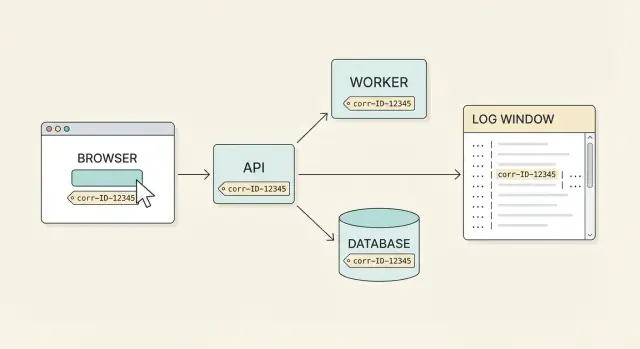
Por qué los IDs de correlación importan para soporte
El soporte casi nunca recibe un informe de error limpio. Un usuario dice "hice clic en Pagar y falló", pero ese único clic puede involucrar el navegador, un gateway de API, un servicio de pagos, una base de datos y un job en segundo plano. Cada parte registra su propia porción de la historia en distintos momentos y máquinas. Sin una etiqueta compartida, acabas adivinando qué líneas de registro pertenecen juntas.
Un ID de correlación es esa etiqueta compartida. Es un ID único adjunto a una acción de usuario (o a un flujo lógico) y que se mantiene a través de cada petición, reintento y salto entre servicios. Con cobertura de extremo a extremo real, puedes empezar con la queja del usuario y obtener la cronología completa entre sistemas.
A menudo se confunden varios IDs similares. Aquí está la separación clara:
- Correlation ID: agrupa todo lo relacionado con una acción (por ejemplo, "Guardar ajustes").
- Request ID: identifica una petición HTTP concreta. Los reintentos crean nuevos request IDs.
- Trace ID: lo usan las herramientas de trazado distribuido; objetivo similar, a menudo generado por librerías de tracing.
- Session ID: identifica una sesión de usuario a lo largo de muchas acciones; demasiado amplio para depurar un incidente concreto.
Cómo debería funcionar en la práctica es sencillo: un usuario informa un problema, le pides el correlation ID que aparece en la UI (o que aparece en una pantalla de soporte), y cualquiera del equipo puede encontrar la historia completa en minutos. Ves la petición desde el frontend, la respuesta del API, los pasos del backend y el resultado en la base de datos, todo conectado.
Decide tus convenciones de ID de correlación
Antes de generar nada, pon de acuerdo unas reglas. Si cada equipo elige un nombre de cabecera distinto o un campo distinto en los logs, el soporte seguirá atascado adivinando.
Empieza con un nombre canónico y úsalo en todas partes. Una opción habitual es una cabecera HTTP como X-Correlation-Id, más un campo estructurado de logs como correlation_id. Elige una ortografía y un uso de mayúsculas, documéntalo y asegúrate de que tu proxy inverso o gateway no la renombre ni la elimine.
Elige un formato fácil de crear y seguro para compartir en tickets y chats. Los UUIDs funcionan bien porque son únicos y aburridos. Mantén el ID lo bastante corto para copiar, pero no tan corto que haya riesgo de colisiones. La consistencia vence a la originalidad.
Decide también dónde debe aparecer el ID para que la gente lo use realmente. En la práctica eso significa que esté presente en las solicitudes, en los logs y en las salidas de error, y que sea buscable en la herramienta que use tu equipo.
Define cuánto debe vivir un ID. Un valor razonable por defecto es la duración de una acción de usuario, como "clic en Pagar" o "guardar perfil". Para flujos más largos que atraviesan servicios y colas, mantén el mismo ID hasta que el flujo termine y empieza uno nuevo para la siguiente acción. Evita "un ID para toda la sesión" porque las búsquedas se vuelven ruidosas rápidamente.
Una regla estricta: nunca pongas datos personales en el ID. Nada de emails, teléfonos, IDs de usuario o números de pedido. Si necesitas ese contexto, grábalo en campos separados con controles de privacidad adecuados.
Genera el ID en el frontend (enfoque práctico)
El sitio más fácil para comenzar un ID de correlación es el momento en que el usuario inicia la acción que te interesa: clic en "Guardar", envío de un formulario o el inicio de un flujo que dispara varias peticiones. Si esperas a que el backend lo cree, a menudo pierdes la primera parte de la historia (errores de UI, reintentos, solicitudes canceladas).
Usa un formato aleatorio y único. UUID v4 es una elección común porque es fácil de generar y poco probable que colisione. Mantén el ID opaco (sin nombres de usuario, emails ni timestamps) para no filtrar datos personales en cabeceras y logs.
Crea y conserva el ID durante un flujo
Trata un "flujo" como una acción de usuario que puede desencadenar varias peticiones: validar, subir, crear registro y después refrescar listas. Crea un ID cuando empieza el flujo y consérvalo hasta que termine (éxito, fallo o cancelación por parte del usuario). Un patrón simple es guardarlo en el estado del componente o en un objeto de contexto de petición ligero.
Si el usuario inicia la misma acción dos veces, genera un ID de correlación nuevo para el segundo intento. Eso permite al soporte distinguir "mismo clic reintentado" de "dos envíos separados".
Añádelo a cada petición que haga ese flujo
Agrega el ID a cada llamada API disparada por el flujo, normalmente vía una cabecera como X-Correlation-ID. Si usas un cliente de API compartido (wrapper de fetch, instancia de Axios, etc.), pasa el ID una sola vez y deja que el cliente lo inyecte en todas las llamadas.
const correlationId = crypto.randomUUID();
await api.post('/orders', payload, {
headers: { 'X-Correlation-ID': correlationId }
});
await api.get('/orders/summary', {
headers: { 'X-Correlation-ID': correlationId }
});
Si tu UI hace peticiones en segundo plano no relacionadas con la acción (polling, analytics, auto‑refresh), no reutilices el ID del flujo para esas. Mantén los IDs de correlación enfocados para que un ID cuente una sola historia.
Una vez generas un ID de correlación en el navegador, el trabajo es simple: debe salir del frontend con cada solicitud y llegar inalterado a cada límite de API. Ahí es donde suele romperse al añadir nuevos endpoints, nuevos clientes o nuevo middleware.
El valor por defecto más seguro es una cabecera HTTP en cada llamada (por ejemplo X-Correlation-Id). Las cabeceras son fáciles de añadir en un solo lugar (un wrapper de fetch, un interceptor de Axios, una capa de red en móvil) y no requieren cambiar payloads.
Si tienes peticiones cross‑origin, asegúrate de que tu API permita esa cabecera. Si no, el navegador puede bloquearla en silencio y creerás que la estás enviando cuando no es así.
Si debes poner el ID en la query string o en el cuerpo de la petición (algunas herramientas externas o subidas de archivos lo exigen), hazlo de forma consistente y documentada. Elige un nombre de campo y úsalo en todas partes. No mezcles correlationId, requestId y cid según el endpoint.
Los reintentos son otra trampa común. Un reintento debe mantener el mismo ID de correlación si sigue siendo la misma acción del usuario. Ejemplo: el usuario pulsa "Guardar", la red cae y el cliente reintenta el POST. El soporte debería ver un solo rastro conectado, no tres independientes. Un nuevo clic de usuario (o un job nuevo) debería recibir un ID nuevo.
Para WebSockets, incluye el ID en el sobre del mensaje, no solo en el handshake inicial. Una conexión puede transportar muchas acciones de usuario.
Si quieres una comprobación rápida de fiabilidad, mantenlo simple:
- Un helper de cliente compartido añade la cabecera en cada petición.
- Los reintentos reutilizan el mismo ID para la misma acción.
- Cualquier fallback en body/query usa un nombre de campo documentado.
- Los mensajes de WebSocket incluyen un campo explícito
correlationId.
Configura el comportamiento en el punto de entrada de la API
Generate code you can export
Keep full control while Koder.ai generates your React, Go, and Postgres stack.
Tu borde de API (gateway, load balancer o el primer servicio web que recibe tráfico) es donde los IDs de correlación se convierten en fiables o en conjeturas. Trata este punto de entrada como la fuente de verdad.
Acepta un ID entrante si el cliente lo envía, pero no asumas que siempre estará presente. Si falta, genera uno nuevo de inmediato y úsalo durante el resto de la petición. Esto mantiene todo funcionando incluso cuando algunos clientes son antiguos o están mal configurados.
Haz una validación ligera para que valores malos no contaminen tus logs. Mantén la validación permisiva: comprueba longitud y caracteres permitidos, pero evita formatos estrictos que rechacen tráfico real. Por ejemplo, permite 16–64 caracteres y letras, números, guiones y guion bajo. Si el valor falla la validación, reemplázalo por un ID nuevo y continúa.
Haz que el ID sea visible al llamador. Devuélvelo siempre en cabeceras de respuesta e inclúyelo en cuerpos de error. Así un usuario puede copiarlo desde la UI, o un agente de soporte puede pedirlo y encontrar la traza exacta.
Una política práctica en el borde se ve así:
- Lee
X-Correlation-ID (o la cabecera elegida) de la solicitud.
- Si falta o es inválida, crea un ID nuevo y adjúntalo al contexto de la petición.
- Añade
X-Correlation-ID a cada respuesta, incluidos los errores.
- Al devolver errores JSON, repite el ID en el payload.
Ejemplo de payload de error (lo que el soporte debería ver en tickets y capturas):
{
"error": {
"code": "PAYMENT_FAILED",
"message": "We could not confirm the payment.",
"correlation_id": "c3a8f2d1-9b24-4c61-8c4a-2a7c1b9c2f61"
}
}
Propaga el ID entre los servicios backend
Una vez que una petición llega al backend, trata el ID de correlación como parte del contexto de la solicitud, no como algo que almacenas en una variable global. Los globales fallan cuando manejas dos peticiones a la vez o cuando el trabajo asíncrono continúa después de la respuesta.
Una regla que escala: cada función que pueda registrar o llamar a otro servicio debería recibir el contexto que contiene el ID. En servicios Go, eso suele significar pasar context.Context por los handlers, la lógica de negocio y el código cliente.
Cuando el Servicio A llama al Servicio B, copia el mismo ID en la petición saliente. No generes uno nuevo en mitad del vuelo a menos que también mantengas el original en un campo separado (por ejemplo parent_correlation_id). Si cambias IDs, el soporte pierde el hilo único que une la historia.
La propagación suele perderse en lugares previsibles: jobs en segundo plano iniciados durante la petición, reintentos dentro de librerías cliente, webhooks disparados más tarde y llamadas en fan‑out. Cualquier mensaje asíncrono (cola/job) debe llevar el ID, y cualquier lógica de reintento debería preservarlo.
Los logs deben ser estructurados con un nombre de campo estable como correlation_id. Elige una ortografía y úsala en todas partes. Evita mezclar requestId, req_id y traceId a menos que también definas un mapeo claro.
Si es posible, incluye el ID en la visibilidad de la base de datos también. Un enfoque práctico es añadirlo a comentarios de consulta o metadatos de sesión para que los logs de consultas lentas lo muestren. Cuando alguien reporte "el botón Guardar tardó 10 segundos", el soporte puede buscar correlation_id=abc123 y ver el log del API, la llamada al servicio downstream y la sentencia SQL lenta que causó el retraso.
Incluye el ID en logs que los humanos puedan usar
Un ID de correlación solo ayuda si la gente puede encontrarlo y seguirlo. Hazlo un campo de primera clase en los logs (no enterrado dentro del mensaje) y mantén el resto de la entrada de log consistente entre servicios.
Campos de log que hacen usable el ID
Acompaña el ID de correlación con un pequeño conjunto de campos que respondan: cuándo, dónde, qué y quién (de forma segura). Para la mayoría de equipos eso significa:
timestamp (con zona horaria)service y env (api, worker, prod, staging)route (o nombre de operación) y methodstatus y duration_ms- un identificador seguro de usuario (por ejemplo
account_id o un id hashed, no un email)
Con esto, el soporte puede buscar por ID, confirmar que están viendo la petición correcta y ver qué servicio la atendió.
Qué registrar al inicio, éxito y fallo
Apunta a dejar unas migas de pan útiles por petición, no una transcripción completa.
- Inicio: correlation ID, ruta, identificador seguro de usuario y entradas clave (resumidas).
- Éxito: correlation ID, estado, duración y un resultado corto (por ejemplo
rows=12).
- Fallo: correlation ID, tipo de error, contexto seguro y dónde ocurrió (handler, dependencia).
Para evitar logs ruidosos, deja los detalles a nivel debug por defecto y promueve solo los eventos que ayudan a responder "¿dónde falló?". Si una línea no ayuda a localizar el problema o medir el impacto, probablemente no pertenece al nivel info.
La redacción (redaction) importa tanto como la estructura. Nunca pongas PII en el ID de correlación ni en los logs: no emails, nombres, teléfonos, direcciones completas ni tokens en texto plano. Si necesitas identificar un usuario, registra un ID interno o un hash unidireccional.
Get rewarded for building
Share what you build on Koder.ai or refer teammates to get credits.
Un usuario escribe al soporte: "El checkout falló cuando hice clic en Pagar." La mejor pregunta de seguimiento es simple: "¿Puedes pegar el correlation ID que aparece en la pantalla de error?" Ellos responden con cid=9f3c2b1f6a7a4c2f.
Soporte ahora tiene un identificador que conecta la UI, el API y la actividad en la base de datos. El objetivo es que cada línea de log de esa acción lleve el mismo ID.
Soporte busca logs por 9f3c2b1f6a7a4c2f y ve el flujo:
frontend INFO cid=9f3c2b1f6a7a4c2f event="checkout_submit" cart=3 items
api INFO cid=9f3c2b1f6a7a4c2f method=POST path=/api/checkout user=1842
api ERROR cid=9f3c2b1f6a7a4c2f msg="payment failed" provider=stripe status=502
A partir de ahí, un ingeniero sigue el mismo ID hasta el siguiente salto. La clave es que las llamadas del backend (y cualquier job en cola) también reenvían el ID.
payments INFO cid=9f3c2b1f6a7a4c2f action="charge" amount=49.00 currency=USD
payments ERROR cid=9f3c2b1f6a7a4c2f err="timeout" upstream=stripe timeout_ms=3000
db INFO cid=9f3c2b1f6a7a4c2f query="insert into failed_payments" rows=1
Ahora el problema es concreto: el servicio de pagos hizo timeout después de 3 segundos y se registró un fallo. El ingeniero puede revisar despliegues recientes, confirmar si cambiaron los timeouts y ver si están ocurriendo reintentos.
Para cerrar el ciclo, haz cuatro comprobaciones:
- Arregla la causa (por ejemplo, ajusta el timeout y añade un reintento seguro).
- Asegúrate de que los errores visibles al usuario incluyan el correlation ID.
- Vigila nuevos logs con el mismo patrón de error y distintos IDs.
- Confirma que el ID sobrevive todos los saltos (incluyendo workers y mensajes en colas).
Errores comunes y cómo evitarlos
La forma más rápida de hacer inútiles los IDs de correlación es romper la cadena. La mayoría de fallos vienen de pequeñas decisiones que parecen inocuas mientras construyes, pero molestan cuando el soporte necesita respuestas.
Un error clásico es generar un ID nuevo en cada salto. Si el navegador envía un ID, tu gateway de API debería conservarlo, no reemplazarlo. Si realmente necesitas un ID interno (por ejemplo para un mensaje en cola o un job), conserva el original como campo parent para que la historia siga conectada.
Otra laguna común es el logging parcial. Los equipos añaden el ID en el primer API, pero se olvidan de él en procesos worker, jobs programados o en la capa de acceso a base de datos. El resultado es un callejón sin salida: ves la petición entrar al sistema, pero no a dónde fue después.
Evita el problema de "caos de nombres"
Aunque el ID exista en todas partes, puede ser difícil buscar si cada servicio usa un nombre de campo distinto o un formato distinto. Elige un nombre y cíñete a él en frontend, APIs y logs (por ejemplo correlation_id). También elige un formato (a menudo un UUID) y trátalo como case‑sensitive para que copiar y pegar funcione.
No pierdas el ID cuando las cosas van mal. Si una API devuelve un 500 o un error de validación, incluye el correlation ID en la respuesta de error (y preferiblemente en una cabecera de respuesta también). Así un usuario puede pegarlo en un chat de soporte y tu equipo puede trazar inmediatamente la ruta completa.
Una prueba rápida: ¿puede una persona de soporte partir de un ID y seguirlo por cada línea de log implicada, incluyendo fallos?
Lista de comprobación rápida para verificar cobertura de extremo a extremo
Debug without risky releases
Use snapshots and rollback so debugging changes are easy to undo.
Usa esto como chequeo antes de decirle al soporte "solo busca en los logs". Esto solo funciona cuando cada salto sigue las mismas reglas.
Comprobaciones que deben pasar
- Tienes un formato de ID y un nombre de cabecera, usado en todas partes (frontend, gateway, APIs, workers).
- El frontend crea (o recibe) el ID al inicio de la acción del usuario y lo mantiene estable hasta que esa acción termina.
- Tu punto de entrada API crea un ID si falta y siempre lo devuelve en cabeceras de respuesta.
- Cada servicio backend incluye
correlation_id en los logs relacionados con la petición como campo estructurado.
- El on‑call puede pegar un ID en la búsqueda de logs y ver todo el camino en minutos: petición de borde, auth, llamadas a servicios, operación en base de datos y reintentos.
Si alguna comprobación falla, arréglalo así
Elige el cambio más pequeño que deje la cadena ininterrumpida.
- Si los IDs cambian a mitad del flujo, deja de generar nuevos IDs dentro de servicios internos. Conserva el
correlation_id original y añade un span_id separado si necesitas más detalle.
- Si faltan campos en los logs, añade middleware de logging para que los ingenieros no tengan que recordar incluirlo.
- Si soporte no puede conseguir el ID, asegúrate de que la UI lo muestra en pantallas de error y que el gateway lo refleja en cada respuesta.
Una prueba rápida que detecta fallos: abre devtools, ejecuta una acción, copia el correlation ID de la primera petición, y confirma que ves el mismo valor en cada petición API relacionada y en cada línea de log correspondiente.
Próximos pasos: incorpóralo en tu proceso de entrega
Los IDs de correlación solo ayudan cuando todos los usan de la misma forma, siempre. Trata el comportamiento del ID de correlación como parte obligatoria del "definition of done" al desplegar, no como una mejora opcional de logs.
Añade un pequeño paso de trazabilidad a la definición de terminado para cualquier endpoint o acción UI nueva. Cubre cómo se crea (o reutiliza) el ID, dónde vive durante el flujo, qué cabecera lo transporta y qué hace cada servicio cuando falta la cabecera.
Una lista de verificación ligera suele ser suficiente:
- Frontend: genera o reutiliza un ID por acción de usuario y lo adjunta a cada llamada API de esa acción.
- Punto de entrada API: acepta la cabecera, valida o genera, y luego la devuelve en la respuesta.
- Backend: pásalo a servicios downstream y jobs, e inclúyelo en los logs.
- Logging: mantén el nombre del campo consistente (por ejemplo,
correlation_id) entre apps y servicios.
- Revisiones: rechaza PRs que añadan endpoints sin pruebas que demuestren que el ID aparece en los logs.
Soporte también necesita un script simple para que la depuración sea rápida y repetible. Decide dónde aparece el ID para los usuarios (por ejemplo, un botón "Copiar ID de depuración" en diálogos de error) y documenta qué debe pedir el soporte y dónde buscar.
Antes de confiar en ello en producción, ejecuta un flujo en staging que reproduzca el uso real: pulsa un botón, provoca un error de validación y después completa la acción. Confirma que puedes seguir el mismo ID desde la petición del navegador, a través de los logs del API, dentro de cualquier worker y hasta las trazas de la base de datos si las registras.
Si construyes aplicaciones en Koder.ai, ayuda escribir tu cabecera de correlation ID y las convenciones de logging en Planning Mode para que los frontends React y los servicios Go generados empiecen consistentes por defecto.