18 ago 2025·8 min
Borrado suave vs borrado definitivo: compensaciones importantes en aplicaciones reales
Borrado suave vs borrado definitivo: conoce las compensaciones reales para analítica, soporte, eliminación al estilo GDPR y complejidad de consultas, además de patrones seguros de restauración.
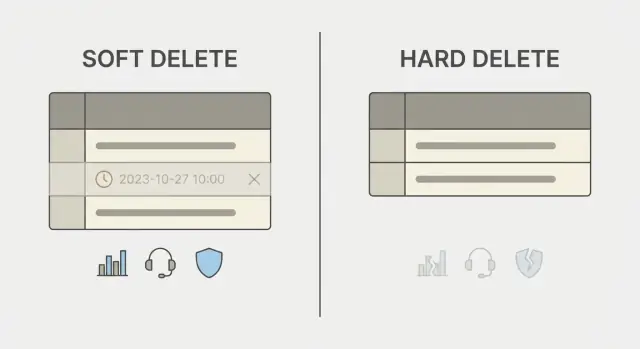
Qué significan realmente el borrado suave y el borrado definitivo
Un botón de eliminar puede significar dos cosas muy diferentes en una base de datos.
Un borrado definitivo elimina la fila. Después de eso, el registro desaparece a menos que tengas copias de seguridad, logs o réplicas que todavía lo conserven. Es fácil de razonar, pero es final.
Un borrado suave conserva la fila pero la marca como eliminada, normalmente con un campo como deleted_at o is_deleted. La aplicación trata entonces las filas marcadas como invisibles. Conservas datos relacionados, preservas historial y a veces puedes restaurar el registro.
Esta elección aparece en el trabajo diario más de lo que la gente cree. Afecta cómo respondes preguntas como: “¿Por qué bajó el ingreso el mes pasado?”, “¿Puedes recuperar mi proyecto eliminado?” o “Recibimos una solicitud de eliminación por GDPR: ¿estamos borrando realmente los datos personales?” También define qué significa “eliminado” en la interfaz. Los usuarios suelen asumir que pueden deshacerlo, hasta que no pueden.
Una regla práctica:
- Usa borrado suave cuando los usuarios esperen un deshacer, cuando soporte necesite recuperar errores o cuando necesites una pista de auditoría.
- Usa borrado definitivo cuando conservar los datos cree riesgo legal, riesgo de seguridad o costes de almacenamiento claros sin valor real.
- Usa ambos cuando quieras un período de “papelera”: primero borrado suave y luego purga permanente.
Ejemplo: un cliente elimina un espacio de trabajo y luego se da cuenta de que contenía facturas necesarias para contabilidad. Con un borrado suave, soporte puede restaurarlo (si tu app está diseñada para manejar restauraciones con seguridad). Con un borrado definitivo, probablemente tendrás que explicar copias de seguridad, retrasos o “no es posible”.
Ningún enfoque es “el mejor”. La opción menos dolorosa depende de lo que necesites proteger: la confianza del usuario, la precisión de los informes o el cumplimiento de privacidad.
Compensaciones en analítica: precisión vs conservar historial
Las decisiones de eliminación aparecen rápido en analítica. El día que empiezas a medir usuarios activos, conversión o ingresos, “eliminado” deja de ser un estado simple y se vuelve una decisión de reporte.
Si haces borrado definitivo, muchas métricas se ven limpias porque los registros eliminados desaparecen de las consultas. Pero también pierdes contexto: suscripciones pasadas, tamaño de equipo histórico o cómo fue el embudo el mes pasado. Un cliente eliminado puede hacer que los gráficos históricos cambien al volver a ejecutar informes, lo cual asusta a finanzas y revisiones de crecimiento.
Si haces borrado suave, conservas el historial, pero puedes inflar números accidentalmente. Un simple “COUNT users” puede incluir personas que se fueron. Un gráfico de churn puede contar dos veces si tratas deleted_at como churn en un reporte y lo ignoras en otro. Incluso los ingresos se pueden complicar si las facturas quedan pero la cuenta está marcada como eliminada.
Lo que suele funcionar es elegir un patrón de reporte consistente y mantenerlo:
- Filtrar registros eliminados en métricas de “estado actual” (usuarios activos, MRR actual).
- Usar tablas de snapshot para dashboards temporales para que el historial no cambie cuando las entidades se eliminen luego.
- Separar hechos de entidades: mantener filas inmutables de eventos (pagos, inicios de sesión) incluso si ocultas el registro del usuario.
- Tratar “eliminado” como un estado de ciclo de vida con su propia fecha y reportarlo explícitamente (creado, activado, eliminado).
- Definir ventanas de retención: cuándo los datos borrados suavemente pasan a eliminarse de verdad.
La clave es documentación para que los analistas no adivinen. Escribe qué significa “activo”, si se incluyen usuarios borrados suavemente y cómo se atribuyen ingresos si una cuenta se elimina después.
Ejemplo concreto: un espacio de trabajo se elimina por error y luego se restaura. Si tu dashboard cuenta espacios sin filtrar, verás una caída y recuperación súbita que en realidad no ocurrió en el uso real. Con snapshots, el gráfico histórico se mantiene estable mientras las vistas del producto pueden seguir ocultando espacios eliminados.
Soporte y pista de auditoría: qué puedes recuperar después
La mayoría de tickets de soporte sobre eliminación suenan igual: “Lo eliminé por error” o “¿Dónde está mi registro?” Tu estrategia de eliminación decide si soporte puede responder en minutos o si la única respuesta honesta es “Se fue”.
Con borrado suave, normalmente puedes verificar qué pasó y deshacerlo. Con borrado definitivo, soporte suele depender de copias de seguridad (si existen), y eso puede ser lento, incompleto o imposible para un solo elemento. Por eso la elección no es solo un detalle de la base de datos. Define qué tan “útil” puede ser tu producto cuando algo sale mal.
Una pista de auditoría simple (qué almacenar)
Si esperas soporte real, añade algunos campos que expliquen eventos de eliminación:
deleted_at(timestamp)deleted_by(id de usuario o sistema)delete_reason(opcional, texto corto)deleted_from_ipodeleted_from_device(opcional)restored_atyrestored_by(si soportas restauración)
Incluso sin un registro de actividad completo, estos detalles permiten a soporte responder: quién lo eliminó, cuándo ocurrió y si fue un accidente o una limpieza automatizada.
Qué implican los borrados definitivos para soporte
Los borrados definitivos pueden estar bien para datos temporales, pero para registros visibles al usuario cambian lo que soporte puede hacer.
Soporte no puede restaurar un solo registro a menos que hayas construido una papelera en otro lugar. Puede necesitar una restauración completa desde backup, lo que puede afectar otros datos. Tampoco puede probar fácilmente qué pasó, lo que lleva a largos intercambios.
Las funciones de restauración cambian la carga de trabajo también. Si los usuarios pueden auto-restaurarse dentro de una ventana de tiempo, los tickets bajan. Si la restauración requiere acción manual de soporte, los tickets pueden aumentar, pero se vuelven rápidos y repetibles en lugar de investigaciones puntuales.
Eliminación estilo GDPR: el borrado suave no es borrado completo
El “derecho a ser olvidado” suele significar que debes dejar de procesar los datos de una persona y eliminarlos de los lugares donde aún son utilizables. No siempre significa que debas borrar inmediatamente todos los agregados históricos, pero sí que no deberías conservar datos identificables “por si acaso” si ya no tienes una razón legal para guardarlos.
Aquí es donde el borrado suave vs borrado definitivo deja de ser solo una decisión de producto. Un borrado suave (como poner deleted_at) a menudo solo oculta el registro en la app. Los datos siguen en la base de datos, siguen siendo consultables por administradores y a menudo siguen presentes en exportaciones, índices de búsqueda y tablas analíticas. Para muchas solicitudes de eliminación bajo GDPR, eso no es borrado.
Aún necesitas una purga cuando:
- Un usuario solicita eliminación y no tienes una razón de retención válida (por ejemplo, reglas de facturación).
- Almacenaste datos de categorías especiales y tu política exige su eliminación.
- El registro aparece en exportaciones visibles para usuarios o puede ser recuperado por soporte.
- Un tercero (email, analítica, herramientas de soporte) todavía lo conserva.
Las copias de seguridad y los logs son la parte que los equipos olvidan. Puede que no puedas borrar una sola fila de una copia de seguridad cifrada, pero puedes definir una regla: las copias de seguridad expiran rápido y las restauraciones deben re-aplicar los eventos de eliminación antes de que el sistema vuelva a estar en producción. Los logs deberían evitar guardar datos personales en bruto cuando sea posible y tener límites claros de retención.
Una política simple y práctica es un borrado en dos pasos:
- Borrado suave inmediatamente (para que el producto se comporte correctamente, las cuentas se desactiven y “restaurar registros eliminados” funcione en errores).
- Iniciar un temporizador de retención (por ejemplo, 7 a 30 días) y programar un job de purga que haga borrado definitivo o anonimice campos personales.
- Registrar lo ocurrido en una pista de auditoría usando marcadores no identificativos (timestamps, códigos de razón) para que soporte pueda explicar acciones sin conservar los datos.
Si tu plataforma soporta exportes de código fuente o exportes de datos, trata esos archivos exportados como almacenes de datos también: define dónde viven, quién puede acceder y cuándo se borran.
Complejidad de consultas y comportamiento del producto: el coste oculto
Diseña tu política de borrado
Usa el modo de planificación para definir reglas de restauración, purga y auditoría antes de construir.
El borrado suave suena simple: añade deleted_at (o is_deleted) y oculta la fila. El coste oculto es que cada lugar donde lees datos ahora debe recordar ese flag. Si lo olvidas una vez, obtienes bugs extraños: totales que incluyen elementos eliminados, búsquedas que muestran resultados “fantasma” o un usuario ve algo que creía borrado.
Los casos límite de UI y UX aparecen rápido. Imagina que un equipo elimina un proyecto llamado “Roadmap” y después intenta crear uno nuevo con el mismo nombre. Si tu base de datos tiene una regla única en el nombre, la creación puede fallar porque la fila eliminada aún existe. La búsqueda también puede confundir a la gente: si ocultas elementos eliminados en listados pero no en la búsqueda global, los usuarios pensarán que tu app está rota.
Los filtros de borrado suave suelen olvidarse en:
- Dashboards administrativos y herramientas de soporte
- Jobs en segundo plano (emails, recordatorios, limpiezas)
- Consultas y exportaciones de analítica
- Chequeos de permisos (“¿existe este registro?”)
- Autocompletar y búsqueda
El rendimiento suele estar bien al principio, pero la condición extra añade trabajo. Si la mayoría de filas están activas, filtrar deleted_at IS NULL es barato. Si muchas filas están eliminadas, la base de datos debe saltarse más filas a menos que añadas el índice correcto. En términos sencillos: es como buscar documentos actuales en un cajón que también contiene muchos antiguos.
Un área de “Archivo” separada puede reducir la confusión. Haz que la vista por defecto muestre solo registros activos y coloca los elementos eliminados en un lugar con etiquetas claras y una ventana temporal. En herramientas construidas rápidamente (por ejemplo, apps internas hechas en Koder.ai), esta decisión de producto suele prevenir más tickets de soporte que cualquier truco de consulta.
Modelos de datos comunes para borrado suave
El borrado suave no es una sola característica. Es una elección de modelo de datos y el modelo que elijas modelará todo lo que venga: reglas de consulta, comportamiento de restauración y qué significa “eliminado” para tu producto.
Modelo 1: deleted_at más deleted_by
El patrón más común es un timestamp nullable. Cuando se elimina un registro, se pone deleted_at (y a menudo deleted_by con el id del usuario). Los registros “activos” son aquellos donde deleted_at es null.
Esto funciona bien cuando necesitas una restauración limpia: restaurar es simplemente limpiar deleted_at y deleted_by. También da a soporte una señal de auditoría simple.
Modelo 2: estados explícitos
En lugar de un timestamp, algunos equipos usan un campo status con estados claros como active, archived y deleted. Esto es útil cuando “archivado” es un estado real del producto (oculto en la mayoría de pantallas pero aún contado en facturación, por ejemplo).
El coste son reglas. Debes definir qué significa cada estado en todas partes: búsqueda, notificaciones, exportaciones y analítica.
Modelo 3: almacenamiento separado para registros de alto valor
Para objetos sensibles o de alto valor, puedes mover filas eliminadas a una tabla separada o registrar un evento en un log append-only.
- Borrado suave por timestamp:
deleted_at,deleted_by - Máquina de estados:
statuscon estados nombrados - Tabla separada de eliminados: la tabla “activa” se mantiene pequeña
- Log de eventos: guarda “quién hizo qué” sin mantener filas completas para siempre
Esto se usa cuando las restauraciones deben controlarse estrictamente o cuando quieres una pista de auditoría sin mezclar datos eliminados en las consultas diarias.
Los registros hijos también necesitan una regla intencional. Si se elimina un workspace, ¿qué pasa con proyectos, archivos y membresías?
- Cascade: marcar hijos como eliminados también
- Restrict: bloquear la eliminación hasta que los hijos se manejen
- Archive: convertir hijos a
archived(no eliminados) - Detach: quitar relaciones pero conservar al hijo
Elige una regla por relación, escríbela y mantenla consistente. La mayoría de bugs de “la restauración falló” vienen de padres e hijos que usan significados diferentes de eliminado.
Cómo implementar una función de restauración segura (paso a paso)
Un botón de restaurar suena simple, pero puede romper silenciosamente permisos, resucitar datos antiguos en el lugar equivocado o confundir a usuarios si “restaurado” no significa lo que esperan. Empieza escribiendo la promesa exacta que hace tu producto.
Un flujo de restauración práctico
Usa una secuencia pequeña y estricta para que la restauración sea predecible y auditable.
- Define qué significa “restaurar”. ¿El registro conserva el mismo ID? ¿Vuelve al mismo padre (workspace, proyecto) y mantiene las mismas relaciones? Decide qué pasa con membresías, roles y visibilidad.
- Haz que el usuario confirme y captura una razón. Muestra lo que se restaurará (nombre, propietario, fecha de última modificación) y exige una confirmación clara. Para equipos de soporte, un campo de razón corto (“eliminado por error”, “cerrando ticket”) suele ser suficiente.
- Comprueba conflictos antes de cambiar nada. Problemas comunes: el nombre antiguo fue reutilizado, el usuario ya no tiene permiso o registros relacionados fueron borrados definitivamente. Elige una regla: bloquear la restauración con un mensaje claro o restaurar a un estado seguro “necesita revisión”.
- Registra la acción de restauración. Guarda quién restauró, cuándo, desde dónde (UI, API) y qué cambió. Esto ayuda en auditorías y soporte, y es esencial cuando alguien pregunta “¿por qué volvió esto?”.
- Añade un límite temporal cuando corresponda. Muchas apps permiten restauraciones por 30 o 90 días y luego requieren un proceso de recuperación diferente o lo tratan como permanente.
Si construyes apps rápidamente en una herramienta guiada por chat como Koder.ai, mantén estas comprobaciones como parte del flujo generado para que cada pantalla y endpoint siga las mismas reglas.
Errores comunes y trampas a evitar
Exporta el código cuando estés listo
Genera la app y luego exporta la base de código para mantener control total.
El mayor dolor con los borrados suaves no es el borrado en sí, sino todos los lugares que olvidan que el registro está “muerto”. Muchos equipos eligen borrado suave por seguridad y luego muestran elementos eliminados en resultados de búsqueda, badges o totales. Los usuarios notan rápido cuando un dashboard dice “12 proyectos” pero solo aparecen 11 en la lista.
Un segundo problema común es el control de acceso. Si un usuario, equipo o workspace está borrado suavemente, no debería poder iniciar sesión, llamar a la API o recibir notificaciones. Esto suele fallar cuando la verificación de inicio de sesión busca por email, encuentra la fila y nunca revisa el flag de eliminado.
Trampas comunes que generan tickets de soporte después:
- Olvidar el filtro de eliminado en un camino de lectura (vistas admin, exportes, búsqueda, jobs en segundo plano).
- Restaurar registros que colisionan con campos únicos (email, username, slug, número de factura).
- Eliminar un padre pero dejar hijos “activos” (o eliminar hijos mientras el padre parece vivo).
- Contar filas eliminadas en analítica, cuotas o facturación.
- Enviar datos eliminados a terceros porque integraciones y jobs de sincronización no entienden “eliminado”.
Las colisiones de unicidad son especialmente desagradables durante la restauración. Si alguien crea una cuenta nueva con el mismo email mientras la vieja está borrada suavemente, una restauración falla o sobreescribe la identidad equivocada. Decide la regla con antelación: bloquear la reutilización hasta la purga, permitir la reutilización pero deshabilitar la restauración, o restaurar con un nuevo identificador.
Un escenario común: un agente de soporte restaura un workspace borrado suavemente. El workspace vuelve, pero sus miembros siguen eliminados y una integración reanuda la sincronización de registros antiguos con una herramienta externa. Desde la vista del usuario, la restauración “funcionó a medias” y generó un nuevo lío.
Antes de lanzar restauración, haz explícitos estos comportamientos:
- Qué significa “eliminado” para login, acceso a API y notificaciones
- Cómo maneja la restauración campos únicos y propiedad
- Cómo siguen los registros relacionados al padre (todo o nada evita sorpresas)
- Cómo tratan exportes e integraciones los datos eliminados (excluir, marcar o enviar marcas de lápida)
Ejemplo realista: un workspace eliminado por error
Un equipo SaaS B2B tiene un botón “Eliminar workspace”. Un viernes, un admin hace una limpieza y elimina 40 workspaces que parecían inactivos. El lunes, tres clientes se quejan de que sus proyectos desaparecieron y piden una restauración inmediata.
El equipo asumió que la decisión sería simple. No lo fue.
Primer problema: soporte no puede restaurar lo que se eliminó realmente. Si la fila del workspace se borró definitivamente y cascada eliminó proyectos, archivos y membresías, la única opción son backups. Eso significa tiempo, riesgo y una respuesta incómoda al cliente.
Segundo problema: la analítica parece rota. El dashboard cuenta “workspaces activos” consultando solo filas donde deleted_at IS NULL. La eliminación accidental hace que los gráficos muestren una caída súbita en adopción. Peor aún, un informe semanal compara con la semana anterior y marca un pico de churn falso. Los datos no se perdieron, pero se excluyeron en los lugares equivocados.
Tercer problema: llega una solicitud de privacidad para uno de los usuarios afectados. Piden eliminar sus datos personales. Un borrado suave puro no satisface esto. El equipo necesita un plan para purgar campos personales (nombre, email, logs IP) mientras conserva agregados no personales como totales de facturación y números de factura.
Cuarto problema: todos preguntan “¿Quién hizo clic en eliminar?” Si no hay rastro, soporte no puede explicar qué pasó.
Un patrón más seguro es tratar la eliminación como un evento con metadatos claros:
- Marcar el workspace como eliminado (y ocultarlo en el producto)
- Registrar
deleted_by,deleted_aty una razón o id de ticket - Loguear lo que se verá afectado (número de proyectos, asientos, almacenamiento)
- Permitir restauración en una ventana de tiempo y luego purgar campos personales seleccionados cuando sea necesario
Este es el tipo de flujo que los equipos suelen construir rápidamente en plataformas como Koder.ai y luego se dan cuenta de que la política de eliminación necesita tanto diseño como las funcionalidades alrededor.
Lista de verificación rápida para elegir la estrategia correcta de eliminación
Lanza herramientas administrativas para soporte
Crea pantallas internas para encontrar, restaurar y revisar elementos eliminados de forma segura.
Elegir entre borrado suave y borrado definitivo tiene menos que ver con preferencias y más con lo que tu app debe garantizar después de que un registro esté “fuera”. Haz estas preguntas antes de escribir una sola consulta.
- ¿Necesitas alguna vez borrado real? Si debes atender solicitudes de privacidad o legales, planifica la eliminación verdadera (y copias de seguridad, exportes y caches también). Un flag de borrado suave no basta.
- ¿Necesitas un botón de restaurar, y por cuánto tiempo? Si el “deshacer” importa, decide la ventana de restauración (7 días, 30 días, siempre) y qué pasa cuando expira.
- ¿Los reportes necesitarán los datos antiguos después de la eliminación? Algunos equipos quieren que los gráficos reflejen lo que los usuarios ven hoy; otros necesitan cuentas históricas para finanzas o análisis de crecimiento. Tu elección de eliminación cambia qué significan “usuarios activos” e “ingresos totales”.
- ¿Soporte puede explicar lo ocurrido sin trabajo de detective? Si esperas tickets como “mi proyecto desapareció”, necesitas una pista clara: quién lo borró, cuándo y desde dónde, más datos suficientes para investigar.
- ¿Tu equipo puede mantener el comportamiento consistente en todas partes? Los borrados suaves suelen crear reglas ocultas: cada consulta debe filtrar registros eliminados, cada join debe comportarse y cada pantalla debe coincidir en qué significa “eliminado”.
Una forma simple de comprobar la decisión es escoger un incidente realista y repasarlo. Por ejemplo: alguien elimina un workspace por error un viernes por la noche. El lunes, soporte debe ver el evento de eliminación, restaurarlo de forma segura y evitar revivir datos relacionados que deban permanecer eliminados. Si construyes una app en una plataforma como Koder.ai, define estas reglas pronto para que tu backend y UI generados sigan una política única en lugar de esparcir casos especiales por el código.
Próximos pasos: elige una política y constrúyela con seguridad
Elige tu enfoque escribiendo una política simple que puedas compartir con tu equipo y soporte. Si no está por escrito, derivará y los usuarios notarán la inconsistencia.
Empieza con un conjunto claro de reglas:
- Qué se borra suavemente (y cuánto tiempo permanece restaurable)
- Qué se borra definitivamente inmediatamente (y por qué)
- Cuándo se purgan los datos borrados suavemente (por ejemplo tras X días)
- Quién puede restaurar y qué prueba o aprobación se requiere
- Cómo se manejan las solicitudes de eliminación por privacidad de extremo a extremo
Luego construye dos caminos claros que no se mezclen: una vía de “restauración admin” para errores y una vía de “purga por privacidad” para la eliminación real. La vía de restauración debe ser reversible y registrada. La vía de purga debe ser final y eliminar o anonimizar todos los datos relacionados que puedan identificar a una persona, incluidas copias de seguridad o exportes si tu política lo exige.
Añade salvaguardas para que los datos eliminados no se filtren de nuevo al producto. La forma más fácil es tratar “eliminado” como un estado de primera clase en tus tests. Añade puntos de revisión para cualquier nueva consulta, página de lista, búsqueda, exporte y job de analítica. Una buena regla: si una pantalla muestra datos visibles al usuario, debe tener una decisión explícita sobre registros eliminados (ocultar, mostrar con etiqueta o solo admin).
Si estás en etapas tempranas, prototipa ambos flujos antes de consolidar el esquema. En Koder.ai puedes bosquejar la política de eliminación en modo planificación, generar el CRUD básico y probar escenarios de restauración y purga rápido, ajustando el modelo de datos antes de comprometerlo.