utilisée.
- La récupération est intégrée. Facilitez les corrections courantes : revenir à une version antérieure, relancer l'extraction, régénérer les previews.
Un test de réalité : demandez à quelqu'un de revoir trois reçus similaires et de faire volontairement une mauvaise modification sur l'un. S'il peut repérer la version courante, comprendre le statut et corriger l'erreur en moins d'une minute, vous êtes proche.
Scénario d'exemple et prochaines étapes pratiques
Le remboursement mensuel de reçus est un exemple clair de travail centré sur le document. Un employé upload des reçus, puis deux réviseurs les vérifient : un manager, puis la finance. Le reçu est le produit ; votre appli vit ou meurt sur le versioning, les previews, les métadonnées et des statuts clairs.
Jamie upload une photo d'un reçu de taxi. Votre système crée le Document #1842 avec la Version v1 (le fichier original), une miniature et un preview, et des métadonnées comme merchant, date, currency, total et un score de confiance OCR. Le document passe en Imported, puis en Needs review quand preview et extraction sont prêts.
Plus tard, Jamie upload accidentellement le même reçu. Une détection de doublon (hash de fichier plus comparaison merchant/date/total similaire) peut proposer : « Semble être un doublon de #1842. Attacher quand même ou ignorer ? » Si l'utilisateur attache, stockez‑le comme un autre File lié au même Document pour conserver un seul fil de révision et un seul statut.
Pendant la révision, le manager voit l'aperçu, les champs clés et les avertissements. L'OCR a deviné $18.00 alors que l'image montre clairement $13.00. Jamie corrige le total. Ne supprimez pas l'historique. Créez la Version v2 avec les champs mis à jour, gardez v1 inchangée et loggez « Total corrigé par Jamie ».
Si vous voulez construire ce type de workflow rapidement, Koder.ai (koder.ai) peut vous aider à générer la première version de l'app à partir d'un plan de chat, mais la même règle s'applique : définissez d'abord les objets et états, puis laissez les écrans suivre.
Prochaines étapes pratiques :
- Esquissez le modèle de données : Document, Version, File, ExtractedField, Review, StatusHistory
- Concevez deux écrans : inbox (statut + avertissements) et vue détail (preview + champs + versions)
- Testez avec cinq reçus réels et itérez sur les statuts, règles de doublons et rapidité de révision