27 ago 2025·8 min
Pools de trabajadores en Go para trabajos en segundo plano: reintentos, cancelación y apagado
Los pools de trabajadores en Go ayudan a equipos pequeños a ejecutar trabajos en segundo plano con reintentos, cancelación y apagado limpio usando patrones simples antes de añadir infraestructura pesada.
Por qué los trabajos en segundo plano se complican rápido
En un servicio pequeño en Go, el trabajo en segundo plano suele empezar con una meta simple: devolver la respuesta HTTP rápido y luego hacer lo que tarde después. Eso puede ser enviar correos, redimensionar imágenes, sincronizar con otra API, reconstruir índices de búsqueda o ejecutar informes nocturnos.
El problema es que esos trabajos son trabajo de producción real, solo que sin las protecciones que normalmente tienes al manejar solicitudes. Una goroutine lanzada desde un handler HTTP parece suficiente hasta que ocurre un deploy a mitad de tarea, una API upstream se ralentiza o la misma petición se reintenta y dispara el trabajo dos veces.
Los primeros puntos dolorosos son previsibles:
- Trabajos bloqueados: una llamada se queda colgada y los workers dejan de avanzar.
- Trabajo duplicado: los reintentos en la capa HTTP vuelven a ejecutar el mismo trabajo.
- Sin plan de apagado: el proceso sale y el trabajo se pierde o queda a medias.
- Fallos silenciosos: los errores se registran una vez (o no se registran) y desaparecen.
- Tormentas de reintentos: los trabajos que fallan se reintentan al instante y sobrecargan dependencias.
Aquí es donde un patrón pequeño y explícito como un pool de trabajadores en Go ayuda. Convierte la concurrencia en una elección (N workers), transforma “hacer esto después” en un tipo de trabajo claro y te da un punto central para manejar reintentos, timeouts y cancelación.
Ejemplo: una app SaaS necesita enviar facturas. No quieres 500 envíos simultáneos tras una importación por lotes, ni reenviar la misma factura porque la petición fue reintentada. Un pool te permite limitar el throughput y tratar “enviar factura #123” como una unidad de trabajo rastreable.
Un pool de trabajadores no es la herramienta adecuada cuando necesitas garantías duraderas entre procesos. Si los trabajos deben sobrevivir a caídas, programarse para el futuro o ser procesados por varios servicios, probablemente necesites una cola real más almacenamiento persistente para el estado del trabajo.
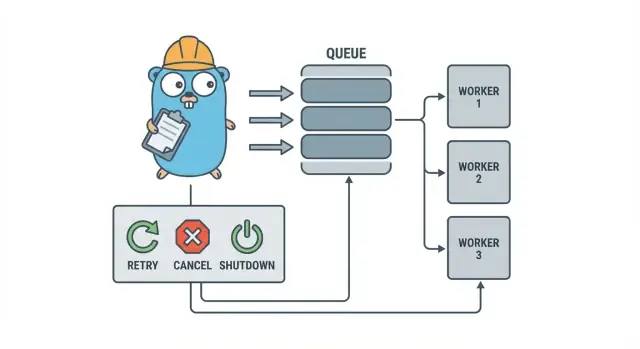
El modelo del pool explicado en lenguaje simple
Un pool de trabajadores en Go es deliberadamente aburrido: mete trabajo en una cola, un conjunto fijo de workers lo extrae y asegúrate de que todo pueda detenerse limpiamente.
Los términos básicos:
- Job: una unidad de trabajo, como “redimensionar esta imagen” o “enviar este correo de factura”.
- Cola: donde esperan los jobs.
- Worker: una goroutine que toma trabajos y los ejecuta repetidamente.
- Dispatcher: la parte que acepta trabajos y los introduce en la cola.
En muchos diseños en proceso, un channel de Go es la cola. Un canal con buffer puede contener un número limitado de trabajos antes de que los productores bloqueen. Ese bloqueo es backpressure, y a menudo es lo que evita que tu servicio acepte trabajo ilimitado y se quede sin memoria cuando el tráfico sube.
El tamaño del buffer cambia la sensación del sistema. Un buffer pequeño hace visible la presión rápido (los llamantes esperan antes). Un buffer grande suaviza picos cortos pero puede ocultar la sobrecarga hasta más tarde. No hay un número perfecto, solo uno que coincida con cuánto tiempo de espera puedes tolerar.
También eliges si el tamaño del pool es fijo o dinámico. Los pools fijos son más fáciles de razonar y mantienen el uso de recursos predecible. Autoescalar workers ayuda con carga desigual, pero añade decisiones que tendrás que mantener (cuándo escalar, cuánto y cuándo reducir).
Finalmente, “ack” en un pool en proceso normalmente solo significa “el worker terminó el job y no devolvió error.” No hay un broker externo que confirme la entrega, así que tu código define qué significa “hecho” y qué pasa cuando un trabajo falla o es cancelado.
Objetivos de diseño: reintentos, cancelación y apagado limpio
Un pool de trabajadores es simple a nivel mecánico: ejecutar un número fijo de workers, alimentarlos con trabajos y procesarlos. El valor está en el control: concurrencia predecible, manejo de fallos claro y una ruta de apagado que no deje trabajo a medias.
Tres objetivos mantienen a los equipos pequeños en calma:
- Limitar la concurrencia para que un pico no derrita la base de datos o una API externa.
- Evitar perder trabajo (o al menos saber exactamente qué se descartó y por qué).
- Que sea depurable: cada trabajo debe ser rastreable mediante logs y algunos contadores.
La mayoría de fallos son aburridos, pero aun así debes tratarlos de forma diferente:
- Errores transitorios (problemas de red, límites de tasa) que deberían reintentarse.
- Errores permanentes (entrada inválida, registro inexistente) que no deben reintentarse.
- Timeouts (una dependencia se queda colgada) que hay que cortar para que los workers no se saturen.
La cancelación no es lo mismo que “error”. Es una decisión: un usuario canceló, un deploy reemplazó tu proceso o tu servicio se está apagando. En Go, trata la cancelación como una señal de primera clase usando context cancellation, y asegúrate de que cada trabajo la compruebe antes de empezar trabajo caro y en varios puntos seguros durante la ejecución.
El apagado limpio es donde muchos pools fallan. Decide pronto qué significa “seguro” para tus trabajos: ¿terminas el trabajo en curso o paras rápido y lo vuelves a ejecutar después? Un flujo práctico es:
- Dejar de aceptar nuevos trabajos.
- Indicar a los workers que terminen después del trabajo actual (o que paren de inmediato).
- Esperar hasta un plazo, luego forzar la salida.
Si defines estas reglas temprano, los reintentos, la cancelación y el apagado se mantienen pequeños y predecibles en lugar de convertirse en un framework casero.
Paso a paso: construir un pool básico
Un pool de trabajadores es solo un grupo de goroutines extrayendo jobs de un channel y haciendo el trabajo. La parte importante es hacer lo básico predecible: cómo es un job, cómo paran los workers y cómo sabes cuándo todo el trabajo ha terminado.
Empieza con un tipo Job simple. Dale un ID (para logs), una carga útil (qué procesar), un contador de intentos (útil más adelante), timestamps y un lugar para guardar datos de contexto por trabajo.
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := &Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i < size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case <-p.ctx.Done():
return
case job, ok := <-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case <-p.ctx.Done():
return context.Canceled
case p.jobs <- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
Unas cuantas decisiones prácticas que tomarás de inmediato:
- Escoge un tamaño de cola basado en cuánto tiempo de espera puedes tolerar.
- Decide qué significa backpressure para los llamantes: bloquear, devolver un error o descartar.
- Mantén
Stop()yWait()separados para poder parar la entrada primero y luego esperar a que termine el trabajo en curso.
Añadiendo reintentos sin convertirlo en un framework
Los reintentos son útiles, pero también donde los pools se complican. Mantén el objetivo estrecho: reintenta solo cuando otra tentativa tenga una buena oportunidad de éxito y detente rápido cuando no la tenga.
Empieza por decidir qué es reintentable. Problemas temporales (fallos de red, timeouts, respuestas “intenta más tarde”) suelen merecer un reintento. Los permanentes (entrada inválida, registro faltante, denegación de permiso) no.
Una política de reintento pequeña suele ser suficiente:
- Marca errores como reintentables o no reintentables (por ejemplo, envuélvelos con un helper
Retryable(err)). - Fija un máximo de intentos (a menudo 3 a 5). Más allá de eso normalmente solo estás quemando tiempo.
- Usa backoff exponencial con jitter para que los trabajos no reintenten al mismo tiempo.
- Limita la demora (por ejemplo, nunca dormir más de 30 segundos).
- Registra los reintentos con número de intento, próxima demora y ID del job.
El backoff no necesita ser complicado. Una forma común es: delay = min(base * 2^(attempt-1), max), luego añade jitter (aleatorizar +-20%). El jitter importa porque, de lo contrario, muchos workers fallan y reintentan a la vez.
¿Dónde debe vivir la demora? Para sistemas pequeños, dormir dentro del worker está bien, pero ocupa un slot de worker. Si los reintentos son raros, eso es aceptable. Si son comunes o las demoras son largas, considera reencolar el job con un timestamp de “run after” para que los workers sigan ocupados con otros trabajos.
En el fallo final, sé explícito. Guarda el job fallido (y el último error) para revisión, registra suficiente contexto para reproducirlo o empújalo a una lista de muertos que revises regularmente. Evita las pérdidas silenciosas. Un pool que oculta fallos es peor que no tener reintentos.
Cancelación y timeouts que realmente detienen el trabajo
Build clean shutdown in Go
Create signal handling and context timeouts in minutes from a chat prompt.
Los pools solo parecen seguros cuando puedes detenerlos. La regla más simple es: pasa un context.Context por cada capa que pueda bloquear. Eso incluye la sumisión, la ejecución y la limpieza.
Una configuración práctica usa dos límites de tiempo:
- Un timeout por trabajo para que una tarea no acapare un worker para siempre.
- Un timeout de apagado para que el proceso pueda salir aunque algunos trabajos no cooperen.
Usa context de extremo a extremo
Dale a cada job su propio contexto derivado del contexto del worker. Entonces cada llamada lenta (DB, HTTP, colas, I/O) debe usar ese contexto para poder devolver control temprano.
func worker(ctx context.Context, jobs <-chan Job) {
for {
select {
case <-ctx.Done():
return
case job, ok := <-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
Si Run llama a tu BD o a una API, conecta el context en esas llamadas (por ejemplo, QueryContext, NewRequestWithContext o métodos de cliente que acepten contexto). Si lo ignoras en un lugar, la cancelación pasa a ser “a lo mejor” y suele fallar cuando más la necesitas.
Trabajo parcial y pasos “seguros para reintentar”
La cancelación puede ocurrir a mitad del trabajo, así que asume que el trabajo parcial es normal. Apunta a pasos idempotentes para que las reejecuciones no creen duplicados. Enfoques comunes: usar claves únicas para inserciones (o upserts), escribir marcadores de progreso (started/done), guardar resultados antes de continuar y comprobar ctx.Err() entre pasos.
Trata el apagado como una fecha límite: deja de aceptar nuevos trabajos, cancela los contextos de los workers y espera solo hasta el timeout de apagado para que los trabajos en vuelo terminen.
Apagado limpio: qué hacer cuando el proceso debe salir
Un apagado limpio tiene una meta: dejar de tomar nuevo trabajo, decir al trabajo en curso que pare y salir sin dejar el sistema en un estado raro.
Empieza con señales. En la mayoría de despliegues verás SIGINT localmente y SIGTERM desde el administrador de procesos o el runtime del contenedor. Usa un contexto de apagado que se cancele cuando llegue una señal y pásalo a tu pool y handlers.
Luego, deja de aceptar nuevos trabajos. No permitas que los llamantes se bloqueen para siempre intentando enviar a un canal que nadie lee. Mantén las sumisiones detrás de una función que compruebe una bandera cerrada o haga select sobre el contexto de apagado antes de enviar.
Decide qué pasa con el trabajo en cola:
- Drenar: terminar lo que ya está en cola, pero rechazar nuevas sumisiones.
- Descartar: eliminar lo que no haya empezado aún.
Drenar es más seguro para cosas como pagos y correos. Descartar está bien para tareas “agradables de tener” como recomputar una caché.
Una secuencia práctica de apagado:
- Captura SIGINT/SIGTERM y cancela un contexto compartido.
- Para las sumisiones (cierra la ruta de submit, no necesariamente el canal de trabajo).
- Deja que los workers terminen o aborten según el contexto.
- Espera a los workers con un WaitGroup.
- Aplica una fecha límite y luego sal.
El plazo importa. Por ejemplo, da a los trabajos en vuelo 10 segundos para parar. Después de eso, registra qué sigue en ejecución y sal. Eso mantiene los deploys predecibles y evita procesos atascados.
Logs y métricas simples para pools de trabajo
Add idempotency to job handlers
Ask Koder.ai to add idempotency keys and safe retries to your job handlers.
Cuando un pool falla, rara vez lo hace de forma estruendosa. Los jobs se ralentizan, los reintentos se amontonan y alguien informa que “no pasa nada”. Logs y unos pocos contadores básicos convierten eso en una historia clara.
Dale a cada job un ID estable (o génialo al enviar) e inclúyelo en cada línea de log. Mantén los logs consistentes: una línea cuando un job empieza, otra cuando termina y otra cuando falla. Si reintentas, registra el número de intento y la próxima demora.
Una forma simple de logear:
- start: job_id, worker_id, attempt, kind
- finish: job_id, worker_id, attempt, duration_ms
- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
Las métricas pueden ser mínimas y aun así valen. Controla longitud de la cola, trabajos en vuelo, totales de éxitos y fallos, y latencia de jobs (al menos media y máxima). Si la cola crece y los trabajos en vuelo están al máximo del número de workers, estás saturado. Si los submitters se bloquean al enviar al canal de jobs, el backpressure está alcanzando al llamante. No siempre es malo, pero debe ser deliberado.
Cuando “los jobs están atascados”, comprueba si el proceso sigue recibiendo trabajos, si la cola crece, si los workers están vivos y qué trabajos llevan más tiempo en ejecución. Los tiempos de ejecución largos suelen apuntar a timeouts faltantes, dependencias lentas o un bucle de reintentos que no termina.
Un ejemplo realista: una cola background para una SaaS pequeña
Imagina una SaaS pequeña donde un pedido cambia a PAID. Justo después del pago necesitas generar un PDF de la factura, mandar el correo al cliente y notificar al equipo interno. No quieres que eso bloquee la petición web. Esto encaja bien en un pool porque el trabajo es real, pero el sistema sigue siendo pequeño.
La carga del job puede ser mínima: lo suficiente para recuperar el resto desde la base de datos. El handler de la API escribe una fila como jobs(status='queued', type='send_invoice', payload, attempts=0) en la misma transacción que la actualización del pedido, luego un loop en background consulta jobs encolados y los empuja al channel del worker.
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
Cuando un worker lo recoge, el camino feliz es sencillo: cargar el pedido, generar la factura, llamar al proveedor de correo y marcar el job como hecho.
Los reintentos son donde esto se vuelve real. Si tu proveedor de correo tiene una caída temporal, no quieres 1.000 jobs fallando para siempre ni que ataquen al proveedor cada segundo. Un enfoque práctico es:
- Tratar errores de red y respuestas 5xx como reintentables.
- Usar backoff exponencial con un máximo (por ejemplo, 5s, 15s, 45s, 2m).
- Limitar intentos (por ejemplo, 10) y luego marcar el job como fallido.
- Registrar el último error para que soporte vea qué pasó.
Durante la caída, los jobs pasan de queued a in_progress y luego vuelven a queued con un tiempo de ejecución futuro. Cuando el proveedor se recupere, los workers naturalmente drenarán el backlog.
Ahora imagina un deploy. Mandas SIGTERM. El proceso debe dejar de tomar nuevo trabajo pero terminar lo que está en vuelo. Para la consulta de jobs, para de alimentar el channel y espera a los workers con una fecha límite. Los jobs que terminan se marcan como done. Los que sigan en ejecución cuando venza la fecha límite deberían marcarse de nuevo como queued (o dejarse como in_progress con un watchdog) para que se recojan después de que arranque la nueva versión.
Errores comunes y trampas
La mayoría de bugs en procesamiento background no están en la lógica del job. Vienen de errores de coordinación que solo aparecen bajo carga o durante el apagado.
Una trampa clásica es cerrar un canal desde más de un lugar. El resultado es un panic difícil de reproducir. Elige un dueño para cada canal (usualmente el productor) y que sea el único que llame a close(jobs).
Los reintentos son otra área donde las buenas intenciones causan incidentes. Si reintentas todo, reintentarás fallos permanentes también. Eso desperdicia tiempo, aumenta la carga y puede convertir un problema pequeño en un incidente. Clasifica errores y limita reintentos con una política clara.
Los duplicados ocurrirán incluso con un diseño cuidadoso. Los workers pueden caer a mitad del job, un timeout puede dispararse después de que el trabajo ya terminó o puedes reenviar durante un deploy. Si el job no es idempotente, los duplicados causan daños reales: dos facturas, dos correos de bienvenida, dos reembolsos.
Los errores que aparecen con más frecuencia:
- Cerrar el mismo channel desde múltiples goroutines.
- Reintentar fallos permanentes en vez de exponerlos.
- No tener una clave de idempotencia, así que los duplicados provocan efectos secundarios dobles.
- Colas en memoria sin límite que crecen hasta disparar la memoria.
- Ignorar
context.Context, así el trabajo sigue después de iniciado el apagado.
Las colas sin límite son especialmente engañosas. Un pico de trabajo puede acumularse discretamente en RAM. Prefiere un canal con buffer limitado y decide qué pasa cuando se llena: bloquear, descartar o devolver un error.
Lista rápida antes de desplegar
Prototype an invoice job pipeline
Generate the paid-to-invoice pipeline and background worker loop from a single spec.
Antes de poner un pool en producción, deberías poder describir el ciclo de vida del job en voz alta. Si alguien pregunta “¿dónde está este job ahora?”, la respuesta no debería ser una conjetura.
Una lista de comprobación práctica:
- Puedes nombrar cada estado y transición: queued, picked up, running, finished, failed (y qué los mueve).
- La concurrencia es un solo control (como
workerCount) y cambiarlo no requiere reescribir el código. - Los reintentos están acotados: los máximos de intentos están claros, el backoff crece y el fallo permanente va a algún sitio intencional.
- El comportamiento de apagado está probado: dejas de aceptar, permites que terminen los trabajos en vuelo y tienes un timeout duro.
- Los logs responden lo básico: job ID, número de intento, duración y motivo del error.
Haz un ensayo realista antes del lanzamiento: encola 100 jobs “send receipt email”, fuerza a 20 a fallar y reinicia el servicio a mitad de ejecución. Deberías ver que los reintentos se comportan como se espera, sin efectos secundarios duplicados y la cancelación realmente deteniendo trabajo cuando alcanza la fecha límite.
Si algún punto está poco claro, afínalo ahora. Arreglos pequeños aquí ahorran días después.
Siguientes pasos: cuándo añadir infraestructura más pesada (y cuándo no)
Un pool en proceso simple suele ser suficiente mientras el producto es joven. Si tus trabajos son “agradables de tener” (enviar correos, refrescar cachés, generar informes) y puedes volverlos a ejecutar, un worker pool mantiene el sistema fácil de razonar.
Señales de que superaste un pool en proceso
Fíjate en estos puntos de presión:
- Ejecutas múltiples instancias de la app y solo una debe recoger un job.
- Necesitas durabilidad (los jobs deben sobrevivir a fallos y deploys).
- Necesitas una auditoría: quién encoló qué, cuándo se ejecutó y el resultado exacto.
- Necesitas controles de backpressure entre servicios, no solo dentro de un proceso.
- Necesitas programación estricta o demoras largas (horas o días) con activación fiable.
Si ninguno de esos es cierto, las herramientas más pesadas pueden añadir más piezas móviles que valor.
Migrar gradualmente sin reescribir
La mejor defensa es una interfaz de job estable: un payload pequeño, un ID y un handler que devuelva un resultado claro. Así puedes cambiar el backend de la cola más tarde (de un channel en memoria a una tabla en la base de datos y después a una cola dedicada) sin cambiar la lógica de negocio.
Un paso intermedio práctico es un pequeño servicio Go que lea jobs desde PostgreSQL, los reclame con un lock y actualice el estado. Obtienes durabilidad y auditoría básica mientras mantienes la misma lógica de worker.
Si quieres prototipar rápido, Koder.ai (koder.ai) puede generar un starter Go + PostgreSQL desde un prompt, incluyendo una tabla de jobs en background y un loop de worker; sus snapshots y rollback pueden ayudar mientras ajustas reintentos y comportamiento de apagado.