29 dic 2025·8 min
Herramientas administrativas que previenen la pérdida de datos: acciones masivas más seguras
Las herramientas de administración que previenen la pérdida de datos usan acciones masivas seguras, confirmaciones claras, eliminaciones suaves, logs de auditoría y límites por rol para que los operadores eviten errores costosos.
Dónde ocurre la pérdida de datos en herramientas administrativas
Las herramientas administrativas internas parecen más seguras porque “solo el personal” puede usarlas. Esa confianza es precisamente lo que las convierte en de alto riesgo. Las personas que las usan tienen poder, trabajan rápido y suelen hacer la misma acción muchas veces al día. Un descuido puede afectar miles de registros.
La mayoría de los accidentes no son intencionales. Provienen de momentos de “ups”: un filtro demasiado amplio, un término de búsqueda que coincidió con más de lo esperado o un desplegable que quedó en el tenant equivocado. Otro clásico es el entorno equivocado: alguien piensa que está en staging, pero está mirando producción porque la interfaz se parece mucho.
La velocidad y la repetición empeoran esto. Cuando una herramienta está pensada para moverse rápido, los usuarios desarrollan memoria muscular: hacer clic, confirmar, siguiente. Si la pantalla se retrasa, hacen clic dos veces. Si una acción masiva tarda, abren una segunda pestaña. Estos hábitos son normales, pero crean las condiciones para errores.
“Destruir datos” no es solo pulsar un botón de eliminar. En la práctica puede significar:
- Eliminar registros (incluyendo eliminaciones en cascada)
- Sobrescribir campos (por ejemplo, poner el estado a “closed” para el conjunto equivocado)
- Desvincular relaciones (desasociar un usuario de una cuenta, quitar permisos)
- Purgar historial (borrar logs, mensajes, truncar tablas)
- Exportaciones o sincronizaciones irreversibles (empujar datos erróneos a otro sistema)
Para equipos que construyen herramientas administrativas que previenen la pérdida de datos, “suficientemente seguro” debe ser un acuerdo claro, no una sensación. Una definición simple: un operador apurado debería poder recuperarse de un error común sin ayuda de ingeniería, y una acción rara e irreversible debería requerir fricción extra, una prueba clara de intención y un registro que puedas auditar después.
Aunque construyas apps rápido con una plataforma como Koder.ai, estos riesgos siguen siendo los mismos. La diferencia es si diseñas salvaguardas desde el día uno o esperas al primer incidente para aprender.
Empieza con un mapa de riesgos simple
Antes de cambiar cualquier UI, aclara qué puede salir mal. Un mapa de riesgos es una lista breve de acciones que pueden causar daño real, más las reglas que deben rodearlas. Este paso es lo que separa las herramientas administrativas que previenen la pérdida de datos de las que solo parecen cuidadosas.
Comienza escribiendo tus acciones más peligrosas. Normalmente no son las ediciones cotidianas. Son las operaciones que cambian muchos registros rápido o tocan datos sensibles.
Un primer listado útil es:
- Eliminar, fusionar, cerrar o deshabilitar cuentas de forma permanente
- Reasignar propiedad (clientes, facturas, tickets, leads)
- Importaciones y actualizaciones masivas (CSV, trabajos por API, migraciones)
- Acciones de facturación (reembolsos, créditos, cancelaciones)
- Cambios de permisos (roles, acceso a PII)
Luego, marca cada acción como reversible o irreversible. Sé estricto. Si solo puedes revertirla restaurando desde un backup, trátala como irreversible para el operador que está haciendo el trabajo.
Después decide qué debe protegerse por política, no solo por diseño. Reglas legales y de privacidad suelen aplicarse a PII (nombres, emails, direcciones), registros de facturación y logs de auditoría. Aunque una herramienta pueda borrar algo técnicamente, tu política puede requerir retención o una revisión de dos personas.
Separa las operaciones rutinarias de las excepcionales. El trabajo rutinario debe ser rápido y seguro (pequeños cambios, deshacer claro). El trabajo excepcional debe ser más lento a propósito (chequeos extra, aprobaciones, límites más estrictos).
Finalmente, acuerda términos simples de “radio de impacto” para que todos hablen el mismo idioma: un registro, muchos registros, todos los registros. Por ejemplo, “reasignar este cliente” es diferente de “reasignar todos los clientes de este representante”. Esa etiqueta guiará después tus valores por defecto, confirmaciones y límites de rol.
Ejemplo: en un proyecto de vibe-coding en Koder.ai, podrías marcar “importación masiva de usuarios” como muchos-registros, reversible solo si registras cada ID creado, y protegido por política porque toca PII.
Patrones para acciones masivas más seguras
Las acciones masivas son donde buenas herramientas administrativas se vuelven riesgosas. Si quieres construir herramientas administrativas que prevengan la pérdida de datos, trata cada botón de “aplicar a muchos” como una herramienta eléctrica: útil, pero diseñada para evitar deslices.
Un buen predeterminado es mostrar una vista previa primero y luego ejecutar. En lugar de ejecutar de inmediato, muestra qué cambiaría y permite que el operador confirme solo después de ver el alcance.
Haz el alcance explícito y difícil de malinterpretar. No aceptes “todo” como una idea vaga. Obliga al operador a definir filtros como tenant, estado y rango de fechas, y luego muestra el número exacto de registros que coinciden. Una pequeña lista de muestra (incluso 10 ítems) ayuda a que la gente note errores como “región equivocada” o “incluye archivados”.
Un patrón práctico que funciona bien:
- Empieza con una pantalla de ejecución en seco que muestre conteo, filtros y una muestra breve de registros afectados
- Requiere una elección de alcance explícita (por ejemplo: “Solo clientes Activos en Tenant A, creados antes de 2024-01-01”)
- Limita cada ejecución (por ejemplo 1.000 registros) y pide ejecutar de nuevo para el siguiente lote
- Ralentiza los cambios para que un mal clic no sobrecargue la base de datos ni sistemas downstream
- Ejecuta como un trabajo en cola con progreso, logs y una opción clara de cancelar
Los trabajos en cola superan al “disparar y olvidar” porque crean rastro y dan al operador la posibilidad de detener la acción si nota algo raro al 5% completado.
Ejemplo: un operador quiere deshabilitar cuentas de usuario masivamente tras un pico de fraude. La vista previa muestra 842 cuentas, pero la muestra incluye clientes VIP. Esa pista pequeña muchas veces evita el error real: un filtro que omitió “fraud_flag = true”.
Si estás montando una consola interna rápidamente (incluso con una plataforma conversacional como Koder.ai), incorpora estos patrones desde temprano. Ahorran más tiempo del que suman.
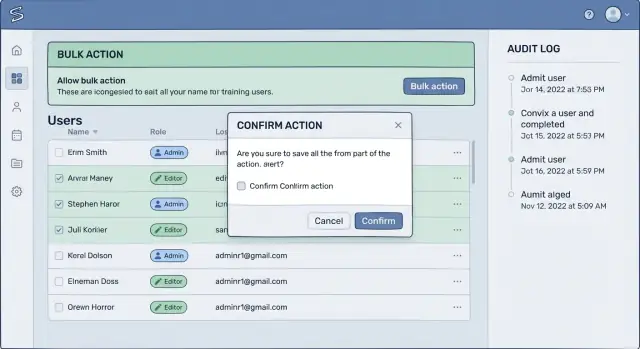
Flujos de confirmación que la gente realmente lee
La mayoría de las confirmaciones fallan porque son demasiado genéricas. Si la pantalla dice “¿Estás seguro?”, la gente hace clic por inercia. Una confirmación que funciona usa las mismas palabras que tu usuario usaría para explicar el resultado a un compañero.
Reemplaza etiquetas vagas como “Eliminar” o “Aplicar” por el impacto real: “Desactivar 38 cuentas”, “Quitar acceso para este tenant” o “Anular 12 facturas”. Esta es una de las mejoras más sencillas para evitar pérdida de datos, porque convierte un clic reflejo en un momento de reconocimiento.
Haz que el usuario confirme el alcance
Un buen flujo fuerza una comprobación mental rápida: “¿Es esto lo correcto, sobre el conjunto correcto de registros?” Pon el alcance en la confirmación, no solo en la página detrás. Incluye el nombre del tenant o workspace, el conteo de registros y cualquier filtro como rango de fechas o estado.
Por ejemplo: “Cerrar cuentas para Tenant: Acme Retail. Conteo: 38. Filtro: último inicio de sesión antes de 2024-01-01.” Si alguno de esos valores está mal, el usuario lo detecta antes de que ocurra el daño.
Cuando la acción es verdaderamente destructiva, exige un acto pequeño y deliberado. Las confirmaciones escritas funcionan bien cuando el costo del error es alto.
- Pide una frase corta como DELETE 38 ACCOUNTS
- O pide que escriban exactamente el nombre del tenant
- O exige reingresar el conteo mostrado en pantalla
Usa dos pasos solo cuando el impacto sea alto
Las confirmaciones en dos pasos deben ser raras, o los usuarios las ignorarán. Guárdalas para acciones difíciles de recuperar, que cruzan tenants o afectan dinero. El paso uno confirma intención y alcance. El paso dos confirma el momento, como “Ejecutar ahora” vs “Programar”, o requiere una autorización con mayor permiso.
Finalmente, evita “OK/Cancelar”. Los botones deben decir lo que ocurre: “Desactivar cuentas” y “Volver”. Esto reduce clics equivocados y hace que la decisión se sienta real.
Eliminaciones suaves, restauraciones y reglas de retención
Planifica las protecciones primero
Diseña roles, confirmaciones y reglas de retención antes de generar la primera pantalla.
La eliminación suave es la opción más segura por defecto para la mayoría de registros visibles al usuario: cuentas, pedidos, tickets, publicaciones e incluso pagos. En lugar de quitar la fila, márcala como eliminada y escóndela de las vistas normales. Este es uno de los patrones más simples para prevenir pérdida de datos, porque los errores se vuelven reversibles.
Una política de eliminación suave necesita una ventana de retención clara y una propiedad definida. Decide cuánto tiempo los elementos eliminados son recuperables (por ejemplo, 30 o 90 días) y quién puede devolverlos. Ata los derechos de restauración a roles, no a individuos, y trata las restauraciones como cambios en producción.
Haz la restauración visible (y registrada)
Restaurar debe ser fácil de encontrar cuando alguien está viendo un registro eliminado, no enterrado en una pantalla separada. Añade un estado visible como “Eliminado”, muestra cuándo pasó y quién lo hizo. Cuando se restaura, regístralo como un evento aparte, no como una edición del borrado original.
Una forma rápida de definir tus reglas de retención es responder estas preguntas:
- ¿Cuál es el período de retención por defecto por tipo de objeto?
- ¿Qué rol puede restaurar y necesita dar una razón?
- ¿Qué pasa cuando expira el período de retención?
- ¿Quién puede extender la retención por motivos legales o de facturación?
- ¿Cómo manejas solicitudes de “eliminar mis datos”?
Casos límite que rompen las restauraciones
La eliminación suave suena fácil hasta que restaurar choca con un mundo que ha cambiado. Las restricciones de unicidad pueden colisionar (un nombre de usuario fue reutilizado), faltan referencias (se eliminó el registro padre) y el historial de facturación debe permanecer consistente aunque el usuario “no exista”. Un enfoque práctico es mantener libros contables inmutables (facturas, eventos de pago) separados de los datos de perfil de usuario, y restaurar relaciones con cuidado, mostrando advertencias cuando una restauración completa no sea posible.
La eliminación permanente debe ser rara y explícita. Si la permites, que se sienta como una excepción, con una ruta de aprobación corta:
- Requerir un rol más alto que el de eliminación suave
- Pedir una confirmación escrita y un motivo
- Poner la eliminación en cola con un retraso (por ejemplo, 24 horas)
- Notificar a un propietario o canal on-call
- Mantener un registro final incluso después de la eliminación
Si construyes tu admin sobre una plataforma como Koder.ai, define eliminación suave, restauración y retención como acciones de primera clase desde temprano, para que sean consistentes en todas las pantallas y flujos generados.
Auditabilidad: haz las acciones explicables después
Los accidentes pasan en paneles administrativos, pero el verdadero daño muchas veces viene después: nadie puede responder qué cambió, quién lo hizo y por qué. Si quieres herramientas administrativas que eviten la pérdida de datos, trata los logs de auditoría como parte del producto, no como un remedo para depurar.
Empieza registrando acciones de forma que un humano pueda leerlas. “Usuario 183 actualizó registro 992” no es suficiente cuando un cliente está molesto y la persona on-call intenta arreglarlo rápido. Los buenos logs capturan identidad, tiempo, alcance e intención, además de suficiente detalle para revertir o al menos entender el impacto.
Qué registrar (para que sea útil después)
Una línea base práctica es:
- Quién lo hizo (usuario, rol e información de suplantación si se usó)
- Qué y dónde (nombre de la acción, tenant/cuenta y tipos de objetos afectados)
- Cuándo y desde dónde (timestamp, zona horaria, IP o ID de sesión/dispositivo)
- Qué cambió (antes/después para campos clave, o un diff para objetos grandes)
- Por qué pasó (razón en texto libre y un ID de ticket opcional)
Las acciones masivas merecen un trato especial. Regístralas como un solo “job” con un resumen claro (cuántos seleccionados, cuántos tuvieron éxito, cuántos fallaron) y almacena también resultados por ítem. Esto facilita responder: “¿Reembolsamos 200 pedidos o solo 173?” sin buscar en un muro de entradas.
Haz que los logs sean fáciles de buscar: por usuario admin, tenant, tipo de acción y rango de tiempo. Incluye filtros para “solo trabajos masivos” y “acciones de alto riesgo” para que los revisores puedan detectar patrones.
No impongas burocracia. Un campo corto de “razón” que soporte plantillas (“Cliente solicitó cierre”, “Investigación de fraude”) se completa más seguido que un formulario largo. Si hay un ticket de soporte, deja pegar el ID.
Finalmente, planea el acceso de lectura. Muchos usuarios internos necesitan ver logs, pero solo un grupo pequeño debe ver campos sensibles (como valores completos antes/después). Separa “puede ver resúmenes de auditoría” de “puede ver detalles” para reducir exposición.
Límites y salvaguardas basadas en roles
La mayoría de los accidentes suceden porque los permisos son demasiado amplios. Si todos son efectivamente admins, un operador cansado puede causar daño permanente con un solo clic. La meta es simple: hacer el camino seguro el predeterminado y hacer que las acciones riesgosas requieran intención extra.
Diseña roles alrededor de trabajos reales, no de títulos. Un agente de soporte que responde tickets no necesita el mismo acceso que quien administra reglas de facturación.
Construye roles alrededor de tareas
Empieza separando lo que la gente puede ver de lo que puede cambiar. Un conjunto práctico de roles internos podría ser:
- Solo lectura: ver usuarios, pedidos y logs
- Operador: editar perfiles y resetear contraseñas
- Operador de facturación: emitir reembolsos dentro de un límite
- Custodio de datos: fusionar registros y ejecutar correcciones masivas
- Admin de seguridad: deshabilitar cuentas y gestionar roles
Esto mantiene el “borrado” fuera del trabajo diario y reduce el radio de impacto cuando alguien se equivoca.
Para las acciones más peligrosas, añade un modo elevado. Piénsalo como una llave con tiempo limitado. Para entrar en modo elevado, exige un paso más fuerte (reautenticación, aprobación de manager o una segunda persona) y asegúrate de que se venza automáticamente después de 10 a 30 minutos.
Los guardarraíles del entorno también salvan equipos. La UI debe dificultar confundir staging con producción. Usa señales visuales llamativas, muestra el nombre del entorno en cada encabezado y desactiva acciones destructivas en entornos no productivos a menos que las actives explícitamente.
Finalmente, protege los tenants entre sí. En sistemas multi-tenant, los cambios entre tenants deben estar bloqueados por defecto y solo habilitados para roles específicos con un cambio de tenant explícito y una confirmación visible.
Si construyes sobre Koder.ai, trata estos guardarraíles como características del producto, no como remiendos. Las herramientas administrativas que previenen la pérdida de datos suelen ser simplemente un buen diseño de permisos más algunos topes de velocidad bien ubicados.
Un escenario realista: reembolsos masivos y cierres de cuenta
Previsualiza antes de ejecutar
Añade un paso de ejecución en seco que muestre filtros, conteos y una muestra antes de ejecutar.
Un agente de soporte necesita manejar una interrupción de pagos. El plan es simple: reembolsar pedidos afectados y luego cerrar las cuentas que pidieron la cancelación. Aquí es exactamente donde las herramientas administrativas que previenen la pérdida de datos demuestran su valor, porque el agente va a ejecutar dos acciones masivas de alto impacto una tras otra.
El riesgo aparece en un detalle minúsculo: el filtro. El agente selecciona “Pedidos creados en las últimas 24 horas” en lugar de “Pedidos pagados durante la ventana de la caída”. En un día ocupado, eso podría incluir miles de clientes normales y desencadenar reembolsos que nunca pidieron. Si el siguiente paso es “Cerrar cuentas por pedidos reembolsados”, el daño se propaga rápido.
Antes de que la herramienta ejecute nada, la UI debe forzar una pausa con una vista previa clara que coincida con cómo piensa la gente, no con cómo piensa la base de datos. Por ejemplo, debe mostrar:
- Total de cuentas que se cerrarán (y cuántas ya están cerradas)
- Importe total de reembolso, más importes mínimo/máximo
- Una muestra pequeña y desplazable de clientes afectados (nombres, emails, IDs de pedido)
- Excepciones y saltos (pagos fallidos, ya reembolsados, pedidos disputados)
- El resumen exacto del filtro en lenguaje simple, con un botón evidente de “Editar filtro”
Luego añade una segunda confirmación separada para el cierre de cuentas, porque es un daño de otro tipo. Un buen patrón es exigir escribir una frase corta como “CLOSE 127 ACCOUNTS” para que el agente note si el número está mal.
Si “cerrar cuenta” es una eliminación suave, la recuperación es realista. Puedes restaurar las cuentas, mantener los accesos bloqueados y establecer una regla de retención (por ejemplo, purga automática después de 30 días) para que no se convierta en basura permanente.
Los logs de auditoría son lo que hace posible la limpieza y la investigación después. El manager debe ver quién lo ejecutó, el filtro exacto, los totales de la vista previa mostrados en ese momento y la lista de registros afectados. Los límites por rol también importan: los agentes pueden emitir reembolsos hasta un tope diario, pero solo un manager puede cerrar cuentas o aprobar cierres por encima de un umbral.
Si construyes este tipo de consola en Koder.ai, características como snapshots y rollback son guardarraíles útiles adicionales, pero la primera línea de defensa sigue siendo la vista previa, las confirmaciones y los roles.
Paso a paso: meter seguridad en un admin existente
Retrofitar seguridad funciona mejor cuando tratas tu admin como un producto, no como un conjunto de páginas internas. Elige primero un flujo de alto riesgo (como deshabilitar usuarios masivamente) y avanza paso a paso.
Un plan práctico de retrofitting
Empieza listando las pantallas y endpoints que pueden borrar, sobrescribir o mover dinero. Incluye riesgos “ocultos” como importaciones CSV, ediciones masivas y scripts que los operadores ejecutan desde la UI.
Luego haz las acciones masivas más seguras obligando a definir alcance y mostrar una vista previa. Muestra exactamente qué registros coinciden con los filtros, cuántos cambiarán y una muestra pequeña de IDs antes de ejecutar.
A continuación, reemplaza eliminaciones permanentes por eliminación suave donde puedas. Guarda una bandera de eliminado, quién lo hizo y cuándo. Añade una vía de restauración tan fácil de usar como eliminar, además de reglas de retención claras (por ejemplo, “recuperable por 30 días”).
Después de eso, añade un registro de auditoría y siéntate con los operadores a revisar entradas reales. Si una línea de log no puede responder “qué cambió, de qué a qué y por qué”, no ayudará durante incidentes.
Finalmente, ajusta roles y añade aprobaciones para acciones de alto impacto. Por ejemplo, permite a soporte emitir reembolsos hasta un límite pequeño, pero requiere una segunda persona para importes grandes o cierres de cuenta. Así las herramientas administrativas que previenen la pérdida de datos siguen siendo útiles sin dar miedo.
Ejemplo rápido
Un operador necesita cerrar 200 cuentas inactivas. Antes del cambio, hacen clic en “Eliminar” y esperan que los filtros estén correctos. Después del retrofit, deben confirmar la consulta exacta (“status=inactive, last_login>365d”), revisar el conteo y la lista de muestra, elegir “Cerrar (restaurable)” en lugar de eliminar y escribir un motivo.
Un buen estándar de “hecho” es:
- Puedes previsualizar y exportar el conjunto afectado antes de ejecutar.
- Puedes deshacer (restaurar o rollback) dentro de una ventana definida.
- Cada acción es atribuible a una persona y una razón.
- Las acciones de alto impacto están limitadas por rol o requieren aprobación.
Si creas herramientas internas en una plataforma guiada por chat como Koder.ai, añade estos guardarraíles como componentes reutilizables para que nuevas páginas de admin hereden valores más seguros.
Errores comunes que siguen llevando a accidentes
Escala tu construcción
Pasa de Free a Pro o Business cuando necesites más capacidad para herramientas internas.
Muchos equipos construyen en teoría herramientas administrativas que previenen la pérdida de datos y luego pierden datos en la práctica porque las funciones de seguridad son fáciles de ignorar o difíciles de usar.
La trampa más común es la confirmación única para todo. Si cada acción muestra el mismo “¿Estás seguro?” la gente deja de leerlo. Peor aún, algunos equipos añaden más confirmaciones para “arreglar” errores, lo que entrena a los operadores a clicar más rápido.
Otro problema es la falta de contexto en el momento en que importa. Una acción destructiva debe mostrar claramente en qué tenant o workspace estás, si es producción o un entorno de prueba y cuántos registros serán tocados. Cuando esa información está enterrada en otra pantalla, la herramienta está pidiendo un mal día.
Las acciones masivas también son peligrosas cuando se ejecutan al instante sin seguimiento. Los operadores necesitan un registro claro del trabajo: qué se ejecutó, con qué filtro, quién lo inició y qué hizo el sistema ante errores. Sin eso, no puedes pausar, deshacer o siquiera explicar lo ocurrido.
Estos son errores que aparecen una y otra vez:
- Usar el mismo texto de confirmación para eliminaciones, reembolsos y cambios de permisos
- Añadir confirmaciones con tanta frecuencia que la gente pasa por ellas en piloto automático
- No mostrar el conteo de registros, el tenant y el entorno en la pantalla de confirmación
- Ejecutar acciones masivas al instante sin vista previa, sin página de trabajo y sin forma de detener
- Mantener logs de auditoría, pero no hacerlos buscables por usuario, registro o tiempo
Un ejemplo rápido: un operador pretende desactivar 12 cuentas en un tenant sandbox, pero la herramienta usa por defecto el último tenant usado y lo oculta en el encabezado. Ejecutan la acción, ésta se realiza al instante y el único “registro” es una entrada vaga como “actualización masiva completada”. Cuando alguien lo nota, no es fácil saber qué cambió ni restaurarlo.
Una buena seguridad no son más popups. Es contexto claro, confirmaciones significativas y acciones que puedas rastrear y revertir.
Lista de verificación rápida y siguientes pasos
Antes de lanzar una acción destructiva, haz una última revisión con ojos frescos. La mayoría de incidentes administrativos ocurren cuando una herramienta permite actuar sobre el alcance equivocado, oculta el impacto real o no ofrece una forma clara de volver atrás.
Aquí tienes una lista de predespliegue para herramientas administrativas que previenen la pérdida de datos:
- Alcance + vista previa: muestra exactamente qué cambiará (quién, qué, dónde). Incluye una vista legible y una muestra de registros.
- Conteos + límites: muestra el número total de ítems e impone topes sensatos (y límites de tasa) para que un clic no toque “todo”.
- Chequeos de contexto: obliga al operador a confirmar el tenant/cuenta, el entorno (prod vs test) y a añadir una breve razón que aparecerá en los logs.
- Ruta de recuperación: prefiere eliminación suave cuando puedas, confirma que la restauración funciona y define la retención (cuánto tiempo es posible recuperar).
- Responsabilidad: registra quién hizo qué, cuándo, desde dónde y con qué filtros. Haz los logs buscables y asegura que los roles correspondan a responsabilidades reales.
Si eres operador, haz una pausa de diez segundos y repite la herramienta en voz baja: “Estoy actuando sobre el tenant X, cambiando N registros, en producción, por la razón Y.” Si algo no está claro, detente y pide una UI más segura antes de ejecutar.
Siguientes pasos: prototipa flujos más seguros rápidamente en Koder.ai usando Planning Mode para esbozar pantallas y guardarraíles primero. Mientras pruebas, usa snapshots y rollback para intentar casos reales sin miedo. Cuando el flujo esté sólido, exporta el código fuente y despliega cuando estés listo.