Avant d’esquisser des écrans ou de choisir une base de données, clarifiez l’objectif de l’application : à quoi elle sert, qui s’en servira et à quoi ressemble le « bon » résultat. Les applications d’évaluation fournisseurs échouent souvent parce qu’elles cherchent à satisfaire tout le monde en même temps — ou parce qu’elles ne peuvent pas répondre à des questions de base comme « Quel fournisseur évaluons‑nous réellement ? »
Objectifs, utilisateurs et périmètre
Qui l’utilise (et ce dont ils ont besoin)
Commencez par nommer vos principaux groupes d’utilisateurs et leurs décisions quotidiennes :
- Achats (Procurement) a besoin d’une fiche fournisseur cohérente, de vues comparatives entre fournisseurs et d’une piste d’audit défendable pour les décisions d’approvisionnement.
- Finance s’intéresse à la variance des coûts, au respect des conditions de paiement et aux signaux de risque qui affectent les prévisions.
- Opérations veut une résolution rapide des problèmes : suivre les incidents, documenter les actions correctives et vérifier si la performance s’améliore.
- Fournisseurs (portail optionnel) veulent voir les retours, pouvoir répondre et comprendre comment les scores sont calculés.
Une astuce utile : choisissez un « utilisateur central » (souvent les achats) et concevez la première version autour de son flux. Ajoutez ensuite le groupe suivant uniquement quand vous pouvez expliquer quelle nouvelle capacité cela débloque.
Résultats clés visés
Rédigez des résultats en termes de changements mesurables, pas de fonctionnalités. Exemples courants :
- Meilleures décisions fournisseurs (par ex. listes de fournisseurs préférés basées sur des preuves, pas des anecdotes)
- Résolution plus rapide des incidents (propriétaire clair, délais et suivis)
- Évaluation plus cohérente (moins de variations entre évaluateurs ou sites)
Ces résultats orienteront ensuite le choix des KPI et des rapports.
Définir ce que « fournisseur » signifie dans votre système
« Fournisseur » peut signifier différentes choses selon la structure organisationnelle et les contrats. Décidez tôt si un fournisseur est :
- une entité légale (société mère)
- un site / emplacement (utile quand la qualité varie par usine ou région)
- une ligne de service (ex. logistique vs packaging du même prestataire)
Ce choix affecte tout : agrégations des scores, permissions et même si une mauvaise performance d’une installation doit impacter toute la relation.
Choisir l’approche de notation
Trois modèles fréquents :
- KPI pondérés : entrées numériques (%, taux de défaut) multipliées par des poids. Idéal pour la transparence et l’automatisation.
- Rubriques (rubrics) : l’évaluateur choisit un niveau (par ex. « Excellent/Bien/Moyen/Médiocre ») avec un texte d’accompagnement. Idéal quand les données sont qualitatives.
- Hybride : KPI pour les zones mesurables + rubriques pour la collaboration, la réactivité ou l’adéquation stratégique.
Rendez la méthode compréhensible afin qu’un fournisseur (et un auditeur interne) puisse la suivre.
Définir des métriques de succès pour l’application
Choisissez quelques métriques au niveau de l’application pour valider l’adoption et la valeur :
- Adoption : % de fournisseurs actifs ayant au moins une revue au cours du dernier trimestre
- Complétude des revues : champs obligatoires remplis, preuves attachées, KPI renseignés
- Délai du cycle : temps entre ouverture de la revue → approbation → partage avec le fournisseur (si applicable)
Avec objectifs, utilisateurs et périmètre définis, vous aurez une base stable pour le modèle de scoring et le design des workflows qui suivent.
Modèle de scoring et conception des KPI
Une application d’évaluation fournisseurs vit ou meurt selon que le score reflète l’expérience réelle des parties prenantes. Avant de construire des écrans, écrivez les KPI exacts, les échelles et les règles afin que procurement, opérations et finance interprètent les résultats de la même façon.
Choisir un petit ensemble de KPI défendables
Commencez par un noyau que la plupart des équipes reconnaissent :
- Livraison à temps (ex. % d’expéditions dans la fenêtre convenue)
- Qualité (taux de défaut, taux de retour, % d’inspections conformes)
- Respect des SLA (tickets résolus dans le délai cible, disponibilité si pertinent)
- Variance de coût (facture vs PO, frais imprévus)
- Réactivité (délai de première réponse, délai de résolution pour les escalades)
Rendez chaque définition mesurable et liez chaque KPI à une source de données ou une question de revue.
Définir des échelles que l’on peut expliquer
Choisissez soit 1–5 (facile pour les humains) soit 0–100 (plus granulaire), puis décrivez ce que signifie chaque niveau. Par exemple : « Livraison à temps : 5 = ≥ 98 %, 3 = 92–95 %, 1 = < 85 %. » Des seuils clairs réduisent les disputes et rendent les revues comparables entre équipes.
Poids, données manquantes et règles d’équité
Attribuez des poids par catégorie (ex. Livraison 30 %, Qualité 30 %, SLA 20 %, Coût 10 %, Réactivité 10 %) et documentez quand les poids changent (différents types de contrats peuvent prioriser différemment).
Décidez comment gérer les données manquantes :
- Exclure le KPI du dénominateur pour la période, ou
- Appliquer une valeur neutre par défaut, ou
- Marquer le score comme « données insuffisantes » et bloquer le classement.
Quelle que soit la politique, appliquez‑la de façon cohérente et rendez‑la visible dans les vues détaillées pour éviter de confondre « manquant » et « bon ».
Plusieurs fiches par fournisseur
Supportez plusieurs scorecards par fournisseur pour permettre des comparaisons par contrat, région ou période. Cela évite de lisser des problèmes isolés par une moyenne globale.
Litiges et corrections
Documentez comment les litiges affectent les scores : si une métrique peut être corrigée rétroactivement, si un litige marque temporairement le score, et quelle version est « officielle ». Même une règle simple comme « les scores se recalculent quand une correction est approuvée, avec une note expliquant le changement » prévient des confusions futures.
Modèle de données et schéma basique
Un modèle de données propre maintient l’équité du scoring, la traçabilité des revues et la crédibilité des rapports. Vous devez pouvoir répondre simplement à « Pourquoi ce fournisseur a‑t‑il obtenu 72 ce mois ? » et « Qu’est‑ce qui a changé depuis le trimestre dernier ? » sans bricolages.
Entités principales (ce que vous stockez)
Au minimum, définissez ces entités :
- Vendor : profil fournisseur (nom, statut, catégorie, contacts)
- Contract : détails de l’accord commercial et fenêtres de validité
- Order/Invoice (ou Transaction unifiée) : faits opérationnels alimentant les KPI
- KPI Metric : définitions comme % livraison à temps, taux de défaut
- Score : résultat calculé pour un fournisseur sur une période (global et/ou par métrique)
- Review : retours qualitatifs, notes et preuves narratives
- Attachment : fichiers liés aux revues ou litiges (emails, photos, PDFs)
Ce jeu permet de supporter à la fois la performance « dure » mesurée et le feedback « mou », qui ont généralement des workflows différents.
Modélisez explicitement les relations :
- Vendor → Contracts : un fournisseur peut avoir plusieurs contrats au fil du temps.
- Vendor → Orders/Invoices : les transactions se rattachent généralement à un fournisseur.
- Score → Metric : les scores doivent être traçables jusqu’à la définition de la métrique et la version du calcul.
- Review → Period : les revues doivent avoir une période claire (mois/trimestre) pour ne pas flotter hors contexte.
Une approche courante :
scorecard_period (ex. 2025-10)vendor_period_score (score global)vendor_period_metric_score (par KPI, inclut numérateur/dénominateur si pertinent)
Champs dont vous serez content de disposer plus tard
Ajoutez des champs de cohérence sur la plupart des tables :
- Horodatages :
created_at, updated_at, et pour les approbations submitted_at, approved_at
- Auteur et acteur :
created_by_user_id, plus approved_by_user_id quand pertinent
- Système source :
source_system et identifiants externes comme erp_vendor_id, crm_account_id, erp_invoice_id
- Confiance/qualité : un score
confidence ou data_quality_flag pour marquer des flux incomplets ou des estimations
Ces champs alimentent les pistes d’audit, la gestion des litiges et une analytique d’achats fiable.
Rétention, versioning et « qu’est‑ce qui a changé ? »
Les scores changent parce que des données arrivent en retard, des formules évoluent ou quelqu’un corrige un mapping. Plutôt que d’écraser l’historique, stockez des versions :
- Conservez une version de calcul (ou
calculation_run_id) sur chaque ligne de score.
- Enregistrez des codes raison pour les recalculs (facture arrivée en retard, mise à jour de définition KPI, correction manuelle).
- Envisagez une piste d’audit en mode append‑only pour les tables importantes (scores, revues, approbations) afin de montrer qui a changé quoi et quand.
Pour la rétention, définissez la durée de conservation des transactions brutes vs. des scores dérivés. Souvent, on conserve les scores dérivés plus longtemps (stockage réduit, forte valeur pour le reporting) et on garde les extractions ERP brutes sur une fenêtre politique plus courte.
Stratégie d’identifiants pour le matching ERP/CRM
Traitez les IDs externes comme des champs de première classe, pas comme des notes :
- Stockez à la fois external ID et system name (ERP_A vs ERP_B).
- Faites respecter l’unicité par système source (ex.
unique(source_system, external_id)).
- Ajoutez des tables de mapping légères quand des fournisseurs fusionnent/se séparent pour préserver l’exactitude historique des scores.
Ces fondations facilitent les sections suivantes — intégrations, suivi des KPI, modération des revues et auditabilité.
Ingestion des données et intégrations
Une application d’évaluation fournisseurs n’est bonne que si ses entrées sont fiables. Prévoyez plusieurs chemins d’ingestion dès le départ, même si vous commencez par un seul. La plupart des équipes ont besoin d’un mélange de saisie manuelle pour les cas marginaux, d’imports en masse pour l’historique et de sync API pour les mises à jour continues.
Sources de données courantes
Saisie manuelle utile pour les petits fournisseurs, les incidents ponctuels ou quand une équipe doit enregistrer une revue immédiatement.
Import CSV aide à démarrer le système avec des historiques (performances, factures, tickets, livraisons). Rendez les imports prévisibles : publiez un modèle et versionnez‑le pour que les changements ne cassent pas silencieusement les imports.
Sync API connecte typiquement les ERP/outils procurement (PO, réceptions, factures) et les systèmes de service (tickets, violations de SLA). Préférez la synchronisation incrémentale (depuis le dernier curseur) pour éviter de tout repuller à chaque fois.
Validation pour éviter d’importer de la mauvaise donnée
Appliquez des règles de validation à l’import :
- Champs requis (vendor ID, date, nom/valeur du métrique)
- Plages numériques (ex. scores 0–100, quantités non négatives)
- Détection de doublons (même vendor + métrique + période + ID source)
Conservez les lignes invalides avec des messages d’erreur pour que les admins puissent corriger et réimporter sans perdre le contexte.
Corrections, backfills et journaux de recalcul
Les imports comporteront des erreurs. Supportez les re‑runs (idempotents via les source IDs), les backfills (périodes historiques) et des journaux de recalcul qui enregistrent ce qui a changé, quand et pourquoi. C’est critique pour la confiance quand le score d’un fournisseur évolue.
Planification et transparence
La plupart des équipes font bien avec des imports quotidiens/hebdomadaires pour finance et livraison, et des événements quasi temps réel pour les incidents critiques.
Exposez une page admin conviviale (ex. /admin/imports) montrant le statut, le compte des lignes, les avertissements et les erreurs exactes—pour que les problèmes soient visibles et réparables sans développeur.
Rôles, permissions et workflow d’approbation
Des rôles clairs et un chemin d’approbation prévisible évitent le « chaos des fiches » : modifications conflictuelles, changements de notation surprises, et incertitude sur ce que voit le fournisseur. Définissez les règles d’accès tôt, puis appliquez‑les dans l’UI et l’API.
Types de rôles (et leur utilité)
Un ensemble pratique de départ :
- Admin : gère les paramètres orga, les assignations de rôle, les modèles de scoring et les règles de modération.
- Évaluateur interne : soumet des revues, preuves et brouillons de mise à jour des scores.
- Approbateur : valide les actions sensibles (publier des revues, verrouiller des périodes, approuver des changements de score).
- Utilisateur fournisseur : voit sa propre fiche, répond aux revues, télécharge des clarifications (si autorisé).
- Lecture seule : consulte tableaux de bord et profils fournisseur sans modifier.
Permissions qui correspondent à des actions réelles
Évitez les permissions vagues comme « peut gérer les fournisseurs ». Contrôlez des capacités spécifiques :
- Voir : qui peut voir les revues, les noms d’évaluateurs, les pièces jointes et l’historique des scores.
- Éditer : qui peut créer/éditer des brouillons, changer des valeurs KPI ou ajuster des poids.
- Publier : qui peut passer du brouillon au visible.
- Exporter : qui peut télécharger les rapports (CSV/PDF) et à quel périmètre (fournisseur unique vs tous les fournisseurs).
Envisagez de séparer « exporter ses fournisseurs » vs « exporter tout ».
Règles de visibilité pour les fournisseurs
Les utilisateurs fournisseurs devraient, en général, voir seulement leurs propres données : scores, revues publiées, et statut des points ouverts. Limitez l’identification des évaluateurs par défaut (ex. afficher le département ou le rôle plutôt que le nom complet) pour réduire les frictions interpersonnelles. Si vous autorisez les réponses fournisseurs, conservez‑les en fil et étiquetez‑les clairement.
Flux d’approbation pour garantir confiance et cohérence
Traitez les revues et changements de score comme des propositions jusqu’à approbation :
- L’évaluateur interne soumet un brouillon de revue/mise à jour de score.
- L’approbateur examine les preuves, vérifie la politique et approuve, demande des modifications ou rejette.
- Seuls les éléments approuvés affectent le « score courant » et deviennent visibles aux fournisseurs.
Les workflows limités dans le temps aident : par exemple, les changements de score peuvent nécessiter une approbation seulement lors de la clôture mensuelle/trimestrielle.
Exigences de piste d’audit
Pour conformité et responsabilité, journalisez chaque événement significatif : qui a fait quoi, quand, d’où et ce qui a changé (valeurs avant/après). Les entrées d’audit doivent couvrir changements de permissions, éditions de revues, approbations, publications, exports et suppressions. Rendre la piste d’audit consultable, exportable pour un audit, et protégée contre la falsification (stockage append‑only ou logs immuables).
UX et écrans principaux
Reduce Your Build Cost
Gagnez des crédits en créant du contenu sur Koder.ai ou en invitant des collègues et des partenaires.
Une application d’évaluation fournisseurs réussit si les utilisateurs pressés trouvent rapidement le bon fournisseur, comprennent le score en un coup d’œil et laissent des retours fiables sans friction. Commencez par un petit ensemble d’écrans « de base » et faites en sorte que chaque nombre soit explicable.
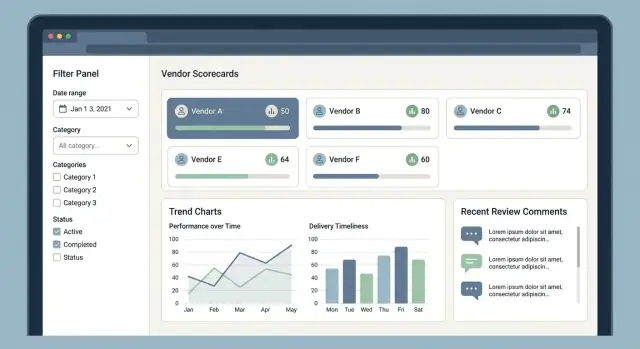
1) Liste des fournisseurs (le centre de commande)
La plupart des sessions commencent ici. Layout simple : nom, catégorie, région, bande de score courante, statut et dernière activité.
Les filtres et la recherche doivent sembler instantanés et prévisibles :
- Catégorie, région, statut (actif/en attente/bloqué)
- Plage de dates (ex. dernière revue, dernier incident de livraison)
- Bande de score (A/B/C ou plages 0–100)
Enregistrez des vues fréquentes (ex. « Fournisseurs critiques en EMEA < 70 ») pour que les équipes achats ne reconstruisent pas les filtres chaque jour.
2) Profil fournisseur (une page, beaucoup de réponses)
Le profil doit résumer « qui ils sont » et « comment ils performent » sans forcer l’utilisateur à naviguer trop tôt dans des onglets. Placez les contacts et métadonnées contractuelles à côté d’un résumé de score clair.
3) Fiche de score avec drill‑down « pourquoi »
Affichez le score global et la ventilation par KPI (qualité, livraison, coût, conformité). Chaque KPI doit afficher sa source : revues sous‑jacentes, incidents ou métriques qui l’ont produit.
Un bon modèle :
- KPI → formule/poids → éléments contributeurs → preuves (commentaires, pièces jointes, horodatages)
4) Revues et incidents (saisie rapide, contexte fort)
Rendez la saisie des revues mobile‑friendly : grandes cibles tactiles, champs courts et commentaires rapides. Attachez toujours les revues à une période et (si pertinent) à un PO, site ou projet pour que le feedback reste actionnable.
5) Rapports (prêts à la décision)
Les rapports doivent répondre aux questions courantes : « Quels fournisseurs sont en baisse ? » et « Qu’est‑ce qui a changé ce mois ? » Utilisez des graphiques lisibles, des étiquettes claires et la navigation clavier pour l’accessibilité.
Les revues capturent le contexte, les preuves et le « pourquoi » derrière les chiffres. Pour les garder cohérentes (et défendables), traitez les revues comme des enregistrements structurés d’abord, texte libre ensuite.
Types de revues à supporter
Différents moments appellent des modèles différents. Début simple :
- Revues périodiques (mensuelles/trimestrielles) : pour le suivi régulier et les tendances.
- Revues basées incident : liées à une livraison tardive, un défaut qualité, ou un problème de conformité.
- Revues de clôture de projet : bilan de fin d’engagement avec leçons apprises.
Chaque type peut partager des champs communs mais autoriser des questions spécifiques au type pour éviter le forcing.
Champs structurés : rendre les revues interrogeables
Aux côtés du commentaire narratif, incluez des champs structurés pour filtrer et reporter :
- Tags et catégories (ex. Logistique, Qualité, Communication)
- Forces et faiblesses (champs séparés pour éviter le feedback unilatéral)
- Actions avec propriétaire, date d’échéance et statut
Cette structure transforme le feedback en travail traçable, pas seulement du texte.
Gestion des preuves (sans rendre la tâche pénible)
Permettez d’attacher des preuves au moment de l’évaluation :
- Pièces jointes (photos, PDFs)
- Liens vers des docs partagés
- Références à tickets / POs / orders (sélectionnables idéalement depuis une liste)
Stockez des métadonnées (qui a uploadé, quand, à quoi cela se rapporte) pour éviter les recherches fastidieuses lors d’un audit.
Modération et historique des éditions
Même les outils internes nécessitent de la modération. Ajoutez :
- Contrôles basiques anti‑profanité/spam
- Règles d’escalade pour les allégations graves (sécurité, fraude)
- Un historique des modifications qui enregistre ce qui a changé et par qui (y compris les censures)
Évitez les éditions silencieuses — la transparence protège évaluateurs et fournisseurs.
Notifications, rappels et SLA de réponse
Définissez les règles de notification :
- Alerter le fournisseur quand une revue est publiée (ou quand une réponse est demandée)
- Envoyer des rappels internes pour les actions en retard
- Fixer un SLA de réponse (ex. 5 jours ouvrés) avec une escalade en cas de non‑respect
Bien fait, le dispositif transforme les revues en un workflow bouclé plutôt qu’en une plainte isolée.
Architecture et choix technos
Ship a Pilot Faster
Déployez et hébergez rapidement votre application d'évaluation des fournisseurs pour que les parties prenantes puissent la tester rapidement.
La première décision d’architecture porte moins sur le « dernier cri » que sur la capacité à livrer rapidement une plateforme fiable sans créer un fardeau de maintenance.
Si vous voulez aller vite, envisagez de prototyper le flux (fournisseurs → fiches → revues → approbations → rapports) sur une plateforme qui peut générer une application fonctionnelle à partir d’un cahier des charges clair. Par exemple, Koder.ai est une plateforme « vibe‑coding » où l’on peut construire web, backend et mobile via une interface conversationnelle, puis exporter le code source quand on est prêt. C’est un moyen pratique de valider le modèle de scoring et les rôles/permissions avant d’investir lourdement dans des intégrations et une UI sur‑mesure.
Monolithe vs services modulaires (restez simple)
Pour la plupart des équipes, un monolithe modulaire est l’équilibre : une application déployable mais organisée en modules clairs (Vendors, Scorecards, Reviews, Reporting, Admin). Développement et debug restent simples, tout comme la sécurité et le déploiement.
Séparez en services uniquement si vous avez une forte raison — charges lourdes de reporting, plusieurs équipes produit ou exigences d’isolation strictes. Parcours d’évolution typique : monolithe maintenant, extraction d’« imports/reporting » plus tard si nécessaire.
Conception de l’API (REST qui correspond au travail réel)
Une API REST est souvent la plus simple à raisonner et à intégrer. Visez des ressources prévisibles et quelques endpoints « tâche » où le système effectue un travail réel.
Exemples :
/api/vendors (create/update vendors, status)/api/vendors/{id}/scores (current score, historical breakdown)/api/vendors/{id}/reviews (list/create reviews)/api/reviews/{id} (update, moderate actions)/api/exports (request exports; returns job id)
Gardez les opérations lourdes (exports, recalculs en masse) asynchrones pour que l’UI reste réactive.
Jobs en arrière‑plan (imports, recalculs, notifications)
Utilisez une file de jobs pour :
- importer les données fournisseurs (CSV/SFTP/API)
- recalculer les scores quand les KPI, poids ou revues changent
- envoyer des notifications (revue demandée, score changé, approbation requise)
Cela facilite aussi la gestion des retries sans intervention manuelle.
Mise en cache pour tableaux de bord et rapports lourds
Les tableaux de bord peuvent être coûteux. Cachez les métriques agrégées (par période, catégorie, unité métier) et invalidez le cache sur des changements significatifs, ou rafraîchissez sur un planning. Cela maintient la rapidité tout en gardant la possibilité d’un drill‑down précis.
Documentation (devs et admins)
Rédigez des docs API (OpenAPI/Swagger) et maintenez un guide interne, accessible depuis l’app en style /blog — ex. “How scoring works”, “How to handle disputed reviews”, “How to run exports” — et liez‑le depuis l’application vers /blog pour qu’il soit simple à trouver et à mettre à jour.
Sécurité, confidentialité et fiabilité
Les données de scoring peuvent influencer des contrats et des réputations : il faut des contrôles sécurisés, auditable et faciles à suivre pour les non‑techniques.
Authentification et contrôle d’accès
Commencez par les bonnes options de connexion :
- Email/mot de passe pour les petites équipes (appliquez règles fortes et MFA si possible).
- SSO pour entreprises via SAML ou OIDC pour gérer l’accès centralement et révoquer rapidement.
Associez l’authentification à un RBAC : admins procurement, évaluateurs, approbateurs, et acteurs lecture seule. Gardez des permissions granulaires (ex. « voir scores » vs « voir texte des revues »). Conservez une piste d’audit pour les changements de score, approbations et éditions.
Protéger les données sensibles
Chiffrez en transit (TLS) et au repos (base + backups). Traitez les secrets (mots de passe DB, clés API, certificats SSO) comme des ressources critiques :
- Stockez‑les dans un vault managé
- Faites des rotations régulières
- Ne les committez jamais dans le repo
Prévention des abus et endpoints sûrs
Même si l’app est « interne », des endpoints publics (reset de mot de passe, liens d’invitation, formulaires de soumission de revue) peuvent être abusés. Ajoutez du rate limiting et une protection anti‑bots (CAPTCHA ou scoring de risque) là où c’est pertinent, et verrouillez les APIs par tokens à scope réduit.
Confidentialité dès la conception
Les revues contiennent souvent noms, emails et détails d’incidents. Minimisez les données personnelles par défaut (préférez champs structurés au texte libre), définissez des règles de rétention et fournissez des outils pour rediger ou supprimer du contenu si nécessaire.
Exploitation fiable sans fuite de données
Consignez assez pour dépanner (request IDs, latences, codes d’erreur) mais évitez d’enregistrer les textes sensibles des revues ou les pièces jointes. Utilisez monitoring et alertes pour imports échoués, erreurs de jobs de scoring et accès inhabituels — sans faire des logs une seconde base de données contenant des données sensibles.
Reporting, tableaux de bord et explicabilité
Une application d’évaluation n’est utile que si elle aide à prendre des décisions. Le reporting doit répondre à trois questions : Qui performe bien, par rapport à quoi, et pourquoi ?
Vues de dashboard utiles aux décideurs pressés
Commencez par un dashboard exécutif résumant score global, évolutions et répartition par catégorie (qualité, livraison, conformité, coût, service, etc.). Les courbes de tendance sont essentielles : un fournisseur légèrement moins bon mais en forte amélioration peut être préférable à un bon fournisseur en déclin.
Rendez les dashboards filtrables (période, unité métier/site, catégorie fournisseur, contrat). Utilisez des valeurs par défaut cohérentes (ex. « 90 derniers jours ») pour que deux personnes regardant le même écran obtiennent des réponses comparables.
Benchmarking avec contrôles d’accès
Le benchmarking est puissant mais sensible. Permettez des comparaisons au sein d’une même catégorie (ex. « fournisseurs packaging ») tout en appliquant des permissions :
- La direction des achats voit des comparaisons nommées.
- Les responsables de site voient uniquement les fournisseurs qu’ils gèrent.
- Les parties prenantes générales voient des rangs anonymisés ou des quartiles.
Cela évite des divulgations accidentelles tout en supportant la sélection.
Rapports drill‑down : du score à la source
Les dashboards doivent renvoyer à des rapports détaillés expliquant les mouvements :
- Par période : rollups mensuels/trimestriels avec deltas par KPI.
- Par site : mettre en lumière des problèmes localisés.
- Par contrat : vérifier l’alignement avec les SLA et les termes commerciaux.
Un bon drill‑down se termine par la preuve : revues liées, incidents, tickets ou enregistrements d’expédition.
Exports pour partage interne
Supportez CSV pour l’analyse et PDF pour le partage. Les exports doivent refléter les filtres à l’écran, inclure un horodatage et, éventuellement, un filigrane usage interne (et identité du visualiseur) pour décourager le partage externe.
Évitez les scores « boîte noire ». Chaque score doit disposer d’une ventilation claire :
- Contributions par KPI (poids, valeurs brutes, normalisation)
- Pénalités/bonus appliqués (ex. non‑conformité critique)
- Notes de calcul et version (pour auditer les changements de formule)
Quand on peut voir les détails du calcul, les litiges se résolvent plus vite et les plans d’amélioration s’accordent plus facilement.
Tests et contrôles qualité
Lock Down Permissions Early
Configurez le RBAC et les approbations pour que seules les notes approuvées deviennent officielles.
Tester une plateforme d’évaluation revient à protéger la confiance. Les équipes achats doivent être sûres qu’un score est correct, et les fournisseurs doivent être assurés que revues et approbations sont gérées de façon consistante.
Construire des jeux de test réalistes et imparfaits
Créez des petits jeux de données réutilisables incluant des cas limites : KPI manquants, soumissions tardives, valeurs conflictuelles entre imports, litiges (ex. contestation d’un SLA de livraison). Incluez des cas sans activité pour une période, ou des KPI devant être exclus pour des dates invalides.
Vérifier la logique de scoring avec des tests unitaires
Les calculs de scoring sont le cœur du produit : testez‑les comme une formule financière :
- Règles de pondération (y compris quand les poids ne font pas 100 %)
- Comportement d’arrondi et égalités dans le classement
- Seuils (quand un KPI passe de « bon » à « attention »)
- Tests de régression pour tout changement de définition de KPI
Les tests unitaires doivent affirmer non seulement les scores finaux, mais aussi les composants intermédiaires (score par KPI, normalisation, pénalités/bonus) pour faciliter le debug.
Couvrir imports, permissions et workflows par des tests d’intégration
Les tests d’intégration doivent simuler des flux bout‑en‑bout : importer une fiche fournisseur, appliquer des permissions, et vérifier que seuls les rôles autorisés peuvent voir/commenter/approuver/escalader. Incluez des tests pour la piste d’audit et pour les actions bloquées (ex. un fournisseur tentant d’éditer une revue approuvée).
Faites des tests d’acceptation utilisateur avec procurement et un groupe pilote de fournisseurs. Suivez les moments de confusion et adaptez le texte UI, les validations et les aides.
Enfin, réalisez des tests de charge pour les périodes de pointe (fin de mois/trimestre) sur : temps de chargement des tableaux, exports en masse et jobs de recalcul concurrents.
Plan de lancement et feuille de route d’itération
Une application gagne quand on l’utilise réellement. Livrer par phases, remplacer les tableurs progressivement et fixer des attentes sur ce qui changera aide à l’adoption.
Lancement phasé pour gagner la confiance
Commencez par la version la plus légère qui produit tout de même des fiches utiles.
Phase 1 : Scorecards internes uniquement. Fournissez à procurement et parties prenantes un endroit propre pour consigner les valeurs KPI, générer une fiche et laisser des notes internes. Simplifiez le workflow et priorisez la cohérence.
Phase 2 : Accès fournisseurs. Quand le scoring interne est stable, invitez les fournisseurs à consulter leur fiche, répondre et ajouter du contexte (ex. « retard dû à la fermeture du port »). C’est là que permissions et piste d’audit deviennent critiques.
Phase 3 : Automatisation. Ajoutez intégrations et recalculs planifiés une fois le modèle de scoring éprouvé. Automatiser trop tôt peut amplifier de mauvaises données ou des définitions floues.
Si vous voulez accélérer le pilote, Koder.ai peut aider : monter rapidement le flux (rôles, approbation, fiches, exports), itérer avec procurement « en mode planification » puis exporter la base de code pour durcir les intégrations et contrôles de conformité.
Plan de migration (adieu tableurs, en sécurité)
Si vous remplacez des tableurs, prévoyez une transition graduelle plutôt qu’un cutover brutal.
Fournissez des modèles d’import qui reflètent les colonnes existantes (nom fournisseur, période, valeurs KPI, évaluateur, notes). Ajoutez des helpers : erreurs « fournisseur inconnu », prévisualisation et mode dry‑run.
Décidez aussi si vous migrez tout l’historique ou seulement les périodes récentes. Souvent, importer les 4–8 derniers trimestres suffit pour activer les rapports de tendance sans transformer la migration en fouille archéologique.
Rendez la formation courte et ciblée :
- Fiches 1 page pour évaluateurs, approbateurs et admins
- Astuces in‑app au premier lancement (comment scorer, où laisser du contexte, que signifie « soumettre »)
- Checklist admin : créer catégories, définir KPI, configurer cycles de revue et vérifier les accès
Maintenance continue et itération
Traitez les définitions de scoring comme un produit. Les KPI évoluent, les catégories s’étendent et les poids changent.
Définissez une politique de recalcul : que se passe‑t‑il si une définition de KPI change ? Recalculez‑vous l’historique ou conservez‑vous les résultats originaux pour l’auditabilité ? Beaucoup d’équipes conservent les résultats historiques et ne recalculent qu’à partir d’une date d’effet.
Étapes suivantes : tarification et packaging
En sortant du pilote, décidez ce qui est inclus par palier (nombre de fournisseurs, cycles, intégrations, reporting avancé, accès portail fournisseur). Si vous formalisez un plan commercial, esquissez les packs et reliez‑les à /pricing.
Si vous évaluez construire vs acheter vs accélérer, traitez « à quelle vitesse peut‑on livrer un MVP digne de confiance ? » comme un facteur de packaging. Des plateformes comme Koder.ai (offres de la gratuité à l’entreprise) peuvent servir de pont : construire et itérer rapidement, déployer et héberger, et garder l’option d’exporter la totalité du code quand votre programme de scoring mûrit.