Qué es (y qué no es) una réplica de lectura
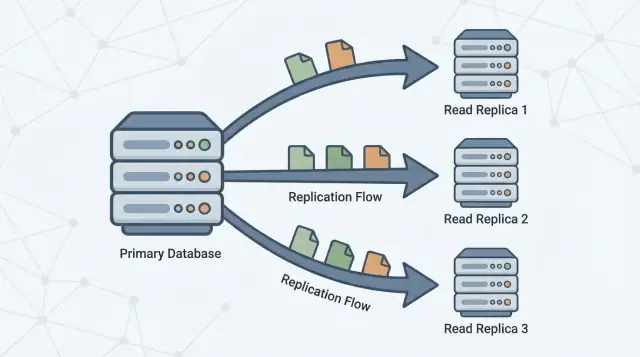
Una réplica de lectura es una copia de tu base de datos principal (a menudo llamada primaria) que se mantiene actualizada recibiendo continuamente cambios desde ella. Tu aplicación puede enviar consultas solo de lectura (como SELECT) a la réplica, mientras la primaria continúa manejando todas las escrituras (como INSERT, UPDATE y DELETE).
La promesa básica
La promesa es simple: más capacidad de lectura sin poner más presión sobre la primaria.
Si tu aplicación tiene mucho tráfico de “obtener” —páginas de inicio, páginas de producto, perfiles de usuario, dashboards— mover algunas de esas lecturas a una o varias réplicas puede liberar a la primaria para centrarse en las escrituras y en las lecturas críticas. En muchas configuraciones, esto puede hacerse con cambios mínimos en la aplicación: mantienes una base de datos como fuente de la verdad y añades réplicas como lugares adicionales para consultar.
Lo que no es una réplica de lectura
Las réplicas de lectura son útiles, pero no son un botón mágico de rendimiento. No:
- Aumentan la capacidad de escritura. Todas las escrituras siguen llegando a la primaria.
- Arreglan consultas lentas. Si una consulta es ineficiente (faltan índices, escanea tablas enormes, patrones de join malos), probablemente será lenta en las réplicas también—solo será lenta en otro sitio.
- Sustituyen un buen diseño de esquema y datos. Las réplicas no solucionan puntos calientes, filas sobredimensionadas ni una tabla “todo en uno” desbordada.
- Eliminan la necesidad de monitorizar. Las réplicas añaden partes móviles: retardo, límites de conexión y comportamiento de failover.
Expectativas para el resto de la guía
Piensa en las réplicas como una herramienta de escalado de lectura con trade-offs. El resto de este artículo explica cuándo ayudan realmente, las formas comunes en que fallan y cómo conceptos como retardo de replicación y consistencia eventual afectan lo que ven los usuarios cuando empiezas a leer desde una copia en vez de desde la primaria.
Por qué existen las réplicas de lectura
Un único servidor de base de datos primaria suele empezar sintiéndose “lo suficientemente grande”. Maneja escrituras (inserciones, actualizaciones, borrados) y también responde a todas las peticiones de lectura (SELECT) desde tu app, dashboards y herramientas internas.
A medida que el uso crece, las lecturas suelen multiplicarse más rápido que las escrituras: cada vista de página puede disparar varias consultas, las pantallas de búsqueda pueden expandirse en muchas búsquedas y las consultas tipo analítica pueden escanear muchas filas. Incluso si tu volumen de escrituras es moderado, la primaria puede convertirse en un cuello de botella porque tiene que hacer dos trabajos a la vez: aceptar cambios de forma segura y rápida, y servir una pila creciente de tráfico de lectura con baja latencia.
Separar lecturas y escrituras
Las réplicas de lectura existen para dividir esa carga. La primaria se mantiene enfocada en procesar escrituras y en mantener la “fuente de la verdad”, mientras una o más réplicas manejan consultas solo de lectura. Cuando tu aplicación puede encaminar algunas consultas a réplicas, reduces la presión de CPU, memoria y I/O en la primaria. Eso típicamente mejora la capacidad de respuesta general y deja más margen para ráfagas de escritura.
Replicación en una frase
La replicación es el mecanismo que mantiene las réplicas actualizadas copiando cambios desde la primaria a otros servidores. La primaria registra cambios y las réplicas aplican esos cambios para poder responder consultas usando datos casi iguales.
Este patrón es común en muchos sistemas de bases de datos y servicios gestionados (por ejemplo PostgreSQL, MySQL y variantes en la nube). La implementación exacta difiere, pero el objetivo es el mismo: aumentar la capacidad de lectura sin forzar a la primaria a escalar verticalmente para siempre.
Cómo funciona la replicación (modelo mental simple)
Piensa en una base de datos primaria como la “fuente de la verdad”. Acepta cada escritura —crear pedidos, actualizar perfiles, registrar pagos— y asigna a esos cambios un orden definido.
Una o más réplicas de lectura entonces siguen a la primaria, copiando esos cambios para poder responder consultas de lectura (como “mostrar mi historial de pedidos”) sin poner más carga sobre la primaria.
El flujo básico
- La primaria acepta escrituras y las registra en un log durable (el nombre exacto varía según la base de datos).
- Las réplicas transmiten o obtienen esas entradas del log desde la primaria.
- Las réplicas reproducen los mismos cambios en el mismo orden, poniéndose al día gradualmente.
Las lecturas pueden servirse desde réplicas, pero las escrituras siguen yendo a la primaria.
Replicación síncrona vs asíncrona (a alto nivel)
La replicación puede ocurrir en dos modos generales:
- Síncrona: la primaria espera a que una réplica (o un quórum) confirme que recibió el cambio antes de considerar la escritura “confirmada”. Esto reduce lecturas obsoletas, pero puede incrementar la latencia de escritura y hacerlas más sensibles a problemas de replica/red.
- Asíncrona: la primaria confirma la escritura inmediatamente y las réplicas se van poniendo al día después. Esto mantiene las escrituras rápidas y resistentes, pero las réplicas pueden quedar temporalmente atrás.
Retardo de replicación y “consistencia eventual”
Esa demora —que las réplicas queden atrás respecto a la primaria— se llama retardo de replicación. No es automáticamente un fallo; suele ser el trade-off normal que aceptas para escalar lecturas.
Para los usuarios, el retardo aparece como consistencia eventual: después de que cambias algo, el sistema se volverá consistente en todas partes, pero no necesariamente de inmediato.
Ejemplo: actualizas tu dirección de correo y refrescas tu perfil. Si la página se sirve desde una réplica que está unos segundos atrasada, puedes ver brevemente el correo antiguo —hasta que la réplica aplique la actualización y se “ponga al día”.
Cuándo las réplicas de lectura realmente ayudan
Las réplicas ayudan cuando tu base de datos primaria está sana para escrituras pero se ve desbordada al servir tráfico de lectura. Son más efectivas cuando puedes descargar una parte significativa de la carga de SELECT sin cambiar cómo escribes datos.
Señales de que estás limitado por lecturas (no por escrituras)
Busca patrones como:
- CPU alta en la primaria durante picos de tráfico, mientras el rendimiento de escrituras no sube de forma inusual
- Una proporción muy alta de consultas
SELECT comparada con INSERT/UPDATE/DELETE
- Consultas de lectura que se vuelven más lentas en picos aunque las escrituras se mantengan estables
- Saturación del pool de conexiones impulsada por endpoints de solo lectura (páginas de producto, feeds, resultados de búsqueda)
Cómo confirmar que las lecturas son el problema (métricas a revisar)
Antes de añadir réplicas, valida con señales concretas:
- CPU vs I/O: ¿La CPU de la primaria está al máximo cuando la latencia de lectura sube? ¿O es el I/O de disco el cuello de botella?
- Mezcla de consultas: Porcentaje de tiempo invertido en
SELECT (desde el slow query log/APM).
- Latencia p95/p99 de lecturas: Monitorea endpoints de lectura y la latencia de consultas por separado.
- Tasa de aciertos en buffer/cache: Una tasa baja puede significar que las lecturas fuerzan acceso a disco.
- Consultas top por tiempo total: Una consulta costosa puede dominar la “carga de lectura”.
No te saltes las soluciones más baratas
A menudo, el primer movimiento correcto es optimizar: añadir el índice correcto, reescribir una consulta, reducir llamadas N+1 o cachear lecturas calientes. Estos cambios pueden ser más rápidos y baratos que operar réplicas.
Lista rápida: réplicas vs optimización
Elige réplicas si:
- La mayor parte de la carga es tráfico de lectura y las lecturas ya están razonablemente optimizadas
- Puedes tolerar lecturas ocasionalmente desactualizadas para las consultas descargadas
- Necesitas capacidad adicional rápidamente sin cambios de esquema/consulta riesgosos
Elige optimizar primero si:
- Unas pocas consultas dominan el tiempo total de lectura
- Faltan índices u hay joins ineficientes evidentes
- Las lecturas son lentas incluso con bajo tráfico (señal de problemas en el diseño de consultas)
Casos de uso donde encajan mejor
Las réplicas son más valiosas cuando la primaria está ocupada manejando escrituras (checkout, registros, actualizaciones), pero una gran parte del tráfico es de solo lectura. En una arquitectura primario–replica, enviar las consultas adecuadas a réplicas mejora el rendimiento sin cambiar funcionalidades de la app.
1) Dashboards y analítica que no deben ralentizar transacciones
Los dashboards suelen ejecutar consultas largas: agrupaciones, filtros en rangos de fechas amplios o joins entre varias tablas. Esas consultas pueden competir con el trabajo transaccional por CPU, memoria y caché.
Un lugar apropiado para estas consultas es una réplica de lectura:
- Cargas de informes internas
- Dashboards de administración
- Vistas de métricas “diarias/semanales”
Mantienes la primaria enfocada en transacciones rápidas y predecibles mientras las lecturas analíticas escalan independientemente.
2) Páginas de búsqueda y navegación con alto volumen de lecturas
Navegación de catálogo, perfiles de usuario y feeds de contenido pueden generar mucho tráfico de lecturas similares. Cuando la presión de escalado de lectura es el cuello de botella, las réplicas pueden absorber tráfico y reducir picos de latencia.
Esto es especialmente efectivo cuando las lecturas tienen muchos misses de caché (consultas muy variadas) o no puedes depender solo de un caché de aplicación.
3) Jobs en segundo plano que escanean muchos datos
Exportaciones, backfills, recomputar resúmenes y trabajos “encontrar todo lo que coincide con X” pueden golpear fuerte la primaria. Ejecutar esos escaneos contra una réplica suele ser más seguro.
Asegúrate de que el job tolere consistencia eventual: con retardo de replicación puede no ver las actualizaciones más recientes.
4) Lecturas multi-región para menor latencia (con advertencias sobre desactualización)
Si tienes usuarios globales, colocar réplicas más cerca de ellos reduce el RTT. El trade-off es más exposición a lecturas desactualizadas durante retardo o problemas de red, por lo que es mejor para páginas donde “casi actualizado” es aceptable (navegación, recomendaciones, contenido público).
Dónde las réplicas pueden salir mal
Comienza con Go y Postgres
Genera un backend Go + Postgres y empieza a definir desde temprano las rutas de lectura y escritura.
Las réplicas son excelentes cuando “lo suficientemente cercano” es aceptable. Fallan cuando tu producto asume silenciosamente que cada lectura refleja la última escritura.
El síntoma clásico: “Acabo de actualizarlo, ¿por qué no cambió?”
Un usuario edita su perfil, envía un formulario o cambia una configuración —y la siguiente carga de página toma datos de una réplica que está unos segundos atrás. La actualización se confirmó, pero el usuario ve datos antiguos y vuelve a intentar, envía doble o pierde confianza.
Esto es especialmente doloroso en flujos donde el usuario espera confirmación inmediata: cambiar un correo, alternar preferencias, subir un documento o publicar un comentario y luego ser redirigido.
Pantallas que deben ser “siempre actuales” (no juegues aquí)
Algunas lecturas no toleran estar desactualizadas, ni siquiera brevemente:
- Carritos de compra y totales de checkout
- Saldos de billetera, puntos de fidelidad, conteos de inventario
- Pantallas de “¿mi pago se procesó?”
Si una réplica está atrasada, puedes mostrar un total de carrito incorrecto, vender de más o mostrar un saldo antiguo. Aunque el sistema luego se corrija, la experiencia de usuario (y el volumen de soporte) sufre.
Herramientas de administración y operaciones necesitan la verdad más reciente
Los dashboards internos suelen impulsar decisiones reales: revisión de fraude, soporte al cliente, cumplimiento de pedidos, moderación e investigación de incidentes. Si una herramienta admin lee desde réplicas, corres el riesgo de actuar sobre datos incompletos —por ejemplo, reembolsar un pedido ya reembolsado o perder el último estado.
Solución práctica: enrutar “read-your-writes” a la primaria
Un patrón común es el enrutamiento condicional:
- Tras una escritura de un usuario, envía sus lecturas de confirmación a la primaria durante una ventana corta (segundos a minutos).
- Mantén las lecturas de fondo, anónimas o no críticas en réplicas.
Esto preserva los beneficios de las réplicas sin convertir la consistencia en una conjetura.
Entender el retardo de replicación y las lecturas desactualizadas
El retardo de replicación es la demora entre que una escritura se confirma en la primaria y cuando ese mismo cambio se hace visible en una réplica. Si tu app lee desde una réplica durante esa demora, puede devolver resultados “desactualizados” —datos que eran verdaderos hace un momento pero ya no lo son.
Por qué ocurre el retardo
El retardo es normal y suele aumentar bajo estrés. Causas comunes:
- Picos de carga en la primaria: muchas escrituras significan más cambios que enviar y aplicar.
- Réplica con recursos insuficientes o ocupada: la réplica no aplica cambios tan rápido como llegan (CPU, I/O de disco).
- Latencia/jitter de red: retrasos en mover la transmisión de replicación.
- Transacciones grandes / actualizaciones masivas: un único cambio grande puede tardar en serializarse, transferirse y reproducirse.
Cómo aparecen las lecturas desactualizadas en el producto
El retardo no solo afecta la “frescura”, también la corrección desde la perspectiva del usuario:
- Un usuario actualiza su perfil y al refrescar ve el valor antiguo.
- “Mensajes no leídos” o insignias de notificación fluctúan porque los conteos se calculan sobre filas ligeramente antiguas.
- Pantallas de administración/reporting no muestran los últimos pedidos, reembolsos o cambios de estado.
Empieza decidiendo qué puede tolerar cada funcionalidad:
- Añadir una ventana de tolerancia: “Los datos pueden tener hasta 30 segundos de antigüedad” es aceptable para muchos dashboards.
- Enrutar lecturas después de escritura a la primaria: tras un cambio, lee esa entidad desde la primaria por un período corto.
- Mensajería en la UI: ajustar expectativas (“Actualizando…”, “Puede tardar unos segundos en aparecer”).
- Lógica de reintento: si una lectura crítica no encuentra un registro recién escrito, reintenta contra la primaria o reintenta tras un pequeño retraso.
Qué monitorizar y cuándo alertar
Controla el retardo de réplica (tiempo/bytes detrás), la tasa de aplicación en réplicas, errores de replicación y CPU/disk I/O de las réplicas. Alerta cuando el retardo exceda tu tolerancia acordada (por ejemplo, 5s, 30s, 2m) y cuando el retardo siga creciendo con el tiempo (señal de que la réplica no podrá ponerse al día sin intervención).
Escalado de lecturas vs escalado de escrituras (trade-offs clave)
Separa informes de transacciones
Crea pantallas internas de informes sin mezclar lecturas intensivas en las rutas críticas de escritura.
Las réplicas son una herramienta para escalar lecturas: añadir más lugares para servir SELECT. No son una herramienta para escalar escrituras: aumentar cuántos INSERT/UPDATE/DELETE puede aceptar el sistema.
Escalar lecturas: en qué son buenas las réplicas
Al añadir réplicas, añades capacidad de lectura. Si tu aplicación está limitada por endpoints de solo lectura (páginas de producto, feeds, búsquedas), puedes repartir esas consultas entre varias máquinas.
Esto suele mejorar:
- Latencia de consultas bajo carga (menos contención en la primaria)
- Throughput para lecturas (más CPU/memoria/I/O disponible para
SELECT)
- Aislamiento para lecturas pesadas, como cargas de reporting, para que no interfieran con el tráfico transaccional
Escalar escrituras: lo que las réplicas no hacen
Un error común es pensar que “más réplicas = más throughput de escrituras”. En una configuración típica primario-replica, todas las escrituras siguen yendo a la primaria. De hecho, más réplicas pueden aumentar ligeramente el trabajo de la primaria, porque debe generar y enviar datos de replicación a cada réplica.
Si tu problema es throughput de escrituras, las réplicas no lo arreglan. Normalmente mirarás otras soluciones (optimización de queries/índices, batching, particionado/sharding, o cambiar el modelo de datos).
Límites de conexiones y pooling: el cuello de botella oculto
Aunque las réplicas te den más CPU para lecturas, aún puedes golpear primero los límites de conexión. Cada nodo de base de datos tiene un máximo de conexiones concurrentes, y añadir réplicas puede multiplicar los lugares a los que tu app podría conectar—sin reducir la demanda total.
Regla práctica: usa pooling de conexiones (o un pooler) y mantén intencional el número de conexiones por servicio. Si no, las réplicas pueden volverse simplemente “más bases de datos para sobrecargar”.
Coste: la capacidad no es gratis
Las réplicas añaden costes reales:
- Más nodos (gasto en cómputo)
- Más almacenamiento (cada réplica suele almacenar una copia completa)
- Más esfuerzo operativo (monitorizar lag, estrategia de backups/restore, cambios de esquema, respuesta a incidentes)
El trade-off es simple: las réplicas te compran margen para lecturas y aislamiento, pero añaden complejidad y no elevan el techo de escrituras.
Alta disponibilidad y failover: qué pueden hacer las réplicas
Las réplicas pueden mejorar la disponibilidad de lecturas: si la primaria está sobrecargada o temporalmente inaccesible, aún puedes servir algo de tráfico de solo lectura desde réplicas. Eso puede mantener páginas orientadas al cliente responsivas (para contenido que tolera cierta desactualización) y reducir el radio de daño de un incidente en la primaria.
Lo que las réplicas no proporcionan por sí solas es un plan completo de alta disponibilidad. Una réplica normalmente no está lista para aceptar escrituras automáticamente, y “existe una copia legible” es distinto a “el sistema puede aceptar escrituras de forma segura y rápida”.
Failover típicamente significa: detectar fallo de la primaria → elegir una réplica → promoverla a nueva primaria → redirigir las escrituras (y usualmente las lecturas) al nodo promovido.
Algunos servicios gestionados automatizan gran parte de esto, pero la idea central es la misma: cambias quién está autorizado a aceptar escrituras.
Riesgos clave a planificar
- Datos desactualizados en la réplica: la réplica puede estar atrasada. Si la promueves, podrías perder las escrituras más recientes que no llegaron a replicarse.
- Evitar split-brain: debes impedir que dos nodos acepten escrituras al mismo tiempo. Por eso las promociones suelen estar gobernadas por una única autoridad (un plano de control gestionado, un sistema de quórum o procedimientos operativos estrictos).
- Enrutamiento y caches: tu app necesita una forma fiable de cambiar objetivos—connection strings, DNS, proxies o un router de base de datos. Asegúrate de que el tráfico de escritura no pueda “accidentalmente” seguir yendo a la antigua primaria.
Prueba como si fuera una característica
Trata el failover como algo que practicas. Haz ejercicios en staging (y con cuidado en producción en ventanas de bajo riesgo): simula la pérdida de la primaria, mide el tiempo de recuperación, verifica el enrutamiento y confirma que tu app maneja periodos de solo lectura y reconexiones sin problemas.
Patrones prácticos de enrutamiento (split read/write)
Las réplicas solo ayudan si el tráfico realmente llega a ellas. “Split read/write” son las reglas que envían escrituras a la primaria y lecturas elegibles a réplicas—sin romper la corrección.
Patrón 1: dividir en la aplicación
El enfoque más sencillo es el enrutamiento explícito en la capa de acceso a datos:
- Todas las escrituras (
INSERT/UPDATE/DELETE, cambios de esquema) van a la primaria.
- Solo lecturas seleccionadas pueden usar una réplica.
Esto es fácil de razonar y de revertir. También es donde puedes codificar reglas de negocio como “tras checkout, siempre leer el estado del pedido desde la primaria por un tiempo”.
Algunos equipos prefieren un proxy de base de datos o un driver inteligente que entienda endpoints primario vs réplica y enrute según el tipo de consulta o la configuración de la conexión. Esto reduce cambios en la app, pero cuidado: los proxies no siempre pueden saber qué lecturas son “seguras” desde la perspectiva del producto.
Elegir qué consultas pueden ir a réplicas
Buenos candidatos:
- Analítica, cargas de reporting, dashboards
- Páginas de búsqueda/navegación donde datos ligeramente desactualizados son aceptables
- Jobs en background que reintentan y no necesitan el último valor
Evita enrutar lecturas que siguen inmediatamente a una escritura de usuario (por ejemplo, “actualizar perfil → recargar perfil”) a menos que tengas una estrategia de consistencia.
Transacciones y consistencia de sesión
Dentro de una transacción, mantén todas las lecturas en la primaria.
Fuera de transacciones, considera sesiones “read-your-writes”: después de una escritura, fija ese usuario/sesión a la primaria por un TTL corto o enruta consultas de seguimiento específicas a la primaria.
Empieza pequeño y mide
Añade una réplica, enruta un conjunto limitado de endpoints/consultas y compara antes/después:
- CPU de la primaria e IOPS de lectura
- Utilización de la réplica
- Tasa de errores y percentiles de latencia
- Incidentes relacionados con lecturas desactualizadas
Expande el enrutamiento solo cuando el impacto sea claro y seguro.
Monitorización y operaciones básicas
Despliega e itera rápidamente
Lanza tu app con hosting y despliegue, y luego itera conforme crece el tráfico.
Las réplicas no son “instalarlas y olvidarlas”. Son servidores de base de datos adicionales con sus propios límites de rendimiento, modos de fallo y tareas operativas. Un poco de disciplina de monitorización suele ser la diferencia entre “las réplicas ayudaron” y “las réplicas añadieron confusión”.
Qué vigilar (las pocas métricas que importan)
Céntrate en indicadores que expliquen síntomas visibles por usuarios:
- Retardo de réplica: cuánto está detrás la réplica respecto a la primaria (segundos, bytes o posición WAL/LSN según la base de datos). Esta es tu alerta temprana para lecturas desactualizadas.
- Errores de replicación: conexiones rotas, fallos de autenticación, disco lleno o problemas con slots de replicación. Trátalos como incidentes.
- Latencia de consultas (p50/p95) en réplicas vs primaria: las réplicas pueden estar lentas incluso cuando la primaria está bien (estado de caché distinto, hardware distinto, informes largos).
- Tasa de aciertos en caché: una réplica que falla constantemente en caché puede mostrar mayor latencia tras reinicios o cambios de tráfico.
Planificación de capacidad: ¿cuántas réplicas necesitas?
Empieza con una réplica si tu objetivo es descargar lecturas. Añade más cuando tengas una restricción clara:
- Throughput de lecturas: una réplica no puede seguir el pico de QPS o consultas analíticas pesadas.
- Aislamiento: dedica una réplica a workloads de reporting para que los dashboards no roben recursos del tráfico de usuario.
- Geografía: una réplica por región puede reducir latencia de lectura, pero aumenta la sobrecarga operativa.
Regla práctica: escala réplicas solo después de confirmar que las lecturas son el cuello de botella (no índices, consultas lentas o caching de aplicación).
Tareas operativas comunes
- Backups: decide dónde se hacen los backups. Tomarlos desde una réplica puede reducir carga en la primaria, pero verifica requisitos de consistencia y que la réplica esté sana.
- Cambios de esquema: prueba migraciones con la replicación en mente (DDL de larga duración puede aumentar el retardo). Coordina despliegues para que app y esquema sean compatibles mientras se propagan.
- Ventanas de mantenimiento: parchear o reiniciar réplicas reduce temporalmente la capacidad de lectura. Planifica rotaciones para no bajar por debajo del margen requerido.
Checklist de resolución de problemas: “las réplicas están lentas”
- Comprueba el retardo de réplica: si es alto, los usuarios pueden reintentar o ver datos obsoletos.
- Compara los slow query logs en réplica vs primaria: las consultas de reporting suelen aparecer aquí.
- Verifica CPU, memoria, disco I/O y red en el host de réplica.
- Busca contención de locks o transacciones largas en la primaria que retrasen la replicación.
- Confirma que tu enrutamiento de lecturas no está sobrecargando una sola réplica (balanceo de carga desigual).
- Valida que los índices existan en las réplicas (deben reflejar la primaria) y que las estadísticas estén actualizadas.
Alternativas y un marco simple de decisión
Las réplicas son una herramienta para escalar lecturas, pero rara vez son la primera palanca a accionar. Antes de añadir complejidad operativa, verifica si una solución más simple te da el mismo resultado.
Alternativas a probar primero
Caché puede eliminar clases enteras de lecturas de la base de datos. Para páginas mayoritariamente de lectura (detalles de producto, perfiles públicos, configuración), un cache de aplicación o un CDN puede reducir la carga drásticamente—sin introducir retardo de replicación.
Índices y optimización de consultas a menudo superan a las réplicas en el caso común: unas pocas consultas costosas consumiendo CPU. Añadir el índice adecuado, reducir columnas en SELECT, evitar N+1 y corregir joins malos puede convertir “necesitamos réplicas” en “solo necesitábamos un mejor plan”.
Vistas materializadas / pre-agregación ayudan cuando el workload es inherentemente pesado (analítica, dashboards). En lugar de re-ejecutar consultas complejas, almacenas resultados calculados y los actualizas con una cadencia.
Cuándo considerar particionado/sharding en su lugar
Si tus escrituras son el cuello de botella (filas calientes, contención de locks, límites de IOPS de escritura), las réplicas no ayudarán mucho. Ahí es cuando particionar tablas por tiempo/cliente o shardear por ID de cliente puede dispersar la carga de escrituras y reducir la contención. Es un paso arquitectónico mayor, pero aborda la restricción real.
Un marco simple para decidir
Hazte cuatro preguntas:
- ¿Cuál es el objetivo? Reducir latencia de lectura, descargar reporting o mejorar alta disponibilidad?
- ¿Qué tan frescas deben ser las lecturas? Si no puedes tolerar lecturas desactualizadas, las réplicas pueden causar problemas visibles al usuario.
- ¿Cuál es tu presupuesto? Las réplicas añaden coste de infraestructura y operaciones continuas.
- ¿Cuánta complejidad puedes absorber? Split read/write, manejar consistencia eventual y probar failover no son triviales.
Si estás prototipando un producto o lanzando un servicio rápido, ayuda incorporar estas limitaciones en la arquitectura desde el inicio. Por ejemplo, equipos que construyen sobre Koder.ai (una plataforma que genera apps React con backends en Go + PostgreSQL desde una interfaz de chat) suelen comenzar con una única primaria para simplicidad, y luego pasan a réplicas tan pronto como dashboards, feeds o reporting interno compiten con el tráfico transaccional. Un flujo de trabajo orientado a planificación facilita decidir qué endpoints pueden tolerar consistencia eventual y cuáles deben leer siempre de la primaria.
Si quieres ayuda para elegir un camino, consulta /pricing para opciones, o explora guías relacionadas en /blog.