09 dic 2025·8 min
SQL vs NoSQL: diferencias clave y casos de uso
Conoce las diferencias reales entre bases de datos SQL y NoSQL: modelos de datos, escalabilidad, consistencia y cuándo conviene usar cada una según tu aplicación.
Conoce las diferencias reales entre bases de datos SQL y NoSQL: modelos de datos, escalabilidad, consistencia y cuándo conviene usar cada una según tu aplicación.
La elección entre bases de datos SQL y NoSQL condiciona cómo diseñas, construyes y escalas tu aplicación. El modelo de datos influye en todo: estructuras de datos, patrones de consulta, rendimiento, fiabilidad y la rapidez con que tu equipo puede evolucionar el producto.
A grandes rasgos, las bases de datos SQL son sistemas relacionales. Los datos se organizan en tablas con esquemas fijos, filas y columnas. Las relaciones entre entidades son explícitas (mediante claves foráneas) y consultas se realizan con SQL, un lenguaje declarativo potente. Estos sistemas enfatizan transacciones ACID, consistencia fuerte y una estructura bien definida.
Las bases de datos NoSQL son sistemas no relacionales. En lugar de un modelo tabular rígido, ofrecen varios modelos de datos diseñados para distintas necesidades, como:
Eso significa que “NoSQL” no es una sola tecnología, sino un término paraguas para múltiples enfoques, cada uno con sus compensaciones en flexibilidad, rendimiento y modelado de datos. Muchos sistemas NoSQL relajan garantías estrictas de consistencia a cambio de alta escalabilidad, disponibilidad o baja latencia.
Este artículo se centra en la diferencia entre SQL y NoSQL: modelos de datos, lenguajes de consulta, rendimiento, escalabilidad y consistencia (ACID frente a consistencia eventual). El objetivo es ayudarte a elegir entre SQL y NoSQL para proyectos concretos y entender cuándo encaja mejor cada tipo de base de datos.
No tienes que elegir solo una. Muchas arquitecturas modernas usan persistencia poliglota, donde SQL y NoSQL coexisten en un mismo sistema, cada uno manejando las cargas para las que son más adecuados.
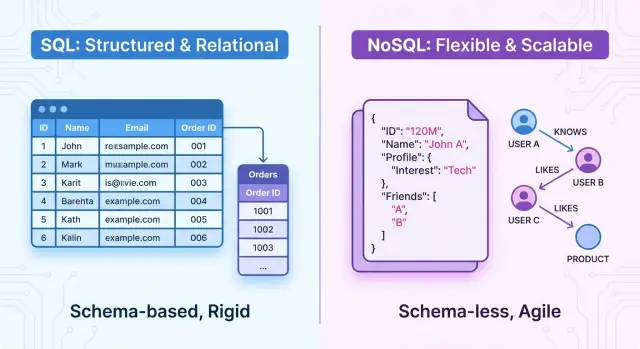
Una base de datos SQL (relacional) almacena datos en forma tabular estructurada y usa Structured Query Language (SQL) para definir, consultar y manipular esos datos. Se construye sobre el concepto matemático de relaciones, que puedes pensar como tablas bien organizadas.
Los datos se organizan en tablas. Cada tabla representa un tipo de entidad, como customers, orders o products.
email o order_date.Cada tabla sigue un esquema fijo: una estructura predefinida que especifica
INTEGER, VARCHAR, DATE)NOT NULL, UNIQUE)El esquema lo aplica la base de datos, lo que ayuda a mantener los datos coherentes y previsibles.
Las bases de datos relacionales sobresalen al modelar cómo se relacionan las entidades.
customer_id).\n- Una clave foránea es una columna que hace referencia a la clave primaria de otra tabla, enlazando filas relacionadas.Estas claves permiten definir relaciones tales como:
Las bases de datos relacionales soportan transacciones: grupos de operaciones que se comportan como una unidad. Las transacciones se definen por las propiedades ACID:
Estas garantías son cruciales para sistemas financieros, gestión de inventarios y cualquier aplicación donde la corrección importe.
Sistemas relacionales populares incluyen:
Todos implementan SQL, añadiendo sus propias extensiones y herramientas para administración, optimización y seguridad.
Las bases de datos NoSQL son almacenes de datos no relacionales que no usan el modelo tradicional tabla–fila–columna de los sistemas SQL. En su lugar, se centran en modelos de datos flexibles, escalabilidad horizontal y alta disponibilidad, a menudo a costa de garantías transaccionales estrictas.
Muchas bases NoSQL se describen como sin esquema o con esquema flexible. En vez de definir un esquema rígido por adelantado, puedes almacenar registros con distintos campos o estructuras en la misma colección o bucket.
Esto es especialmente útil para:
Como los campos pueden añadirse u omitirse por registro, los desarrolladores pueden iterar rápido sin migraciones por cada cambio estructural.
NoSQL es un término paraguas que cubre varios modelos distintos:
Muchos sistemas NoSQL priorizan disponibilidad y tolerancia a particiones, proporcionando consistencia eventual en lugar de transacciones ACID estrictas en todo el conjunto de datos. Algunos ofrecen niveles de consistencia tunables o capacidades transaccionales limitadas (por documento, partición o rango de claves), de forma que puedes escoger entre garantías más fuertes y mayor rendimiento para operaciones específicas.
Aquí es donde SQL y NoSQL se sienten más diferentes. El modelado de datos condiciona cómo diseñas funciones, consultas y cómo evolucionará la aplicación.
Las bases SQL usan esquemas estructurados y predefinidos. Diseñas tablas y columnas por adelantado, con tipos y restricciones estrictas:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT NOT NULL,
total DECIMAL(10, 2) NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(id)
);
Cada fila debe ajustarse al esquema. Cambiarlo después suele implicar migraciones (ALTER TABLE, backfilling, etc.).
Las bases NoSQL suelen soportar esquemas flexibles. Un almacén de documentos puede permitir que cada documento tenga campos distintos:
{
"_id": 1,
"name": "Alice",
"orders": [
{ "id": 101, "total": 49.99 },
{ "id": 102, "total": 15.50 }
]
}
Los campos pueden añadirse por documento sin una migración central. Algunos sistemas NoSQL admiten esquemas opcionales o impuestos, pero en general son más laxos.
Los modelos relacionales fomentan la normalización: dividir datos en tablas relacionadas para evitar duplicación y mantener la integridad. Esto favorece escrituras consistentes y rápidas y menor uso de almacenamiento, pero las lecturas complejas pueden requerir joins entre muchas tablas.
Los modelos NoSQL suelen favorecer la desnormalización: incrustar datos relacionados para las lecturas que más te importan. Esto mejora el rendimiento en lectura y simplifica consultas, pero las escrituras pueden ser más lentas o complejas porque la misma información puede vivir en varios lugares.
En SQL, las relaciones son explícitas y aplicadas:
En NoSQL, las relaciones se modelan mediante:
La elección depende de tus patrones de acceso:
Con SQL, los cambios de esquema requieren más planificación pero ofrecen garantías fuertes y consistencia en todo el conjunto de datos. Las refactorizaciones son explícitas: migraciones, backfills, actualización de restricciones.
Con NoSQL, los requisitos en evolución suelen ser más fáciles de soportar a corto plazo. Puedes empezar a guardar nuevos campos de inmediato y actualizar gradualmente los documentos antiguos. La compensación es que el código de la aplicación debe manejar múltiples formas de documento y casos límite.
Elegir entre modelos normalizados (SQL) y desnormalizados (NoSQL) no es sobre "mejor o peor": se trata de alinear la estructura de datos con tus patrones de consulta, volumen de escrituras y frecuencia de cambios en el modelo de dominio.
Las bases SQL se consultan con un lenguaje declarativo: describes qué quieres, no cómo obtenerlo. Constructos como SELECT, WHERE, JOIN, GROUP BY y ORDER BY permiten expresar preguntas complejas sobre varias tablas en una sola sentencia.
Como SQL está estandarizado (ANSI/ISO), la mayoría de los sistemas relacionales comparten una sintaxis base común. Los proveedores añaden extensiones, pero habilidades y consultas suelen transferirse razonablemente entre PostgreSQL, MySQL, SQL Server y otros.
Esta estandarización trae un ecosistema rico: ORMs, constructores de consultas, herramientas de reporting, BI, frameworks de migración y optimizadores de consultas. Puedes integrar muchas de estas herramientas con cualquier base SQL con cambios mínimos, lo que reduce el vendor lock‑in y acelera el desarrollo.
Los sistemas NoSQL exponen consultas de formas variadas:
Algunas bases NoSQL ofrecen pipelines de agregación o mecanismos tipo MapReduce para analítica, pero las joins cross‑colección o cross‑partición son limitadas o inexistentes. En su lugar, los datos relacionados suelen incrustarse en el mismo documento o desnormalizarse entre registros.
Las consultas relacionales a menudo dependen de patrones con muchos JOINs: normalizas los datos y los reconstruyes al leer con joins. Esto es potente para reporting ad‑hoc y preguntas en evolución, pero los joins complejos pueden ser más difíciles de optimizar.
Los patrones NoSQL tienden a ser centrados en documento o clave: diseña los datos alrededor de las consultas más frecuentes. Las lecturas son rápidas y simples—a menudo una sola búsqueda por clave—pero cambiar patrones de acceso después puede requerir remodelado de datos.
Para aprendizaje y productividad:
Los equipos que necesitan consultas ad‑hoc ricas a través de relaciones suelen preferir SQL. Los equipos con patrones de acceso estables y predecibles a gran escala encuentran que los modelos de consulta NoSQL encajan mejor con sus necesidades.
La mayoría de bases SQL se diseñan alrededor de transacciones ACID:
Esto hace a SQL una buena elección cuando la corrección es más importante que el rendimiento bruto de escritura.
Muchos sistemas NoSQL se inclinan por propiedades BASE:
Las escrituras pueden ser muy rápidas y distribuidas, pero una lectura puede ver datos obsoletos durante un breve intervalo.
CAP dice que un sistema distribuido bajo particiones de red debe elegir entre:
No puedes garantizar C y A durante una partición.
Patrones típicos:
Los sistemas modernos a menudo mezclan modos (por ejemplo, consistencia ajustable por operación) para que diferentes partes de una aplicación elijan las garantías que necesitan.
Las bases SQL tradicionales se diseñaron para un único nodo potente.
Normalmente comienzas escalando verticalmente: más CPU, RAM y discos rápidos en un solo servidor. Muchos motores también soportan réplicas de lectura: nodos adicionales que atienden tráfico de solo lectura mientras todas las escrituras van al primario. Este patrón funciona bien para:
Sin embargo, el escalado vertical alcanza límites físicos y de coste, y las réplicas de lectura pueden introducir latencia de replicación para lecturas.
Los sistemas NoSQL suelen construirse para escalar horizontalmente: distribuir datos a través de muchos nodos usando sharding o particionado. Cada shard contiene un subconjunto de datos, de modo que lecturas y escrituras se pueden distribuir, aumentando el rendimiento.
Este enfoque es adecuado para:
La contrapartida es mayor complejidad operacional: elegir claves de shard, gestionar rebalanceos y tratar consultas cross‑shard.
Para cargas con muchas lecturas con joins y agregaciones complejas, una base SQL con índices bien diseñados puede ser extremadamente rápida, porque el optimizador usa estadísticas y planes de consulta.
Muchos sistemas NoSQL favorecen accesos simples por clave. Sobresalen en búsquedas de baja latencia y alto throughput cuando las consultas son predecibles y los datos se modelan alrededor de patrones de acceso en lugar de consultas ad‑hoc.
La latencia en clústeres NoSQL puede ser muy baja, pero las consultas cross‑partición, índices secundarios y operaciones multi‑documento pueden ser más lentas o limitadas. Operacionalmente, escalar NoSQL suele requerir más gestión del clúster, mientras que escalar SQL suele requerir mejor hardware e índices cuidadosos en menos nodos.
Las bases relacionales brillan cuando necesitas OLTP (procesamiento de transacciones en línea) fiable y de alto volumen:
Estos sistemas dependen de transacciones ACID, consistencia estricta y comportamiento claro en rollbacks. Si una transferencia nunca debe doble‑cobrar o perder dinero entre dos cuentas, una base SQL suele ser más segura que la mayoría de las opciones NoSQL.
Cuando tu modelo de datos está bien comprendido y es estable, y las entidades están fuertemente relacionadas, una base relacional suele ser la opción natural. Ejemplos:
Los esquemas normalizados, claves foráneas y joins de SQL facilitan imponer integridad y consultar relaciones complejas sin duplicar datos.
Para reporting y BI sobre datos claramente estructurados (esquemas estrella/copos de nieve, data marts), las bases SQL y los data warehouses compatibles con SQL suelen ser la elección. Los equipos analíticos conocen SQL y las herramientas existentes (dashboards, ETL, gobernanza) se integran directamente.
A menudo se pasa por alto la madurez operacional. Las bases SQL ofrecen:
Cuando las auditorías, certificaciones o exposición legal son relevantes, una base SQL suele ser la opción más directa y defendible en la comparación SQL vs NoSQL.
NoSQL tiende a encajar mejor cuando la escala, la flexibilidad y la disponibilidad continua importan más que los joins complejos y las garantías transaccionales estrictas.
Si esperas un volumen masivo de escrituras, picos impredecibles o datasets que crezcan a terabytes y más, los sistemas NoSQL (clave‑valor o column‑family) suelen ser más fáciles de escalar horizontalmente. Sharding y replicación suelen estar integrados, permitiéndote añadir capacidad con nodos adicionales en lugar de re‑arquitecturar un único servidor potente.
Patrón habitual en:
Cuando tu modelo de datos cambia con frecuencia, un diseño flexible o sin esquema es valioso. Las bases de documentos permiten evolucionar campos y estructuras sin migraciones por cada cambio.
Funciona bien para:
Los almacenes NoSQL son fuertes en cargas append‑heavy y ordenadas por tiempo:
Las bases clave‑valor y de series temporales están optimizadas para escrituras muy rápidas y lecturas sencillas.
Muchas plataformas NoSQL priorizan la geo‑replicación y escrituras multi‑región, permitiendo que usuarios globales lean y escriban con baja latencia. Esto es útil cuando:
La contrapartida suele ser aceptar consistencia eventual en lugar de semánticas ACID estrictas a través de regiones.
Elegir NoSQL suele implicar renunciar a algunas funcionalidades habituales en SQL:
Cuando estas compensaciones son aceptables, NoSQL puede ofrecer mejor escalabilidad, flexibilidad y alcance global que una base relacional tradicional.
La persistencia poliglota significa usar deliberadamente múltiples tecnologías de base de datos en el mismo sistema, escogiendo la mejor herramienta para cada trabajo en lugar de forzar todo en una sola tienda.
Un patrón común es:
Esto mantiene el “sistema de registro” en una base relacional y descarga cargas volátiles o intensivas en lectura a NoSQL.
También puedes combinar sistemas NoSQL:
La meta es alinear cada almacén con un patrón de acceso específico: búsquedas simples, agregados, búsqueda o lecturas temporales.
Las arquitecturas híbridas requieren puntos de integración:
La contrapartida es sobrecoste operativo: más tecnologías que aprender, monitorizar, asegurar, respaldar y depurar. La persistencia poliglota funciona mejor cuando cada datastore adicional resuelve un problema real y medible, no solo por moda.
Elegir entre SQL y NoSQL consiste en emparejar tus datos y patrones de acceso con la herramienta adecuada, no en seguir tendencias.
Pregunta:
Si la respuesta es sí, una base relacional suele ser la opción por defecto. Si tus datos son tipo documento, anidados o varían mucho de registro a registro, un modelo de documento u otro NoSQL puede encajar mejor.
La consistencia estricta y transacciones complejas suelen favorecer SQL. Alto throughput de escritura con consistencia relajada puede favorecer NoSQL.
La mayoría de proyectos pueden escalar mucho con SQL si se usan buenos índices y hardware. Si anticipas escala muy grande con patrones simples (búsquedas por clave, series temporales, logs), ciertos sistemas NoSQL pueden resultar más económicos.
SQL sobresale en consultas complejas, herramientas BI y exploración ad‑hoc. Muchas bases NoSQL se optimizan para rutas de acceso predefinidas y pueden hacer nuevas consultas más difíciles o costosas.
Prefiere tecnologías que tu equipo pueda operar con confianza, especialmente para troubleshooting y migraciones en producción.
Una única base SQL gestionada suele ser más barata y simple hasta que realmente la superes.
Antes de decidir:
Usa esas medidas—no suposiciones—para elegir. Para muchos proyectos, empezar con SQL es el camino más seguro, con la opción de introducir componentes NoSQL más adelante para casos de uso muy específicos o a gran escala.
NoSQL no llegó para matar a las bases relacionales; llegó para complementarlas.
Las bases relacionales siguen dominando como sistemas de registro: finanzas, RRHH, ERP, inventarios y cualquier flujo donde la consistencia y transacciones ricas importan. NoSQL brilla donde los esquemas flexibles, el alto volumen de escrituras o las lecturas distribuidas superan a los joins complejos y las garantías ACID.
La mayoría de organizaciones acaban usando ambos, escogiendo la herramienta adecuada para cada carga.
Históricamente las relacionales escalaron verticalmente, pero los motores modernos ofrecen:
Escalar un sistema relacional puede implicar más diseño que añadir nodos a un clúster NoSQL, pero el escalado horizontal es posible con el diseño y herramientas adecuados.
"Sin esquema" realmente significa "el esquema lo impone la aplicación, no la base de datos".
Los almacenes de documentos, clave‑valor y columnas aún tienen estructura; simplemente permiten que ésta evolucione por registro. Esta flexibilidad es poderosa, pero sin contratos de datos claros y validación, conduce rápidamente a datos inconsistentes.
El rendimiento depende mucho más del modelado, los índices y los patrones de carga que de la etiqueta "SQL vs NoSQL".
Una colección NoSQL sin índices adecuados será más lenta que una tabla relacional bien optimizada para muchas consultas. Y una tabla relacional mal diseñada puede quedar por detrás de un modelo NoSQL alineado con los patrones de acceso.
Muchas bases NoSQL soportan durabilidad fuerte, cifrado, auditoría y control de acceso. A la inversa, una base relacional mal configurada puede ser insegura y frágil.
La seguridad y la fiabilidad son propiedades del producto específico, la configuración, el despliegue y la madurez operacional—no de la categoría "SQL" o "NoSQL" en abstracto.
Los equipos suelen moverse entre SQL y NoSQL por dos motivos: escalado y flexibilidad. Un producto de alto tráfico puede mantener una base relacional como sistema de registro y añadir NoSQL para lecturas a escala o nuevas funcionalidades con esquemas más flexibles.
Una migración total de golpe es arriesgada. Opciones más seguras incluyen:
Al pasar de SQL a NoSQL, es tentador replicar tablas como documentos o pares clave‑valor. Esto suele llevar a:
Diseña el nuevo esquema según los patrones de acceso, no como copia de tablas.
Un patrón común es SQL para datos autoritativos (facturación, cuentas) y NoSQL para vistas optimizadas de lectura (feeds, búsqueda, cache). Sea cual sea la mezcla, invierte en:
Así mantienes las migraciones controladas en lugar de movimientos dolorosos de sentido único.
SQL y NoSQL difieren principalmente en cuatro áreas:
Ninguna categoría es universalmente mejor. La elección correcta depende de tus requisitos reales, no de modas.
Escribe tus necesidades:\n - Estructura de datos y relaciones\n - Patrones de consulta y reporting\n - Expectativas de consistencia vs disponibilidad\n - Tráfico pico, volumen de datos y objetivos de latencia\n - Habilidades operativas y tooling disponible
Default razonable:\n - Prefiere SQL para sistemas transaccionales, analítica y datos empresariales bien estructurados.\n - Considera NoSQL para cargas con muchas escrituras, escala muy grande o datos semiestructurados/variables.
Empieza pequeño y mide:\n - Construye un slice vertical o POC.\n - Recoge métricas: latencia de consultas, throughput, tasas de error, esfuerzo operacional.\n - Itera sobre esquema, índices y particionado según uso real.
Mantén la puerta abierta a híbridos:\n - Usa varias bases si distintas partes del sistema tienen necesidades muy diferentes.\n - Documenta decisiones, compensaciones y patrones en tu base de conocimientos interna (por ejemplo en /docs/architecture/datastores).
Para profundizar, extiende este resumen con estándares internos, checklists de migración y lecturas adicionales en tu manual de ingeniería o en /blog.
SQL (relacional):
NoSQL (no relacional):
Usa una base de datos SQL cuando:
Para la mayoría de los nuevos sistemas de registro empresarial, SQL es una opción sensata por defecto.
NoSQL encaja mejor cuando:
Bases de datos SQL:
Bases de datos NoSQL:
Esto significa que el control del esquema se desplaza de la base de datos (SQL) a la aplicación (NoSQL).
Bases de datos SQL:
Muchos sistemas NoSQL:
Elige SQL cuando las lecturas desactualizadas sean peligrosas; elige NoSQL cuando una brevedad de incoherencia sea aceptable a cambio de escalabilidad y alta disponibilidad.
Las bases de datos SQL típicamente:
Las bases de datos NoSQL típicamente:
La compensación es que los clústeres NoSQL son operacionalmente más complejos, mientras que SQL puede alcanzar límites en un solo nodo antes.
Sí. La persistencia poliglota es común:
Patrones de integración comunes:
La clave es añadir cada almacenamiento adicional solo cuando resuelva un problema claro.
Para migrar de forma gradual y segura:
Evita migraciones "big‑bang"; prefiere pasos incrementales y monitorizados.
Considera:
Protótipa ambas opciones para flujos críticos y mide latencia, rendimiento y complejidad antes de decidir.
Conceptos erróneos comunes incluyen:
Evalúa productos y arquitecturas concretas en lugar de confiar en mitos por categoría.