Qué hace que una app sea centrada en documentos
Una app es centrada en documentos cuando el propio documento es el producto que los usuarios crean, revisan y del que dependen. La experiencia se construye alrededor de archivos como PDF, imágenes, escaneos y recibos, no alrededor de un formulario donde el archivo es solo un adjunto.
En los flujos centrados en documentos, la gente hace trabajo real dentro del documento: lo abre, comprueba qué cambió, añade contexto y decide qué pasa después. Si no se puede confiar en el documento, la app deja de ser útil.
La mayoría de las apps centradas en documentos necesitan unas pantallas principales desde el principio:
- Una bandeja de entrada para nuevas subidas, elementos asignados y cualquier cosa que requiera atención
- Una vista de detalle del documento con vista previa, metadatos, comentarios e historial
- Un flujo de revisión para aprobar, rechazar o solicitar cambios
- Un área de exportación o compartición para pasar el documento a otro sistema
Los problemas aparecen rápido. Los usuarios suben el mismo recibo dos veces. Alguien edita un PDF y lo vuelve a subir sin explicar por qué. Un escaneo no tiene fecha, ni proveedor, ni propietario. Semanas después, nadie sabe qué versión se aprobó ni en qué se basó la decisión.
Una buena app centrada en documentos se siente rápida y fiable. Los usuarios deberían poder responder a estas preguntas en segundos:
- ¿Es esta la última versión y quién la cambió?
- ¿Puedo previsualizarla inmediatamente sin descargarla?
- ¿Qué es, descrito en unos pocos campos sencillos que pueda filtrar?
- ¿En qué estado está ahora y qué acción se espera?
Esa claridad viene de las definiciones. Antes de construir pantallas, decide qué significan “versión”, “preview”, “metadatos” y “estado” en tu app. Si esos términos son difusos, tendrás duplicados, historial confuso y flujos de revisión que no reflejan el trabajo real.
Conceptos centrales para modelar antes de construir la UI
La UI a menudo parece simple (una lista, un visor, unos botones), pero el modelo de datos soporta la carga. Si los objetos básicos son correctos, el historial de auditoría, las previsualizaciones rápidas y las aprobaciones fiables serán mucho más sencillas.
Empieza separando el “registro de documento” del “contenido del archivo”. El registro es de lo que hablan los usuarios (Factura de ACME, Recibo de taxi). El contenido son los bytes (PDF, JPG) que pueden reemplazarse, reprocesarse o moverse sin cambiar lo que el documento significa dentro de la app.
Un conjunto práctico de objetos para modelar:
- Document: la entrada estable que los usuarios buscan, comentan y aprueban
- File: un blob almacenado (PDF/imagen) con tamaño, checksum, clave de almacenamiento y MIME type
- Version: una instantánea del documento en un momento dado, enlazando a uno o varios Files
- Preview: activos derivados (miniatura, imagen de la primera página, extracción de texto) ligados a un File o Version
- Metadata: campos estructurados (comerciante, total, fecha) más la salida cruda de extracción y su confianza
- Status: el estado de negocio actual (needs review, approved, rejected)
Decide qué obtiene un ID que nunca cambia. Una regla útil: el ID del Document vive para siempre, mientras que Files y Previews pueden regenerarse. Las Versions también necesitan IDs estables, porque la gente referencia “cómo se veía ayer” y necesitarás una pista de auditoría.
Modela las relaciones de forma explícita. Un Document tiene muchas Versions. Cada Version puede tener múltiples Previews (diferentes tamaños o formatos). Esto mantiene rápidas las pantallas de lista porque pueden cargar datos de preview ligeros, mientras que las pantallas de detalle cargan el archivo completo solo cuando es necesario.
Ejemplo: un usuario sube la foto arrugada de un recibo. Creas un Document, guardas el File original, generas una miniatura Preview y creas la Version 1. Más tarde, el usuario sube un escaneo más nítido. Eso se convierte en la Version 2, sin romper comentarios, aprobaciones ni búsqueda ligada al Document.
Versionado: cómo almacenar el historial sin caos
La gente espera que un documento cambie con el tiempo sin “convertirse” en un elemento distinto. La forma más sencilla de lograrlo es separar identidad (el Document) de contenido (la Version y los Files).
Empieza con un document_id estable que nunca cambie. Incluso si el usuario vuelve a subir el mismo PDF, reemplaza una foto borrosa o sube un escaneo corregido, debería seguir siendo el mismo registro de documento. Comentarios, asignaciones y logs de auditoría se adjuntan limpiamente a un ID duradero.
Trata cada cambio significativo como una nueva fila version. Cada version debe capturar quién la creó y cuándo, además de punteros de almacenamiento (clave de archivo, checksum, tamaño, número de páginas) y artefactos derivados (texto OCR, imágenes de preview) ligados a ese archivo exacto. Evita “editar en el lugar”. Parece más simple al principio, pero rompe la trazabilidad y hace que los errores sean difíciles de deshacer.
Para lecturas rápidas, guarda un current_version_id en el documento. La mayoría de pantallas solo necesitan “la última”, así no tienes que ordenar versiones en cada carga. Cuando necesites historial, carga las versiones por separado y muestra una línea de tiempo clara.
Los rollbacks son solo un cambio de puntero. En lugar de borrar nada, asigna current_version_id a una versión anterior. Es rápido, seguro y mantiene la pista de auditoría intacta.
Para que el historial sea comprensible, registra por qué existe cada versión. Un pequeño campo consistente reason (más una nota opcional) evita una línea de tiempo llena de actualizaciones misteriosas. Razones comunes: reemplazo por re-subida, limpieza de escaneo, corrección OCR, redacción y edición tras aprobación.
Ejemplo: un equipo de finanzas sube la foto de un recibo, la reemplaza por un escaneo más claro y luego corrige el OCR para que el total sea legible. Cada paso es una nueva version, pero el documento sigue siendo un único elemento en la bandeja de entrada. Si la corrección OCR fue incorrecta, el rollback es un clic porque solo cambias current_version_id.
Previews y miniaturas que se mantengan rápidas y fiables
En los flujos centrados en documentos, la vista previa suele ser lo principal con lo que interactúan los usuarios. Si las vistas previas son lentas o inestables, la app entera parece rota.
Trata la generación de previews como un trabajo separado, no como algo que espere la pantalla de subida. Guarda primero el archivo original, devuelve el control al usuario y luego genera las previews en segundo plano. Esto mantiene la UI responsiva y hace que los reintentos sean seguros.
Almacena múltiples tamaños de preview. Un solo tamaño nunca sirve para todas las pantallas: miniatura pequeña para listas, imagen mediana para vistas divididas y página completa para revisión detallada (página a página para PDFs).
Rastrea el estado de preview explícitamente para que la UI siempre sepa qué mostrar: pending, ready, failed y needs_retry. Mantén las etiquetas amigables para el usuario en la UI, pero ten estados claros en los datos.
Para mantener la renderización rápida, cachea valores derivados junto al registro de preview en vez de recalcularlos en cada vista. Campos comunes: número de páginas, ancho y alto de preview, rotación (0/90/180/270) y una “mejor página para miniatura”.
Diseña para archivos lentos y desordenados. Un PDF escaneado de 200 páginas o una foto de recibo arrugada puede tardar en procesarse. Usa carga progresiva: muestra la primera página lista tan pronto exista, y luego completa el resto.
Ejemplo: un usuario sube 30 fotos de recibos. La vista de lista muestra miniaturas como “pending” y luego cada tarjeta pasa a “ready” a medida que su preview termina. Si algunas fallan por una imagen corrupta, permanecen visibles con una acción clara de reintento en lugar de desaparecer o bloquear todo el lote.
Mantén las vistas previas rápidas y honestas
Modela trabajos y estados de preview (pending-ready-failed) sin bloquear las subidas.
Los metadatos convierten un montón de archivos en algo que puedes buscar, ordenar, revisar y aprobar. Ayudan a responder preguntas sencillas rápido: ¿Qué es este documento? ¿De quién proviene? ¿Es válido? ¿Qué debe pasar después?
Una forma práctica de mantener metadatos limpios es separarlos por su origen:
- Metadatos del sistema: nombre de archivo, tamaño, MIME type, número de páginas, tiempo de subida, checksum
- Metadatos extraídos: texto OCR, campos detectados (proveedor, fecha, total), valores de código de barras/QR
- Metadatos ingresados por el usuario: correcciones, etiquetas, notas, categorización, comentarios del aprobador
Estos compartimentos evitan discusiones posteriores. Si un total es incorrecto, puedes ver si vino del OCR o de una edición humana.
Para recibos y facturas, un conjunto pequeño de campos rinde mucho si los usas con consistencia (mismo nombre, mismos formatos). Campos ancla comunes: vendor, date, total, currency y document_number. Manténlos opcionales al principio. La gente sube escaneos parciales y fotos borrosas, y bloquear el progreso por la falta de un campo ralentiza todo el flujo.
Trata los valores desconocidos como ciudadanos de primera clase. Usa estados explícitos como null/unknown, más una razón cuando sea útil (página faltante, ilegible, no aplicable). Eso permite que el documento avance mientras muestra a los revisores qué necesita atención.
También guarda la procedencia y la confianza para los campos extraídos. La fuente puede ser user, OCR, import o API. La confianza puede ser una puntuación 0–1 o un conjunto pequeño como high/medium/low. Si OCR lee “$18.70” con baja confianza porque el último dígito está manchado, la UI puede resaltarlo y pedir confirmación rápida.
Los documentos multipágina necesitan una decisión extra: qué pertenece al documento entero y qué pertenece a una sola página. Totales y proveedor suelen pertenecer al documento. Notas por página, redacciones, rotaciones y clasificaciones por página suelen pertenecer al nivel de página.
Estados que reflejen el trabajo real
El status responde a una pregunta: “¿En qué punto del proceso está este documento?” Mantenlo pequeño y aburrido. Si añades un estado cada vez que alguien lo pide, acabarás con filtros que nadie confía.
Un conjunto práctico de estados de negocio que mapea a decisiones reales:
- Imported: el archivo existe, pero nada se ha comprobado aún
- Needs review: un humano debe confirmar campos clave o la legibilidad
- Approved: listo para uso downstream (pagar, archivar, publicar o exportar)
- Rejected: no usable, con una razón
- Archived: conservado como registro, fuera del trabajo activo
Mantén el “procesamiento” fuera del estado de negocio. OCR en ejecución y generación de_preview describen lo que el sistema está haciendo, no lo que una persona debe hacer a continuación. Almacena eso como estados de procesamiento separados.
También separa la asignación del estado (assignee_id, team_id, due_date). Un documento puede estar Approved y aun así asignado para seguimiento, o Needs review sin propietario asignado.
Registra el historial de estados, no solo el valor actual. Un log sencillo como (from_status, to_status, changed_at, changed_by, reason) resulta útil cuando alguien pregunta “¿Quién rechazó este recibo y por qué?”
Finalmente, decide qué acciones están permitidas en cada estado. Mantén reglas simples: Imported puede pasar a Needs review; Approved es de solo lectura a menos que se cree una nueva versión; Rejected puede reabrirse pero debe conservar la razón previa.
Patrones de UI para listas, vistas de detalle y flujos de revisión
La mayor parte del tiempo se pasa escaneando una lista, abriendo un elemento, corrigiendo unos pocos campos y pasando al siguiente. Una buena UI hace esos pasos rápidos y predecibles.
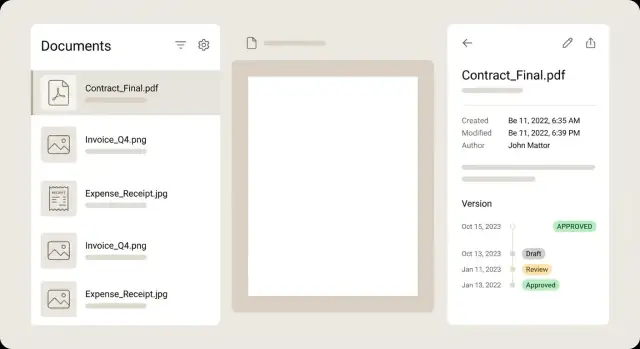
Para la lista de documentos, trata cada fila como un resumen para que los usuarios decidan sin abrir cada archivo. Una fila fuerte muestra una miniatura pequeña, un título claro, unos campos clave (comerciante, fecha, total), un distintivo de estado y una advertencia sutil cuando algo necesita atención.
Mantén la vista de detalle calmada y fácil de escanear. Un diseño común es vista previa a la izquierda y metadatos a la derecha, con controles de edición junto a cada campo. Los usuarios deberían poder hacer zoom, rotar y pasar páginas sin perder su lugar en el formulario. Si un campo fue extraído por OCR, muestra una pequeña pista de confianza y, idealmente, resalta el área fuente en la preview cuando el campo está enfocado.
Las versiones funcionan mejor como una línea de tiempo, no como un desplegable. Muestra quién cambió qué y cuándo, y permite abrir cualquier versión pasada en modo solo lectura. Si ofreces comparación, céntrate en diferencias de metadatos (cantidad cambiada, proveedor corregido) en lugar de forzar una comparación píxel a píxel del PDF.
El modo de revisión debe optimizar la velocidad. Un flujo de triaje centrado en teclado suele ser suficiente: acciones rápidas de aprobar/rechazar, arreglos rápidos para campos comunes y una caja de comentario corta para rechazos.
Los estados vacíos importan porque los documentos suelen estar en medio del procesamiento. En lugar de un cuadro en blanco, explica qué está ocurriendo: “Generando preview”, “OCR en ejecución” o “Este tipo de archivo no tiene vista previa aún.”
Paso a paso: un flujo simple desde la subida hasta la aprobación
Pasa del borrador a producción
Despliega y aloja tu app centrada en documentos cuando estés listo para compartirla.
Un flujo sencillo se siente como “subir, comprobar, aprobar”. Bajo el capó, funciona mejor cuando separas el archivo en sí (versions y previews) del significado de negocio (metadatos y status).
1) La subida cae en una bandeja de entrada
El usuario sube un PDF, una foto o un escaneo de recibo y lo ve de inmediato en una lista de bandeja. No esperes a que termine el procesamiento. Muestra nombre de archivo, hora de subida y un distintivo claro como “Processing”. Si ya conoces la fuente (importación por email, cámara móvil, arrastrar y soltar), muéstrala también.
2) Crea Document + Version, la preview empieza en pending
Al subir, crea un registro Document (el elemento de larga duración) y un registro Version (este archivo concreto). Ajusta current_version_id a la nueva versión. Guarda preview_state = pending y extraction_state = pending para que la UI pueda ser honesta sobre qué está listo.
La vista de detalle debería abrirse inmediatamente, pero mostrando un visor de marcador de posición y un mensaje claro de “Preparando vista previa” en lugar de un marco roto.
Un job en background crea miniaturas y una preview visible (imágenes de página para PDFs, imágenes redimensionadas para fotos). Otro job extrae metadatos (proveedor, fecha, total, moneda, tipo de documento). Cuando cada job termina, actualiza solo su estado y timestamps para que puedas reintentar fallos sin tocar todo lo demás.
Mantén la UI compacta: muestra estado de preview, estado de extracción y resalta campos con baja confianza.
4) El revisor corrige campos, cambia estado y añade notas
Cuando la preview está lista, los revisores corrigen campos, añaden notas y mueven el documento por estados de negocio como Imported → Needs review → Approved (o Rejected). Registra quién cambió qué y cuándo.
Si un revisor sube un archivo corregido, se convierte en una nueva Version y el documento vuelve automáticamente a Needs review.
Las exportaciones, la sincronización contable o los informes internos deben leer desde current_version_id y la snapshot de metadatos aprobada, no desde la “última extracción”. Esto evita que una re-subida a medio procesar cambie números.
Errores comunes y trampas a evitar
Los flujos centrados en documentos fallan por razones banales: atajos tempranos se convierten en dolor diario cuando la gente sube duplicados, corrige errores o pregunta “¿Quién cambió esto y cuándo?”
Tratar el nombre de archivo como la identidad del documento es un error clásico. Los nombres cambian, los usuarios re-suben y las cámaras generan duplicados como IMG_0001. Da a cada documento un ID estable y trata el nombre de archivo como una etiqueta.
Sobrescribir el archivo original cuando alguien sube un reemplazo también causa problemas. Parece más simple, pero pierdes la pista de auditoría y no puedes responder preguntas básicas después (qué se aprobó, qué se editó, qué se envió). Mantén el binario inmutable y añade un nuevo registro de versión.
La confusión de estados crea errores sutiles. “OCR en ejecución” no es lo mismo que “Needs review”. Los estados de procesamiento describen lo que la máquina hace; el estado de negocio describe qué debe hacer una persona a continuación. Cuando se mezclan, los documentos acaban en la cubeta equivocada.
Las decisiones de UI también pueden crear fricción. Si bloqueas la pantalla hasta que se generen las previews, la gente percibirá la app como lenta aun cuando la subida haya tenido éxito. Muestra el documento de inmediato con un marcador claro y luego intercala las miniaturas cuando estén listas.
Finalmente, los metadatos pierden confianza cuando guardas valores sin procedencia. Si el total vino del OCR, indícalo. Conserva timestamps.
Una lista rápida de comprobación:
- ID de documento estable separado del nombre de archivo
- Nueva versión por reemplazo, sin sobrescrituras
- Separar estado de negocio del estado de procesamiento
- Carga de preview y miniaturas no bloqueante
- Metadatos con fuente y timestamps
Ejemplo: en una app de recibos, un usuario re-sube una foto más clara. Si lo versionas, conserva la imagen antigua, marca OCR como reprocesando y mantiene Needs review hasta que un humano confirme el total.
Lista de comprobación rápida antes del lanzamiento
Prototipa las pantallas principales
Crea rápidamente una bandeja de entrada, un visor de documentos y acciones de revisión en la capa gratuita.
Los flujos centrados en documentos se consideran “listos” solo cuando la gente puede confiar en lo que ve y recuperarse cuando algo sale mal. Antes del lanzamiento, prueba con documentos reales y desordenados (recibos borrosos, PDFs rotados, subidas repetidas).
Cinco comprobaciones que detectan la mayoría de sorpresas:
- La versión actual es inequívoca. Marca la versión activa, muestra quién la cambió y cuándo, e incluye una razón corta como “recortado” o “re-subido”.
- Las previews fallan con gracia. Si una preview se está generando, muestra un marcador útil (nombre de archivo, hora de subida, número de páginas si se conoce) y un estado claro de pending. Si la generación falla, muestra un error y una opción de reintento.
- Los estados coinciden con acciones. Cada estado necesita un significado claro y un pequeño conjunto de acciones permitidas. Si existe Approved, hazlo de solo lectura.
- Las ediciones de metadatos no borran la extracción. Permite que los usuarios corrijan el OCR sin perder el valor extraído original. Conserva ambos y muestra cuál se está usando.
- La recuperación está integrada. Facilita arreglos comunes: volver a una versión anterior, ejecutar de nuevo la extracción, regenerar previews.
Una prueba de realidad rápida: pide a alguien que revise tres recibos similares y haga intencionadamente un cambio erróneo en uno. Si puede identificar la versión actual, entender el estado y corregir el error en menos de un minuto, estás cerca.
Escenario de ejemplo y próximos pasos prácticos
Los reembolsos mensuales de recibos son un ejemplo claro de trabajo centrado en documentos. Un empleado sube recibos y luego dos revisores los comprueban: un gestor y luego finanzas. El recibo es el producto, así que tu app vive o muere por el versionado, las previews, los metadatos y los estados claros.
Jamie sube la foto de un recibo de taxi. Tu sistema crea el Document #1842 con Version v1 (el archivo original), una miniatura y preview, y metadatos como merchant, date, currency, total y una puntuación de confianza OCR. El documento comienza en Imported y pasa a Needs review cuando la preview y la extracción están listas.
Más tarde, Jamie sube el mismo recibo otra vez por accidente. Un chequeo de duplicados (hash de archivo más coincidencia aproximada de merchant/date/total) puede mostrar una opción simple: “Parece un duplicado de #1842. ¿Adjuntar igual o descartar?” Si lo adjunta, guárdalo como otro File ligado al mismo Document para mantener un solo hilo de revisión y un único estado.
Durante la revisión, el gestor ve la preview, los campos clave y las advertencias. El OCR adivinó el total como $18.00, pero la imagen muestra claramente $13.00. Jamie corrige el total. No sobrescribas el historial. Crea la Version v2 con campos actualizados, conserva v1 sin cambios y registra “Total corregido por Jamie”.
Si quieres construir este tipo de flujo rápido, Koder.ai (koder.ai) puede ayudarte a generar la primera versión de la app a partir de un plan por chat, pero la misma regla aplica: define los objetos y estados primero, y deja que las pantallas sigan.
Pasos prácticos siguientes:
- Esboza el modelo de datos: Document, Version, File, ExtractedField, Review, StatusHistory
- Diseña dos pantallas: lista de bandeja (estado + advertencias) y vista de detalle (preview + campos + versiones)
- Prueba con cinco recibos reales e itera en estados, reglas de duplicados y velocidad de revisión