02 jun 2025·8 min
Crear una aplicación web para gestionar solicitudes de comunicación entre equipos
Aprende a planear, diseñar y construir una aplicación web que recopile, dirija y haga seguimiento de solicitudes de comunicación entre equipos con propiedad clara, estados y SLAs.
Definir el problema y el alcance
Antes de construir nada, especifica qué intentas resolver. “Comunicación entre equipos” puede significar desde un mensaje rápido en Slack hasta un anuncio de lanzamiento de producto. Si el alcance es difuso, la aplicación se convertirá en un vertedero —o nadie la usará.
¿Qué es una “solicitud de comunicación” aquí?
Escribe una definición simple que la gente pueda recordar, más algunos ejemplos y no‑ejemplos. Los tipos de solicitud típicos incluyen:
- Anuncios hacia clientes (mantenimiento, cambios de política)
- Aprobaciones de respuestas de soporte para casos sensibles
- Notas de lanzamiento y changelogs
- Actualizaciones para ventas (nuevos precios, posicionamiento)
- Declaraciones revisadas por ejecutivos o legal
También documenta qué no pertenece (por ejemplo, lluvia de ideas ad-hoc, actualizaciones informativas generales, o “¿puedes entrar a una llamada?”). Un límite claro evita que el sistema se convierta en una bandeja genérica.
¿Quién está involucrado y qué rol desempeña?
Lista los equipos que intervienen en las solicitudes y la responsabilidad de cada uno:
- Solicitante (envía la necesidad, aporta contexto y recursos)
- Aprobador (confirma prioridad, riesgos, cumplimiento y mensaje)
- Ejecutor (redacta/produce el contenido, publica o envía)
- Revisor (verificación final de precisión, tono y marca)
Si un rol varía según el tipo de solicitud (por ejemplo, Legal solo en ciertos temas), regístralo ahora: esto guiará las reglas de enrutamiento más adelante.
¿Cómo sabrás que funcionó?
Elige algunos resultados medibles, como:
- Menos “¿alguna actualización?” en chat
- Menor tiempo desde la solicitud hasta la publicación
- Menos solicitudes perdidas o duplicadas
Finalmente, escribe los puntos de dolor actuales en lenguaje llano: propiedad poco clara, información faltante, solicitudes de último minuto y solicitudes ocultas en DMs. Esto será tu línea base —y tu justificación para el cambio.
Mapear el flujo y los user stories
Antes de construir, alinea a los interesados sobre cómo una solicitud pasa de “alguien necesita ayuda” a “trabajo entregado”. Un mapa de flujo simple evita complejidad accidental y resalta dónde suelen romperse las transiciones.
Historias de usuario (sé específico)
Aquí tienes cinco historias iniciales que puedes adaptar:
- Como solicitante, envío un breve resumen y veo de inmediato quién lo gestiona y cuándo puedo esperar una fecha de entrega.
- Como responsable de triage, puedo validar rápidamente la solicitud, hacer una pregunta de seguimiento o rechazarla con una razón clara.
- Como aprobador, puedo revisar la solicitud, aprobar/declinar y dejar un comentario que quede en el registro.
- Como programador/publicador, puedo situar el trabajo aprobado en un calendario, detectar conflictos y confirmar la fecha de publicación.
- Como interesado, puedo seguir el estado y las actualizaciones sin perseguir a la gente en chat.
Mapear el ciclo de vida de la solicitud
Un ciclo de vida común para una app de gestión de solicitudes de comunicación entre equipos es:
enviar → triage → aprobar → programar → publicar → cerrar
Para cada paso, anota:
- Criterios de entrada (qué debe ser cierto para comenzar)
- Propietario (persona o rol)
- Resultado esperado (qué significa “hecho”)
- Salidas permitidas (avanzar, devolver para ediciones, rechazar)
Decisiones configurables vs. fijas
Haz configurables: equipos, categorías, prioridades y preguntas del intake por categoría. Mantén fijas (al menos al principio): las statuses principales y la definición de “cerrado.” Demasiada configurabilidad temprano dificulta el reporte y la capacitación.
Pasos de mayor riesgo que diseñar con cuidado
Vigila puntos de fallo: aprobaciones que se estancan, conflictos de programación entre canales y revisiones de cumplimiento/legal que requieren rastro de auditoría y propiedad estricta. Estos riesgos deben moldear directamente tus reglas de flujo y transiciones de estado.
Diseñar el formulario de ingreso (obtener la información correcta desde el inicio)
Una app de solicitudes solo funciona si el formulario captura consistentemente un brief utilizable. La meta no es pedirlo todo, sino pedir lo correcto para que tu equipo no pase días persiguiendo aclaraciones.
Comienza con el brief mínimo viable
Mantén la primera pantalla concisa. Como mínimo, recopila:
- Título de la solicitud (resumen en una frase)
- Descripción (qué necesitas y por qué)
- Audiencia (a quién va dirigido)
- Canal (email, en‑app, redes, prensa, etc.)
- Fecha deseada (cuándo debe salir)
- Adjuntos (borrador, creativos, capturas, notas legales)
Añade texto de ayuda corto bajo cada campo, por ejemplo: “Ejemplo de audiencia: ‘Todos los clientes US en plan Pro’.” Estos micro‑ejemplos reducen la ida y vuelta más que guías largas.
Campos útiles que previenen retrabajo
Una vez que lo básico esté estable, incluye campos que faciliten priorización y coordinación:
- Prioridad (por ejemplo, Baja/Media/Alta)
- Impacto en el negocio (qué cambia si no se lanza)
- Enlaces (PRD, ticket de Jira, analítica, documento de marca)
- Stakeholders (aprobador y partes informadas)
- Idioma/región (si aplica localización o reglas regionales)
Usa preguntas condicionales para mantenerlo corto y completo
La lógica condicional mantiene el formulario ligero. Ejemplos:
- Si Canal = Prensa, solicita portavoz, fecha de embargo y lista de medios.
- Si Audiencia incluye Clientes, pregunta por criterios de segmentación y preparación de soporte.
Validar para completitud (sin ser molesto)
Usa reglas de validación claras: campos obligatorios, fecha no puede estar en el pasado, adjuntos obligatorios para prioridad “Alta” y mínimo de caracteres para la descripción.
Cuando rechaces una presentación, devuélvela con orientación específica (por ejemplo, “Añade audiencia objetivo y enlace al ticket fuente”), para que los solicitantes aprendan el estándar esperado con el tiempo.
Crear estados, propiedad y reglas claras
Una app de gestión solo funciona cuando todos confían en el estado. Eso significa que la app debe ser la fuente única de verdad, no un “estado real” oculto en conversaciones laterales, DMs o correos.
Define un conjunto de estados simple y compartido
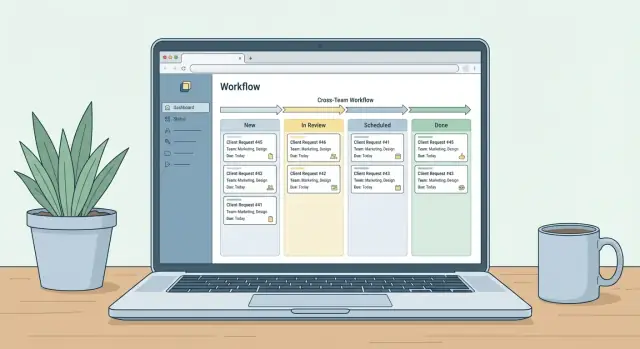
Mantén los estados pocos, inequívocos y ligados a acciones. Un conjunto práctico por defecto para solicitudes de comunicación entre equipos es:
- Nuevo — enviado y en espera de triage
- Necesita información — bloqueado hasta que el solicitante aporte datos
- En revisión — evaluándose factibilidad, prioridad o política
- Aprobado — aceptado y listo para planificar
- Programado — asignado a una fecha/hito
- Hecho — entregado y cerrado
- Rechazado — declinado con una razón registrada
La clave es que cada estado responda: ¿Qué sigue y quién espera a quién?
Asigna propietarios por paso (para que nada quede flotando)
Cada estado debe tener un “propietario” claro:
- Responsable de triage (a menudo un on‑call rotativo) asegura que cada Nuevo sea atendido rápido.
- Aprobador toma la decisión durante En revisión.
- Asignado se encarga de la entrega una vez Aprobado/Programado.
La propiedad evita el fallo común donde todos están “involucrados” pero nadie es responsable.
Escribe reglas que prevengan el caos de estados
Añade reglas ligeras directamente en la app:
- Quién puede mover una solicitud (por ejemplo, solo triage puede salir de Nuevo; solo aprobadores pueden poner Aprobado/Rechazado).
- Cuándo puede reabrirse (por ejemplo, permitir reabrir desde Hecho solo dentro de 14 días y requiriendo una razón).
- Qué se requiere por transición (por ejemplo, mover a Programado requiere fecha; mover a Rechazado requiere justificación).
Estas reglas mantienen el reporte preciso, reducen la ida y vuelta y hacen predecibles los traspasos entre equipos.
Planificar el modelo de datos y campos clave
Un modelo de datos claro mantiene tu sistema flexible conforme aparecen nuevos equipos, tipos de solicitud y pasos de aprobación. Apunta a un pequeño conjunto de tablas núcleo que soporten muchos flujos, en vez de crear un esquema nuevo por cada equipo.
Tablas núcleo (comienza simple)
Como mínimo, planifica estas:
- Usuarios: nombre, email, rol, indicador activo
- Equipos: nombre del equipo, política SLA por defecto, reglas de enrutamiento
- Solicitudes: el “ticket” en sí (detalles más abajo)
- Comentarios: conversación enhebrada ligada a una solicitud
- Adjuntos: archivos o enlaces, con quien subió y timestamp
- HistorialDeEstado: cada cambio de estado (y de preferencia también cambios de propietario)
Esta estructura soporta traspasos entre equipos y facilita el reporting mucho más que depender solo del “estado actual”.
Campos clave en el registro de Solicitud
Tu tabla Solicitudes debe capturar lo básico para enrutamiento y responsabilidad:
- equipo_solicitante y/o usuario_solicitante
- categoría (campaña, anuncio, prensa, revisión legal, etc.)
- prioridad (o impacto/urgencia)
- fecha_deseada (lo que pide el solicitante)
- sla_target_at (fecha límite calculada según la política SLA)
- estado_actual
- propietario_actual_usuario (o equipo propietario + asignado)
Considera también: resumen/título, descripción, canales solicitados (email, Slack, intranet) y activos requeridos.
Etiquetas + búsqueda para filtrado real
Añade tags (muchos a muchos) y un campo texto_buscable (o columnas indexadas) para que los equipos filtren colas con rapidez y reporten tendencias (por ejemplo, “lanzamiento-de-producto” o “urgente‑ejecutivo”).
La auditabilidad no es opcional
Planifica necesidades de auditoría desde el inicio:
- Guarda created_at / updated_at / closed_at
- Mantén HistorialDeEstado con quién cambió qué y cuándo
- Conserva valores previos para campos críticos (estado, propietario, fechas)
Cuando pregunten “¿Por qué esto llegó tarde?” tendrás una respuesta clara sin hurgar en logs de chat.
Diseñar las pantallas principales y la navegación
Haz que tu desarrollo sea rentable
Comparte lo que construiste con Koder.ai y gana créditos por contenido o referidos.
Una buena navegación no es decoración: es cómo evitas que “¿Dónde lo miro?” se vuelva el flujo real. Diseña pantallas según los roles naturales en el trabajo de solicitudes y mantén cada vista centrada en la siguiente acción.
Vista del solicitante (enviar y hacer seguimiento)
La experiencia del solicitante debe sentirse como rastrear un paquete: clara, serena y siempre actual. Tras enviar, muestra una página única de la solicitud con estado, propietario, fechas objetivo y el próximo paso esperado.
Facilita:
- Enviar una solicitud y adjuntar activos
- Ver progreso en el tiempo (una línea de tiempo sencilla funciona)
- Responder rápido a Necesita información con comentarios/archivos
- Recibir actualizaciones sin buscar (email + en‑app)
Vista de triage (cola y decisiones)
Aquí está la sala de control. Por defecto muestra una cola con filtros (equipo, categoría, estado, prioridad) y acciones en lote.
Incluye:
- Una cola priorizada con “tiempo en estado” visible
- Asignar y reasignar rápido
- Detección de duplicados (coincidencia por título + solicitante + enlaces)
- Controles de prioridad y fecha límite sin abrir cada solicitud
Vista del ejecutor (hacer el trabajo)
Los ejecutores necesitan una pantalla de carga personal: “Qué es mío, qué sigue, qué está en riesgo”. Muestra fechas próximas, dependencias y una checklist de activos para evitar idas y vueltas.
Vista de administrador (configurar sin romper el flujo)
Los admins deben gestionar equipos, categorías, permisos y SLAs desde un área de ajustes. Mantén las opciones avanzadas a un clic y ofrece valores por defecto seguros.
Navegación consistente
Usa una navegación lateral (o pestañas superiores) que mapee a áreas por rol: Solicitudes, Cola, Mi trabajo, Reportes, Ajustes. Si un usuario tiene varios roles, muestra todas las secciones relevantes pero haz que la pantalla inicial sea acorde al rol (por ejemplo, los triagers aterrizan en Cola).
Permisos, seguridad y auditabilidad
Los permisos no son solo requisitos de TI: son la forma de evitar compartir información por error y mantener el flujo sin confusiones. Comienza simple y ajusta conforme aprendes lo que los equipos realmente necesitan.
Acceso basado en roles (predecible)
Define un pequeño conjunto de roles y haz cada uno obvio en la interfaz:
- Solicitante: puede enviar, ver sus propias solicitudes, responder preguntas y ver estado.
- Miembro de equipo (ejecutor): puede ver la cola de su equipo, comentar, pedir cambios y actualizar estado.
- Aprobador: puede aprobar/rechazar pasos específicos (por ejemplo, sign‑off de comunicaciones o revisión legal).
- Admin: gestiona plantillas, campos, equipos y reglas de permiso.
Evita “casos especiales” al principio. Si alguien necesita acceso extra, trátalo como un cambio de rol, no como una excepción puntual.
Proteger solicitudes sensibles sin frenar a todos
Usa visibilidad por equipo por defecto: una solicitud es visible para el solicitante más los equipos asignados. Luego añade dos opciones:
- Campos privados (por ejemplo, presupuesto, datos de empleados) visibles solo para roles específicos.
- Solicitudes restringidas donde solo un grupo nombrado puede acceder al registro completo.
Esto mantiene la colaboración habitual mientras protege casos excepcionales.
Decidir cómo trabajan los invitados (si aplica)
Si necesitas revisores externos u otros stakeholders ocasionales, elige un modelo:
- Enlaces de solo lectura con expiración (útil para compartir un borrador final).
- Cuentas requeridas (mejor para aprobaciones, comentarios y trazabilidad).
Mezclar ambos puede funcionar, pero documenta cuándo se permite cada uno.
Auditabilidad: hacer la rendición automática
Registra acciones clave con timestamp y actor: cambios de estado, ediciones a campos críticos, aprobaciones/rechazos y confirmación final de publicación. Haz que el rastro de auditoría sea fácil de exportar para cumplimiento y lo bastante visible para que los equipos confíen en la historia sin preguntar.
Notificaciones y recordatorios que no generan ruido
Construye el MVP en chat
Convierte tu mapa de flujo de trabajo en una app de solicitudes funcional a partir de una especificación de chat estructurada.
Las notificaciones deben impulsar una solicitud, no crear una segunda bandeja que la gente ignore. La meta es simple: decirle a la persona correcta lo correcto en el momento correcto, con un siguiente paso claro.
Notificar solo en eventos clave del flujo
Comienza con un conjunto corto de eventos que cambian directamente lo que alguien debe hacer:
- Enviado (confirmación al solicitante + “qué sigue”)
- Asignado (el responsable recibe contexto + enlace)
- Necesita información (el solicitante recibe preguntas específicas y una fecha límite)
- Aprobado/declinado (solicitante + equipo descendente si aplica)
- Próximo a vencerse y vencido (propietario + posible escalado a manager)
Si un evento no desencadena una acción, mantenlo en el log de actividad en vez de notificarlo.
Elige 1–2 canales y hazlos bien
Evita dispersar actualizaciones a todos lados. La mayoría de los equipos triunfa empezando con un canal principal (a menudo correo) más un canal en tiempo real (Slack/Teams) para propietarios.
Una regla práctica: usa mensajes en tiempo real para trabajo que posees, y email para visibilidad y registros. Las notificaciones en la app son útiles cuando la gente vive diariamente en la herramienta.
Reglas de recordatorio que reducen el ruido
Los recordatorios deben ser predecibles y configurables:
- Resúmenes diarios o dos veces por semana para “necesita info” y “esperando por ti”
- Horas de silencio (sin pings fuera del horario; enviar por la mañana siguiente)
- Escalar solo tras un umbral claro (por ejemplo, 48 horas de retraso)
Usa plantillas para que las actualizaciones sean accionables
Las plantillas mantienen los mensajes consistentes y escaneables. Cada notificación debe incluir:
- Título + ID de la solicitud
- Estado actual y propietario
- Qué cambió
- Un único CTA claro (por ejemplo, “Añadir info”, “Revisar”, “Marcar completado”)
Esto hace que cada mensaje parezca progreso en lugar de ruido.
SLAs, fechas de entrega y programación
Si las solicitudes no se envían a tiempo, la causa suele ser expectativas poco claras: “¿Cuánto debe tardar esto?” y “¿Para cuándo?” Integra tiempo en el flujo para que sea visible, consistente y justo.
Define SLAs por tipo de solicitud
Establece expectativas de servicio acordes al trabajo. Por ejemplo:
- Anuncios: 5 días hábiles
- Elementos de newsletter: 3 días hábiles
- Comunicaciones ejecutivas: 10 días hábiles
Haz que el campo SLA sea conducido por la selección: en cuanto el solicitante elige un tipo, la app muestra el tiempo de entrega esperado y la fecha de publicación más temprana viable.
Calcula automáticamente las fechas objetivo
Evita cálculos manuales. Guarda dos fechas:
- Fecha de publicación deseada (lo que pide el solicitante)
- Fecha objetivo de finalización (lo que el equipo se compromete)
Luego calcula la fecha objetivo usando el tiempo de entrega del tipo de solicitud (días hábiles) y los pasos necesarios (por ejemplo, aprobaciones). Si alguien cambia la fecha de publicación, la app debe actualizar inmediatamente la fecha objetivo y marcar “plazo ajustado” cuando la fecha solicitada sea anterior a la factible.
Programación para prevenir colisiones
Una cola sola no muestra conflictos. Añade una vista de calendario sencilla que agrupe ítems por fecha de publicación y canal (email, intranet, redes, etc.). Esto ayuda a detectar sobrecarga (muchos envíos el martes) y negociar alternativas antes de comenzar el trabajo.
Registrar razones de retraso
Cuando una solicitud se retrasa, captura una única “razón de demora” para que el reporting sea accionable: esperando al solicitante, esperando aprobaciones, capacidad, o cambio de alcance. Con el tiempo, esto convierte retrasos en patrones corregibles en lugar de sorpresas recurrentes.
Construir un MVP y elegir un enfoque tecnológico práctico
La forma más rápida de obtener valor es lanzar un MVP pequeño y usable que reemplace chats ad‑hoc y hojas de cálculo, sin intentar resolver todos los casos extremos.
Comienza con un MVP que la gente realmente use
Apunta al conjunto de características más pequeño que soporte un ciclo completo de solicitudes:
- Un formulario de ingreso que capture lo esencial (tipo, audiencia, fecha límite, prioridad, adjuntos)
- Una cola compartida (un lugar para ver “qué está esperando”)
- Estados simples alineados al flujo (por ejemplo: Nuevo → En revisión → Aprobado → Programado → Hecho, con Necesita información y Rechazado como rutas laterales)
- Comentarios y menciones @ para aclaraciones
- Notificaciones básicas (confirmación al solicitante, asignación a propietario, cambios de estado)
Si haces bien eso, reducirás la ida y vuelta inmediatamente y crearás una única fuente de verdad.
Elige una stack que se ajuste a tu equipo (no a la lista de deseos)
Escoge el enfoque que coincida con tus habilidades, velocidad y gobernanza:
- Low-code (entrega más rápida): ideal para formularios + aprobaciones + dashboards sencillos.
- Plataformas de herramientas internas: fuertes para apps autenticadas con tablas, filtros y paneles de admin.
- Desarrollo full‑stack: mejor cuando necesitas integraciones personalizadas, permisos complejos o automatizaciones pesadas.
Si quieres acelerar la ruta full‑stack sin volver a hojas de cálculo frágiles, plataformas como Koder.ai pueden ser útiles para obtener una app interna funcional a partir de una especificación conversacional estructurada. Puedes prototipar el formulario, la cola, roles/permisos y dashboards rápidamente, y luego iterar con stakeholders—manteniendo la opción de exportar código fuente y desplegar según tus políticas.
Implementa búsqueda y filtros desde el inicio
Incluso con 50–100 solicitudes, la gente necesita acotar la cola por equipo, estado, fecha de vencimiento y prioridad. Añade filtros desde el día uno para que la herramienta no se convierta en un scroll interminable.
Añade analítica después (una vez limpios los datos)
Cuando el flujo esté estable, agrega reportes: throughput, tiempo de ciclo, tamaño del backlog y tasa de cumplimiento de SLA. Obtendrás mejores insights cuando los equipos usen consistentemente los mismos estados y reglas de fechas.
Lanzamiento, adopción y plan de iteración
Automatiza la responsabilidad
Mantén un registro de auditoría con historial claro de estados para aprobaciones y cambios de fechas límite.
Una app de solicitudes solo funciona si la gente la usa —y la sigue usando. Trata el primer lanzamiento como una fase de aprendizaje, no como un gran despliegue. Tu objetivo es establecer la nueva “fuente de verdad” para solicitudes de comunicación entre equipos y luego afinar el flujo según el comportamiento real.
Comienza con un piloto pequeño
Pilotea con 1–2 equipos y 1–2 categorías de solicitud. Elige equipos con traspasos frecuentes y un manager que pueda reforzar el proceso. Mantén el volumen manejable para responder rápido a problemas y generar confianza.
Durante el piloto, mantén el proceso antiguo en paralelo solo si es absolutamente necesario. Si las actualizaciones siguen ocurriendo en chat o email, la app nunca será la predeterminada.
Publica guías ligeras
Crea pautas breves que respondan:
- Qué debe enviarse (y qué no)
- Tiempo de anticipación requerido (por ejemplo, “72 horas para solicitudes estándar”)
- Dónde viven las actualizaciones (la app, no los DMs)
Fija las guías en el hub del equipo y enlázalas desde la app (por ejemplo, /help/requests). Hazlas lo bastante cortas para que la gente realmente las lea.
Construye un ciclo de retroalimentación accionable
Recoge feedback semanal de solicitantes y propietarios. Pregunta específicamente sobre campos faltantes, estados confusos y spam de notificaciones. Acompaña esto con una revisión rápida de solicitudes reales: ¿dónde dudaron, abandonaron o eludieron el flujo?
Itera sin romper hábitos
Itera con cambios pequeños y predecibles: ajusta campos del formulario, SLAs y permisos según el uso real. Anuncia cambios en un solo lugar, con una nota “qué cambió / por qué cambió”. La estabilidad fomenta adopción; la reestructuración constante la erosiona.
Si quieres que se mantenga, mide la adopción (solicitudes enviadas por la app vs. fuera), tiempo de ciclo y retrabajo. Usa esos resultados para priorizar la siguiente iteración.
Medir resultados y mejorar con el tiempo
Lanzar la app no es la meta final: es el inicio de un bucle de retroalimentación. Si no mides el sistema, puede convertirse en una “caja negra” donde los equipos dejan de confiar en los estados y vuelven a mensajes laterales.
Comienza con dashboards que la gente realmente use
Crea un conjunto pequeño de vistas que respondan las preguntas diarias:
- Solicitudes abiertas (qué hay en la cola ahora)
- Vencidas (fecha de entrega o SLA pasada)
- Próximas (por vencer para planificar)
- Carga por equipo/propietario (para detectar cuellos de botella y distribución desigual)
Mantén estos dashboards visibles y consistentes. Si los equipos no los entienden en 10 segundos, no los consultarán.
Revisa métricas mensualmente —y decide qué cambiar
Elige una reunión mensual recurrente (30–45 minutos) con representantes de los equipos principales. Úsala para revisar un set corto y estable de métricas, como:
- Tiempo promedio a la primera respuesta
- Tiempo promedio hasta la finalización
- Tasa de cumplimiento de SLA
- Tasa de reapertura (solicitudes que vuelven)
- Volumen por tipo de solicitud
Termina la reunión con decisiones específicas: ajustar SLAs, aclarar preguntas del intake, refinar estados o cambiar reglas de propiedad. Documenta cambios en un changelog simple para que la gente sepa qué cambió.
Mantén una taxonomía ligera
Una taxonomía de solicitudes solo es útil si se mantiene pequeña. Apunta a un puñado de categorías más tags opcionales. Evita crear cientos de tipos que requieran vigilancia constante.
Planifica mejoras basadas en evidencia
Una vez lo básico esté estable, prioriza mejoras que reduzcan trabajo manual:
- Plantillas para solicitudes repetibles
- Integraciones (chat, email, calendario, ticketing)
- Aprobaciones impulsadas por políticas (solo cuando sean necesarias)
- Una API para reportes o para crear solicitudes desde otras herramientas
Deja que el uso y las métricas —no las opiniones— decidan qué construir a continuación.