Por qué los cambios de esquema causan interrupciones
La indisponibilidad por un cambio en la base de datos no siempre es una caída clara y obvia. Para los usuarios puede parecer una página que carga infinitamente, un pago que falla o una app que de repente muestra "algo salió mal". Para los equipos se manifiesta como alertas, aumento de tasas de error y una acumulación de escrituras fallidas que hay que limpiar.
Los cambios de esquema son arriesgados porque la base de datos es compartida por todas las versiones de la app que estén ejecutándose. Durante un despliegue suele haber código viejo y nuevo conviviendo (despliegues rolling, múltiples instancias, jobs en segundo plano). Una migración que parece correcta aún puede romper alguna de esas versiones.
Los fallos habituales incluyen:
- El código nuevo escribe en una columna que aún no existe, provocando errores inmediatos.
- El código antiguo lee una columna o tabla que la migración renombró o eliminó, causando fallos tras el deploy.
- Un backfill o la creación de un índice dispara la CPU o bloquea filas, haciendo lentas las peticiones normales o provocando timeouts.
- Un cambio "rápido" de restricción (como NOT NULL) bloquea escrituras mientras se valida la tabla.
Incluso cuando el código está bien, los despliegues quedan bloqueados porque el problema real es la compatibilidad temporal entre versiones. Los cambios sin tiempo de inactividad siguen una regla: cada estado intermedio debe ser seguro para código viejo y nuevo. Cambias la base de datos sin romper lecturas ni escrituras existentes, despliegas código que puede manejar ambas formas y eliminas la ruta antigua solo cuando nadie depende ya de ella.
Ese esfuerzo extra vale la pena cuando tienes tráfico real, SLAs estrictos o muchas instancias y workers. Para una herramienta interna pequeña con poca actividad, una ventana de mantenimiento planificada puede ser más simple.
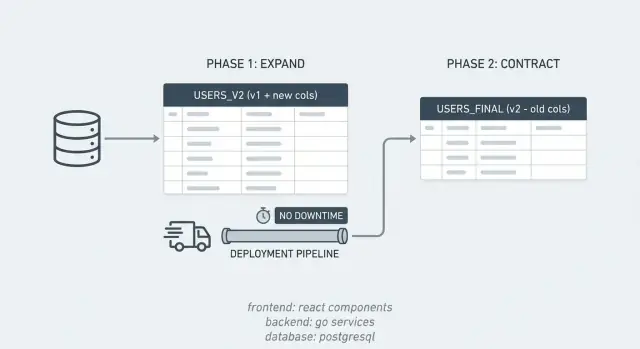
Expandir/contraer en palabras sencillas
La mayoría de los incidentes por trabajo de base de datos ocurren porque la app espera que el cambio sea instantáneo, mientras que el cambio en la base de datos tarda. El patrón expandir/contraer evita eso dividiendo un cambio arriesgado en pasos más pequeños y seguros.
Durante un tiempo, tu sistema soporta dos "dialectos" a la vez. Introduces la nueva estructura primero, mantienes la antigua en funcionamiento, mueves datos gradualmente y luego limpias.
El patrón es simple:
- Expandir: añade lo que necesitas (columnas, tablas, índices) sin romper la app actual.
- Ejecutar ambos caminos: despliega código que funcione con las estructuras vieja y nueva para que las versiones mixtas sigan comportándose.
- Contraer: cuando todo use la nueva estructura, elimina el esquema antiguo y el código antiguo.
Esto encaja bien con despliegues rolling. Si actualizas 10 servidores uno a uno, durante un tiempo tendrás versiones viejas y nuevas juntas. Expandir/contraer mantiene ambas compatibles con la misma base de datos durante ese solapamiento.
También hace que los rollbacks sean menos peligrosos. Si una nueva versión tiene un bug, puedes revertir la app sin revertir la base de datos, porque las estructuras antiguas aún existen durante la ventana de expandir.
Ejemplo: quieres dividir una columna full_name de PostgreSQL en first_name y last_name. Añades las nuevas columnas (expandir), publicas código que puede leer y escribir ambas formas, haces el backfill de filas antiguas y luego eliminas full_name cuando estés seguro de que nadie lo usa (contraer).
Qué suele incluir "expandir"
La fase de expandir trata de añadir nuevas opciones, no de quitar las antiguas.
Un movimiento común es añadir una nueva columna. En PostgreSQL, normalmente es más seguro añadirla como nullable y sin default. Añadir una columna no nula con default puede provocar una reescritura de la tabla o bloqueos más fuertes, según la versión de Postgres y el cambio exacto. Una secuencia más segura es: añadir nullable, desplegar código tolerante, backfill y luego aplicar NOT NULL.
Los índices también requieren cuidado. Crear un índice normal puede bloquear escrituras más tiempo del esperado. Cuando sea posible, usa la creación de índices concurrente para que lecturas y escrituras sigan fluyendo. Tarda más, pero evita bloqueos que detengan el release.
Expandir también puede significar añadir tablas nuevas. Si pasas de una sola columna a una relación many-to-many, puedes añadir una tabla de unión manteniendo la columna antigua. La ruta antigua sigue funcionando mientras la nueva estructura empieza a recoger datos.
En la práctica, expandir suele incluir:
- Añadir nuevas columnas nullable o tablas nuevas junto a las existentes
- Crear índices de forma no bloqueante cuando sea posible
- Usar feature flags para controlar cuándo se activan nuevas lecturas o escrituras
- Escribir en ambos campos (dual-write) cuando haga falta
- Mantener lecturas retrocompatibles (antigua, nueva o fallback)
Tras expandir, las versiones viejas y nuevas de la app deberían poder ejecutarse al mismo tiempo sin sorpresas.
Desplegar código que sea compatible
La mayor parte del dolor en releases ocurre en el medio: algunos servidores ejecutan código nuevo, otros siguen con el antiguo, mientras la base de datos ya está cambiando. Tu objetivo es claro: cualquier versión durante el despliegue debe funcionar con el esquema viejo y el expandido.
Un enfoque común es el dual-write. Si añades una nueva columna, la app nueva escribe en la columna antigua y en la nueva. Las versiones antiguas siguen escribiendo solo en la antigua, que sigue existiendo. Mantén la nueva columna opcional al principio y retrasa las restricciones estrictas hasta que estés seguro de que todos los escritores se han actualizado.
Las lecturas suelen cambiarse con más cuidado que las escrituras. Durante un tiempo, mantén las lecturas en la columna antigua (la que sabes que está completamente poblada). Tras el backfill y la verificación, cambia las lecturas para preferir la columna nueva, con fallback a la antigua si la nueva está vacía.
También conserva estable la salida de tu API mientras la base de datos cambia por debajo. Aunque introduzcas un campo interno nuevo, evita cambiar la forma de las respuestas hasta que todos los consumidores estén listos (web, móvil, integraciones).
Un despliegue amigable con rollback suele verse así:
- Release 1: añade la nueva columna y publica código que pueda leer datos antiguos y escribir en ambas columnas.
- Release 2: backfill de filas existentes y publica código que prefiera la nueva columna pero pueda hacer fallback.
- Release 3: deja de escribir en la columna antigua (pero mantenla presente).
- Release 4: elimina las lecturas antiguas y luego elimina la columna antigua.
La idea clave es que el primer paso irreversible es eliminar la estructura antigua, así que lo dejas para el final.
El backfill es donde muchas migraciones "sin tiempo de inactividad" fallan. Quieres rellenar la nueva columna para filas existentes sin locks largos, consultas lentas ni picos de carga inesperados.
Los lotes importan. Apunta a batches que terminen rápido (segundos, no minutos). Si cada lote es pequeño, puedes pausar, reanudar y ajustar el job sin bloquear releases.
Para seguir el progreso, usa un cursor estable. En PostgreSQL eso suele ser la clave primaria. Procesa filas en orden y guarda el último id completado, o trabaja por rangos de id. Esto evita escaneos completos de tabla caros cuando el job se reinicia.
Aquí hay un patrón simple:
UPDATE my_table
SET new_col = ...
WHERE new_col IS NULL
AND id > $last_id
ORDER BY id
LIMIT 1000;
Haz la actualización condicional (por ejemplo, WHERE new_col IS NULL) para que el job sea idempotente. Las reejecuciones solo tocarán filas que aún necesitan trabajo, lo que reduce escrituras innecesarias.
Planifica que lleguen datos nuevos durante el backfill. El orden habitual es:
- Actualizar primero el código de la aplicación para que las escrituras nuevas también llenen el nuevo campo.
- Backfill de filas históricas en lotes.
- Ejecutar un bucle corto de puesta al día que reconsidere filas recientes.
- Si hace falta, añadir una salvaguarda (como un trigger o un default) para evitar nuevos NULL.
Un buen backfill es aburrido: constante, medible y fácil de pausar si la base de datos se calienta.
Verificar que la migración está realmente hecha
El momento más arriesgado no es añadir la columna nueva. Es decidir que puedes confiar en ella.
Antes de pasar a contract, demuestra dos cosas: los datos nuevos están completos y la producción los ha estado leyendo sin problemas.
Empieza con comprobaciones de completitud rápidas y repetibles:
- Confirma que la nueva columna no tiene NULLs inesperados.
- Compara cuántas filas eran elegibles frente a cuántas se llenaron.
- Revisa manualmente un puñado de IDs y compara valores antiguos y nuevos.
- Prueba casos límite (cadenas vacías, cero, registros muy antiguos).
- Repite las mismas comprobaciones más tarde para asegurarte de que no hay deriva.
Si estás dual-writing, añade una comprobación de consistencia para atrapar bugs silenciosos. Por ejemplo, ejecuta una consulta horaria que encuentre filas donde old_value <> new_value y alerta si no es cero. A menudo es la manera más rápida de descubrir que algún writer sigue actualizando solo el campo antiguo.
Vigila señales básicas en producción mientras corre la migración. Si el tiempo de consulta o las esperas por locks suben, hasta tus consultas de verificación “seguras” pueden estar añadiendo carga. Supervisa las tasas de error de cualquier camino que lea la columna nueva, especialmente justo después de despliegues.
¿Cuánto debes mantener ambos caminos? El tiempo suficiente para sobrevivir al menos un ciclo completo de releases y una reejecución del backfill. Muchos equipos usan 1–2 semanas, o hasta estar seguros de que no queda ninguna versión antigua ejecutándose.
Fase de contract: eliminar la ruta antigua
Contract es donde los equipos se ponen nerviosos porque parece el punto sin retorno. Si expand se hizo bien, contract es mayormente limpieza y puedes hacerlo en pasos pequeños y de bajo riesgo.
Elige el momento con cuidado. No elimines nada justo después de terminar un backfill. Dale al menos un ciclo completo de releases para que jobs retrasados y casos extremos tengan tiempo de aparecer.
Una secuencia de contract segura suele ser:
- Dejar de dual-write y confirmar que las escrituras nuevas van solo a la(s) columna(s) nueva(s).
- Quitar lecturas antiguas en la aplicación para eliminar el fallback.
- Borrar paths de código muertos, feature flags y jobs que referencien el esquema antiguo.
- Eliminar triggers temporales, jobs de sincronización o vistas de compatibilidad.
- Eliminar índices y restricciones antiguas, y finalmente eliminar la columna antigua.
Si puedes, divide contract en dos releases: uno que elimina referencias en el código (con logging extra) y otro posterior que elimina objetos de la base de datos. Esa separación facilita rollback y troubleshooting.
Los detalles de PostgreSQL importan aquí. Dropear una columna es mayormente un cambio de metadatos, pero aun así requiere un ACCESS EXCLUSIVE lock breve. Planifica una ventana tranquila y mantén la migración rápida. Si creaste índices extra, prefiere DROP INDEX CONCURRENTLY para no bloquear escrituras (no puede ejecutarse dentro de un bloque de transacción, así que tu tooling de migraciones debe soportarlo).
Errores y trampas comunes
Las migraciones sin tiempo de inactividad fallan cuando la base de datos y la app dejan de ponerse de acuerdo sobre lo permitido. El patrón solo funciona si cada estado intermedio es seguro para código viejo y nuevo.
Trampas que rompen producción
Estos errores aparecen con frecuencia:
- Añadir NOT NULL demasiado pronto, mientras una versión antigua puede seguir escribiendo sin el nuevo campo.
- Hacer el backfill de una tabla enorme en una sola transacción, lo que puede mantener locks, inflar tablas y provocar timeouts.
- Suponer que un default es gratuito. En PostgreSQL, algunos defaults disparan una reescritura de tabla.
- Cambiar lecturas a la nueva columna antes de que las escrituras la estén llenando de forma fiable.
- Olvidar otros writers y readers (cron jobs, workers, exportaciones, consultas de reporting).
Un escenario realista: empiezas a escribir full_name desde la API, pero un job en segundo plano que crea usuarios solo establece first_name y last_name. Ese job corre de noche, inserta filas con full_name = NULL y luego el código asumirá que full_name siempre está presente.
Cómo evitar quedarte atascado a mitad de migración
Trata cada paso como un release que puede durar días:
- Mantén la nueva columna nullable durante la transición y aplica la obligatoriedad en el código primero.
- Backfill en pequeños lotes con pausas y vigila la carga de la BD.
- Haz el código tolerante: lee ambas rutas, escribe en ambas cuando haga falta y maneja valores faltantes.
- Audita todos los puntos que tocan la tabla, incluidos workers y reporting.
Lista rápida antes de cada release
Una checklist repetible evita que publiques código que solo funciona en un estado de base de datos.
Antes de desplegar, confirma que la base de datos ya tiene las piezas expandidas (nuevas columnas/tablas, índices creados de forma de bajo bloqueo). Luego confirma que la app es tolerante: debe funcionar contra la forma antigua, la expandida y un estado a medio backfill.
Mantén la checklist corta:
- Expansión presente: los nuevos objetos de esquema existen y se añadieron con bajo bloqueo.
- Compatibilidad real: la app funciona con esquema antiguo y expandido, incluidos workers y rutas admin.
- Backfill controlado: batches pequeños, pausables y con métricas básicas de progreso.
- Cambio de lectura planificado: sabes exactamente cuándo cambian las lecturas y cómo hacer rollback si los resultados son incorrectos.
- Contract retrasado: esperas al menos uno o dos ciclos de release antes de eliminar objetos antiguos.
Una migración solo se considera hecha cuando las lecturas usan los datos nuevos, las escrituras ya no mantienen los datos antiguos y has verificado el backfill con al menos una comprobación simple (conteos o muestreo).
Un ejemplo realista: reemplazar una columna sin downtime
Imagina una tabla customers en PostgreSQL con una columna phone que guarda valores desordenados (diferentes formatos, a veces vacía). Quieres reemplazarla por phone_e164, pero no puedes bloquear releases ni apagar la app.
Una secuencia limpia expandir/contraer sería:
- Expandir: añade
phone_e164 como nullable, sin default y sin restricciones pesadas aún.
- Despliegue compatible: actualiza el código para escribir tanto
phone como phone_e164, pero deja las lecturas en phone para que nada cambie para los usuarios.
- Backfill: convierte filas existentes en lotes pequeños (por ejemplo, 1.000 a la vez).
- Cambiar lecturas: despliega código que lea
phone_e164 primero y haga fallback a phone si sigue siendo NULL.
- Contract: cuando estés seguro de que todo usa
phone_e164, elimina el fallback, borra phone y luego añade restricciones más estrictas si las necesitas.
El rollback sigue siendo sencillo cuando cada paso es retrocompatible. Si el cambio de lectura causa problemas, revierte la app y la BD seguirá teniendo ambas columnas. Si el backfill provoca picos de carga, pausa el job, reduce el tamaño de los lotes y continúa más tarde.
Si quieres que el equipo mantenga alineamiento, documenta el plan en un solo lugar: el SQL exacto, qué release cambia lecturas, cómo mides la finalización (por ejemplo, porcentaje de phone_e164 no NULL) y quién es responsable de cada paso.
Próximos pasos: hacerlo repetible
Expandir/contraer funciona mejor cuando se vuelve rutinario. Escribe un runbook corto que el equipo pueda reutilizar para cada cambio de esquema, idealmente de una página y lo suficientemente específico como para que un nuevo compañero lo siga.
Una plantilla práctica cubre:
- Expandir (migraciones exactas)
- Cambios de código (qué debe seguir siendo retrocompatible y dónde se usa dual-read o dual-write)
- Backfill (tamaño de lote, límites de tasa, pausa/reanudar)
- Verificación (las consultas y métricas que prueban la corrección)
- Contract (qué se elimina y cuándo)
Decide la propiedad desde el principio. “Todos pensaban que alguien más haría contract” es cómo columnas antiguas y feature flags viven meses.
Aunque el backfill sea online, prográmalo cuando el tráfico sea menor. Es más fácil mantener lotes pequeños, vigilar la carga y parar rápido si la latencia sube.
Si despliegas con Koder.ai (koder.ai), Planning Mode puede ser una forma útil de mapear fases y puntos de control antes de tocar producción. Las mismas reglas de compatibilidad se aplican, pero tener los pasos escritos hace más difícil saltarse las partes "aburridas" que evitan las interrupciones.