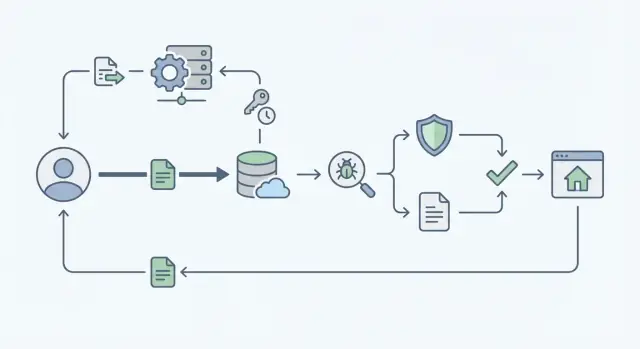
Qué hace que las subidas de archivos sean difíciles a escala
Las subidas de archivos parecen sencillas hasta que llegan usuarios reales. Una persona sube una foto de perfil. Luego diez mil usuarios suben PDFs, vídeos y hojas de cálculo al mismo tiempo. De pronto la app se siente lenta, los costes de almacenamiento suben y los tickets de soporte se acumulan.
Los modos de falla comunes son previsibles. Las páginas de subida se quedan colgadas o caducan cuando tu servidor intenta gestionar todo el archivo en lugar de dejar que el almacenamiento de objetos haga el trabajo pesado. Los permisos derivan, así que alguien adivina una URL de objeto y ve algo que no debería. Llegan archivos “inofensivos” con malware o con formatos complicados que rompen herramientas posteriores. Y los logs son incompletos, así que no puedes responder preguntas básicas como quién subió qué y cuándo.
Lo que quieres en realidad es aburrido y fiable: subidas rápidas, reglas claras (tipos y tamaños permitidos) y una pista de auditoría que facilite investigar incidentes.
La compensación más difícil es velocidad versus seguridad. Si ejecutas todas las comprobaciones antes de que el usuario termine, esperará y reintentará, lo que aumenta la carga. Si pospones las comprobaciones demasiado, archivos inseguros o no autorizados pueden propagarse antes de que los detectes. Un enfoque práctico es separar la subida de las comprobaciones y mantener cada paso rápido y medible.
También sé específico sobre “escala”. Anota tus números: archivos por día, picos de subidas por minuto, tamaño máximo de archivo y dónde están tus usuarios. Las regiones importan por latencia y normas de privacidad.
Si construyes una app en una plataforma como Koder.ai, ayuda decidir estos límites pronto, porque moldean cómo diseñas permisos, almacenamiento y el flujo de trabajo de escaneo en segundo plano.
Un modelo de amenazas simple para subidas
Antes de elegir herramientas, aclara qué puede salir mal. Un modelo de amenazas no necesita ser un documento grande. Es un entendimiento breve y compartido de lo que debes prevenir, lo que puedes detectar después y qué compensaciones aceptarás.
Los atacantes suelen intentar colarse en puntos previsibles: el cliente (cambiando metadatos o falsificando el MIME type), el borde de la red (replays y abuso de rate-limit), el almacenamiento (adivinando nombres de objetos, sobrescribiendo) y la descarga/preview (activando rendering riesgoso o robando archivos vía acceso compartido).
A partir de ahí, mapea las amenazas a controles simples:
Los archivos sobredimensionados son el abuso más fácil. Pueden disparar costes y ralentizar a usuarios reales. Deténlos temprano con límites estrictos en bytes y rechazo rápido.
Los tipos falsos vienen después. Un archivo llamado invoice.pdf puede ser otra cosa. No confíes en extensiones o comprobaciones de UI. Verifica según los bytes reales después de la subida.
El malware es distinto. Normalmente no puedes escanear todo antes de que la subida termine sin hacer la experiencia dolorosa. El patrón habitual es detectarlo de forma asíncrona, poner en cuarentena los ítems sospechosos y bloquear el acceso hasta que el escaneo pase.
El acceso no autorizado suele ser lo más dañino. Trata cada subida y cada descarga como una decisión de permiso. Un usuario solo debe subir a una ubicación que posea (o a la que tenga permiso de escribir) y solo descargar archivos que pueda ver.
Para muchas apps, una política sólida v1 es:
- Hacer cumplir tamaño máximo y categorías permitidas (imágenes, PDFs, etc.)
- Verificar el tipo real del archivo en el servidor después de la subida
- Escanear de forma asíncrona y poner en cuarentena hasta que esté limpio
- Requerir autorización explícita para subir y descargar
- Registrar y alertar sobre fallos repetidos (tamaño, tipo, auth)
Una arquitectura práctica de subida que sigue siendo rápida
La forma más rápida de manejar subidas es mantener a tu servidor de aplicación fuera del “negocio de los bytes”. En lugar de enviar cada archivo a través de tu backend, deja que el cliente suba directamente al almacenamiento de objetos usando una URL firmada de corta duración. Tu backend se concentra en decisiones y registros, no en empujar gigabytes.
La separación es simple: el backend responde “quién puede subir qué y dónde”, mientras el almacenamiento recibe los datos del archivo. Esto elimina un cuello de botella común: servidores de app que hacen trabajo doble (auth más proxy del archivo) y se quedan sin CPU, memoria o red bajo carga.
Las piezas mínimas necesarias
Mantén un registro pequeño de la subida en tu base de datos (por ejemplo, PostgreSQL) para que cada archivo tenga un propietario claro y un ciclo de vida definido. Crea este registro antes de que comience la subida y actualízalo a medida que ocurren eventos.
Campos que suelen ser valiosos incluyen identificadores de owner y tenant/workspace, la key del objeto en almacenamiento, un estado, el tamaño y MIME reclamados, y un checksum que puedas verificar.
Planea los estados de la subida desde el inicio
Trata las subidas como una máquina de estados para que las comprobaciones de permisos sigan siendo correctas incluso cuando hay reintentos.
Un conjunto práctico de estados es:
solicitadosubidoanalizadoaprobadorechazado
Solo permite que el cliente use la URL firmada después de que el backend cree un registro solicitado. Tras la confirmación del almacenamiento de la subida, muévelo a subido, lanza el escaneo de malware en segundo plano y solo expón el archivo una vez que esté aprobado.
Paso a paso: subidas con URL firmadas sin cuellos de botella
Empieza cuando el usuario hace clic en Subir. Tu app llama al backend para iniciar una subida con detalles básicos como nombre de archivo, tamaño y uso previsto (avatar, factura, adjunto). El backend comprueba permiso para ese destino específico, crea un registro de subida y devuelve una URL firmada de corta duración.
La URL firmada debe tener un alcance estrecho. Idealmente solo permite una única subida a una clave de objeto exacta, con una expiración corta y condiciones claras (límite de tamaño, tipo de contenido permitido, checksum opcional).
El navegador sube directamente al almacenamiento usando esa URL. Cuando termina, el navegador llama al backend otra vez para finalizar. En la finalización, vuelve a verificar permisos (los usuarios pueden perder acceso) y verifica lo que realmente quedó en almacenamiento: tamaño, tipo detectado y checksum si usas uno. Haz la operación de finalizar idempotente para que los reintentos no creen duplicados.
Luego marca el registro como subido y desencadena el escaneo en segundo plano (cola/job). La UI puede mostrar “Procesando” mientras corre el escaneo.
Validación de tipo y tamaño en la que puedas confiar
Enviar permisos multi-tenant
Genera reglas claras de autorización de carga y descarga por workspace o tenant.
Qué validar y dónde
Confiar en una extensión es como terminar con invoice.pdf.exe en tu bucket. Trata la validación como un conjunto repetible de comprobaciones que ocurren en más de un lugar.
Empieza con límites de tamaño. Pon el tamaño máximo en la política de la URL firmada (o en las condiciones del pre-signed POST) para que el almacenamiento pueda rechazar subidas sobredimensionadas temprano. Aplica el mismo límite otra vez cuando tu backend registre los metadatos, porque los clientes aún pueden intentar eludir la UI.
Las comprobaciones de tipo deben basarse en el contenido, no en el nombre de archivo. Inspecciona los primeros bytes del archivo (magic bytes) para confirmar que coinciden con lo esperado. Un PDF real comienza con %PDF, y los PNG comienzan con una firma fija. Si el contenido no coincide con tu allowlist, recházalo aunque la extensión parezca correcta.
Mantén listas de permitidos específicas por funcionalidad. Una subida de avatar puede permitir solo JPEG y PNG. Una función de documentos puede permitir PDF y DOCX. Esto reduce el riesgo y hace tus reglas más fáciles de explicar.
Checksums y nombres de archivo
Nunca confíes en el nombre original como clave de almacenamiento. Normalízalo para mostrar (elimina caracteres extraños, acorta la longitud), pero guarda tu propia key segura, como un UUID más una extensión que asignes después de la detección de tipo.
Almacena un checksum (por ejemplo SHA-256) en tu base de datos y compáralo más tarde durante el procesamiento o escaneo. Esto ayuda a detectar corrupción, subidas parciales o manipulación, especialmente cuando las subidas se reintentan bajo carga.
Escaneo de malware que no hace esperar a los usuarios
El escaneo de malware importa, pero no debería estar en la ruta crítica. Acepta la subida rápidamente y luego trata el archivo como bloqueado hasta que pase un escaneo.
El patrón asíncrono
Crea un registro de subida con un estado como pendiente_de_escaneo. La UI puede mostrar el archivo, pero no debe ser utilizable aún.
El escaneo normalmente se desencadena por un evento de almacenamiento cuando se crea el objeto, publicando un trabajo en una cola justo después de la finalización de la subida, o ambas cosas (cola más evento de almacenamiento como respaldo).
El worker de escaneo descarga o streamnea el objeto, ejecuta los scanners y luego escribe el resultado en tu base de datos. Conserva lo esencial: estado del escaneo, versión del scanner, timestamps y quién solicitó la subida. Esa pista de auditoría facilita mucho el soporte cuando alguien pregunta “¿Por qué se bloqueó mi archivo?”.
Qué ocurre cuando un archivo falla
No dejes archivos fallidos mezclados con los limpios. Elige una política y aplícala de forma consistente: poner en cuarentena y quitar acceso, o eliminar si no lo necesitas para investigar.
Sea lo que sea, comunica al usuario con calma y precisión. Diles qué pasó y qué hacer a continuación (re-subir, contactar soporte). Alerta a tu equipo si ocurren muchas fallas en poco tiempo.
Lo más importante: establece una regla estricta para descargas y previews: solo los archivos marcados como aprobado pueden ser servidos. Todo lo demás debe devolver una respuesta segura como “El archivo aún está siendo verificado”.
Comprobaciones de permiso que siguen siendo correctas bajo carga
Las subidas rápidas son estupendas, pero si la persona equivocada puede adjuntar un archivo al workspace equivocado, tienes un problema mayor que solicitudes lentas. La regla más simple y fuerte es: cada registro de archivo pertenece exactamente a un tenant (workspace/organización/proyecto) y tiene un owner o creador claro.
Haz comprobaciones de permiso dos veces: cuando emites la URL firmada para subir y de nuevo cuando alguien intenta descargar o ver el archivo. La primera comprobación detiene subidas no autorizadas. La segunda te protege si el acceso se revoca, una URL se filtra o el rol de un usuario cambia después de la subida.
El principio de menor privilegio mantiene tanto la seguridad como el rendimiento predecibles. En lugar de un permiso amplio “files”, separa roles como “puede subir”, “puede ver” y “puede gestionar (borrar/compartir)”. Muchas solicitudes entonces son búsquedas rápidas (usuario, tenant, acción) en lugar de lógica personalizada costosa.
Para evitar adivinación de IDs, evita IDs secuenciales en URLs y APIs. Usa identificadores opacos y mantén las keys de almacenamiento no adivinables. Las URLs firmadas son transporte, no tu sistema de permisos.
Los archivos compartidos son donde los sistemas a menudo se vuelven lentos y desordenados. Trata el compartir como datos explícitos, no acceso implícito. Un enfoque simple es un registro de compartición separado que conceda permiso a un usuario o grupo a un archivo, opcionalmente con expiración.
Mantener las subidas rápidas a medida que crecen tráfico y tamaño de archivos
Poner en cuarentena archivos hasta aprobar
Configura trabajos en segundo plano para escaneo y solo sirve archivos tras la aprobación.
Cuando se habla de escalar subidas seguras, a menudo se enfocan en las comprobaciones de seguridad y olvidan lo básico: mover bytes es lo lento. El objetivo es mantener el tráfico de archivos grandes fuera de tus servidores de app, controlar los reintentos y evitar convertir las comprobaciones de seguridad en una cola desbordada.
Haz predecibles los archivos grandes
Para archivos grandes, usa subidas multipart o por chunks para que una conexión inestable no obligue a reiniciar desde cero. Los chunks también te ayudan a imponer límites más claros: tamaño total máximo, tamaño máximo por chunk y tiempo máximo de subida.
Establece timeouts y reintentos deliberados en el cliente. Algunos reintentos ayudan a usuarios reales; reintentos ilimitados pueden explotar costes, especialmente en redes móviles. Apunta a timeouts cortos por chunk, un pequeño tope de reintentos y una fecha límite dura para toda la subida.
Controla el paso de “create upload”
Las URLs firmadas mantienen la ruta de datos ligera, pero la petición que las crea sigue siendo un punto caliente. Protégela para que siga respondiendo:
- Rate-limit en “create upload” por usuario y por IP
- Impone límites de tamaño antes de emitir la URL firmada
- Mantén un TTL corto para que las URLs no usadas expiren pronto
- Rastrea subidas en curso para que un usuario no pueda iniciar cientos a la vez
- Usa claves de idempotencia para que refrescos no creen subidas duplicadas
La latencia también depende de la geografía. Mantén tu app, almacenamiento y workers de escaneo en la misma región cuando sea posible. Si necesitas hosting por país para cumplimiento, planifica el enrutamiento temprano para que las subidas no reboten entre continentes. Plataformas que corren globalmente en AWS (como Koder.ai) pueden situar workloads más cerca de usuarios cuando la residencia de datos importa.
Finalmente, planifica las descargas, no solo las subidas. Sirve archivos con URLs firmadas de descarga y establece reglas de caché según tipo de archivo y nivel de privacidad. Activos públicos pueden cacharse más tiempo; recibos privados deben tener tokens de corta duración y comprobaciones de permiso.
Ejemplo: facturas y recibos en una app multiusuario
Imagina una app para pequeñas empresas donde empleados suben facturas y fotos de recibos, y un manager las aprueba para reembolso. Aquí el diseño de subidas deja de ser académico: tienes muchos usuarios, imágenes grandes y dinero real en juego.
Un buen flujo usa estados claros para que todos sepan qué pasa y puedas automatizar lo aburrido: el archivo llega al almacenamiento de objetos y guardas un registro vinculado al usuario/workspace/gasto; un job en segundo plano escanea el archivo y extrae metadatos básicos (como el tipo MIME real); luego el ítem se aprueba y se hace usable en informes, o se rechaza y bloquea.
Los usuarios necesitan feedback rápido y específico. Si el archivo es demasiado grande, muestra el límite y el tamaño actual (por ejemplo: “El archivo tiene 18 MB. El máximo es 10 MB.”). Si el tipo es incorrecto, indica qué está permitido (“Sube un PDF, JPG o PNG”). Si el escaneo falla, mantén el mensaje calmado y accionable (“Este archivo podría ser inseguro. Por favor sube otra copia.”).
Los equipos de soporte necesitan un rastro que les ayude a depurar sin abrir el archivo: upload ID, user ID, workspace ID, timestamps de creado/subido/scan iniciado/scan finalizado, códigos de resultado (demasiado grande, tipo no coincide, scan fallido, permiso denegado), además de key de almacenamiento y checksum.
Las re-subidas y reemplazos son comunes. Trátalas como nuevas subidas, adjúntalas al mismo gasto como una nueva versión, conserva el historial (quién lo reemplazó y cuándo) y marca solo la versión más reciente como activa. Si construyes esta app en Koder.ai, esto mapea limpiamente a una tabla uploads más una tabla expense_attachments con un campo de versión.
Errores comunes y arreglos fáciles
Desplegar más cerca de los usuarios
Lanza en regiones de AWS que se ajusten a latencia y requisitos de residencia de datos.
La mayoría de bugs en subidas no son trucos sofisticados. Son atajos pequeños que se convierten en riesgo real cuando el tráfico crece.
Los cinco errores que aparecen con más frecuencia
- Confiar solo en las comprobaciones del lado cliente. Arreglo: valida de nuevo en el servidor usando bytes reales (magic bytes) y aplica límites de tamaño usando metadatos de almacenamiento, no solo el reporte del navegador.
- Hacer las URLs firmadas de larga duración. Arreglo: mantenlas cortas (minutos), de un solo propósito y limitadas a una key de objeto. Rota credenciales y registra cada emisión.
- Permitir descargas antes de que termine el escaneo. Arreglo: sube a una ubicación en cuarentena, escanea asíncronamente y solo promueve o sirve tras un resultado limpio.
- Usar nombres o rutas proporcionadas por el usuario como claves de almacenamiento. Arreglo: genera tus propias keys de objeto (UUIDs) y guarda el nombre original como metadata de presentación.
- Omitir comprobaciones de permiso en la descarga. Arreglo: trata la descarga como una decisión separada y vuelve a verificar propiedad, pertenencia al workspace y reglas de compartición cada vez que crees una URL de descarga.
Arreglos sencillos que previenen cuellos de botella
Más comprobaciones no tienen por qué hacer las subidas lentas. Separa la ruta rápida de la ruta pesada.
Haz comprobaciones rápidas de forma síncrona (auth, tamaño, tipo permitido, rate limits) y luego delega el escaneo y la inspección profunda a un worker en segundo plano. Los usuarios pueden seguir trabajando mientras el archivo pasa de “subido” a “listo”. Si construyes con un builder basado en chat como Koder.ai, aplica la misma mentalidad: haz el endpoint de subida pequeño y estricto y empuja el escaneo y el post-procesamiento a jobs.
Lista rápida y siguientes pasos
Antes de lanzar las subidas, define qué significa “suficientemente seguro para v1”. Los equipos suelen meterse en problemas mezclando reglas estrictas (que bloquean a usuarios reales) con reglas ausentes (que invitan abuso). Empieza pequeño, pero asegúrate de que cada subida tenga un camino claro desde “recibido” hasta “permitido para descargar”.
Una checklist previa al lanzamiento:
- Hacer cumplir un límite duro de tamaño temprano (antes de que crezcan los costes de almacenamiento)
- Usar una allowlist de tipos validada por contenido (magic bytes), no solo por nombre de archivo
- Bloquear acceso hasta que el escaneo pase: no sirvas archivos a otros antes
- Requerir comprobaciones de autorización en cada descarga
- Mantener logs de auditoría para subida, resultado de escaneo e intentos de descarga
Si necesitas una política mínima viable, mantenla simple: límite de tamaño, allowlist estricta de tipos, subida con URL firmada y “cuarentena hasta que el escaneo pase”. Agrega características posteriores (previews, más tipos, reprocesamiento en segundo plano) una vez que la ruta central sea estable.
El monitoreo es lo que evita que “rápido” se vuelva “misteriosamente lento” conforme creces. Mide la tasa de fallos de subida (cliente vs servidor/almacenamiento), tasa de fallos de escaneo y latencia de escaneo, tiempo medio de subida por bucket de tamaño, denegaciones de autorización en descarga y patrones de egreso de almacenamiento.
Realiza una pequeña prueba de carga con tamaños de archivo realistas y redes del mundo real (datos móviles se comportan distinto al Wi‑Fi de oficina). Arregla timeouts y reintentos antes del lanzamiento.
Si estás implementando esto en Koder.ai (koder.ai), Planning Mode es un lugar práctico para mapear tus estados y endpoints primero, y luego generar el backend y la UI alrededor de ese flujo. Snapshots y rollback también ayudan cuando ajustas límites o reglas de escaneo.