Un Transformer es una forma de ayudar a las máquinas a entender secuencias —cosas donde el orden y el contexto importan, como oraciones, código o una serie de búsquedas. En lugar de leer un token a la vez y depender de una memoria frágil, los Transformers miran toda la secuencia y deciden a qué prestar atención al interpretar cada parte.
Ese cambio sencillo resultó ser muy importante. Es una razón clave por la que los modelos de lenguaje grandes (LLMs) modernos pueden mantener contexto, seguir instrucciones, escribir párrafos coherentes y generar código que referencia funciones y variables anteriores.
Si has usado un chatbot, una función de “resumir esto”, búsqueda semántica o un asistente de código, has interactuado con sistemas basados en Transformer. El mismo esquema central soporta:
- Herramientas de chat y soporte que rastrean lo que dijiste antes
- Sistemas de búsqueda y recomendación que emparejan significado, no solo palabras clave
- Resúmenes que pueden ponderar qué es central versus detalle secundario
- Herramientas de código que conectan definiciones, usos e intenciones entre archivos
Qué aprenderás en este artículo
Desglosaremos las partes clave—autoatención, atención multi-cabeza, codificación posicional y el bloque Transformer básico—y explicaremos por qué este diseño escala tan bien cuando los modelos crecen.
También tocaremos variantes modernas que mantienen la idea central pero la ajustan para velocidad, coste o ventanas de contexto más largas.
Qué esperar (y qué no)
Esta es una guía de alto nivel con explicaciones en lenguaje llano y matemáticas mínimas. El objetivo es construir intuición: qué hacen las piezas, por qué funcionan juntas y cómo eso se traduce en capacidades reales de producto.
Noam Shazeer es un investigador e ingeniero de IA conocido por ser uno de los coautores del artículo de 2017 “Attention Is All You Need.” Ese trabajo introdujo la arquitectura Transformer, que más tarde se convirtió en la base de muchos modelos de lenguaje grandes (LLMs). El trabajo de Shazeer forma parte de un esfuerzo de equipo: el Transformer fue creado por un grupo de investigadores en Google, y es importante reconocerlo así.
Qué cambió el artículo de 2017
Antes del Transformer, muchos sistemas de PLN dependían de modelos recurrentes que procesaban texto paso a paso. La propuesta del Transformer mostró que se podían modelar secuencias efectivamente sin recurrencia usando la atención como mecanismo principal para combinar información a lo largo de una oración.
Ese cambio importó porque facilitó paralelizar el entrenamiento (puedes procesar muchos tokens a la vez) y abrió la puerta a escalar modelos y conjuntos de datos de una forma que rápidamente se volvió práctica para productos reales.
De idea de investigación a bloque productivo
La contribución de Shazeer—junto con la de los otros autores—no quedó confinada a benchmarks académicos. El Transformer se volvió un módulo reutilizable que los equipos pudieron adaptar: intercambiar componentes, cambiar el tamaño, ajustarlo para tareas y, más tarde, preentrenarlo a escala.
Así es como viajan muchas innovaciones: un artículo introduce una receta limpia y general; los ingenieros la refinan; las empresas la operacionalizan; y eventualmente se convierte en la elección por defecto para construir funciones de lenguaje.
Mantener el crédito preciso
Es correcto decir que Shazeer fue un colaborador clave y coautor del artículo del Transformer. No es correcto presentarlo como el único inventor. El impacto viene del diseño colectivo—y de las muchas mejoras posteriores que la comunidad construyó sobre ese plano original.
Qué vino antes: RNNs, LSTMs y sus límites
Antes de los Transformers, muchos problemas de secuencia (traducción, habla, generación de texto) estaban dominados por Redes Neuronales Recurrentes (RNNs) y luego LSTMs (Long Short-Term Memory). La idea era simple: leer texto un token a la vez, mantener una “memoria” (estado oculto) y usar ese estado para predecir lo que sigue.
Una imagen rápida de cómo funcionaban
Una RNN procesa una oración como una cadena. Cada paso actualiza el estado oculto según la palabra actual y el estado anterior. Las LSTMs mejoraron esto añadiendo puertas que deciden qué mantener, olvidar o sacar —facilitando retener señales útiles por más tiempo.
Por qué eran difíciles las dependencias a largo plazo
En la práctica, la memoria secuencial tiene un cuello de botella: mucha información debe comprimirse en un único estado conforme la oración se alarga. Incluso con LSTMs, las señales de palabras muy anteriores pueden desvanecerse o ser sobrescritas.
Esto hacía difícil aprender relaciones como enlazar un pronombre con el sustantivo correcto muchas palabras atrás o mantener el tema a lo largo de varias cláusulas.
Retos de entrenamiento y escalado
RNNs y LSTMs también son lentos de entrenar porque no pueden paralelizar completamente en el tiempo. Puedes agrupar por lotes diferentes oraciones, pero dentro de una misma oración, el paso 50 depende del 49, que depende del 48, y así sucesivamente.
Ese cálculo paso a paso se vuelve una limitación seria cuando quieres modelos más grandes, más datos y experimentación más rápida.
La motivación para un enfoque más paralelizable
Los investigadores necesitaban un diseño que pudiera relacionar palabras entre sí sin marchar estrictamente de izquierda a derecha durante el entrenamiento: una forma de modelar relaciones de largo alcance directamente y aprovechar mejor el hardware moderno. Esta presión preparó el terreno para el enfoque centrado en atención introducido en Attention Is All You Need.
Atención, explicada sin matemáticas
La atención es la forma que tiene el modelo de preguntarse: “¿A qué otras palabras debo mirar ahora mismo para entender esta palabra?” En lugar de leer una oración estrictamente de izquierda a derecha y confiar en que la memoria mantenga todo, la atención permite al modelo mirar las partes más relevantes de la oración cuando las necesita.
La idea de “buscar y recuperar”
Un modelo mental útil es un pequeño motor de búsqueda dentro de la oración.
- Query: lo que la palabra actual está buscando (la pregunta)
- Keys: lo que cada otra palabra ofrece (etiquetas en posibles coincidencias)
- Values: la información real a sacar si hay coincidencia (el contenido)
Entonces el modelo forma una query para la posición actual, la compara con las keys de todas las posiciones y recupera una mezcla de values.
Puntuaciones de relevancia → pesos de atención
Esas comparaciones producen puntuaciones de relevancia: señales de “qué tan relacionado está esto”. El modelo las convierte en pesos de atención, que son proporciones que suman 1.
Si una palabra es muy relevante, recibe una mayor parte del foco del modelo. Si varias palabras importan, la atención puede repartirse entre ellas.
Un ejemplo simple (pronombres y gramática)
Tomemos: “María le dijo a Jenna que ella llamaría más tarde.”
Para interpretar ella, el modelo debe mirar candidatos como “María” y “Jenna”. La atención asigna mayor peso al nombre que mejor encaje en el contexto.
O considera: “Las llaves del armario están perdidas.” La atención ayuda a enlazar “están” con “llaves” (el sujeto verdadero), no con “armario”, aunque “armario” esté más cerca. Ese es el beneficio central: la atención enlaza significado a distancia, cuando se necesita.
Autoatención: el mecanismo central
La autoatención es la idea de que cada token en una secuencia puede mirar otros tokens de esa misma secuencia para decidir qué importa ahora mismo. En lugar de procesar palabras estrictamente de izquierda a derecha (como los modelos recurrentes antiguos), el Transformer permite que cada token reúna pistas desde cualquier parte de la entrada.
Tokens atendiendo a tokens
Imagina la oración: “Vertí el agua en la taza porque estaba vacía.” La palabra “estaba” debería conectarse con “taza”, no con “agua”. Con autoatención, el token para “estaba” asigna mayor importancia a tokens que ayudan a resolver su significado (“taza”, “vacía”) y menor importancia a los irrelevantes.
Cómo se construye el contexto
Tras la autoatención, cada token deja de ser solo sí mismo. Se convierte en una versión consciente del contexto: una mezcla ponderada de información de otros tokens. Puedes pensar que cada token crea un resumen personalizado de toda la oración, afinado para lo que necesita.
En la práctica, esto significa que la representación de “taza” puede llevar señales de “vertí”, “agua” y “vacía”, mientras que “vacía” puede incorporar lo que describe.
Por qué el entrenamiento puede ser paralelo
Porque cada token puede calcular su atención sobre la secuencia completa al mismo tiempo, el entrenamiento no tiene que esperar a que se procesen tokens previos paso a paso. Este procesamiento paralelo es una de las razones principales por las que los Transformers entrenan eficazmente en grandes conjuntos de datos y escalan a modelos enormes.
Por qué es potente para relaciones a largo plazo
La autoatención facilita conectar partes distantes del texto. Un token puede enfocarse directamente en una palabra relevante muy lejos, sin pasar información por una larga cadena de pasos intermedios.
Ese camino directo ayuda en tareas como correferencia (“ella”, “ello”, “ellos”), mantener el tema a través de párrafos y manejar instrucciones que dependen de detalles anteriores.
Atención multi-cabeza: muchas miradas a la misma oración
Planifica antes de programar
Esboza el flujo de trabajo en el modo de planificación antes de generar código.
Un único mecanismo de atención es poderoso, pero aún se siente como entender una conversación con una sola cámara. Las oraciones a menudo contienen varias relaciones a la vez: quién hizo qué, a qué se refiere “ello”, qué palabras marcan el tono y cuál es el tema.
Por qué una sola vista de atención no basta
Cuando lees “El trofeo no cabía en la maleta porque era demasiado pequeño”, quizá necesites rastrear varias pistas a la vez (gramática, significado y sentido común). Una sola cabeza de atención puede centrarse en el sustantivo más cercano; otra puede usar la frase verbal para decidir a qué refiere “era”.
Qué hacen múltiples cabezas
La atención multi-cabeza ejecuta varias atenciones en paralelo. Cada “cabeza” tiende a mirar la oración a través de una lente distinta—frecuentemente descritas como subespacios distintos. En la práctica, eso permite que las cabezas se especialicen en patrones como:
- Sintaxis local (por ejemplo, adjetivo → sustantivo)
- Enlaces de largo alcance (por ejemplo, sujeto ↔ verbo a través de una cláusula)
- Correferencia (por ejemplo, pronombre → entidad)
- Señales temáticas (palabras que marcan el sujeto o la polaridad)
Cómo se combinan las cabezas
Después de que cada cabeza produzca sus propias ideas, el modelo no elige solo una. Concatena las salidas de las cabezas (apilándolas lado a lado) y luego las proyecta de vuelta al espacio de trabajo principal del modelo con una capa lineal aprendida.
Piensa en ello como fusionar varias notas parciales en un resumen limpio que la siguiente capa pueda usar. El resultado es una representación que puede capturar muchas relaciones a la vez—una de las razones por las que los Transformers funcionan tan bien a escala.
Codificación posicional: enseñar el orden de las palabras al modelo
La autoatención es excelente para detectar relaciones—pero por sí sola no sabe quién vino primero. Si desordenas las palabras de una oración, una capa de autoatención simple puede tratar la versión mezclada como igualmente válida, porque compara tokens sin un sentido incorporado de posición.
La codificación posicional soluciona esto inyectando información de “¿dónde estoy en la secuencia?” en las representaciones de los tokens. Una vez que la posición está adjunta, la atención puede aprender patrones como “la palabra justo después de no importa mucho” o “el sujeto suele aparecer antes del verbo” sin tener que inferir el orden desde cero.
Cómo añaden orden las codificaciones posicionales
La idea central es simple: cada embedding de token se combina con una señal de posición antes de entrar al bloque Transformer. Esa señal de posición puede entenderse como un conjunto extra de características que etiquetan un token como 1.º, 2.º, 3.º… en la entrada.
Hay varios enfoques comunes:
- Posiciones absolutas (fijas): los Transformers clásicos usaban patrones sinusoidales deterministas. No añaden parámetros nuevos y pueden generalizar a longitudes más allá de las vistas en entrenamiento (hasta cierto punto).
- Posiciones absolutas aprendidas: el modelo aprende un vector para “posición 1”, “posición 2”, etc. Esto puede funcionar muy bien, pero a menudo ata el modelo a una ventana máxima de contexto con la que fue entrenado.
- Posiciones relativas: en vez de codificar “este es el token 57”, el modelo se centra en distancias como “este token está 3 pasos antes de aquel”. Variantes modernas (incluyendo métodos tipo rotary) suelen entrar en esta familia.
Por qué importa en tareas de largo contexto
Las elecciones posicionales pueden afectar notablemente el modelado de contextos largos—cosas como resumir un informe extenso, rastrear entidades a través de muchos párrafos o recuperar un detalle mencionado miles de tokens antes.
Con entradas largas, el modelo no solo aprende lenguaje; aprende dónde mirar. Los esquemas relativos y tipo-rotary tienden a facilitar comparar tokens muy separados y preservan patrones a medida que el contexto crece, mientras que algunos esquemas absolutos pueden degradarse más rápido cuando se excede la ventana de entrenamiento.
En la práctica, la codificación posicional es una de esas decisiones de diseño discretas que pueden determinar si un LLM se siente afilado y consistente a 2.000 tokens y aún coherente a 100.000.
Gana créditos por contenido
Gana créditos compartiendo contenido sobre tu proyecto en Koder.ai.
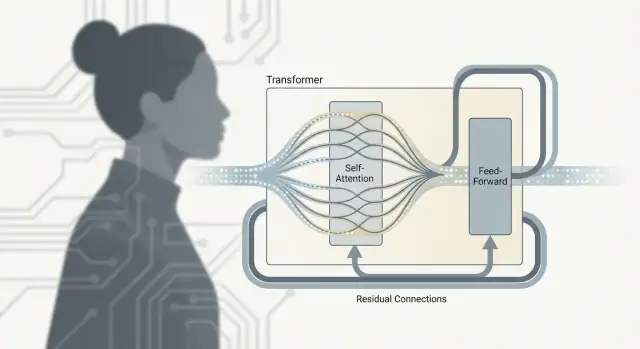
Un Transformer no es solo “atención”. El trabajo real ocurre dentro de una unidad repetida—a menudo llamada bloque Transformer—que mezcla información entre tokens y luego la refina. Apila muchos de estos bloques y obtendrás la profundidad que hace tan capaces a los modelos de lenguaje grandes.
Después de la atención: qué hace la FFN/MLP
La autoatención es el paso de comunicación: cada token recopila contexto de otros tokens.
La red feed-forward (FFN), también llamada MLP, es el paso de pensamiento: toma la representación actualizada de cada token y ejecuta la misma pequeña red neuronal sobre ella de forma independiente.
En términos sencillos, la FFN transforma y remodela lo que cada token ya sabe, ayudando al modelo a construir características más ricas (como patrones sintácticos, hechos o rasgos de estilo) después de haber recogido el contexto relevante.
Por qué los bloques alternan atención y FFN
La alternancia importa porque las dos partes hacen trabajos distintos:
- La atención mueve información entre tokens (quién influye a quién)
- La FFN procesa información dentro de cada token (cómo convertir ese contexto en características útiles)
Repetir ese patrón permite al modelo construir gradualmente significados de más alto nivel: comunicar, calcular, comunicar otra vez, calcular otra vez.
Conexiones residuales: los “carriles de salto”
Cada subcapa (atención o FFN) está envuelta con una conexión residual: la entrada se suma a la salida. Esto ayuda a que los modelos profundos entrenen porque los gradientes pueden fluir por el “carril de salto” incluso si una capa aún está aprendiendo. También permite que una capa haga ajustes pequeños en lugar de tener que reaprender todo desde cero.
Normalización por capas: mantener señales estables
La normalización por capas es un estabilizador que evita que las activaciones se disparen o se hundan al pasar por muchas capas. Piénsalo como mantener un nivel de volumen consistente para que las capas posteriores no se saturen ni se queden sin señal—haciendo el entrenamiento más suave y confiable, especialmente a escala de LLM.
Codificador–decodificador vs solo-decodificador: ¿qué impulsa a los LLMs?
El Transformer original en Attention Is All You Need se diseñó para traducción, donde conviertes una secuencia (francés) en otra (inglés). Ese trabajo se divide naturalmente en dos roles: leer bien la entrada y escribir la salida con fluidez.
Codificador–decodificador: “leer, luego escribir”
En un Transformer codificador–decodificador, el codificador procesa toda la oración de entrada a la vez y produce un conjunto rico de representaciones. El decodificador genera la salida un token a la vez.
Crucialmente, el decodificador no depende solo de sus tokens pasados: también usa cross-attention para mirar las salidas del codificador, ayudándole a estar anclado en el texto fuente.
Esta configuración sigue siendo excelente cuando debes condicionar fuertemente en una entrada—traducción, resumen o preguntas con un pasaje específico.
Solo-decodificador: un modelo que sigue prediciendo
La mayoría de los LLMs modernos son solo-decodificador. Se entrenan para una tarea simple y poderosa: predecir el siguiente token.
Para que esto funcione, usan autoatención enmascarada (causal). Cada posición solo puede atender a tokens anteriores, no futuros, así la generación se mantiene consistente: el modelo escribe de izquierda a derecha, extendiendo continuamente la secuencia.
Esto domina en LLMs porque es sencillo de entrenar en enormes corpus de texto, coincide directamente con el caso de uso de generación y escala eficientemente con datos y cómputo.
Dónde encajan los modelos solo-codificador
Los Transformers solo-codificador (estilo BERT) no generan texto; leen la entrada de forma bidireccional. Son estupendos para clasificación, búsqueda y embeddings—todo lo que requiera entender un texto más que producir una larga continuación.
Los Transformers resultaron especialmente amigables con el escalado: si les das más texto, más cómputo y modelos más grandes, tienden a mejorar de forma predecible.
Una gran razón es la simplicidad estructural. Un Transformer está construido a partir de bloques repetidos (autoatención + una pequeña red feed-forward, más normalización), y esos bloques se comportan de forma similar tanto si entrenas con un millón de palabras como con un billón.
El entrenamiento paralelo es la superpotencia oculta
Los modelos de secuencia anteriores (como RNNs) tenían que procesar tokens uno por uno, lo que limita cuánto trabajo puedes hacer a la vez. Los Transformers, en cambio, pueden procesar todos los tokens de una secuencia en paralelo durante el entrenamiento.
Eso los hace ideales para GPUs/TPUs y configuraciones distribuidas grandes—justo lo necesario al entrenar LLMs modernos.
La “ventana de contexto” y por qué importa
La ventana de contexto es el fragmento de texto que el modelo puede “ver” en un momento dado: tu prompt más la conversación reciente o texto de documento. Una ventana mayor permite al modelo conectar ideas a lo largo de más oraciones o páginas, mantener restricciones y responder preguntas que dependen de detalles anteriores.
Pero el contexto no es gratis.
La limitación clave: el coste de la atención crece con la longitud
La autoatención compara tokens entre sí. A medida que la secuencia se alarga, el número de comparaciones crece rápidamente (aproximadamente con el cuadrado de la longitud).
Por eso las ventanas de contexto muy largas pueden ser caras en memoria y cómputo, y por qué muchos esfuerzos modernos se centran en hacer la atención más eficiente.
Escalar desbloqueó comportamiento de propósito general
Cuando los Transformers se entrenan a escala, no solo mejoran en una tarea concreta. A menudo empiezan a mostrar capacidades amplias y flexibles—resumir, traducir, escribir, programar y razonar—porque la misma maquinaria de aprendizaje general se aplica a datos enormes y variados.
Variantes modernas basadas en el mismo plano
Prototipa flujos de trabajo RAG
Prueba la recuperación, los embeddings y los bucles de herramientas sin reconstruir la misma infraestructura.
El diseño original del Transformer sigue siendo el punto de referencia, pero la mayoría de los LLMs de producción son “Transformers más”: pequeñas ediciones prácticas que mantienen el bloque central (atención + MLP) mientras mejoran la velocidad, estabilidad o la longitud del contexto.
Mejoras comunes que verás
Muchas mejoras no cambian qué es el modelo, sino que hacen que entren y se ejecute mejor:
- Mejores métodos posicionales: alternativas a las posiciones sinusoidales clásicas (a menudo rotary o relativos) que mejoran el manejo de rangos largos.
- Optimización de la atención: implementaciones que reducen el uso de memoria y aumentan el rendimiento (por ejemplo, kernels fusionados o cálculos de atención más eficientes).
- Ajustes de normalización: variar dónde y cómo se aplica la normalización puede mejorar la estabilidad del entrenamiento y reducir la sensibilidad a hiperparámetros.
Estos cambios por lo general no alteran la “essencia Transformer”: la refinan.
Enfoques para contexto largo (a alto nivel)
Extender el contexto de unos pocos miles de tokens a decenas o cientos de miles suele apoyarse en atención dispersa (atender solo a tokens seleccionados) o variantes de atención eficiente (aproximar o reestructurar la atención para reducir cómputo).
El compromiso suele ser entre precisión, memoria y complejidad de ingeniería.
Mixture-of-Experts (MoE): más capacidad sin coste lineal
Los modelos MoE añaden múltiples subredes “expertas” y enrutan cada token solo a un subconjunto. Conceptualmente: obtienes un cerebro más grande, pero no activas todo cada vez.
Esto puede reducir el cómputo por token para un conteo de parámetros dado, pero aumenta la complejidad del sistema (enrutamiento, balanceo de expertos, serving).
Cómo evaluar las afirmaciones de variantes
Cuando un modelo presume una nueva variante Transformer, pide:
- Benchmarks relevantes para tus tareas (no solo puntuaciones llamativas)
- Latencia (tiempo hasta el primer token y tokens/seg)
- Coste (entrenamiento e inferencia), incluyendo memoria y requisitos de hardware
La mayoría de las mejoras son reales—pero raramente son gratis.
Qué significa esto para equipos que construyen con LLMs
Las ideas del Transformer, como la autoatención y el escalado, son fascinantes—pero los equipos de producto las sienten más como compensaciones: cuánto texto puedes introducir, qué tan rápido llega la respuesta y cuánto cuesta por petición.
Elegir un modelo o proveedor: las cuatro compensaciones
Longitud de contexto: Más contexto permite incluir más documentos, historial de chat e instrucciones. También incrementa el gasto en tokens y puede ralentizar las respuestas. Si tu función depende de “leer estas 30 páginas y responder”, prioriza la longitud de contexto.
Latencia: Experiencias de chat y copiloto en tiempo real viven o mueren por el tiempo de respuesta. La salida en streaming ayuda, pero la elección del modelo, la región y el batching también importan.
Coste: El precio suele ser por token (entrada + salida). Un modelo que sea 10% “mejor” puede costar 2–5× más. Usa comparaciones de precios para decidir qué nivel de calidad merece la pena pagar.
Calidad: Defínela para tu caso: precisión factual, seguir instrucciones, tono, uso de herramientas o código. Evalúa con ejemplos reales de tu dominio, no solo benchmarks genéricos.
Cuando los embeddings superan a la generación
Si principalmente necesitas búsqueda, deduplicación, clustering, recomendaciones o “encontrar similar”, los embeddings (a menudo modelos estilo codificador) suelen ser más baratos, rápidos y estables que invocar un modelo de generación. Usa generación solo para el paso final (resúmenes, explicaciones, redacción) tras la recuperación.
Para un análisis más profundo, dirige a tu equipo a un explicador técnico como /blog/embeddings-vs-generation.
Dónde aparece esto en flujos de trabajo reales de entrega
Al convertir las capacidades del Transformer en un producto, la parte difícil suele ser menos la arquitectura y más el flujo alrededor de ella: iteración del prompt, grounding, evaluación y despliegue seguro.
Una vía práctica es usar una plataforma de vibe-coding como Koder.ai para prototipar y lanzar funciones respaldadas por LLMs más rápido: puedes describir la app web, endpoints de backend y modelo de datos en chat, iterar en modo planificación y luego exportar código fuente o desplegar con hosting, dominios personalizados y rollback mediante snapshots. Eso es especialmente útil cuando experimentas con recuperación, embeddings o bucles de invocación de herramientas y necesitas ciclos de iteración cerrados sin reconstruir la infraestructura básica cada vez.
Lista de verificación práctica para la adopción
- Escribe una especificación de una página: objetivo del usuario, modos de fallo y qué significa “bueno”.
- Decide qué debe estar anclado en tus datos (RAG, citas o llamadas a herramientas).
- Fija presupuestos para tokens, latencia y gasto mensual; mídelo en staging.
- Añade barreras de seguridad: rechazos, redacción y comportamiento de “no sé”.
- Construye evaluación desde temprano: prompts dorados, pruebas de regresión y revisión humana.
- Planifica para cambiar de modelo: mantén prompts y enrutamiento configurables.