23 oct. 2025·7 min
Filtrage côté serveur vs côté client : une checklist de décision
Checklist filtrage côté serveur vs côté client selon taille des données, latence, permissions et cache, pour éviter fuites UI et lenteurs.
Checklist filtrage côté serveur vs côté client selon taille des données, latence, permissions et cache, pour éviter fuites UI et lenteurs.
Le filtrage dans une interface est plus qu'une simple barre de recherche. Il inclut souvent plusieurs actions liées qui changent ce que l'utilisateur voit : recherche textuelle (nom, email, identifiant de commande), facettes (statut, propriétaire, plage de dates, tags) et tri (plus récent, valeur la plus élevée, dernière activité).
La question clé n'est pas quelle technique est « meilleure », mais où réside l'ensemble de données complet et qui y a accès. Si le navigateur reçoit des enregistrements que l'utilisateur ne devrait pas voir, l'UI peut exposer des données sensibles même si vous les cachez visuellement.
La plupart des débats sur filtrage côté serveur vs côté client réagissent en réalité à deux échecs que les utilisateurs remarquent immédiatement :
Il y a un troisième problème qui génère des rapports de bugs sans fin : résultats incohérents. Si certains filtres s'exécutent côté client et d'autres côté serveur, les utilisateurs voient des comptes, des pages et des totaux qui ne correspondent pas. Cela brise rapidement la confiance, surtout sur les listes paginées.
Une règle pratique : si l'utilisateur n'est pas autorisé à accéder à l'ensemble complet, filtrez côté serveur. S'il est autorisé et que le jeu de données est suffisamment petit pour être chargé rapidement, le filtrage côté client peut convenir.
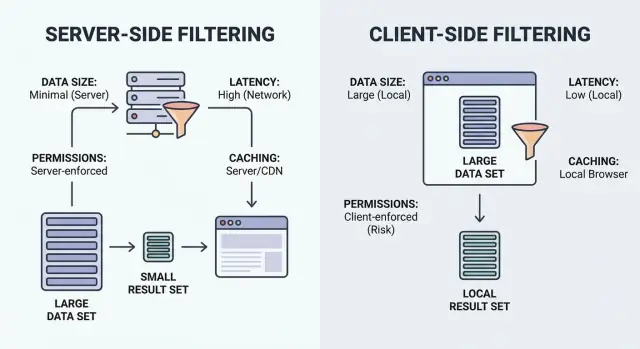
Filtrer, c'est simplement « montre-moi les éléments qui correspondent ». La question est où la correspondance se fait : dans le navigateur (client) ou sur votre backend (serveur).
Filtrage côté client s'exécute dans le navigateur. L'app télécharge un ensemble d'enregistrements (souvent en JSON), puis applique les filtres localement. Cela peut sembler instantané après le chargement, mais ne fonctionne que si le jeu de données est suffisamment petit à envoyer et suffisamment sûr à exposer.
Filtrage côté serveur s'exécute sur votre backend. Le navigateur envoie les critères (par exemple status=open, owner=me, createdAfter=Jan 1) et le serveur retourne seulement les résultats correspondants. En pratique, il s'agit d'un endpoint API qui accepte des filtres, construit une requête base de données et renvoie une liste paginée avec des totaux.
Un modèle mental simple :
Les architectures hybrides sont courantes. Un bon schéma consiste à faire appliquer les gros filtres côté serveur (permissions, appartenance, plage de dates, recherche), puis à utiliser de petits bascules UI localement (cacher les archivés, chips de tags rapides, visibilité de colonnes) sans nouvelle requête.
Le tri, la pagination et la recherche font généralement partie de la même décision. Ils affectent la taille des payloads, la sensation utilisateur et les données exposées.
Commencez par la question la plus pragmatique : combien de données enverriez-vous au navigateur si vous filtriez côté client ? Si la réponse honnête est « plus que quelques écrans », vous le paierez en temps de téléchargement, en mémoire et en interactions plus lentes.
Vous n'avez pas besoin d'estimations parfaites. Obtenez juste l'ordre de grandeur : combien de lignes l'utilisateur pourrait voir, et quelle est la taille moyenne d'une ligne ? Une liste de 500 éléments avec quelques champs courts n'est pas la même chose que 50 000 éléments où chaque ligne contient de longues notes, du texte riche ou des objets imbriqués.
Les enregistrements larges sont les tueurs silencieux de payloads. Un tableau peut paraître petit en nombre de lignes mais lourd si chaque ligne contient beaucoup de champs, de longues chaînes ou des données jointes (contact + entreprise + dernière activité + adresse complète + tags). Même si vous n'affichez que trois colonnes, les équipes envoient souvent « tout, au cas où », et le payload explose.
Pensez aussi à la croissance. Un jeu de données acceptable aujourd'hui peut devenir pénible en quelques mois. Si les données croissent vite, considérez le filtrage côté client comme un raccourci à court terme, pas comme un choix par défaut.
Règles empiriques :
Ce dernier point importe pour autre chose que la performance : « Peut-on envoyer tout le jeu de données au navigateur ? » est aussi une question de sécurité. Si la réponse n'est pas un oui confiant, ne l'envoyez pas.
Les choix de filtrage échouent souvent sur le ressenti, pas sur la justesse. Les utilisateurs ne mesurent pas les millisecondes ; ils remarquent les pauses, les scintillements et les résultats qui sautent pendant qu'ils tapent.
Le temps peut se perdre à différents endroits :
Définissez ce que « assez rapide » signifie pour cet écran. Une vue en liste peut nécessiter une saisie réactive et un défilement fluide, tandis qu'une page de rapport peut tolérer une courte attente si le premier résultat apparaît rapidement.
Ne jugez pas seulement sur le Wi‑Fi du bureau. Sur des connexions lentes, le filtrage côté client peut paraître agréable après le premier chargement, mais ce premier chargement peut être lent. Le filtrage côté serveur garde les payloads petits, mais peut paraître lent si vous envoyez une requête à chaque frappe.
Concevez autour des saisies humaines. Débouncez les requêtes pendant la saisie. Pour de grands ensembles de résultats, utilisez un chargement progressif pour afficher quelque chose rapidement et rester fluide au fur et à mesure du défilement.
Les permissions doivent dicter votre approche plus que la vitesse. Si le navigateur reçoit des données qu'un utilisateur n'a pas le droit de voir, vous avez déjà un problème, même si vous les cachez derrière un bouton désactivé ou une colonne repliée.
Commencez par nommer ce qui est sensible sur cet écran. Certains champs sont évidents (emails, téléphones, adresses). D'autres sont faciles à oublier : notes internes, coûts ou marges, règles de tarification spéciales, scores de risque, indicateurs de modération.
Le piège majeur est « on filtre côté client, mais on n'affiche que les lignes permises ». Cela signifie quand même que l'ensemble complet a été téléchargé. N'importe qui peut inspecter la réponse réseau, ouvrir les devtools ou sauvegarder le payload. Cacher des colonnes dans l'UI n'est pas un contrôle d'accès.
Le filtrage côté serveur est le choix sûr par défaut lorsque l'autorisation varie selon l'utilisateur, surtout quand différents utilisateurs peuvent voir différentes lignes ou champs.
Checklist rapide :
Si la réponse à une de ces questions est oui, appliquez le filtrage et la sélection de champs côté serveur. N'envoyez que ce que l'utilisateur est autorisé à voir, et appliquez les mêmes règles à la recherche, au tri, à la pagination et aux exports.
Exemple : dans une liste de contacts CRM, les commerciaux ne voient que leurs comptes tandis que les managers voient tout. Si le navigateur télécharge tous les contacts et filtre localement, un commercial peut récupérer les comptes cachés depuis la réponse. Le filtrage côté serveur évite cela en ne renvoyant jamais ces lignes.
Le cache peut rendre un écran instantané. Il peut aussi afficher une vérité erronée. L'important est de décider ce que vous pouvez réutiliser, pendant combien de temps, et quels événements doivent l'invalider.
Commencez par choisir l'unité de cache. Cacher une liste complète est simple mais gaspille souvent de la bande passante et devient vite périmé. Cacher des pages fonctionne bien pour le scroll infini. Cacher des résultats de requête (filtre + tri + recherche) est précis, mais peut croître vite si les utilisateurs testent beaucoup de combinaisons.
La fraîcheur importe plus dans certains domaines. Si les données changent rapidement (niveaux de stock, soldes, statut de livraison), même un cache de 30 secondes peut perturber les utilisateurs. Si les données changent lentement (archives, données de référence), un cache plus long est généralement acceptable.
Planifiez l'invalidation avant de coder. Outre le temps, décidez ce qui doit forcer un rafraîchissement : créations/éditions/suppressions, changements de permissions, imports ou fusions en masse, transitions de statut, annulations/rollback et jobs en arrière-plan qui mettent à jour des champs filtrés.
Décidez aussi où le cache vit. La mémoire du navigateur accélère la navigation arrière/avant, mais peut fuiter des données entre comptes si vous ne la clé par utilisateur et organisation. Le cache backend est plus sûr pour les permissions et la cohérence, mais il doit inclure la signature complète du filtre et l'identité de l'appelant pour éviter les mélanges.
Le but est non négociable : l'écran doit paraître rapide sans fuir de données.
La plupart des équipes sont touchées par les mêmes motifs : une UI belle en démo, puis les vraies données, les vraies permissions et les vrais réseaux montrent les failles.
L'échec le plus sérieux est de traiter le filtrage comme de la simple présentation. Si le navigateur reçoit des enregistrements qu'il ne devrait pas, vous avez déjà perdu.
Deux causes communes :
Exemple : des stagiaires ne devraient voir que des leads de leur région. Si l'API renvoie toutes les régions et que le dropdown filtre dans React, les stagiaires peuvent toujours extraire la liste complète.
La lenteur provient souvent d'hypothèses :
Un problème subtil mais pénible est des règles discordantes. Si le serveur traite « commence par » différemment de l'UI, les utilisateurs voient des totaux qui ne correspondent pas, ou des éléments qui disparaissent après rafraîchissement.
Faites une passe finale avec deux états d'esprit : un utilisateur curieux et un jour de réseau pourri.
Un test simple : créez un enregistrement restreint et confirmez qu'il n'apparaît jamais dans le payload, les totaux ou le cache, même en filtrant largement ou en effaçant les filtres.
Imaginez un CRM avec 200 000 contacts. Les commerciaux ne voient que leurs comptes, les managers voient leur équipe et les admins voient tout. L'écran propose recherche, filtres (statut, propriétaire, dernière activité) et tri.
Le filtrage côté client échoue rapidement ici. Le payload est lourd, le premier chargement lent, et le risque de fuite élevé. Même si l'UI cache des lignes, le navigateur a quand même reçu les données. Vous surchargez aussi l'appareil : grands tableaux, tris lourds, exécutions répétées de filtres, forte consommation mémoire et crashs sur téléphones anciens.
Une approche plus sûre est le filtrage côté serveur avec pagination. Le client envoie ses choix de filtres et de recherche, et le serveur renvoie uniquement les lignes que l'utilisateur est autorisé à voir, déjà filtrées et triées.
Un schéma pratique :
Une petite exception où le filtrage côté client convient : des données minuscules et statiques. Un dropdown « Statut du contact » avec 8 valeurs peut être chargé une fois et filtré localement sans risque ni coût notable.
Les équipes ne se font pas souvent piéger en choisissant « mal » une fois. Elles se font piéger en prenant une décision différente pour chaque écran, puis en corrigeant des fuites et des pages lentes sous pression.
Rédigez une courte note de décision par écran avec les filtres : taille du jeu de données, coût d'envoi, ce que signifie « assez rapide », quels champs sont sensibles et comment les résultats doivent être mis en cache (ou non). Gardez serveur et UI alignés pour éviter d'avoir « deux vérités » du filtrage.
Si vous construisez rapidement des écrans dans Koder.ai (koder.ai), décidez en amont quels filtres doivent être appliqués côté backend (permissions et accès au niveau des lignes) et quels petits bascules UI peuvent rester dans la couche React. Ce choix évite souvent les réécritures les plus coûteuses plus tard.
Par défaut, choisissez le filtrage côté serveur lorsque les utilisateurs ont des permissions différentes, que le jeu de données est volumineux ou que vous tenez à des totaux et une pagination cohérents. N'utilisez le filtrage côté client que si l'ensemble complet est petit, sûr à exposer et rapide à télécharger.
Tout ce que le navigateur reçoit peut être inspecté. Même si l'interface cache des lignes ou des colonnes, un utilisateur peut toujours voir les données dans les réponses réseau, les caches ou les objets en mémoire.
Cela arrive généralement quand vous envoyez trop de données puis filtrez/triez de grands tableaux à chaque frappe, ou quand vous envoyez une requête au serveur pour chaque pression de touche sans appliquer de debounce. Gardez les payloads petits et évitez les lourds traitements à chaque changement d'entrée.
Ayez une unique source de vérité pour les filtres « réels » : permissions, recherche, tri et pagination doivent être appliqués ensemble côté serveur. Limitez la logique côté client à de petits basculements UI qui ne changent pas l'ensemble de données sous-jacent.
Le cache côté client peut afficher des données périmées ou fuir des données entre comptes s'il n'est pas correctement indexé. Le cache côté serveur est plus sûr pour les permissions, mais il doit inclure la signature complète de la requête (filtres) et l'identité de l'appelant pour éviter les mélanges.
Posez deux questions : combien de lignes un utilisateur pourrait raisonnablement avoir, et quelle est la taille moyenne d'une ligne en octets. Si vous ne seriez pas à l'aise de le charger sur une connexion mobile typique ou sur un appareil ancien, déplacez le filtrage côté serveur et paginez.
Côté serveur. Si les rôles, équipes, régions ou règles d'appartenance modifient ce qu'une personne peut voir, le serveur doit imposer l'accès au niveau des lignes et des champs. Le client ne doit recevoir que ce que l'utilisateur est autorisé à voir.
Définissez d'abord le contrat des filtres et du tri : champs acceptés, tri par défaut, règles de pagination et comportement de la recherche (sensible à la casse, accents, correspondances partielles). Implémentez la même logique de façon cohérente côté backend et testez que totaux et pages correspondent.
Appliquez un debounce lors de la saisie pour ne pas déclencher une requête à chaque touche, et conservez les anciens résultats visibles jusqu'à l'arrivée des nouveaux pour réduire les scintillements. Utilisez la pagination ou le chargement progressif pour afficher quelque chose rapidement sans bloquer en attendant une réponse massive.
Appliquez d'abord les permissions, puis les filtres et le tri, et ne renvoyez qu'une page plus un total. N'envoyez pas des « champs supplémentaires au cas où », et assurez-vous que les clés de cache incluent user/org/role pour qu'un commercial ne reçoive jamais des données destinées à un manager.