Pourquoi les changements de schéma causent des interruptions
Le downtime lié à une modification de la base n’est pas toujours une coupure nette et évidente. Pour les utilisateurs, cela peut ressembler à une page qui charge indéfiniment, un paiement qui échoue, ou une app qui affiche soudainement « quelque chose s’est mal passé ». Pour les équipes, cela se traduit par des alertes, une hausse des erreurs et un arriéré d’écritures échouées à nettoyer.
Les changements de schéma sont risqués parce que la base est partagée par toutes les versions de votre app en cours d’exécution. Pendant une release, il y a souvent du code ancien et du code nouveau en parallèle (deploys rolling, instances multiples, jobs d’arrière-plan). Une migration qui semble correcte peut tout de même casser l’une de ces versions.
Les échecs courants incluent :
- Le nouveau code écrit dans une colonne qui n’existe pas encore, provoquant des erreurs immédiates.
- L’ancien code lit une colonne ou une table que la migration a renommée ou supprimée, provoquant des plantages après le déploiement.
- Un backfill ou la construction d’un index fait monter la CPU ou verrouille des lignes, ralentissant les requêtes normales ou provoquant des timeouts.
- Un changement de contrainte « rapide » (comme NOT NULL) bloque les écritures pendant la vérification de la table.
Même quand le code est correct, les releases se bloquent parce que le vrai problème est le timing et la compatibilité entre versions.
Les changements de schéma sans interruption se résument à une règle : chaque état intermédiaire doit être sûr pour l’ancien comme pour le nouveau code. Vous modifiez la base sans casser les lectures et écritures existantes, déployez du code capable de gérer les deux formes, et ne supprimez l’ancien chemin que lorsque plus rien n’en dépend.
Cet effort vaut la peine quand vous avez du vrai trafic, des SLA stricts, ou beaucoup d’instances et de workers. Pour un petit outil interne à faible charge, une fenêtre de maintenance planifiée peut être plus simple.
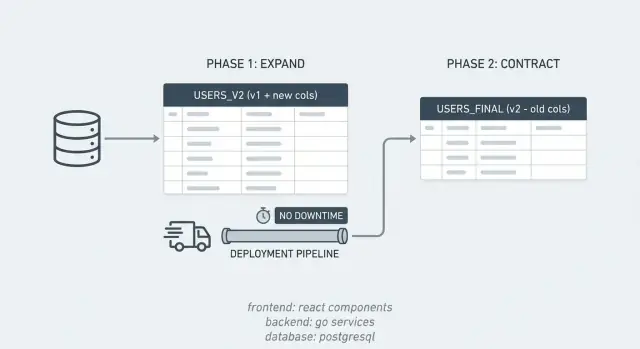
Expand/contract en termes simples
La plupart des incidents liés aux travaux sur la base viennent du fait que l’app s’attend à ce que la base change instantanément, alors que la modification prend du temps. Le pattern expand/contract évite cela en divisant une modification risquée en étapes plus petites et sûres.
Pendant une courte période, votre système supporte deux « dialectes » à la fois. Vous introduisez d’abord la nouvelle structure, conservez l’ancienne, migrez les données progressivement, puis nettoyez.
Le pattern est simple :
- Expand : ajoutez ce dont vous avez besoin (colonnes, tables, index) sans casser l’app actuelle.
- Exécutez les deux chemins : déployez du code qui fonctionne avec les anciennes et nouvelles structures pour que les versions mixtes restent opérationnelles.
- Contract : une fois que tout utilise la nouvelle structure, supprimez l’ancien schéma et le code associé.
Cela s’intègre bien aux deploys rolling. Si vous mettez à jour 10 serveurs un par un, vous aurez brièvement de l’ancien et du nouveau code en parallèle. Expand/contract garde les deux compatibles avec la même base pendant ce chevauchement.
Cela rend aussi les rollbacks moins effrayants. Si une nouvelle release a un bug, vous pouvez revenir en arrière sans restaurer la base, car les anciennes structures existent encore pendant la fenêtre d’expansion.
Exemple : vous voulez scinder une colonne PostgreSQL full_name en first_name et last_name. Vous ajoutez les nouvelles colonnes (expand), livrez du code capable d’écrire et lire les deux formes, backfillez les anciennes lignes, puis supprimez full_name une fois sûr que rien ne l’utilise (contract).
Ce que comprend généralement l’« expand »
La phase d’expansion consiste à ajouter de nouvelles options, pas à en retirer.
Un mouvement courant est d’ajouter une nouvelle colonne. Sous PostgreSQL, il est généralement plus sûr de l’ajouter nullable et sans valeur par défaut. Ajouter une colonne non-null avec un default peut déclencher une réécriture de table ou des verrous plus lourds, selon votre version de Postgres et la modification exacte. Une séquence plus sûre est : ajouter nullable, déployer du code tolérant, backfiller, puis appliquer NOT NULL plus tard.
Les index demandent aussi de la prudence. Créer un index normal peut bloquer les écritures plus longtemps que prévu. Quand c’est possible, utilisez la création d’index concurrente pour que les lectures et écritures continuent. C’est plus long, mais évite un verrou qui stoppe la release.
Expand peut aussi signifier ajouter de nouvelles tables. Si vous passez d’une colonne unique à une relation many-to-many, vous pouvez ajouter une table de jointure en gardant l’ancienne colonne. L’ancien chemin continue de fonctionner pendant que la nouvelle structure commence à collecter des données.
En pratique, expand inclut souvent :
- Ajouter de nouvelles colonnes nullable ou de nouvelles tables en parallèle
- Ajouter des index de façon non bloquante quand c’est possible
- Utiliser des feature flags pour contrôler l’activation des nouvelles lectures/écritures
- Écrire à la fois dans l’ancien et le nouveau champ (dual-write) si nécessaire
- Garder les lectures rétrocompatibles (ancienne, nouvelle ou fallback)
Après l’expansion, les anciennes et nouvelles versions de l’app doivent pouvoir tourner simultanément sans surprise.
Déployer du code qui reste compatible
La plupart des problèmes de release surviennent au milieu : certains serveurs exécutent le nouveau code, d’autres l’ancien, alors que la base a déjà changé. Votre objectif est simple : toute version durant le rollout doit fonctionner avec l’ancien et le schéma étendu.
Une approche courante est le dual-write. Si vous ajoutez une nouvelle colonne, la nouvelle app écrit dans l’ancien et le nouveau champ. Les anciennes versions continuent d’écrire uniquement dans l’ancien, ce qui est acceptable puisque celui-ci existe toujours. Gardez la nouvelle colonne optionnelle au début et retardez les contraintes strictes jusqu’à ce que tous les writers soient mis à jour.
Les lectures basculent généralement plus prudemment que les écritures. Pendant un certain temps, conservez les lectures sur l’ancienne colonne (celle que vous savez entièrement remplie). Après le backfill et la vérification, basculez pour préférer la nouvelle colonne, avec un fallback vers l’ancienne si la nouvelle est manquante.
Conservez aussi la forme de l’API stable pendant que la base change. Même si vous introduisez un nouveau champ interne, évitez de modifier la forme des réponses tant que tous les consommateurs (web, mobile, intégrations) ne sont pas prêts.
Un déroulé favorisant le rollback ressemble souvent à ceci :
- Release 1 : ajoutez la nouvelle colonne et déployez du code qui lit l’ancien format et écrit dans les deux colonnes.
- Release 2 : backfill des lignes existantes, puis déployez du code qui préfère la nouvelle colonne mais peut faire fallback.
- Release 3 : arrêtez d’écrire dans l’ancienne colonne (en la gardant présente).
- Release 4 : retirez les lectures anciennes, puis supprimez l’ancienne colonne.
L’idée clé est que la première étape irréversible est la suppression de l’ancienne structure ; vous la reportez donc à la fin.
Backfiller les données en toute sécurité (sans surcharger la BD)
Le backfill est souvent l’endroit où les migrations « sans interruption » échouent. Vous voulez remplir la nouvelle colonne pour les lignes existantes sans verrous longs, requêtes lentes ou pics de charge inattendus.
La granularité par lots est importante. Visez des lots qui s’achèvent rapidement (secondes, pas minutes). Si chaque lot est petit, vous pouvez mettre en pause, reprendre et ajuster le job sans bloquer les releases.
Pour suivre la progression, utilisez un curseur stable. Sous PostgreSQL, c’est souvent la clé primaire. Traitez les lignes dans l’ordre et stockez le dernier id complété, ou travaillez par plages d’id. Cela évite des scans coûteux de toute la table au redémarrage du job.
Voici un pattern simple :
UPDATE my_table
SET new_col = ...
WHERE new_col IS NULL
AND id > $last_id
ORDER BY id
LIMIT 1000;
Rendez l’update conditionnel (par exemple WHERE new_col IS NULL) pour que le job soit idempotent. Les reruns ne touchent que les lignes qui nécessitent encore du travail, ce qui réduit les écritures inutiles.
Prévoyez les nouvelles données arrivant pendant le backfill. L’ordre habituel est :
- Mettez à jour le code applicatif d’abord pour que les nouvelles écritures remplissent aussi le nouveau champ.
- Backfillez les lignes historiques par petits lots.
- Lancez une boucle de rattrapage courte qui reverifie les lignes récentes.
- Si nécessaire, ajoutez un garde-fou (trigger ou valeur par défaut) pour éviter de nouveaux NULLs.
Un bon backfill est ennuyeux : régulier, mesurable et facile à mettre en pause si la base devient chaude.
Vérifier que la migration est vraiment terminée
Le moment le plus risqué n’est pas l’ajout de la nouvelle colonne, mais la décision de s’y fier.
Avant de passer au contract, prouvez deux choses : les nouvelles données sont complètes, et la production les lit en toute sécurité.
Commencez par des contrôles d’exhaustivité rapides et répétables :
- Confirmez que la nouvelle colonne n’a pas de NULLs inattendus.
- Comparez le nombre de lignes éligibles et le nombre rempli.
- Contrôlez manuellement quelques IDs et comparez l’ancien et le nouveau champ.
- Testez les cas limites (chaînes vides, zéro, très vieilles lignes).
- Relancez les mêmes contrôles plus tard pour vérifier qu’il n’y a pas de dérive.
Si vous faites du dual-writing, ajoutez une vérification de cohérence pour détecter des bugs silencieux. Par exemple, exécutez une requête horaire qui trouve les lignes où old_value <> new_value et alertez si ce n’est pas zéro. C’est souvent le moyen le plus rapide pour découvrir qu’un writer met toujours à jour uniquement l’ancien champ.
Surveillez les signaux de production pendant la migration. Si le temps des requêtes ou les attentes de verrou augmentent, même vos requêtes de vérification « sûres » peuvent ajouter de la charge. Surveillez les taux d’erreur pour tout chemin qui lit la nouvelle colonne, surtout après les déploiements.
Combien de temps garder les deux chemins ? Assez longtemps pour survivre à au moins un cycle complet de release et une relance du backfill. Beaucoup d’équipes utilisent 1–2 semaines, ou jusqu’à être sûres qu’aucune vieille version n’est encore en service.
Phase de contract : supprimer l’ancien chemin
Le contract est le moment où les équipes deviennent nerveuses parce qu’il ressemble au point de non-retour. Si l’expansion a été bien faite, le contract est surtout du nettoyage, et vous pouvez le faire en petites étapes à faible risque.
Choisissez le moment avec soin. Ne supprimez rien juste après avoir fini un backfill. Attendez au moins un cycle de release complet pour que les jobs retardés et les cas limites se manifestent.
Une séquence de contract sûre ressemble généralement à :
- Arrêter le dual-write et confirmer que les nouvelles écritures vont uniquement dans la nouvelle colonne(s).
- Supprimer les lectures anciennes dans l’application pour que le fallback disparaisse.
- Supprimer le code mort, les feature flags et les jobs qui référencent l’ancien schéma.
- Supprimer les triggers temporaires, jobs de sync ou vues de compatibilité.
- Supprimer les anciens index et contraintes, puis supprimer l’ancienne colonne.
Si possible, scindez le contract en deux releases : une qui retire les références dans le code (avec logging supplémentaire), et une plus tard qui supprime les objets de la base. Cette séparation facilite le rollback et le dépannage.
Les spécificités PostgreSQL comptent ici. Supprimer une colonne est principalement une modification métadonnée, mais cela prend quand même un court verrou ACCESS EXCLUSIVE. Planifiez une fenêtre calme et gardez la migration rapide. Si vous avez créé des index supplémentaires, préférez les supprimer avec DROP INDEX CONCURRENTLY pour éviter de bloquer les écritures (cela ne peut pas s’exécuter dans un bloc transactionnel, donc vos outils de migration doivent le supporter).
Erreurs et pièges courants
Les migrations sans interruption échouent quand la base et l’app ne s’accordent plus sur ce qui est autorisé. Le pattern ne fonctionne que si chaque état intermédiaire est sûr pour l’ancien et le nouveau code.
Pièges qui cassent la production
Ces erreurs reviennent souvent :
- Ajouter NOT NULL trop tôt, alors qu’une ancienne version peut encore écrire des lignes sans le nouveau champ.
- Backfiller une grosse table dans une seule transaction, ce qui peut tenir des verrous, causer du bloat et des timeouts.
- Partir du principe qu’un default est gratuit. Sous PostgreSQL, certains defaults déclenchent une réécriture de table.
- Basculer les lectures vers la nouvelle colonne avant que les écritures ne la remplissent de façon fiable.
- Oublier d’autres writers et lecteurs (cron, workers, exports, requêtes de reporting).
Un scénario réaliste : vous commencez à écrire full_name depuis l’API, mais un job d’arrière-plan qui crée des utilisateurs ne met à jour que first_name et last_name. Il s’exécute la nuit, insère des lignes avec full_name = NULL, et plus tard le code suppose que full_name est toujours présent.
Traitez chaque étape comme une release qui peut durer des jours :
- Gardez la nouvelle colonne nullable pendant la transition, et appliquez l’obligation (« required ») d’abord dans le code.
- Backfillez en petits lots avec pauses, et surveillez la charge BD.
- Rendez le code tolérant : lisez les deux chemins, écrivez les deux quand nécessaire, gérez les valeurs manquantes.
- Auditez chaque endroit qui touche la table, y compris workers et rapports.
Checklist rapide avant chaque release
Une checklist répétable vous évite d’envoyer du code qui ne fonctionne que dans un seul état de la base.
Avant de déployer, confirmez que la base contient déjà les éléments étendus (nouvelles colonnes/tables, index créés de façon peu verrous). Puis confirmez que l’app est tolérante : elle doit fonctionner contre l’ancienne forme, la forme étendue et un état à moitié backfillé.
Gardez la checklist courte :
- Expansion présente : les nouveaux objets de schéma existent et ont été ajoutés de façon peu bloquante.
- Compatibilité réelle : l’app fonctionne avec l’ancien et le schéma étendu, y compris workers et chemins admin.
- Backfill contrôlé : petits lots, pausables, avec métriques de progression basiques.
- Basculement des lectures planifié : vous savez exactement quand les lectures changent et comment rollbacker si les résultats sont mauvais.
- Contract retardé : attendez au moins un ou deux cycles de release avant de supprimer les anciens objets.
Une migration est terminée quand les lectures utilisent les nouvelles données, les écritures n’entretiennent plus l’ancien état, et vous avez vérifié le backfill avec au moins un contrôle simple (comptes ou échantillonnage).
Exemple réaliste : remplacer une colonne sans downtime
Supposons une table PostgreSQL customers avec une colonne phone aux formats variables. Vous voulez la remplacer par phone_e164 sans bloquer les releases ni arrêter l’app.
Une séquence expand/contract propre :
- Expand : ajoutez
phone_e164 nullable, sans valeur par défaut et sans contraintes fortes.
- Déploiement compatible : mettez à jour le code pour écrire à la fois
phone et phone_e164, mais conservez les lectures sur phone pour l’utilisateur.
- Backfill : convertissez les lignes existantes par petits lots (par ex. 1 000 à la fois).
- Basculement des lectures : déployez du code qui lit
phone_e164 en priorité et retombe sur phone si NULL.
- Contract : une fois sûr que tout utilise
phone_e164, retirez le fallback, supprimez phone, puis ajoutez des contraintes plus strictes si nécessaire.
Le rollback reste simple si chaque étape est rétrocompatible. Si le basculement de lecture pose problème, revenez au déploiement précédent : la base a toujours les deux colonnes. Si le backfill provoque des pics, mettez le job en pause, réduisez la taille des lots et reprenez.
Pour garder l’équipe alignée, documentez le plan en un seul endroit : le SQL exact, quelle release bascule les lectures, comment mesurer l’achèvement (par ex. pourcentage non-NULL de phone_e164), et qui est responsable de chaque étape.
Étapes suivantes : rendre le processus répétable
Expand/contract fonctionne mieux quand c’est routinier. Rédigez un runbook court que l’équipe pourra réutiliser pour chaque changement de schéma, idéalement d’une page et assez spécifique pour qu’un nouvel arrivant puisse le suivre.
Un modèle pratique couvre :
- Expand (migrations exactes)
- Changements de code (ce qui doit rester rétrocompatible, où utiliser dual-read ou dual-write)
- Backfill (taille des lots, limites de débit, pause/reprise)
- Vérification (requêtes et métriques qui prouvent la correction)
- Contract (ce qui est supprimé et quand)
Décidez de la propriété à l’avance. « Tout le monde pensait que quelqu’un d’autre ferait le contract » est la raison pour laquelle d’anciennes colonnes et feature flags persistent pendant des mois.
Même si le backfill s’exécute en ligne, planifiez-le pendant des heures de trafic plus faible. Il est plus simple de garder des lots petits, surveiller la charge DB et arrêter rapidement si la latence remonte.
Si vous construisez et déployez avec Koder.ai (koder.ai), Planning Mode peut aider à cartographier les phases et checkpoints avant d’attaquer la production. Les mêmes règles de compatibilité s’appliquent, mais écrire les étapes empêche d’omettre les parties ennuyeuses qui évitent les interruptions.