23 oct 2025·6 min
Filtrado del lado del servidor vs del cliente: una lista de verificación para decidir
Lista de verificación filtrado servidor vs cliente: elige según tamaño de datos, latencia, permisos y caché, evitando fugas en la UI y retrasos.
Lista de verificación filtrado servidor vs cliente: elige según tamaño de datos, latencia, permisos y caché, evitando fugas en la UI y retrasos.
Filtrar en una UI es más que una sola caja de búsqueda. Normalmente incluye varias acciones relacionadas que cambian lo que ve el usuario: búsqueda de texto (nombre, correo, ID de pedido), facetas (estado, propietario, rango de fechas, etiquetas) y orden (más nuevos, mayor valor, última actividad).
La pregunta clave no es qué técnica es “mejor”. Es dónde vive el conjunto de datos completo y quién puede acceder a él. Si el navegador recibe registros que el usuario no debería ver, una UI puede exponer datos sensibles aunque los ocultes visualmente.
La mayoría de los debates sobre filtrado en servidor vs cliente son en realidad reacciones a dos fallos que los usuarios notan de inmediato:
Hay un tercer problema que genera informes de bugs sin parar: resultados inconsistentes. Si algunos filtros se ejecutan en el cliente y otros en el servidor, los usuarios ven conteos, páginas y totales que no coinciden. Eso rompe la confianza rápido, especialmente en listas paginadas.
Una regla práctica y simple: si el usuario no puede acceder al conjunto de datos completo, filtra en el servidor. Si puede acceder y el conjunto es lo bastante pequeño para cargarse rápido, el filtrado en el cliente puede estar bien.
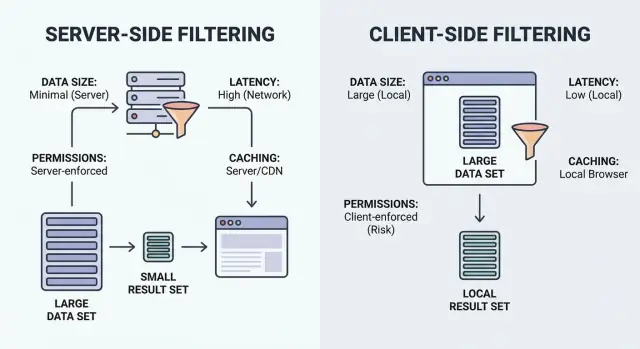
Filtrar es simplemente “muéstrame los ítems que coinciden”. La pregunta clave es dónde ocurre la comparación: en el navegador del usuario (cliente) o en tu backend (servidor).
Filtrado en el cliente se ejecuta en el navegador. La app descarga un conjunto de registros (a menudo JSON) y luego aplica filtros localmente. Puede sentirse instantáneo después de cargar los datos, pero solo funciona cuando el conjunto es lo bastante pequeño para enviarse y lo bastante seguro para exponerse.
Filtrado en el servidor se ejecuta en tu backend. El navegador envía los inputs de filtrado (como status=open, owner=me, createdAfter=Jan 1) y el servidor devuelve solo los resultados que coinciden. En la práctica, suele ser un endpoint de API que acepta filtros, construye una consulta a la base de datos y devuelve una lista paginada más totales.
Un modelo mental simple:
Los setups híbridos son comunes. Un buen patrón es aplicar los filtros “grandes” en el servidor (permisos, propiedad, rango de fechas, búsqueda) y luego usar toggles pequeños solo de UI localmente (ocultar archivados, chips rápidos de etiqueta, visibilidad de columnas) sin otra petición.
Ordenar, paginar y buscar suelen pertenecer a la misma decisión. Afectan el tamaño del payload, la sensación del usuario y qué datos estás exponiendo.
Empieza con la pregunta más práctica: ¿cuánta información enviarías al navegador si filtras en el cliente? Si la respuesta honesta es “más de unas pocas pantallas”, lo pagarás en tiempo de descarga, uso de memoria y en interacciones más lentas.
No necesitas estimaciones perfectas. Solo obtén el orden de magnitud: cuántas filas podría ver el usuario y cuál es el tamaño medio de una fila. Una lista de 500 ítems con pocos campos cortos es muy distinta de 50.000 ítems donde cada fila incluye notas largas, texto enriquecido u objetos anidados.
Los registros anchos son el asesino silencioso del payload. Una tabla puede parecer pequeña por número de filas pero ser pesada si cada fila contiene muchos campos, cadenas largas o datos joinados (contacto + empresa + última actividad + dirección completa + etiquetas). Aunque muestres solo tres columnas, los equipos a menudo envían “todo, por si acaso” y el payload se infla.
Piensa también en el crecimiento. Un conjunto que hoy está bien puede volverse pesado en pocos meses. Si los datos crecen rápido, trata el filtrado en cliente como un atajo a corto plazo, no como opción por defecto.
Reglas prácticas:
Este último punto importa por algo más que rendimiento. “¿Podemos enviar el conjunto completo al navegador?” también es una pregunta de seguridad. Si la respuesta no es un sí seguro, no lo envíes.
Las elecciones de filtrado suelen fallar por la sensación, no por la corrección. Los usuarios no miden milisegundos; notan pausas, parpadeos y resultados que saltan mientras escriben.
El tiempo se puede perder en distintos lugares:
Define qué significa “lo bastante rápido” para esta pantalla. Una vista de lista puede requerir escritura receptiva y scroll suave, mientras que una página de reportes puede tolerar una breve espera siempre que aparezca el primer resultado rápido.
No juzgues solo por la Wi‑Fi de la oficina. En conexiones lentas, el filtrado en cliente puede sentirse bien después de la primera carga, pero esa primera carga puede ser la parte lenta. El filtrado en servidor mantiene los payloads pequeños, pero puede sentirse lento si disparas una petición en cada pulsación.
Diseña en torno a la entrada humana. Usa debounce en las peticiones mientras se escribe. Para conjuntos grandes, usa carga progresiva para que la página muestre algo rápido y siga siendo suave conforme el usuario hace scroll.
Los permisos deberían decidir tu enfoque más que la velocidad. Si el navegador alguna vez recibe datos que un usuario no puede ver, ya tienes un problema, aunque lo ocultes tras un botón deshabilitado o una columna colapsada.
Empieza por nombrar qué es sensible en esta pantalla. Algunos campos son obvios (emails, teléfonos, direcciones). Otros son fáciles de pasar por alto: notas internas, coste o margen, reglas de precio especiales, puntuaciones de riesgo, flags de moderación.
La gran trampa es “filtramos en el cliente, pero solo mostramos las filas permitidas”. Eso aún significa que el dataset completo fue descargado. Cualquiera puede inspeccionar la respuesta de red, abrir las dev tools o guardar el payload. Ocultar columnas en la UI no es control de acceso.
El filtrado en servidor es el valor por defecto más seguro cuando la autorización varía por usuario, especialmente si distintos usuarios pueden ver diferentes filas o campos.
Chequeo rápido:
Si alguna respuesta es sí, mantén el filtrado y la selección de campos en el servidor. Envía solo lo que el usuario puede ver y aplica las mismas reglas a búsqueda, orden, paginación y exportación.
Ejemplo: en una lista de contactos CRM, los representantes pueden ver solo sus cuentas mientras que los managers ven todo. Si el navegador descarga todos los contactos y filtra localmente, un representante aún podría recuperar cuentas ocultas desde la respuesta. El filtrado en servidor evita eso al no enviar esas filas.
El caché puede hacer que una pantalla parezca instantánea. También puede mostrar la verdad equivocada. La clave es decidir qué puedes reutilizar, durante cuánto y qué eventos deben invalidarlo.
Empieza por elegir la unidad de caché. Cachear una lista completa es simple pero normalmente desperdicia ancho de banda y caduca rápido. Cachear páginas funciona bien para scroll infinito. Cachear resultados por consulta (filtro + orden + búsqueda) es preciso, pero puede crecer rápido si los usuarios prueban muchas combinaciones.
La frescura importa más en algunos dominios que en otros. Si los datos cambian rápido (niveles de stock, saldos, estado de entrega), incluso 30 segundos de caché puede confundir. Si los datos cambian despacio (registros archivados, datos de referencia), cachés más largos suelen estar bien.
Planifica la invalidación antes de programar. Además del paso del tiempo, decide qué debe forzar una actualización: creaciones/ediciones/eliminaciones, cambios de permisos, importaciones o merges masivos, transiciones de estado, acciones de deshacer/rollback y jobs en background que actualicen campos que los usuarios filtran.
Decide también dónde vive el caché. La memoria del navegador hace que la navegación atrás/adelante sea rápida, pero puede filtrar datos entre cuentas si no lo claveas por usuario y org. El caché del backend es más seguro para permisos y consistencia, pero debe incluir la firma completa del filtro y la identidad del llamador para que los resultados no se mezclen.
Trata el objetivo como no negociable: la pantalla debe sentirse rápida sin filtrar datos.
La mayoría de los equipos tropieza con los mismos patrones: una UI que luce bien en demo, pero con datos reales, permisos reales y redes reales salen las grietas.
El fallo más grave es tratar el filtrado como presentación. Si el navegador recibe registros que no debería, ya perdiste.
Dos causas frecuentes:
Ejemplo: los internos solo deben ver leads de su región. Si la API devuelve todas las regiones y el dropdown filtra en React, los internos aún pueden extraer la lista completa.
La lentitud suele venir de suposiciones:
Un problema sutil y doloroso son reglas desajustadas. Si el servidor trata “empieza con” distinto que la UI, los usuarios verán conteos que no coinciden o ítems que desaparecen tras un refresco.
Haz un repaso final con dos mentalidades: un usuario curioso y un día de red mala.
Una prueba simple: crea un registro restringido y confirma que nunca aparece en el payload, conteos ni caché, incluso cuando filtras ampliamente o limpias filtros.
Imagínate un CRM con 200.000 contactos. Los reps solo ven sus cuentas, los managers ven su equipo y los admins lo ven todo. La pantalla tiene búsqueda, filtros (estado, propietario, última actividad) y orden.
El filtrado en cliente falla rápido aquí. El payload es pesado, la primera carga se vuelve lenta y el riesgo de fuga de datos es alto. Aunque la UI oculte filas, el navegador recibió los datos. También presionas el dispositivo: arrays grandes, orden pesado, ejecuciones de filtro repetidas, alto uso de memoria y crashes en móviles antiguos.
Un enfoque más seguro es el filtrado en servidor con paginación. El cliente envía las opciones de filtro y el servidor devuelve solo las filas que el usuario puede ver, ya filtradas y ordenadas.
Un patrón práctico:
Una pequeña excepción donde el filtrado en cliente está bien: datos diminutos y estáticos. Un dropdown de “Estado de contacto” con 8 valores puede cargarse una vez y filtrarse localmente con poco riesgo o coste.
Los equipos no suelen quemarse por elegir “mal” una vez. Se queman por tomar decisiones distintas en cada pantalla y luego intentar arreglar fugas y páginas lentas bajo presión.
Escribe una nota corta de decisión por pantalla con filtros: tamaño del dataset, coste de enviarlo, qué significa “lo bastante rápido”, qué campos son sensibles y cómo se cachearán (o no). Mantén servidor y UI alineados para no acabar con “dos verdades” sobre el filtrado.
Si estás construyendo pantallas rápido en Koder.ai (koder.ai), vale la pena decidir desde el principio qué filtros deben hacerse en el backend (permisos y acceso a nivel de fila) y qué toggles pequeños de UI pueden quedarse en React. Esa única decisión suele evitar las reescrituras más caras después.
Por defecto, usa filtrado en servidor cuando los usuarios tienen permisos distintos, el conjunto de datos es grande o te importan la paginación y los totales consistentes. Usa filtrado en el cliente solo cuando el conjunto completo sea pequeño, seguro de exponer y rápido de descargar.
Porque todo lo que el navegador recibe puede inspeccionarse. Aunque la UI oculte filas o columnas, un usuario puede ver los datos en las respuestas de red, en cachés o en objetos en memoria.
Suele ocurrir cuando envías demasiados datos y luego filtras/ordenas grandes arrays en cada pulsación, o cuando lanzas una petición al servidor por cada tecla sin debouncing. Mantén los payloads pequeños y evita trabajo pesado en cada cambio de entrada.
Mantén una sola fuente de verdad para los filtros “reales”: permisos, búsqueda, orden y paginación deben aplicarse en el servidor juntos. Limita la lógica del cliente a pequeños toggles de UI que no cambien el conjunto de datos subyacente.
El caching en cliente puede mostrar datos obsoletos o filtrados incorrectamente, y puede filtrar datos entre cuentas si no está correctamente claveado. El caching en servidor es más seguro para permisos, pero debe incluir la firma completa del filtro y la identidad del llamador para que los resultados no se mezclen.
Hazte dos preguntas: cuántas filas podría tener razonablemente un usuario y cuánto ocupa cada fila en bytes. Si no lo cargarías cómodamente en una conexión móvil típica o en un dispositivo antiguo, pasa el filtrado al servidor y usa paginación.
Servidor. Si roles, equipos, regiones u reglas de propiedad cambian lo que alguien puede ver, el servidor debe aplicar el control de acceso por fila y por campo. El cliente solo debería recibir los registros y campos permitidos.
Define el contrato de filtros primero: campos de filtro aceptados, orden por defecto, reglas de paginación y cómo funciona la búsqueda (mayúsculas, acentos, coincidencias parciales). Luego implementa la misma lógica de forma consistente en el backend y prueba que totales y páginas coincidan.
Usa debounce en la escritura para no pedir en cada tecla y mantén los resultados antiguos visibles hasta que lleguen los nuevos para reducir el parpadeo. Usa paginación o carga progresiva para que el usuario vea algo rápido sin bloquearse por una respuesta enorme.
Aplica primero los permisos, luego filtros y orden, y devuelve solo una página más un conteo total. Evita enviar “campos extra por si acaso” y asegúrate de que las claves de caché incluyan usuario/organización/rol para que un representante nunca reciba datos de un manager.