Por qué la caché ayuda — y por qué complica los sistemas
La caché mantiene una copia de los datos cerca de donde se necesitan para que las peticiones se sirvan más rápido, con menos viajes a los sistemas centrales. La ganancia suele ser una mezcla de velocidad (latencia más baja), coste (menos lecturas caras a la base de datos o llamadas upstream) y estabilidad (los servicios origen sobreviven picos de tráfico).
La ventaja: menos trabajo para el origen
Cuando una caché puede responder una petición, tu “origen” (servidores de aplicación, bases de datos, APIs de terceros) hace menos. Esa reducción puede ser dramática: menos consultas, menos ciclos de CPU, menos saltos de red y menos oportunidades de timeouts.
La caché también suaviza picos, ayudando a que sistemas dimensionados para la carga promedio manejen momentos punta sin escalar de inmediato (o sin caerse).
El intercambio oculto: más trabajo para los ingenieros
La caché no elimina trabajo; lo mueve a diseño y operaciones. Heredas nuevas preguntas:
- ¿Qué debería cacharse?
- ¿Por cuánto tiempo?
- ¿Qué pasa cuando los datos cambian?
- ¿Cómo evitas resultados obsoletos o incorrectos?
- ¿Cómo depuras problemas cuando una caché “oculta” el comportamiento del origen?
Cada capa de caché añade configuración, monitorización y casos límite. Una caché que acelera el 99% de las peticiones puede aún causar incidentes dolorosos en el 1%: expiraciones sincronizadas, experiencias de usuario inconsistentes o inundaciones súbitas al origen.
Capa de caché vs. una sola caché
Una caché única es un almacén (por ejemplo, una caché en memoria junto a tu aplicación). Una capa de caché es un punto de control en la ruta de la petición—CDN, caché del navegador, caché de aplicación, caché de base de datos—cada una con sus propias reglas y modos de fallo.
Esta publicación se centra en la complejidad práctica introducida por múltiples capas: corrección, invalidación y operaciones (no en algoritmos de caché a bajo nivel o ajustes específicos de proveedores).
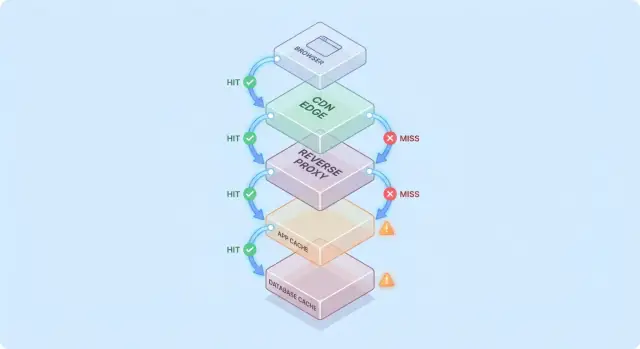
Un modelo simple: flujo de petición a través de múltiples capas
La caché es más fácil de razonar cuando imaginas una petición viajando por una pila de puntos de control “quizá ya lo tengo”.
Ruta típica de una petición
Un camino común es:
- Cliente → Edge (CDN) → App → Base de datos
En cada salto, el sistema puede devolver una respuesta en caché (hit) o reenviar la petición a la siguiente capa (miss). Cuanto antes ocurra el hit (por ejemplo en el edge), más carga evitas en capas profundas.
Los hits se ven bien; los misses son la verdadera prueba
Los hits hacen que los dashboards luzcan bien. Los misses son donde aparece la complejidad: desencadenan trabajo real (lógica de app, consultas a BD) y añaden sobrecarga (búsquedas en caché, serialización, escrituras en la caché).
Un modelo mental útil es: cada miss paga la caché dos veces—todavía haces el trabajo original y además la sobrecarga alrededor de la caché.
Cómo las capas mueven los cuellos de botella
Agregar una capa de caché rara vez elimina cuellos de botella; a menudo los mueve:
- Un CDN puede desplazar la presión fuera de la app, pero aumenta la sensibilidad a la configuración y a la velocidad de purge.
- Una caché de aplicación puede reducir la carga de la base de datos, pero convierte la CPU/memoria del tier de aplicación en el nuevo factor limitante.
- El caching en la base de datos (buffer pools, plan caches) puede ocultar consultas lentas hasta que el working set ya no quepa.
Ejemplo simple: “cacheado dos veces”
Supón que la página de producto está cacheada en el CDN por 5 minutos y la app también guarda detalles de producto en Redis por 30 minutos.
Si cambia un precio, el CDN puede refrescar rápido mientras Redis sigue sirviendo el precio antiguo. Ahora la “verdad” depende de qué capa respondió la petición—un ejemplo temprano de por qué las capas de caché reducen carga pero aumentan la complejidad.
Capas comunes de caché y para qué sirven
Caché no es una única característica: es una pila de lugares donde los datos pueden guardarse y reusarse. Cada capa puede reducir carga, pero cada una tiene reglas distintas sobre frescura, invalidación y visibilidad.
Cachés de navegador y del sistema operativo (lo que controlas vs. lo que no)
Los navegadores guardan imágenes, scripts, CSS y a veces respuestas API según headers HTTP (como Cache-Control y ETag). Esto puede eliminar descargas repetidas por completo—excelente para rendimiento y para reducir tráfico CDN/origen.
La pega: una vez que una respuesta está cacheada en el cliente, no controlas completamente el momento de revalidación. Algunos usuarios pueden mantener activos assets más antiguos (o limpiar la caché inesperadamente), por lo que las URLs versionadas (p. ej., app.3f2c.js) son una red de seguridad común.
Caché en CDN/edge para contenido estático y semi-estático
Un CDN cachea contenido cerca de los usuarios. Brilla con archivos estáticos, páginas públicas y respuestas “mayormente estables” como imágenes de producto, documentación o endpoints limitados por tasa.
Los CDNs también pueden cachear HTML semi-estático si controlas bien la variación (cookies, headers, geo, dispositivo). Reglas de variación mal configuradas son una fuente frecuente de servir contenido incorrecto al usuario equivocado.
Caché de proxy inverso (nivel gateway)
Los reverse proxies (como NGINX o Varnish) se colocan frente a la aplicación y pueden cachear respuestas completas. Esto es útil cuando quieres control centralizado, evicción predecible y protección rápida al origen durante picos de tráfico.
Suele ser menos distribuido globalmente que un CDN, pero más sencillo de adaptar a rutas y headers específicos de tu app.
Caché a nivel de aplicación (in-memory, Redis, Memcached)
Esta caché apunta a objetos, resultados computados y llamadas costosas (p. ej., “perfil de usuario por id” o “reglas de precios por región”). Es flexible y puede conocer la lógica de negocio.
También introduce más decisiones: diseño de claves, elección de TTL, lógica de invalidación y necesidades operativas como dimensionamiento y failover.
Caché en base de datos y caché de resultados de consulta
La mayoría de las bases de datos cachean páginas, índices y planes de consulta automáticamente; algunas soportan caché de resultados. Esto puede acelerar consultas repetidas sin cambiar el código de la aplicación.
Debe verse como un bonus, no una garantía: las cachés de BD son típicamente las menos predecibles bajo patrones de consulta diversos y no eliminan el coste de escrituras, bloqueos o contención como lo hacen caches upstream.
Dónde la caché ofrece la mayor reducción de carga
La caché compensa más cuando convierte operaciones backend repetidas y caras en una búsqueda barata. La clave es emparejar la caché con cargas de trabajo donde las peticiones sean suficientemente similares—y suficientemente estables—para que el reuso sea alto.
Cargas de trabajo con muchas lecturas y cálculos costosos
Si tu sistema atiende muchas más lecturas que escrituras, la caché puede quitar una gran parte del trabajo de BD y app. Páginas de producto, perfiles públicos, artículos de ayuda y resultados de búsqueda/filtrado suelen pedirse repetidamente con los mismos parámetros.
La caché también ayuda con trabajo “costoso” que no es estrictamente BD: generar PDFs, redimensionar imágenes, renderizar plantillas o calcular agregados. Incluso una caché de corta duración (segundos o minutos) puede colapsar la repetición de cómputo durante periodos de alta carga.
Tráfico en picos y protección contra ráfagas
La caché es especialmente eficaz cuando el tráfico es irregular. Si un email de marketing, una mención en noticias o una publicación social envía una ráfaga de usuarios a las mismas URLs, un CDN o caché edge puede absorber la mayor parte del aluvión.
Esto reduce la carga más allá de “respuestas más rápidas”: puede prevenir thrashing de autoscaling, evitar agotamiento de conexiones a BD y ganar tiempo para que los mecanismos de rate limiting y backpressure actúen.
Backends de alta latencia y usuarios de distintas regiones
Si tu backend está lejos de tus usuarios—literalmente (cross-region) o lógicamente (una dependencia lenta)—la caché puede reducir tanto la carga como la latencia percibida. Servir contenido desde un cache CDN cercano evita viajes repetidos de larga distancia al origen.
La caché interna también ayuda cuando el cuello de botella es un store de alta latencia (una BD remota, una API de terceros, un servicio compartido). Reducir el número de llamadas baja la presión de concurrencia y mejora la latencia de cola alta.
Cuando la caché tiene poco sentido
La caché aporta menos cuando las respuestas son altamente personalizadas (datos por usuario, información sensible de cuenta) o cuando los datos cambian constantemente (dashboards en tiempo real, inventarios que se actualizan rápido). En esos casos, las tasas de acierto son bajas, los costes de invalidación suben y el trabajo ahorrado puede ser marginal.
Una regla práctica: la caché vale más cuando muchos usuarios piden lo mismo dentro de una ventana en la que “lo mismo” sigue siendo válido. Si ese solapamiento no existe, otra capa puede añadir complejidad sin reducir la carga.
Invalidación de caché: la principal fuente de complejidad
La caché es fácil cuando los datos nunca cambian. En el momento en que lo hacen, heredas la parte más difícil: decidir cuándo los datos cacheados dejan de ser fiables y cómo cada capa de caché se entera de que hubo un cambio.
Expiración por TTL: simple, pero rara vez “correcta”
Time-to-live (TTL) es atractivo porque es un número y no requiere coordinación. El problema es que el TTL “correcto” depende de cómo se usan los datos.
Si pones un TTL de 5 minutos en un precio de producto, algunos usuarios verán un precio antiguo tras un cambio—potencialmente un problema legal o de soporte. Si lo pones a 5 segundos, puede que no reduzcas mucho la carga. Aún peor, distintos campos en la misma respuesta cambian a ritmos diferentes (inventario vs descripción), así que un TTL único fuerza un compromiso.
Invalidación basada en eventos: precisa, pero requiere coordinación
La invalidación por eventos dice: cuando cambia la fuente de la verdad, publica un evento y purga/actualiza todas las claves de caché afectadas. Esto puede ser muy correcto, pero crea nuevo trabajo:
- Cada ruta de escritura debe emitir eventos de forma fiable.
- Cada capa de caché debe suscribirse, reintentar, deduplicar y manejar entregas fuera de orden.
- Necesitas un mapeo claro de “qué cambió” a “qué claves invalidar”.
Ese mapeo es donde “las dos cosas difíciles: nombrar e invalidar” se vuelve dolorosamente práctico. Si cacheas /users/123 y también cacheas listas de “top contributors”, un cambio de nombre afecta más de una clave. Si no rastreas relaciones, servirás una realidad mezclada.
Patrones: cache-aside vs write-through vs write-back
Cache-aside (la app lee/escribe BD y pobla la caché) es común, pero la invalidación queda a tu cargo.
Write-through (escribir caché y BD juntos) reduce el riesgo de staleness, pero añade latencia y complejidad en manejo de fallos.
Write-back (escribir en caché primero y volcar después) acelera, pero complica mucho la corrección y recuperación.
Stale-while-revalidate: “suficientemente bueno” a propósito
Stale-while-revalidate sirve datos ligeramente antiguos mientras refresca en segundo plano. Suaviza picos y protege el origen, pero es también una decisión de producto: eliges explícitamente “rápido y mayormente actual” frente a “siempre el más reciente”.
Compromisos de consistencia y corrección visible para el usuario
Practica el diseño de claves
Modela claves de caché versionadas y flujos de invalidación en una app funcional, no en un diagrama.
La caché cambia lo que significa “correcto”. Sin caché, los usuarios ven mayormente los últimos datos comprometidos (sujeto al comportamiento normal de la BD). Con caches, los usuarios pueden ver datos ligeramente atrasados—o inconsistentes entre pantallas—sin que haya un error obvio.
Consistencia fuerte vs eventual (y lo que los usuarios realmente notan)
La consistencia fuerte busca “leer tras escribir”: si un usuario actualiza su dirección, la siguiente carga de página debería mostrarla en todas partes. Esto se siente intuitivo, pero puede ser caro si cada escritura debe purgar o refrescar múltiples caches.
La consistencia eventual permite breves stalenesses: la actualización aparecerá pronto, pero no instantáneamente. Los usuarios toleran esto en contenido de bajo riesgo (como contadores de vistas), pero no en dinero, permisos o en cosas que afectan acciones inmediatas.
Condiciones de carrera entre escrituras y refresco de caché
Un fallo común es una escritura coincidiendo con la repoblación de la caché:
- Usuario actualiza perfil.
- Se invalida la caché.
- Otra petición repuebla la caché desde una réplica que aún no recibió la actualización.
Ahora la caché contiene datos viejos por todo su TTL, aunque la base de datos esté correcta.
Inconsistencia entre capas: el edge dice A, la app dice B
Con múltiples capas, distintas partes del sistema pueden discrepar:
- El CDN devuelve una página HTML antigua (“Dirección: Calle Vieja”).
- La caché de la app devuelve JSON más reciente (“Dirección: Calle Nueva”).
- La UI queda mezclada.
Los usuarios interpretan esto como “el sistema está roto”, no como “es eventualmente consistente”.
El versionado reduce la ambigüedad:
- ETags permiten a clientes/CDNs revalidar eficientemente y evitar servir contenido obsoleto cuando la representación cambia.
- Claves de caché versionadas (ej.,
user:123:v7) permiten avanzar con seguridad: una escritura incrementa la versión y las lecturas cambian naturalmente a la nueva clave sin depender de borrados precisos.
Definir staleness aceptable por característica
La decisión clave no es “¿es malo el dato obsoleto?” sino dónde lo es.
Fija presupuestos de staleness explícitos por característica (segundos/minutos/horas) y alinéalos con las expectativas del usuario. Los resultados de búsqueda pueden retrasarse un minuto; saldos de cuenta y control de acceso no deberían.
Esto convierte la “corrección de la caché” en un requisito de producto que puedes probar y monitorizar.
Modos de fallo: estampidas, claves calientes y caídas de caché
La caché suele fallar de formas que parecen “todo iba bien y luego todo se rompió de golpe”. Estos fallos no significan que la caché sea mala—significan que las caches concentran patrones de tráfico, así que pequeños cambios pueden desencadenar efectos grandes.
Arranques en frío y carga desigual tras despliegues
Tras un despliegue, un evento de autoscaling o un flush de caché, puedes tener caches mayormente vacías. La siguiente ráfaga de tráfico fuerza muchas peticiones a la BD o a APIs upstream directamente.
Esto duele especialmente cuando el tráfico sube rápido, porque la caché no ha tenido tiempo de calentar con items populares. Si despliegues coinciden con picos de uso, puedes crear tu propia prueba de carga accidental.
Estampidas de caché (thundering herd)
Una estampida ocurre cuando muchos usuarios piden el mismo ítem justo al expirar (o cuando aún no está cacheado). En lugar de que una petición reconstruya el valor, cientos o miles lo hacen, sobrecargando el origen.
Mitigaciones comunes incluyen:
- Coalescencia de peticiones: dejar que la primera petición reconstruya mientras otras esperan el resultado.
- Locks / single-flight: imponer “solo un constructor” por clave de caché.
- TTL con jitter: aleatorizar las expiraciones para que no caduquen simultáneamente.
Si los requisitos de corrección lo permiten, stale-while-revalidate también suaviza picos.
Claves calientes y distribución desigual
Algunas claves se vuelven desproporcionadamente populares (payload de la página de inicio, producto en tendencia, configuración global). Las claves calientes crean carga desigual: un nodo de caché o un camino al backend se ve saturado mientras otros están inactivos.
Mitigaciones: dividir claves “globales” grandes en otras más pequeñas, añadir sharding/particionado o cachear en otra capa (p. ej., mover contenido verdaderamente público más cerca del usuario vía CDN).
Cuando la caché cae: elige tu fallback
Las caídas de caché pueden ser peores que no tener caché, porque las apps pueden depender de ella. Decide con antelación:
- Fail open (saltar la caché y consultar origen): mayor disponibilidad, mayor riesgo de carga
- Fail closed (devolver errores): protege el origen, peor experiencia
- Degradar con gracia (servir obsoletos/por defecto): a menudo el mejor compromiso
Sea cual sea la elección, los rate limits y circuit breakers ayudan a que una falla de caché no se convierta en un outage del origen.
Sobrecarga operativa: más piezas que gestionar
Evita avalanchas de caché
Simula stampedes y añade lógica single-flight o TTL con jitter en un entorno controlado.
La caché puede reducir la carga en tus orígenes, pero aumenta el número de servicios que operas día a día. Incluso las caches “gestionadas” requieren planificación, tuning e respuesta a incidentes.
Más componentes que ejecutar
Una nueva capa de caché suele significar un nuevo clúster (o al menos un nuevo tier) con límites de capacidad propios. Los equipos deben decidir dimensionamiento de memoria, política de evicción y qué ocurre bajo presión. Si la caché está infra-dimensionada, churn: la tasa de aciertos cae, la latencia sube y el origen se ve igualmente saturado.
Deriva de configuración entre capas
La caché rara vez vive en un solo lugar. Puedes tener CDN, caché de aplicación y caché de base de datos—todos interpretando reglas de forma diferente.
Pequeñas discrepancias se acumulan:
- El CDN respeta headers, la caché de la app usa TTLs hard-coded.
- Una capa omite cookies mientras otra no.
- Reglas de purge existen en un sitio y no en otro.
Con el tiempo, “¿por qué está esto cacheado?” se convierte en un proyecto de arqueología.
Tareas operativas nuevas
Las caches crean trabajo recurrente: precalentar claves críticas tras despliegues, purgar o revalidar cuando los datos cambian, reshardear al añadir/quitar nodos y ensayar qué pasa tras un flush completo.
Complejidad on-call durante incidentes
Cuando los usuarios reportan datos obsoletos o lentitud repentina, los respondedores tienen ahora varios sospechosos: el CDN, el clúster de caché, el cliente de caché de la app y el origen. Depurar a menudo implica revisar tasas de acierto, picos de evicción y timeouts en varias capas—y decidir si saltar, purgar o escalar.
Observabilidad: demostrar que la caché realmente ayuda
La caché solo es una victoria si reduce el trabajo backend y mejora la velocidad percibida. Dado que las peticiones pueden ser servidas por múltiples capas (edge/CDN, caché de app, caché de BD), necesitas observabilidad que responda:
- ¿Qué capa sirvió esta petición?
- ¿Qué cambió cuando no lo hizo?
Métricas que realmente explican resultados
Una alta tasa de aciertos suena bien, pero puede ocultar problemas (como lecturas de caché lentas o churn constante). Sigue un conjunto pequeño de métricas por capa:
- Ratio de hits/misses, por endpoint o namespace
- Latencia por capa (tiempo de lectura de caché vs tiempo de origen), idealmente p50/p95/p99
- Tasa de evicción y edad del ítem (cuánto duran antes de ser removidos)
- Indicadores de carga del origen (QPS BD, CPU, saturación de pool) correlacionados con hits de caché
Si la tasa de aciertos sube pero la latencia total no mejora, la caché puede ser lenta, estar excesivamente serializada o devolver payloads muy grandes.
Tracing a través de capas
El tracing distribuido debe mostrar si una petición fue servida en el edge, por la caché de la app o por la base de datos. Añade etiquetas consistentes como cache.layer=cdn|app|db y cache.result=hit|miss|stale para filtrar trazas y comparar tiempos de ruta de hit vs miss.
Logs y alertas sin filtrar datos
Loggea claves de caché con cuidado: evita identificadores de usuario en claro, emails, tokens o URLs completas con query strings. Prefiere claves normalizadas o hasheadas y registra solo un prefijo corto.
Alerta sobre picos anormales en la tasa de misses, subidas súbitas de latencia en misses y señales de estampida (muchos misses concurrentes para el mismo patrón de clave). Separa dashboards en vistas de edge, app y base de datos, más un panel end-to-end que las una.
Riesgos de seguridad y privacidad en respuestas cacheadas
La caché repite respuestas rápidamente—pero también puede repetir la respuesta equivocada al usuario equivocado. Los incidentes de seguridad relacionados con caché suelen ser silenciosos: todo parece rápido y saludable mientras los datos se filtran.
Cómo datos sensibles terminan en cachés
Un fallo común es cachear contenido personalizado o confidencial (detalles de cuenta, facturas, tickets de soporte, páginas admin). Esto puede suceder en cualquier capa—CDN, proxy inverso o caché de aplicación—especialmente con reglas de “cachearlo todo” demasiado amplias.
Una fuga sutil es cachear respuestas que incluyen estado de sesión (p. ej., Set-Cookie) y luego servir esa respuesta cacheada a otros usuarios.
Errores de autorización: petición correcta, espectador incorrecto
Un bug clásico es cachear el HTML/JSON devuelto para el Usuario A y más tarde servirlo al Usuario B porque la clave de caché no incluía el contexto de usuario. En sistemas multi-tenant, la identidad del tenant debe ser parte de la clave también.
Regla práctica: si la respuesta depende de autenticación, roles, geografía, nivel de precio, feature flags o tenant, tu clave de caché (o la lógica de bypass) debe reflejar esa dependencia.
El comportamiento de caching HTTP está fuertemente impulsado por headers:
Cache-Control: evita almacenamiento accidental con private / no-store cuando haga faltaVary: asegura que las caches separen respuestas por headers relevantes (p. ej., Authorization, Accept-Language)Set-Cookie: a menudo es señal de que la respuesta no debería cachearse públicamente
Cuándo evitar caché por completo
Si el cumplimiento o el riesgo es alto—PII, datos de salud/financieros, documentos legales—prefiere Cache-Control: no-store y optimiza en servidor. Para páginas mixtas, cachea solo fragmentos no sensibles o assets estáticos y mantén los datos personalizados fuera de caches compartidas.
Coste y ROI: decidir si otra capa merece la pena
Recrea la ruta de la solicitud
Levanta una pila React + Go + Postgres desde el chat para reproducir tu problema de caché.
Las capas de caché pueden reducir la carga del origen, pero rara vez son “rendimiento gratis”. Trata cada nueva caché como una inversión: compras menor latencia y menos trabajo en backend a cambio de dinero, tiempo de ingeniería y una superficie de corrección mayor.
Qué pagas vs qué ahorras
Coste extra de infraestructura vs reducción de coste de origen. Un CDN puede reducir egress y lecturas de BD, pero lo pagarás en solicitudes CDN, almacenamiento en caché y a veces llamadas de invalidación. Una caché de aplicación (Redis/Memcached) añade coste de clúster, upgrades y on-call. Los ahorros pueden verse como menos réplicas de BD, instancias más pequeñas o escalado diferido.
Victorias de latencia vs coste de frescura. Cada caché introduce “¿qué tan obsoleto es aceptable?”. Frescura estricta requiere más plumbing de invalidación (y más misses). Tolerar staleness ahorra cómputo pero puede costar confianza del usuario—especialmente en precios, disponibilidad o permisos.
Tiempo de ingeniería: velocidad de entrega vs trabajo de fiabilidad. Una nueva capa suele implicar más paths de código, más pruebas y más clases de incidentes que prevenir (estampidas, claves calientes, invalidaciones parciales). Presupuesta mantenimiento continuo, no solo la implementación inicial.
Ejecuta experimentos pequeños para medir ROI
Antes de desplegar ampliamente, haz una prueba limitada:
- Elige un endpoint o página con carga clara (p. ej., el 5% superior de tráfico).
- Define métricas de éxito: p95 de latencia, QPS BD, tasa de errores, ratio hit de caché.
- Rampa gradualmente; monitorea costes junto a rendimiento.
- Limita el experimento en el tiempo y ten un interruptor de rollback.
Lista de comprobación simple para decidir
Añade una nueva capa de caché solo si:
- El cuello de botella está probado (no supuesto) mediante métricas.
- Hay un objetivo claro (p. ej., reducir lecturas BD en 40%).
- Las reglas de estaleza e invalidación son explícitamente aceptables.
- Puedes monitorizarla (hit rate, evictions, latencia, errores).
- Los ahorros esperados superan los costes operativos y de ingeniería en un horizonte realista.
Directrices prácticas para reducir la complejidad al usar caché
La caché rinde más cuando la tratas como una característica de producto: necesita un propietario, reglas claras y una forma segura de apagarla.
Comienza pequeño y asigna responsabilidad
Añade una capa de caché a la vez (p. ej., primero CDN o caché de aplicación) y asigna un equipo/persona responsable.
Define quién posee:
- cambios de configuración (TTL, reglas de bypass)
- capacidad y comportamiento de evicción
- respuesta a incidentes (qué hacer cuando falla)
Haz las claves de caché aburridas y predecibles
La mayoría de bugs de caché son realmente “bugs de clave”. Usa una convención documentada que incluya las entradas que cambian la respuesta: scope tenant/usuario, locale, clase de dispositivo y feature flags relevantes.
Añade versionado explícito de claves (p. ej., product:v3:...) para poder invalidar de forma segura subiendo una versión en lugar de intentar borrar millones de entradas.
Prefiere estaleza acotada sobre frescura perfecta
Intentar mantener todo perfectamente fresco empuja la complejidad a cada ruta de escritura.
En su lugar, decide qué “obsolescencia aceptable” significa por endpoint (segundos, minutos o “hasta el siguiente refresco”) y encrústalo con:
- TTLs que casen con expectativas de negocio
- refresco en background (servir obsoletos mientras se actualiza)
- invalidación basada en eventos solo para datos realmente sensibles
Construye valores por defecto seguros para fallos
Asume que la caché será lenta, errónea o estará caída.
Usa timeouts y circuit breakers para que las llamadas a la caché no tumben tu ruta de petición. Haz explícita la degradación: si la caché falla, vuelve al origen con límites de tasa, o sirve una respuesta mínima.
Despliega con controles y runbooks
Publica la caché tras un canary o rollout por porcentaje y mantén un interruptor de bypass (por ruta o header) para depuración rápida.
Documenta runbooks: cómo purgar, cómo subir versiones de clave, cómo desactivar la caché temporalmente y dónde revisar métricas. Enlázalos desde la página interna de runbooks para que on-call pueda actuar rápido.
Prototipar cambios de caché sin frenar la entrega
El trabajo de caché suele atascarse porque toca varias capas (headers, lógica de app, modelos de datos y planes de rollback). Una forma de reducir el coste de iteración es prototipar la ruta completa de petición en un entorno controlado.
Con Koder.ai, los equipos pueden levantar rápidamente un stack realista (React web, backends en Go con PostgreSQL e incluso clientes móviles Flutter) desde un flujo guiado por chat, y luego probar decisiones de caché (TTL, diseño de claves, stale-while-revalidate) de punta a punta. Funciones como planning mode ayudan a documentar el comportamiento de caché previsto antes de implementarlo, y snapshots/rollback hacen más seguro experimentar con configuraciones de caché o lógica de invalidación. Cuando estés listo, puedes exportar código fuente o desplegar/conectar dominios—útil para pruebas de rendimiento que necesiten reflejar tráfico de producción.
Si usas una plataforma así, trátala como complemento a la observabilidad de producción: el objetivo es iterar más rápido en el diseño de caché manteniendo claros los requisitos de corrección y los procedimientos de rollback.