Cuando la base de datos está estresada, ¿qué falla primero?
Cuando tu base de datos está sobrecargada, los usuarios rara vez ven un mensaje limpio de "caída". Ven timeouts, páginas que cargan a medias, botones que giran para siempre y acciones que a veces funcionan y otras veces fallan. Un guardado puede tener éxito una vez y al siguiente dar error con "Algo salió mal." Esa incertidumbre es lo que hace que los incidentes se sientan caóticos.
Lo primero que suele fallar son los caminos con muchas escrituras: editar registros, procesos de pago, envío de formularios, actualizaciones en background y cualquier cosa que necesite una transacción y locks. Bajo estrés, las escrituras se vuelven más lentas, se bloquean entre sí y además pueden ralentizar las lecturas al mantener locks y forzar trabajo adicional.
Los errores aleatorios se sienten peor que una limitación controlada porque los usuarios no saben qué hacer después. Reintentan, actualizan, vuelven a hacer clic y generan aún más carga. Los tickets de soporte se disparan porque el sistema parece "más o menos funcionar", pero nadie puede confiar en él.
El objetivo del modo solo-lectura durante incidentes no es la perfección. Es mantener las partes más importantes utilizables: ver registros clave, buscar, comprobar estados y descargar lo que la gente necesita para seguir trabajando. Detienes o demoras intencionalmente las acciones riesgosas (escrituras) para que la base de datos se recupere y las lecturas restantes sigan respondiendo.
Fija expectativas con claridad. Esto es una limitación temporal y no significa que se esté borrando información. En la mayoría de los casos, los datos existentes del usuario siguen ahí y seguros: el sistema simplemente pausa cambios hasta que la base de datos vuelva a estar saludable.
Qué significa realmente el modo solo-lectura
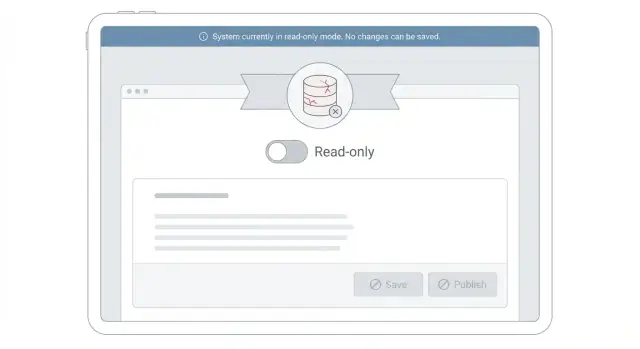
El modo solo-lectura durante incidentes es un estado temporal en el que tu producto sigue siendo usable para ver información, pero rechaza cualquier cosa que cambie datos. El objetivo es simple: mantener el servicio útil mientras proteges la base de datos de trabajo adicional.
En términos sencillos, la gente aún puede buscar cosas, pero no puede realizar cambios que desencadenen escrituras. Normalmente eso significa que navegar por páginas, buscar, filtrar y abrir registros sigue funcionando. Guardar formularios, editar ajustes, publicar comentarios, subir archivos o crear nuevas cuentas están bloqueados.
Una forma práctica de pensarlo es: si una acción actualiza una fila, crea una fila, borra una fila o escribe a una cola, no está permitida. Muchos equipos también bloquean "escrituras ocultas" como eventos de analítica almacenados en la base primaria, logs de auditoría escritos de forma síncrona y timestamps de "última vez visto".
El modo solo-lectura es la opción correcta cuando las lecturas siguen funcionando en su mayoría, pero la latencia de escrituras sube, la contención de locks crece o un backlog de trabajo pesado en escrituras está ralentizando todo.
Ve totalmente offline cuando incluso las lecturas básicas hagan timeout, tu cache no pueda servir lo esencial o el sistema no pueda decir de forma fiable a los usuarios qué es seguro hacer.
Por qué ayuda: las escrituras suelen costar mucho más que una simple lectura. Una escritura puede activar índices, restricciones, locks y consultas posteriores. Bloquear escrituras también previene tormentas de reintentos, donde los clientes siguen reenviando guardados fallidos y multiplican el daño.
Ejemplo: durante un incidente en un CRM, los usuarios aún pueden buscar cuentas, abrir detalles de contactos y ver tratos recientes, pero las acciones Editar, Crear e Importar están deshabilitadas y cualquier petición de guardado se rechaza inmediatamente con un mensaje claro.
Elige las lecturas imprescindibles y las escrituras a parar
Cuando pasas a modo solo-lectura durante incidentes, la meta no es "que todo funcione". La meta es que las pantallas más importantes sigan cargando, mientras cualquier cosa que genere más presión en la base de datos se detiene rápida y seguramente.
Empieza por nombrar las pocas acciones de usuario que deben seguir funcionando incluso en un mal día. Normalmente son lecturas pequeñas que desbloquean decisiones: ver el último registro, comprobar un estado, buscar en una lista corta o descargar un informe ya cacheado.
Luego decide qué puedes pausar sin causar daño mayor. La mayoría de las rutas de escritura entran en "agradable de tener" durante un incidente: ediciones, actualizaciones masivas, importaciones, comentarios, adjuntos, eventos analíticos y cualquier cosa que dispare consultas extra.
Una forma simple de decidir es ordenar las acciones en tres grupos:
- Debe mantenerse: lecturas pequeñas y rápidas que desbloquean al usuario ahora mismo
- Puede pausarse: escrituras y lecturas pesadas que añaden carga o bloquean filas
- Puede degradarse: funcionalidades que pueden mostrar datos cacheados o una vista parcial
También fija un horizonte temporal. Si esperas minutos, puedes ser estricto y bloquear casi todas las escrituras. Si esperas horas, considera permitir un conjunto muy limitado de escrituras seguras (como restablecimientos de contraseña o actualizaciones de estado críticas) y encolar todo lo demás.
Acorda la prioridad desde el principio: seguridad sobre completitud. Es mejor mostrar un mensaje claro de "los cambios están en pausa" que permitir una escritura que se aplique a medias y deje datos inconsistentes.
Cómo decidir cuándo activarlo
Activar el modo solo-lectura es un intercambio: menos funciones ahora, pero un producto usable y una base de datos más sana. La meta es actuar antes de que los usuarios desencadenen una espiral de reintentos, timeouts y conexiones atascadas.
Vigila un pequeño conjunto de señales que puedas explicar en una frase. Si se presentan dos o más al mismo tiempo, trátalo como una advertencia temprana:
- Requests con timeout o que cruzan un umbral claro de latencia (por ejemplo, p95 sube de 300 ms a 3 s)
- CPU de la base de datos al máximo durante varios minutos, no solo un pico corto
- Agotamiento del pool de conexiones (requests en cola porque no hay conexiones disponibles)
- Log de consultas lentas que de repente se llena con las mismas pocas consultas
- Aumento de la tasa de errores por esperas de locks, deadlocks o transacciones fallidas
No te bases solo en métricas. Añade una decisión humana: la persona on-call declara el estado de incidente y activa el modo solo-lectura. Eso evita debates bajo presión y hace la acción auditable.
Haz los umbrales fáciles de recordar y de comunicar. "Las escrituras están pausadas porque la base de datos está sobrecargada" es más claro que "alcanzamos la saturación." También define quién puede accionar el interruptor y dónde se controla.
Evita que el sistema oscile entre modos. Añade una simple histéresis: una vez en solo-lectura, quédate al menos un tiempo mínimo (por ejemplo 10 a 15 minutos) y solo vuelves cuando las señales clave estén normales por un rato. Esto evita que los usuarios vean formularios que funcionan un minuto y fallan al siguiente.
Paso a paso: activar modo solo-lectura con seguridad
Trata el modo solo-lectura durante incidentes como un cambio controlado, no como una improvisación. El objetivo es proteger la base de datos deteniendo escrituras, mientras mantienes las lecturas más valiosas.
Secuencia de despliegue segura
Si puedes, despliega la ruta de código antes de activar el interruptor. Así, activar el modo es solo alternar, no editar en vivo.
- Crea un solo toggle de incidente (feature flag o setting de configuración) que todo el sistema lea. Mantenlo global y sencillo:
READ_ONLY=true. Evita múltiples flags que puedan desincronizarse.
- Actualiza la UI para prevenir intentos de escritura. Desactiva botones Guardar, oculta formularios de edición y convierte inputs en texto plano. Aún muestra datos para que la gente pueda seguir trabajando (ver, buscar, exportar).
- Haz cumplir la regla en el servidor, no solo en la UI. Bloquea escrituras en un único lugar (middleware, guardia del controlador o capa de servicio) para que todos los clientes estén cubiertos, incluyendo apps móviles, usuarios de la API y automatizaciones.
- Devuelve un error claro y consistente para escrituras bloqueadas. Usa un código de estado y un mensaje dedicado como: "La edición está temporalmente deshabilitada mientras estabilizamos el sistema. Tus datos están seguros. Intenta más tarde." No devuelvas un 500 genérico que parezca pérdida de datos.
- Registra cada intento de escritura bloqueado. Captura usuario, endpoint y tipo de acción. Mantén la carga mínima para no poner datos sensibles en logs. Esos registros te ayudan a corregir gaps de UX y a reproducir acciones críticas más tarde si es necesario.
Un detalle pequeño que evita reincidencias
Cuando el modo solo-lectura esté activo, falla rápido antes de tocar la base de datos. No ejecutes consultas de validación y luego bloquees la escritura. La petición bloqueada más rápida es la que nunca llega a tu base de datos estresada.
Mensajes en la UI que reducen confusión y tickets
Posee la implementación
Mantén el control completo exportando el código fuente después de generar tus controles de incidentes.
Cuando habilites el modo solo-lectura durante incidentes, la UI forma parte de la solución. Si la gente sigue haciendo clic en Guardar y recibe errores vagos, reintentarán, actualizarán y abrirán tickets. Mensajes claros reducen carga y frustración.
Un patrón efectivo es un banner visible y persistente en la parte superior de la app. Mantenlo corto y factual: qué está pasando, qué deben esperar los usuarios y qué pueden hacer ahora. No lo escondas en un toast que desaparece.
Di qué funciona, qué está pausado y qué viene después
Los usuarios principalmente quieren saber si pueden seguir trabajando. Dilo en lenguaje llano. Para la mayoría de productos, eso significa:
- Sigue funcionando: ver registros, buscar, descargar, leer dashboards
- Pausado: crear, editar, borrar, subidas, pagos, enviar mensajes
- Haz esto en su lugar: copiar información clave, exportar una vista, reintentar más tarde
- Actualizaciones: "Publicaremos una actualización aquí en 15 minutos."
Una etiqueta de estado simple también ayuda a entender el progreso sin adivinar. "Investigando" significa que aún estás buscando la causa. "Estabilizando" indica que reduces la carga y proteges datos. "Recuperando" implica que las escrituras volverán pronto, pero pueden ir lentas.
Mantén el tono calmado y específico
Evita textos acusatorios o vagos como "Algo salió mal" o "No tienes permiso." Si un botón está deshabilitado, etiquétalo: "La edición está temporalmente pausada mientras estabilizamos el sistema."
Un ejemplo pequeño: en un CRM, mantén legibles las páginas de contacto y trato, pero desactiva Editar, Añadir nota y Nuevo trato. Si alguien lo intenta, muestra un diálogo corto: "Los cambios están pausados ahora. Puedes copiar este registro o exportar la lista, e intenta de nuevo más tarde."
Preserva lecturas clave sin empeorar la carga
Cuando cambias a modo solo-lectura durante incidentes, la meta no es "mantener todo visible." Es "mantener las pocas páginas de las que depende la gente" sin añadir más presión a una base de datos estresada.
Empieza por recortar las pantallas más pesadas. Tablas largas con muchos filtros, búsquedas de texto libre en múltiples campos y ordenaciones complejas suelen disparar consultas lentas. En solo-lectura, simplifica esas pantallas: menos opciones de filtro, una ordenación por defecto segura y un rango de fechas limitado.
Prefiere vistas cacheadas o precomputadas para las páginas que importan. Un simple "resumen de cuenta" que lea desde cache o una tabla resumen suele ser más seguro que cargar logs crudos de eventos o hacer joins entre muchas tablas.
Formas prácticas de mantener lecturas sin agravar la carga:
- Usa tamaños de página más pequeños y quita "mostrar todo"
- Reemplaza ordenaciones complejas por un orden por defecto (por ejemplo, "más recientes primero")
- Difere lecturas no esenciales como analítica, recomendaciones y gráficos de actividad
- Prefiere resúmenes en cache sobre historiales crudos
- Acepta datos ligeramente obsoletos si mantiene las páginas principales responsivas
Un ejemplo concreto: en un incidente CRM, mantiene funcionando Ver contacto, Ver estado del trato y Ver última nota. Oculta temporalmente Búsqueda avanzada, gráfico de ingresos y línea temporal completa de emails, y muestra una nota que indique que los datos pueden estar unos minutos desactualizados.
Qué hacer con jobs, webhooks e integraciones
Ensayar cambios de forma segura
Usa snapshots y rollback para validar cambios en el comportamiento de incidentes sin riesgos.
Al activar modo solo-lectura durante incidentes, la sorpresa más común no es la UI. Son los escritores invisibles: jobs en background, sincronizaciones programadas, acciones masivas de admin e integraciones de terceros que siguen golpeando la base.
Empieza por detener el trabajo en background que crea o actualiza registros. Los culpables habituales son importaciones, sincronizaciones nocturnas, envío de emails que registra logs de entrega, rollups analíticos y bucles de reintento que siguen intentando la misma actualización fallida. Pausarlos reduce la presión rápido y evita una segunda ola de carga.
Un valor por defecto seguro es pausar o limitar jobs pesados en escrituras y cualquier consumidor de colas que persista resultados, deshabilitar acciones masivas de admin (actualizaciones masivas, borrados masivos, reindexaciones grandes) y fallar rápido en endpoints de escritura con una respuesta temporal clara en vez de hacer timeout.
Para webhooks e integraciones, la claridad vence al optimismo. Si aceptas un webhook pero no puedes procesarlo, crearás desajustes y churn de soporte. Cuando las escrituras estén pausadas, devuelve un fallo temporal que indique al emisor reintentar más tarde, y asegúrate de que la mensajería de la UI coincida con lo que haces en el backend.
Ten cuidado con "poner en cola para más tarde". Suena amable, pero puede crear un backlog que inunde el sistema en cuanto vuelvas a activar escrituras. Solo encola escrituras de usuario si puedes garantizar idempotencia, limita el tamaño de la cola y muestra al usuario el estado real (pendiente vs guardado).
Por último, audita escritores masivos ocultos en tu propio producto. Si una automatización puede actualizar miles de filas, debe forzarse a apagarse en modo solo-lectura incluso si el resto de la app sigue cargando.
Errores comunes que empeoran los incidentes
La forma más rápida de agravar un incidente es tratar el modo solo-lectura como un cambio cosmético. Si solo desactivas botones en la UI, la gente seguirá escribiendo vía APIs, pestañas antiguas, apps móviles y jobs en background. La base de datos sigue bajo presión y además pierdes confianza porque usuarios verán "guardado" en un sitio y cambios faltantes en otro.
Un modo real de solo-lectura durante incidentes necesita una regla clara: el servidor rechaza escrituras, siempre, para todos los clientes.
Errores a vigilar
Estos patrones aparecen con frecuencia durante la sobrecarga de la base:
- Bloquear ediciones solo en la UI mientras el backend aún acepta POST, PUT, PATCH y DELETE
- Olvidar rutas ocultas: paneles de admin, herramientas internas, endpoints de importación y APIs públicas usadas por integraciones
- Permitir que el sistema oscile entre normal y solo-lectura cada minuto
- Mostrar mensajes vagos como "Algo salió mal"
- Permitir escrituras parciales que dejan datos inconsistentes
Cómo evitarlos
Haz que el sistema se comporte de forma predecible. Implanta un único interruptor del lado servidor que rechace escrituras con una respuesta clara. Añade un periodo de enfriamiento para que, una vez en solo-lectura, permanezcas ese tiempo mínimo (por ejemplo 10 a 15 minutos) salvo que un operador lo cambie.
Sé estricto con la integridad de datos. Si una escritura no puede completarse por completo, falla toda la operación y di al usuario qué hacer después. Un mensaje simple como "Modo solo-lectura: ver sirve, los cambios están en pausa. Inténtalo más tarde." reduce reintentos repetidos.
Comprobaciones rápidas antes y durante un incidente
El modo solo-lectura durante incidentes solo ayuda si es fácil activarlo y se comporta igual en todas partes. Antes de que empiece el problema, asegúrate de que hay un único toggle (feature flag, config, switch de admin) que on-call pueda habilitar en segundos, sin desplegar.
Cuando sospeches sobrecarga de base de datos, haz una pasada rápida que confirme lo básico:
- Activa el toggle en un entorno seguro y confirma que surte efecto inmediatamente
- Prueba algunas acciones de escritura (guardar, borrar, importar) y confirma que cada endpoint de escritura devuelve la misma respuesta bloqueada y código de estado
- Revisa que el texto del banner esté listo, corto y visible en las pantallas que más usa la gente
- Carga tus 3 páginas principales (por ejemplo: login, dashboard, vista de registro) y confirma que siguen renderizando bajo estrés
- Asegúrate de que soporte tiene un guion de un párrafo que explique qué funciona, qué está pausado y dónde ver actualizaciones
Durante el incidente, mantén a una persona enfocada en verificar la experiencia de usuario, no solo paneles. Una comprobación rápida en una ventana de incógnito detecta issues como banners ocultos, formularios rotos o spinners infinitos que generan tráfico de refresh adicional.
Planifica la salida antes de activarlo. Decide qué significa "salud" (latencia, tasa de errores, retraso de replicación) y haz una verificación corta al reactivar: crea un registro de prueba, edítalo y confirma que conteos y actividad reciente se ven correctos.
Ejemplo de incidente: mantener un CRM usable bloqueando ediciones
Probar el escenario CRM
Prototipa un flujo estilo CRM y prueba qué sigue usable cuando las escrituras están en pausa.
Son las 10:20 AM. Tu CRM está lento y la CPU de la base está al máximo. Empiezan a llegar tickets de soporte: los usuarios no pueden guardar ediciones en contactos y tratos. Pero el equipo aún necesita buscar teléfonos, ver estados de trato y leer las últimas notas antes de llamadas.
Elijes una regla simple: congelar todo lo que escriba, mantener las lecturas más valiosas. En la práctica, la búsqueda de contactos, las páginas de detalle y la vista del pipeline se mantienen. Editar un contacto, crear un trato, añadir notas e importaciones masivas quedan bloqueadas.
En la UI, el cambio debe ser obvio y calmado. En las pantallas de edición, el botón Guardar está deshabilitado y el formulario sigue visible para que la gente pueda copiar lo que escribió. Un banner arriba dice: "Modo solo-lectura activado por alta carga. Ver está disponible. Los cambios están pausados. Intenta de nuevo más tarde." Si un usuario aún lanza una escritura (p. ej. vía API), devuelve un mensaje claro y evita reintentos automáticos que golpearían la base.
Operativamente, mantiene el flujo corto y repetible. Activa solo-lectura y verifica que todos los endpoints de escritura lo respeten. Pausa jobs en background que escriben (sincronizaciones, importes, logging de emails, rollups analíticos). Limita o pausa webhooks e integraciones que crean actualizaciones. Monitoriza carga de la DB, tasa de errores y consultas lentas. Publica una actualización de estado con lo affectado (ediciones) y lo que sigue funcionando (búsqueda y vistas).
Recuperarse no es solo apagar el toggle. Reactiva las escrituras gradualmente, revisa logs de errores por guardados fallidos y vigila una posible tormenta de escrituras desde jobs en cola. Luego comunica claramente: "Modo solo-lectura desactivado. El guardado está restaurado. Si intentaste guardar entre 10:20 y 10:55, revisa tus últimos cambios."
Próximos pasos: haz del modo solo-lectura parte de tu playbook
El modo solo-lectura durante incidentes funciona mejor cuando es aburrido y repetible. La meta es seguir un guion corto con dueños y comprobaciones claras.
Construye un playbook pequeño y usable
Mantenlo en una página. Incluye tus disparadores (las pocas señales que justifican cambiar a solo-lectura), el switch exacto que activas y cómo confirmas que las escrituras están bloqueadas, una lista corta de lecturas clave que deben seguir funcionando, roles claros (quién activa, quién vigila métricas, quién atiende soporte) y criterios de salida (qué debe ser cierto antes de reactivar escrituras y cómo drenarán los backlogs).
Prepara el texto de la UI antes de necesitarlo
Escribe y aprueba los mensajes ahora para no discutir el wording durante un outage. Un conjunto simple cubre la mayoría de casos:
- Banner: "Estamos en modo solo-lectura mientras restauramos el rendimiento. Puedes ver datos, pero los cambios están temporalmente deshabilitados."
- En acciones bloqueadas: "El guardado está en pausa ahora. Tus cambios no se aplicaron. Inténtalo de nuevo en unos minutos."
- Detalle de estado: "Última actualización a las HH:MM. Próxima actualización en 10 minutos."
Practica el cambio en staging y mide el tiempo. Asegúrate de que soporte y on-call encuentren el toggle rápido y que los logs muestren claramente las escrituras bloqueadas. Tras cada incidente, revisa qué lecturas fueron realmente críticas, cuáles eran agradables de tener y cuáles accidentalmente crearon carga, y actualiza la checklist.
Si construyes productos sobre Koder.ai (koder.ai), puede ser útil tratar el modo solo-lectura como un toggle de primera clase en tu app generada para que la UI y las protecciones del servidor permanezcan consistentes cuando más las necesites.