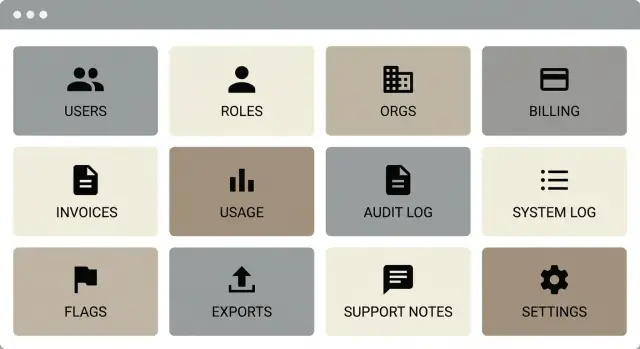
Cómo se ve en la práctica un panel de administración "80% ops"
Un panel de administración que "cubre el 80% de las operaciones" no es el que tiene más ajustes. Es el que permite a tu equipo resolver las solicitudes de soporte y operaciones más comunes en minutos, sin tener que incorporar a un ingeniero para una consulta puntual o una corrección manual.
El cambio está en separar las funcionalidades de producto de las herramientas de soporte. Las funciones de producto ayudan a los usuarios finales a hacer su trabajo. Las herramientas de soporte ayudan a tu equipo interno a responder: "¿Qué pasó? ¿Quién lo hizo? ¿Qué podemos cambiar con seguridad?" Muchos equipos lanzan muchos controles visibles para el usuario y luego se dan cuenta de que soporte todavía no puede ver lo básico como la propiedad, el estado de facturación, errores recientes o un historial limpio de cambios.
Diferentes equipos usan el panel de administración con distintos objetivos. Soporte necesita desbloquear a los usuarios y hacer cambios seguros. Finanzas necesita facturación, facturas, reembolsos y detalles fiscales. Operaciones necesita salud de la organización, tendencias de uso, controles de riesgo y exportaciones. Ingeniería necesita migas de depuración como logs y una pista de auditoría (no observabilidad completa).
Para decidir qué cuenta como el 80%, usa una comprobación de frecuencia vs impacto. La frecuencia es con qué frecuencia aparece la solicitud. El impacto es lo doloroso que es cuando no puedes resolverlo rápido (pérdida de ingresos, riesgo de churn, riesgo de cumplimiento).
Un método simple:
- Lista tus 20 tipos de ticket principales del último mes.
- Puntúa cada uno por Frecuencia (1–5) e Impacto (1–5).
- Multiplica para obtener una puntuación de prioridad.
- Construye pantallas que resuelvan las puntuaciones más altas de extremo a extremo.
Si un usuario dice: "Me cobraron pero no tengo acceso Pro", la mejor lista de verificación del panel de administración es la que lleva a soporte desde la búsqueda del usuario hasta el estado de la suscripción y la factura, con una acción y una pista de auditoría para cada cambio.
Cómo priorizar pantallas para soporte real (paso a paso)
Un panel de administración gana su lugar cuando te ayuda a cerrar tickets rápida y seguramente. La forma más fácil de elegir las pantallas adecuadas es partir de la realidad de soporte, no de lo que se siente "completo".
Priorizar paso a paso
Primero, escribe las 20 preguntas principales que ya recibes (o esperas recibir en los primeros 90 días). Usa tu bandeja de entrada, registros de chat y notas de reembolso. Si estás construyendo algo como Koder.ai, los ejemplos incluyen: "¿Por qué no puedo iniciar sesión?", "¿Quién cambió esta configuración?", "¿Por qué me cobraron dos veces?", "¿Pueden exportar mis datos?", "¿La app está caída para todos?"
Luego, agrupa esas preguntas en unos pocos temas: acceso (usuarios, organizaciones, roles), dinero (facturación, facturas, uso), datos (exportaciones, eliminaciones, retención) e incidentes (auditoría, logs, estado).
Después convierte cada tema en una pantalla, más 2–3 acciones seguras que resuelvan la mayoría de los tickets. "Seguro" significa reversible, registrado y difícil de usar mal. Ejemplos: reenviar invitación, resetear MFA, reintentar un pago, regenerar una exportación o revertir un cambio de configuración.
Ordena qué construir primero
Usa la misma lente de puntuación para cada pantalla propuesta:
- Frecuencia: con qué frecuencia soporte la abrirá
- Urgencia: lo doloroso que es cuando no puedes responder rápido
- Riesgo: lo malo que es si alguien pulsa lo incorrecto
- Esfuerzo: cuánto tarda en lanzarse una versión básica
Construye la versión más pequeña que aún resuelva tickets de extremo a extremo. Una buena prueba es si un agente de soporte puede manejar un caso real sin pedir a un ingeniero. Si no, normalmente falta un detalle (como último inicio de sesión, estado de facturación o qué cambió, cuándo y por quién).
Pantallas 1-3: Overview, Users, Organizations
Estas tres pantallas realizan la mayor parte del trabajo diario en un panel de operaciones. Deben responder dos preguntas rápido: "¿Qué está ardiendo ahora?" y "¿Quién está afectado?"
1) Overview (la página que compruebas primero)
El Overview debe ser un pequeño y fiable chequeo de pulso. Manténlo enfocado en hoy y las últimas 24 horas: nuevas inscripciones, usuarios activos, fallos de pago y cualquier pico en errores. Añade un área corta de alertas para cosas que soporte no debe pasar por alto, como fallos inusuales de inicio de sesión, errores de webhook o un aumento repentino de reembolsos.
Una buena regla: cada métrica en esta página debe llevar a un siguiente clic claro, normalmente a Users, Organizations o Logs.
2) Users (la pantalla donde vive soporte)
La pantalla de Users necesita una gran búsqueda. Soporte debe encontrar personas por email, nombre, ID de usuario y organización. Muestra el estado y señales de confianza al frente: email o teléfono verificado (si lo recoges), último inicio de sesión y si la cuenta está activa, suspendida o invitada pero sin unirse.
Mantén las acciones clave en un lugar consistente y hazlas seguras: desactivar o reactivar, resetear acceso (sesiones, MFA o contraseña según tu producto) y reenviar invitación. Añade un campo de notas internas para contexto como "solicitó cambio de factura el 9 de enero" para que los tickets no empiecen desde cero.
3) Organizations/Teams (donde suele vivir la facturación y los límites)
Esta pantalla debe mostrar membresía, plan actual, uso vs límites y el propietario. Soporte a menudo necesita resolver casos de "la persona equivocada tiene acceso" y "alcanzamos un límite", así que incluye transferencia de propiedad y gestión de membresía.
Mantén estas vistas rápidas con filtros, ordenado y búsquedas guardadas como "pago fallido", "sin ingreso en 30 días" o "por encima del límite". Las pantallas lentas convierten tickets simples en largos.
Pantalla 4: Roles y permisos (para que soporte pueda responder rápido)
Roles y permisos es donde soporte gana o pierde tiempo. Si alguien dice "no puedo hacer X", necesitas responder en minutos. Trata esta pantalla como una vista clara y legible del control de acceso basado en roles, no como una herramienta de desarrollador.
Empieza con dos tablas simples: roles (qué pueden hacer) y personas (quién tiene qué). El detalle más útil es el acceso efectivo. Muestra los roles de un usuario, cualquier rol a nivel de org y cualquier anulación en un solo lugar, con un resumen en lenguaje llano como "¿Puede gestionar facturación: Sí?".
Un editor de permisos seguro importa porque los cambios de rol pueden romper cuentas rápido. Añade una vista previa que muestre exactamente lo que cambiará antes de guardar: qué habilidades se añaden o eliminan y qué usuarios se verán afectados.
Para mantenerlo amigable para soporte, añade un solucionador de problemas "¿Por qué no pueden hacer esto?". Soporte elige una acción (como "exportar datos" o "invitar usuario"), selecciona el usuario y la pantalla devuelve el permiso faltante y dónde debería concederse (rol vs política de org). Eso evita idas y venidas largas y reduce la escalación.
Para acciones de alto riesgo, exige confirmación extra. Las comunes son cambiar roles de administrador, conceder acceso a facturación o pagos, habilitar acceso a producción o permisos de despliegue, y desactivar controles de seguridad como requisitos de MFA.
Finalmente, haz los cambios de permisos auditables. Cada edición debe registrar quién la cambió, a quién impactó, valores antes/después y la razón. En una plataforma como Koder.ai, ese historial ayuda a soporte a explicar por qué un usuario de repente puede o no exportar código fuente, desplegar o gestionar un dominio personalizado.
Pantallas 5-7: Facturación, facturas y uso
La facturación es donde se acumulan los tickets de soporte. Estas pantallas deben ser claras, rápidas y difíciles de usar mal. Si solo clavas una cosa, que sea: "¿En qué plan están, qué pagaron y por qué cambió el acceso?"
Pantalla 5: Facturación y suscripción
Muestra el plan actual, fecha de renovación, estado (activo, trial, vencido, cancelado), conteo de asientos y quién es el dueño de facturación. Pon la fuente de la verdad arriba y mantén el historial abajo (cambios de plan, cambios de asientos). Mantén los controles riesgosos (cancelar, cambiar plan, reiniciar) separados de la visualización, con confirmación y una razón obligatoria.
Pantalla 6: Facturas y pagos
Soporte necesita una lista simple de facturas con fechas, importes, impuestos y estado (pagado, abierto, fallido, reembolsado). Incluye intentos de pago y razones de fallo como tarjeta declinada o autenticación requerida. Los recibos deben ser accesibles con un clic desde la fila de la factura, pero evita permitir ediciones aquí a menos que realmente las necesites.
Pantalla 7: Uso y límites
Si cobras por uso o créditos, muestra un medidor que coincida con lo que el cliente ve. Incluye uso del periodo actual, límites, sobrecargos y cualquier cap. Añade un breve "por qué fueron bloqueados" para que soporte lo explique en lenguaje llano.
Las acciones comunes de soporte pertenecen aquí, pero manténlas controladas: aplicar un crédito único (con caducidad y nota interna), extender una prueba (con límites), actualizar impuestos o dirección de facturación (registrado), reintentar un pago fallido o añadir asientos sin cambiar el plan.
Haz que los campos de solo lectura sean visualmente distintos de los editables. Por ejemplo, muestra "Plan: Business (solo lectura)" junto a "Conteo de asientos (editable)" para que un agente no active accidentalmente un cambio de plan.
Pantallas 8-9: Audit log y system logs para depuración rápida
Plan screens before you code
Usa el modo de planificación para mapear pantallas y acciones seguras antes de generar nada.
Cuando soporte dice "algo cambió", estas dos pantallas evitan conjeturas. El audit log te dice quién hizo qué. El system log te dice qué hizo el sistema (o qué falló). Juntos reducen preguntas de seguimiento y te ayudan a dar respuestas claras rápido.
Pantalla 8: Audit log (la pista humana)
Un audit log debe responder tres preguntas de un vistazo: quién realizó la acción, qué cambió y cuándo ocurrió. Si también capturas dónde (dirección IP, dispositivo, estimación de localización), puedes detectar accesos sospechosos y explicar comportamientos extraños sin culpar al usuario.
Los filtros amigables para soporte suelen incluir actor (admin, agente de soporte, usuario final, API key), usuario y organización, ventana temporal, tipo de acción (login, cambio de rol, cambio de facturación, exportación) y objeto objetivo (cuenta, proyecto, suscripción).
Mantén cada fila legible: nombre de la acción, resumen antes/después y un ID de evento estable que pueda compartirse con ingeniería.
Pantalla 9: System log e incidentes (la pista máquina)
Los system logs son donde confirmas "falla" vs "funcionó pero se retrasó". Esta pantalla debe agrupar errores, reintentos y jobs en segundo plano, y mostrar qué pasó alrededor del mismo momento.
Muestra un conjunto conciso de campos que aceleran la depuración: marca temporal y severidad, request ID y correlation ID, nombre del servicio o trabajo (API, worker, sincronización de facturación), mensaje de error con un stack trace corto (si es seguro), contador de reintentos y estado final.
Esto reduce idas y venidas. Soporte puede responder: "Tu exportación empezó a las 10:14, se reintentó dos veces y falló por timeout. La reiniciamos y se completó a las 10:19. Request ID: abc123."
Pantalla 10: Feature flags sin caos
Los feature flags son una de las formas más rápidas en las que soporte puede ayudar a un cliente sin esperar un release completo. En un panel de administración, deben ser aburridos, claros y seguros.
Una buena vista de flags soporta toggles por usuario y por organización, además de despliegues escalonados (como 5%, 25%, 100%). También necesita contexto para que nadie adivine qué hace un flag a las 2 a.m.
Guardrails que mantienen los flags legibles
Mantén la pantalla pequeña pero estricta. Cada flag debe tener una descripción en lenguaje llano del efecto hacia el usuario, un responsable, una fecha de revisión o caducidad, reglas de alcance (usuario, org, entorno) y un historial de cambios que muestre quién lo cambió y por qué.
El flujo de trabajo de soporte importa también. Permite habilitaciones temporales con una nota corta (ejemplo: "Habilitar para Org 143 por 2 horas para confirmar solución"). Cuando termine el temporizador, debe revertirse automáticamente y dejar rastro en el audit log.
Cuándo un flag debería ser una configuración en su lugar
Los flags son para experimentos y despliegues seguros. Si es una elección a largo plazo que un cliente espera controlar, suele ser una configuración. Señales incluyen solicitudes repetidas durante onboarding o renovación, cambios en facturación/límites/cumplimiento, la necesidad de una etiqueta UI y texto de ayuda, o diferencias permanentes por equipos.
Ejemplo: si un cliente de Koder.ai informa que un nuevo paso de build falla solo en su workspace, soporte puede habilitar temporalmente un flag de compatibilidad para esa org, confirmar la causa raíz y luego o bien enviar un fix o convertir el comportamiento en una configuración real si debe mantenerse.
Pantalla 11: Exportaciones de datos que no crean riesgos nuevos
Las exportaciones parecen inocuas, pero pueden convertirse en la forma más fácil de filtrar datos. En la mayoría de paneles, exportar es la acción que puede copiar mucha información sensible en un solo clic.
Empieza con un pequeño conjunto de exportaciones de alto valor: usuarios, organizaciones, facturación y facturas, uso o créditos y actividad (eventos ligados a un usuario o workspace). Si tu producto almacena contenido generado por usuarios, considera una exportación separada para eso, con permisos más estrictos.
Da control a soporte sin complicar la UI de exportación. Un flujo sólido incluye rango de fechas, unos pocos filtros clave (estado, plan, workspace) y selección opcional de columnas para que el archivo sea legible. CSV funciona bien para trabajo rápido de soporte; JSON es mejor para análisis más profundo.
Haz las exportaciones seguras por diseño. Pon exportaciones detrás de control de acceso basado en roles (no solo “admin”), redácta secretos por defecto (API keys, tokens, datos completos de tarjeta) y enmascara PII cuando sea posible, ejecuta exportaciones como jobs en segundo plano con estado claro (en cola, ejecutando, listo, fallado), establece una ventana de expiración de descarga y limita o capea exportes enormes a menos que una rol superior lo apruebe.
También trata la exportación como un evento auditable. Registra quién exportó, qué exportó (tipo, filtros, rango de fechas, columnas) y dónde se entregó.
Ejemplo: un cliente disputa un cargo. Soporte exporta facturas y uso de los últimos 30 días para esa organización, con solo las columnas necesarias (id de factura, importe, periodo, estado de pago). El audit log captura los detalles de la exportación y el archivo se entrega al terminar el job, sin exponer detalles del método de pago.
Pantalla 12: Workspace de soporte (notas y acciones seguras)
Go from chat to deployment
Genera la app, exporta el código fuente y despliega cuando estés listo.
Un buen workspace de soporte evita que los tickets reboten entre personas. Debe responder una pregunta rápido: "¿Qué le pasó a este cliente y qué ya intentamos?"
Qué necesita mostrar esta pantalla
Empieza con una línea de tiempo del cliente que mezcle eventos del sistema y contexto humano. Notas internas (no visibles para el cliente), etiquetas (para enrutamiento como "facturación", "login", "bug") y un feed de actividad evitan trabajo repetido. Cada acción de administración debe aparecer en la misma línea de tiempo con quién la hizo, cuándo y valores antes/después.
Mantén las acciones seguras y aburridas. Da herramientas a soporte para desbloquear usuarios sin convertirlos en desarrolladores: bloquear o desbloquear una cuenta (con razón obligatoria), invalidar sesiones activas (forzar re-login), reenviar verificación o email de restablecimiento de contraseña, disparar un job de "recalcular acceso" o "refrescar estado de suscripción", o añadir una nota de retención temporal (ejemplo: "no reembolsar hasta revisar").
Si permites "login como usuario" o cualquier tipo de acceso admin a la cuenta del usuario, trátalo como una operación privilegiada. Requiere consentimiento explícito del usuario, regístralo y deja el inicio/parada de sesión en la pista de auditoría.
Plantillas de respuesta que reducen escalaciones
Añade plantillas cortas que recuerden a soporte qué recoger antes de escalar: el mensaje de error exacto, marca temporal/zona horaria, cuenta u organización afectada, pasos realizados y qué acción ya se intentó en el admin.
Ejemplo: un cliente dice que le cobraron dos veces. Soporte abre el workspace, ve una nota de que se hizo un reset de sesión antes, comprueba el estado de facturación y luego registra una nueva nota con los IDs de factura, la confirmación del cliente y la acción de reembolso tomada. El siguiente agente lo ve de inmediato y no repite los mismos pasos.
Errores comunes que hacen que los paneles de administración sean difíciles de operar
La mayoría de los paneles fallan por razones aburridas. No porque el equipo no haya puesto una función bonita, sino porque lo básico hace que el soporte diario sea lento, arriesgado o confuso.
Los errores que más a menudo convierten las pantallas en un sumidero de tiempo:
- Lanzar muchas vistas antes de poder hacer las correcciones comunes. Diez pantallas impresiones, pero soporte aún no puede resetear acceso, reenviar una invitación o corregir una configuración de org.
- No tener un historial claro de cambios. Cuando un usuario dice "mi cuenta fue deshabilitada", necesitas responder quién lo hizo, cuándo y qué más cambió alrededor del mismo momento.
- Permisos demasiado vagos o demasiado estrictos. Si los roles de soporte están bloqueados para acciones seguras, los tickets se acumulan. Si tienen demasiado poder, un clic equivocado puede convertirse en un incidente.
- Búsqueda y filtros débiles. Si no puedes encontrar a un usuario por email, filtrar por estado o acotar resultados por fecha, cada ticket se convierte en una búsqueda manual.
- Acciones peligrosas colocadas junto a flujos rutinarios. Eliminar, reembolsar, deshabilitar o rotar claves nunca deberían estar al lado de "Guardar" sin fricción adicional y etiquetado claro.
Un ejemplo simple: soporte necesita ayudar a un cliente que no puede iniciar sesión tras un cambio de facturación. Sin búsqueda, no encuentran la cuenta rápido. Sin un audit log, no pueden confirmar qué cambió. Sin un control de acceso basado en roles adecuado, o no pueden arreglarlo o pueden hacer demasiado.
Si construyes sobre una plataforma como Koder.ai, trata la seguridad como una característica de producto: haz que el camino más seguro sea el más fácil y que el camino riesgoso sea lento y ruidoso.
Lista rápida antes de lanzar el panel de administración
Get the Users screen right
Genera una pantalla de Usuarios amigable para soporte con búsqueda, estado y acciones seguras.
Antes de decir "listo", haz una comprobación de realidad. Las mejores pantallas son las que soporte puede usar bajo presión, con poco contexto y sin miedo a romper cosas.
Empieza por la velocidad. Si un agente de soporte no puede localizar a un usuario en menos de 10 segundos (por email, ID o org), los tickets se acumularán. Haz la caja de búsqueda visible en la primera vista del admin y muestra los campos que soporte necesita más: estado, último inicio de sesión, org, plan.
Luego, verifica si la facturación es respondible en un vistazo. Soporte debe ver plan actual, estado de facturación, último resultado de pago y próxima fecha de renovación en la misma página que el cliente. Si tienen que abrir tres pestañas, suceden errores.
Lista previa al envío:
- ¿Puede soporte localizar rápidamente a un usuario y confirmar que es la cuenta correcta (ID, org, estado)?
- ¿Pueden ver estado de facturación y el último pago exitoso o fallido sin cambiar de pantalla?
- ¿Pueden responder "¿quién cambió esto?" usando un audit log con actor, hora y detalles antes/después?
- ¿Están las exportaciones limitadas por control de acceso basado en roles y se registra cada solicitud de exportación?
- ¿Pueden los feature flags revertirse de forma segura, con un historial claro de cambios?
Trata cada acción riesgosa como una herramienta potente. Ponla detrás de los permisos correctos, añade un paso claro de confirmación y regístrala. Si construyes estas pantallas en una herramienta como Koder.ai, incorpora estas comprobaciones en tu primera versión para no tener que meter seguridad después.
Ejemplo: resolver un ticket real usando estas pantallas
Un cliente escribe: "Cambié de plan y ahora no puedo iniciar sesión." Aquí es donde las buenas pantallas ahorran tiempo, porque soporte puede seguir el mismo camino cada vez y evitar conjeturas.
Empieza con las comprobaciones que explican la mayoría de los bloqueos: identidad, membresía, estado de facturación y luego permisos. Una causa común es un usuario que sigue activo, pero su organización fue movida a otro plan, hay un pago vencido o un rol cambió durante el upgrade.
Un orden práctico a seguir:
- Users: busca al usuario por email, confirma que está activo y revisa último inicio de sesión y cambios recientes.
- Organizations: abre la org del usuario, confirma la membresía y verifica el estado y plan actual.
- Billing and invoices: busca un pago fallido, una factura vencida o un cambio de plan que haya activado una regla de acceso.
- Roles and permissions: confirma que el usuario sigue teniendo un rol que permite iniciar sesión y el acceso correcto a la org.
- Audit log y system logs: confirma qué pasó (cambio de plan, edición de rol) y por qué falló el inicio de sesión ("cuenta deshabilitada" vs "permiso denegado").
Si todo parece correcto, revisa feature flags. Un flag puede haber activado un nuevo método de autenticación solo para algunas orgs o deshabilitado el login legacy para un tier. Los logs junto con el estado de flags normalmente indican si es un bug o una configuración.
Antes de cerrar el ticket, escribe notas claras de soporte para que el siguiente agente no repita el trabajo:
- Qué viste (plan, estado de factura, rol)
- Qué cambiaste (si algo) y cuándo
- El error exacto de los logs
- Impacto en el usuario (quién está bloqueado, desde cuándo)
Escala a ingeniería solo después de adjuntar contexto útil: ID de usuario, ID de org, marcas temporales, entradas de auditoría relevantes y el estado de flags en el momento del fallo.
Próximos pasos: lanza el v1, mide y luego expande
Un buen primer lanzamiento no es "todas las pantallas". Es el conjunto más pequeño que permite a soporte responder la mayoría de los tickets sin pedir ayuda a ingeniería. Lanza, observa qué ocurre y añade solo lo que se gane su lugar.
Para v1, elige las seis pantallas que desbloquean las solicitudes más comunes: Overview (estado + cuentas clave), Users, Organizations, Roles y permissions (RBAC), Billing y uso, y Logs (audit + system). Si soporte puede identificar a un cliente, confirmar acceso, entender uso y ver qué cambió, cubrirás una porción sorprendente del trabajo diario.
Después de v1 en uso, elige el siguiente conjunto basado en volumen de soporte medido. Eso normalmente significa detalles de factura/pago, exportaciones de datos, feature flags, un workspace de soporte (notas y acciones seguras) y cualquier configuración específica del producto que impulse tickets de “por favor cámbialo por mí”.
Mide con señales sencillas y revísalas semanalmente: categorías top de tickets por cuenta, tiempo hasta la primera respuesta significativa, tiempo hasta resolución, cuántas veces soporte escala a ingeniería y qué acciones de admin se usan más.
Escribe runbooks cortos para las 10 acciones principales (2–5 pasos cada uno). Incluye cómo se ve lo "bueno", qué podría romperse y cuándo detenerse y escalar.
Finalmente, planifica rollback y versionado de cambios de configuración. Cualquier switch que afecte a clientes (permisos, flags, ajustes de facturación) debe tener notas de cambio, quién lo cambió y una forma de revertir rápidamente.
Si quieres construir rápido, Koder.ai (koder.ai) es una opción para generar pantallas de administración desde chat y luego iterar con planning mode y snapshots para que los cambios riesgosos sean más fáciles de revertir.