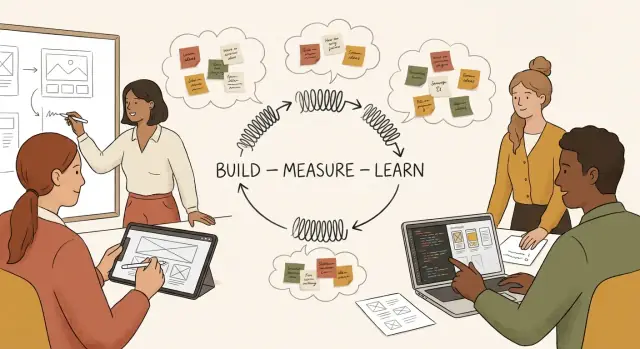
Was wir mit Vibe Coding und dem Build–Measure–Learn‑Loop meinen
Produkt‑Discovery ist größtenteils ein Lernproblem: Man versucht herauszufinden, was Menschen wirklich brauchen, was sie nutzen und wofür sie bezahlen würden – bevor man Monate in das falsche Produkt investiert.
Der Build–Measure–Learn‑Loop (in einfachen Worten)
Der Build–Measure–Learn‑Loop ist ein einfacher Zyklus:
- Build: Erstelle das kleinste Ding, das eine konkrete Annahme testet (ein Prototyp, eine Landingpage, ein Concierge‑Workflow, ein klickbares Demo).
- Measure: Beobachte, was passiert, mithilfe von Signalen, denen du vertraust (Aktivierung, Aufgabenerfüllung, Bereitschaft für einen Anruf, Retention, qualitatives Feedback).
- Learn: Entscheide, was als Nächstes zu tun ist – iterieren, pivotieren oder stoppen – basierend auf Evidenz, nicht Bauchgefühl.
Das Ziel ist nicht „schneller bauen“. Es ist die Zeit zwischen einer Frage und einer verlässlichen Antwort zu reduzieren.
Was wir hier mit „vibe coding“ meinen
Im Produktkontext ist vibe coding schnelles, exploratives Bauen – oft mit KI‑Unterstützung – bei dem du dich darauf konzentrierst, die Absicht auszudrücken („mach einen Flow, der Nutzern erlaubt X zu tun") und schnell lauffähige Software zu formen, die sich echt genug anfühlt, um sie zu testen.
Es ist nicht dasselbe wie unordentlichen Produktionscode zu deployen. Es ist eine Methode, um:
- Ideen in benutzbare Prototypen in Stunden oder Tagen zu verwandeln,
- mehrere Ansätze kostengünstig zu erkunden,
- etwas vor Nutzer zu bringen, solange die Frage noch frisch ist.
Schnelleres Lernen, ohne Validierung zu überspringen
Vibe coding hilft nur, wenn du die richtigen Dinge misst und ehrlich bleibst, was dein Prototyp beweisen kann. Geschwindigkeit ist nützlich, wenn sie die Schleife verkürzt, ohne das Experiment zu schwächen.
Was du in diesem Guide tun wirst
Als Nächstes übersetzen wir Annahmen in Experimente, die du diese Woche durchführen kannst, bauen Prototypen, die verlässliche Signale erzeugen, fügen leichte Messungen hinzu und triffst schnellere Entscheidungen, ohne dich selbst zu täuschen.
Warum Produkt‑Discovery in echten Teams ins Stocken gerät
Produkt‑Discovery scheitert selten daran, dass Teams keine Ideen haben. Sie verlangsamt sich, weil der Weg von „wir denken, das könnte funktionieren“ zu „wir wissen es“ voller Reibung ist – vieles davon unsichtbar, wenn man die Arbeit plant.
Die alltäglichen Verzögerungen, für die niemand budgetiert
Selbst einfache Experimente bleiben am Setup hängen. Repositories müssen erstellt werden, Umgebungen konfiguriert, Analytics diskutiert, Berechtigungen angefragt und Pipelines repariert. Ein eintägiger Test verwandelt sich stillschweigend in zwei Wochen, weil die ersten Tage allein darauf verwendet werden, zu „hello world“ zu kommen.
Dann kommt die Überentwicklung. Teams behandeln einen Discovery‑Prototyp oft wie ein Produktionsfeature: saubere Architektur, Edge‑Case‑Handling, vollständiger Design‑Polish und Refactorings „damit wir es später nicht bereuen“. Aber Discovery‑Arbeit existiert, um Unsicherheit zu reduzieren, nicht um ein perfektes System auszuliefern.
Warten auf Stakeholder ist ein weiterer Loop‑Killer. Feedback‑Zyklen hängen von Reviews, Genehmigungen, Rechtsprüfungen, Markenfreigaben oder einfach davon ab, jemanden im Kalender zu bekommen. Jede Wartezeit fügt Tage hinzu, und die ursprüngliche Frage des Experiments verwässert, während Leute neue Präferenzen einbringen.
Lange Loops machen Lernen zu Meinungen
Wenn es Wochen dauert, eine Hypothese zu testen, kann das Team sich nicht auf frische Evidenz verlassen. Entscheidungen werden aus Erinnerung, interner Debatte und der lautesten Stimme getroffen:
- „Ich habe das schon gesehen – das wird nicht funktionieren.“
- „Wir müssen es richtig bauen, wenn wir es testen.“
- „Kunden haben nicht danach gefragt."
Nichts davon ist per se falsch, aber sie ersetzen direkte Signale.
Die versteckten Kosten: langsames Lernen, verpasste Zeitfenster, Frustration
Die wirklichen Kosten langsamer Discovery sind nicht nur Geschwindigkeit. Es ist verlorenes Lernen pro Monat. Märkte bewegen sich, Wettbewerber launchen, und Kundenbedürfnisse verschieben sich, während du noch dabei bist, einen Test vorzubereiten.
Teams verbrauchen außerdem Energie. Ingenieur:innen fühlen sich, als würden sie Beschäftigungsarbeit leisten. Product Manager verhandeln Prozesse statt Wert zu entdecken. Die Dynamik bricht ein, und schließlich schlagen Leute keine Experimente mehr vor, weil „wir es eh nie schaffen werden“.
Ziel: Zykluszeit komprimieren ohne Signalqualität zu senken
Geschwindigkeit allein ist nicht das Ziel. Das Ziel ist, die Zeit zwischen Annahme und Evidenz zu verkürzen und das Experiment vertrauenswürdig genug zu halten, um eine Entscheidung zu treffen. Hier kann vibe coding helfen: Setup‑ und Bau‑Reibung reduzieren, sodass Teams mehr kleine, fokussierte Tests durchführen und früher lernen können – ohne Discovery in Ratespielerei zu verwandeln.
Wie Vibe Coding den Build–Measure–Learn‑Zyklus komprimiert
Vibe coding komprimiert den Zyklus, indem aus „wir denken, das könnte funktionieren“ schnell etwas wird, das Menschen anklicken, nutzen und auf das sie reagieren können. Das Ziel ist nicht, ein perfektes Produkt früher zu shippen; es ist, schneller zu einem verlässlichen Signal zu kommen.
Wo die Zeit eingespart wird
Die meisten Discovery‑Zyklen verlangsamen sich nicht, weil Teams nicht coden können – sie verlangsamen sich wegen allem rund um den Code. Vibe coding entfernt Reibung an einigen wiederholbaren Stellen:
- Scaffolding: ein neues App‑Gerüst, Routen, Auth‑Stubs, Formulare und Basis‑Datenmodelle hochziehen, ohne einen halben Tag Setup zu verschwenden.
- UI‑Zusammenbau: brauchbare Bildschirme generieren (nicht pixel‑perfekt), damit Flow, Wortwahl und Wertversprechen früh getestet werden können.
- Integrations‑Abkürzungen: Drittanbieter‑Services mocken, Beispieldatensätze verwenden oder „echte“ Integrationen gegen dünne Adapter tauschen, sodass das Experiment sich noch realistisch verhält.
Vom „perfekten Plan“ zum „testbaren Artefakt"
Traditionelles Planen versucht oft, Unsicherheit vor dem Bauen zu reduzieren. Vibe coding kehrt das um: Baue ein kleines Artefakt, um Unsicherheit durch Nutzung zu reduzieren. Statt Edge‑Cases in Meetings zu debattieren, erschaffst du eine enge Slice, die eine Frage beantwortet – und lässt Evidenz den nächsten Schritt steuern.
Kleine, reversible Wetten
Komprimierte Loops funktionieren am besten, wenn deine Experimente:
- Klein sind: eine Hypothese, ein Kernverhalten zu testen.
- Reversibel sind: leicht wegwerfbar ohne Reue.
- Instrumentierbar sind: einfache Events oder Fragen, die dir sagen, was passiert ist.
Zeitlinie vorher/nachher (Tage → Stunden)
Vorher: 1 Tag Scoping + 2 Tage Setup/UI + 2 Tage Integration + 1 Tag QA = ~6 Tage um zu lernen „Nutzer verstehen Schritt 2 nicht.“
Nach Vibe‑Coding: 45 Minuten Scaffold + 90 Minuten Schlüsselbildschirme zusammenbauen + 60 Minuten gemockte Integration + 30 Minuten Basis‑Tracking = ~4 Stunden um dasselbe zu lernen – und am gleichen Tag erneut zu iterieren.
Wann Vibe Coding das richtige Werkzeug ist (und wann nicht)
Vibe coding ist am besten, wenn dein Ziel Lernen ist, nicht Perfektion. Wenn die Entscheidung, die du treffen willst, noch unsicher ist — „Werden Leute das nutzen?“ „Verstehen sie es?“ „Werden sie zahlen?“ — dann schlagen Geschwindigkeit und Flexibilität Politur.
Gute Kandidaten (hohes Lernpotenzial, geringe Nachteile)
Einige Bereiche, in denen vibe‑coded Experimente glänzen:
- Neue Nutzerflows: ein neu gestalteter Checkout, ein neuer „Projekt erstellen“‑Pfad oder ein vereinfachtes Einstellungs‑Screen.
- Pricing‑Seiten und Packaging‑Tests: Layout, Copy, Plan‑Namen, Add‑Ons und Upgrade‑Prompts.
- Onboarding: First‑Run‑Touren, Empty‑States, E‑Mail‑Erfassung und „Aha‑Moment“‑Scaffolding.
- Interne Tools: Admin‑Dashboards, Ops‑Utilities, Support‑Workflows – schnell zu liefern, schnell zu iterieren.
Diese lassen sich meist leicht scopen, messen und zurückrollen.
Schlechte Kandidaten (hohes Risiko, schwer zurückzunehmen)
Vibe coding ist ungeeignet, wenn Fehler teuer oder irreversibel sind:
- Safety‑kritische Features (Gesundheit, Finanzen, Sicherheitskontrollen, alles, was Nutzer schädigen kann)
- Tiefgehende Infrastruktur (Datenmodelle, Berechtigungsarchitektur, Zahlungs‑Rails, migrationsintensive Änderungen)
- Regulierte Workflows (Branchen mit Compliance‑Pflichten, bei denen Logging, Genehmigungen und Audits obligatorisch sind)
In diesen Fällen sollte KI‑unterstützte Geschwindigkeit unterstützend wirken – nicht der Haupttreiber sein.
Eine schnelle Entscheidungs‑Checkliste
Bevor du startest, beantworte vier Fragen:
- Risiko: Was ist der schlimmste glaubwürdige Ausfallmodus?
- Reversibilität: Kannst du es schnell ausschalten oder zurücksetzen?
- Abhängigkeiten: Erfordert es Koordination über Teams/Systeme hinweg?
- Audience‑Größe: Kannst du mit einem kleinen Segment oder internen Nutzern beginnen?
Wenn Risiko niedrig, Reversibilität hoch, Abhängigkeiten minimal und Audience begrenzt, ist vibe coding in der Regel geeignet.
Beginne mit „thin slices“, die sich dennoch echt anfühlen
Eine Thin Slice ist kein Fake‑Demo — es ist eine enge, End‑to‑End‑Erfahrung.
Beispiel: Anstatt „Onboarding bauen“, baue nur den First‑Run‑Screen + eine geführte Aktion + einen klaren Erfolgszustand. Nutzer können etwas Bedeutungsvolles abschließen, und du erhältst verlässliche Signale, ohne dich auf den kompletten Build festzulegen.
Annahmen in Experimente verwandeln, die du diese Woche durchführen kannst
Schnelles Iterieren hilft nur, wenn du etwas Konkretes lernst. Der einfachste Weg, eine Woche Vibe‑Coding zu vergeuden, ist „Produkt verbessern“ ohne zu definieren, was du beweisen oder widerlegen willst.
1) Beginne mit einer Lernfrage
Wähle eine einzelne Frage, die ändern würde, was ihr als Nächstes tut. Halte sie behavioral und konkret, nicht philosophisch.
Beispiel: „Werden Nutzer Schritt 2 abschließen?“ ist besser als „Mögen Nutzer das Onboarding?“ weil es auf einen messbaren Moment im Flow zielt.
2) Verwandle Annahmen in testbare Hypothesen
Schreibe deine Annahme so, dass sie sich innerhalb von Tagen prüfen lässt — nicht Monaten.
- Annahme: „Menschen werden uns genug vertrauen, um ihr Konto zu verbinden.“
- Hypothese: „Mindestens 4 von 10 Erst‑Nutzern, die den Connect‑Screen erreichen, klicken innerhalb von 60 Sekunden auf ‚Connect‘.“
Achte darauf, dass die Hypothese wer, welche Aktion und eine Schwelle enthält. Diese Schwelle verhindert, dass du jedes Ergebnis als Sieg interpretierst.
3) Definiere den kleinsten Build, der die Frage beantwortet
Vibe coding glänzt, wenn du harte Scope‑Grenzen ziehst.
Bestimme, was real sein muss (z. B. der kritische Screen, der Call‑to‑Action, die Copy), was gefälscht sein kann (Beispieldaten, manuelle Genehmigung, Platzhalter‑Integrationen) und was du nicht anfasst (Einstellungen, Edge‑Cases, Performance‑Tuning).
Wenn das Experiment Schritt 2 betrifft, räume Schritt 5 nicht auf.
4) Timebox es — und setze Abbruchbedingungen
Wähle eine Timebox und „Stop‑Conditions“, um endloses Feintuning zu vermeiden.
Beispiel: „Zwei Nachmittage zum Bauen, ein Tag, um 8 Sessions durchzuführen. Früh abbrechen, wenn 6 Nutzer hintereinander am selben Punkt scheitern.“ Das gibt dir die Erlaubnis, schnell zu lernen und weiterzugehen, statt dich in Politur zu verlieren.
Build: Schnelle Prototypen, die dennoch verlässliche Signale liefern
Geschwindigkeit hilft nur, wenn der Prototyp Signale produziert, denen du vertrauen kannst. Das Ziel in der Build‑Phase ist nicht „deployen“, sondern eine glaubwürdige Slice der Experience zu schaffen, die Nutzern erlaubt, den Kern‑Job‑to‑be‑done zu versuchen — ohne Wochen Engineering.
Beginne mit Wiederverwendung, nicht Neuerfindung
Vibe coding funktioniert am besten, wenn du zusammensetzt statt alles neu zu bauen. Verwende eine kleine Sammlung von Komponenten (Buttons, Formulare, Tabellen, Empty‑States), eine Page‑Vorlage und ein vertrautes Layout. Halte einen „Prototype Starter“ bereit, der Navigation, Auth‑Stubs und ein einfaches Designsystem bereits enthält.
Für Daten: Verwende Mock‑Daten bewusst:
- Fülle 10–30 realistische Datensätze (Namen, Daten, Preise), damit Bildschirme nicht leer wirken.
- Nutze eine einfache Fake‑API‑Schicht, sodass du später zu echten Endpoints wechseln kannst, ohne UI neu schreiben zu müssen.
Baue „genug“ UI + Wiring
Mache den kritischen Pfad echt; halte alles andere als überzeugende Simulation.
- Implementiere vollständig die eine Aktion, die du testest (z. B. „Anfrage erstellen“, „Optionen vergleichen“, „Entwurf teilen“).
- Stubbe Nebenpfade mit klaren, freundlichen Platzhaltern (z. B. „Nächster Schritt: Teammitglied einladen").
- Bevorzuge einen Happy Path plus einen gängigen Fehlerzustand (Validierungsfehler, leeres Ergebnis). Das reicht meist für Discovery.
Beobachtbarkeit von Tag 1 an hinzufügen
Wenn du es nicht messen kannst, wirst du es debattieren. Füge von Anfang an leichtes Tracking hinzu:
- Events für Schlüsselschritte (Screen angesehen, Flow gestartet, Schritt abgeschlossen)
- Zeitstempel, um Time‑to‑Value zu sehen
- Drop‑off‑Punkte (wo Nutzer den Flow abbrechen)
Halte Event‑Namen in Alltagssprache, damit alle sie lesen können.
Überspringe nicht Zugänglichkeits‑ und Copy‑Basics
Testvalidität hängt davon ab, dass Nutzer verstehen, was zu tun ist.
- Verwende klare Labels („Anfrage senden“ statt „Absenden").
- Sorge für Fokus‑Zustände, Tastaturnavigation und ausreichenden Kontrast.
- Füge dort einen Ein‑Satz‑Hilfstext hinzu, wo Verwirrung wahrscheinlich ist.
Ein Prototyp, der schnell und verständlich ist, liefert saubereres Feedback — und weniger False‑Negatives.
Measure: Leichte Instrumentierung und Feedback, die zählen
Schnelles Bauen ist nur nützlich, wenn du schnell und glaubwürdig sagen kannst, ob der Prototyp dich der Wahrheit nähergebracht hat. Bei Vibe‑Coding sollte die Messung so leichtgewichtig wie der Build sein: genug Signal für eine Entscheidung, kein komplettes Analytics‑Umbauprojekt.
Wähle den richtigen Messansatz
Passe die Methode an die Frage an, die du beantworten möchtest:
- Usability‑Sessions (5–8 Personen), wenn du warum etwas verwirrend ist oder wo Nutzer steckenbleiben, verstehen musst.
- Click‑Tests (remote, unmoderiert), wenn du Navigation, Labels oder Informationshierarchie validierst.
- Fake‑Door‑Tests, wenn du Nachfrage für ein Feature prüfen willst, bevor du es baust (Button, Pricing‑Tile oder „Zugang anfragen“‑Flow).
- A/B‑Tests, wenn du bereits Traffic hast und zwischen zwei funktionierenden Optionen wählst — nicht, wenn du die Grundlagen errätst.
Definiere Erfolgsmetriken — und Guardrails
Für Discovery wähle 1–2 primäre Outcomes, die an Verhalten gebunden sind:
- Conversion (z. B. % die eine Trial starten, Demo anfragen oder einen Schlüssel‑Schritt abschließen)
- Time‑to‑Value (z. B. Minuten bis zum ersten erfolgreichen Ergebnis)
- Fehlerrate (z. B. % die Validierungsfehler treffen oder an einem Schritt abbrechen)
Füge Guardrails hinzu, damit du dich nicht „gewinnst“, indem du Vertrauen brichst: mehr Support‑Tickets, höhere Refund‑Rate, schlechtere Completion bei Kernaufgaben.
Sei realistisch bei Stichprobengrößen
Frühe Discovery geht um Richtung, nicht statistische Sicherheit. Ein paar Sessions können große UX‑Probleme aufdecken; einige Dutzend Click‑Test‑Antworten klären Präferenzen. Spare strenge Power‑Berechnungen für Optimierung (A/B‑Tests bei hohem Traffic).
Vermeide Vanity‑Metriken
Pageviews, Time on Page und „Likes“ können gut aussehen, während Nutzer die Aufgabe nicht erfüllen. Bevorzuge Outcome‑Metriken: abgeschlossene Aufgaben, aktivierte Accounts, wiederholte Nutzung und wiederholbarer Wert.
Learn: Schnellere Entscheidungen treffen, ohne sich selbst zu täuschen
Geschwindigkeit hilft nur, wenn sie zu klaren Entscheidungen führt. Der „Learn“‑Schritt ist der Punkt, an dem Vibe Coding stillschweigend schiefgehen kann: Du baust und shipped so schnell, dass Aktivität mit Einsicht verwechselt wird. Die Lösung ist simpel — standardisiere, wie du zusammenfasst, was passiert ist, und triff Entscheidungen aus Mustern, nicht Anekdoten.
Ergebnisse in Minuten statt Meetings zusammenfassen
Zieh nach jedem Test die Signale in eine kurze „Was wir gesehen haben“‑Notiz. Achte auf:
- Themen: wiederkehrende Reaktionen („Ich erwartete X“, „Ich verstehe Y nicht").
- Verwirrungsmomente: wo Nutzer pausieren, nach Bestätigung fragen oder zurückgehen.
- Drop‑off‑Punkte: der Schritt, an dem Nutzer den Flow verlassen oder aufhören sich zu engagieren.
Versuche, jede Beobachtung nach Häufigkeit (wie oft) und Schwere (wie stark es den Fortschritt blockierte) zu etikettieren. Ein starkes Zitat ist hilfreich, aber Muster bringen Entscheidungen hervor.
Entscheiden: iterieren, pivotieren oder stoppen
Nutze eine kleine Regelmenge, damit nicht bei jeder Runde neu verhandelt wird:
- Iterieren: Das Kern‑Intent ist validiert, Ausführung ist schwach (Nutzer wollen es, aber Flow/Copy/Pricing sind unklar).
- Pivotieren: Nutzer versuchen konsequent, ein anderes Problem zu lösen als das, für das du designed hast.
- Stoppen: Das Problem fühlt sich zwar real an, aber dein Ansatz zeigt nach mehrfachen Versuchen schwachen Pull — oder der Aufwand, ein verlässliches Signal zu bekommen, übersteigt den Nutzen.
Führe eine laufende Liste (eine Zeile pro Experiment):
Hypothese → Ergebnis → Entscheidung
Beispiel:
- Hypothese: „Teams buchen einen Call nach dem Ansehen einer 2‑minütigen Demo.“
- Ergebnis: 18 Visits, 0 Buchungen; 6 fragten „Ist das für Agenturen?“
- Entscheidung: Positionierung in Richtung Agenturen pivotieren; Landingpage umschreiben; morgen retesten.
Ein Takt, der Momentum schützt
- Täglich (10–15 min): Gestern‑Ergebnis reviewen, heutige Single‑Entscheidung wählen.
- Wöchentlich (30–45 min): Herauszoomen, Experimente vergleichen und die nächste Wette wählen.
Wenn du eine Vorlage brauchst, um das zur Routine zu machen, füge sie in die Team‑Checklist in /blog/a-simple-playbook-to-start-compressing-your-loop-now ein.
Die Fallen schnellen Iterierens vermeiden
Geschwindigkeit ist nur nützlich, wenn du das Richtige lernst. Vibe coding kann deine Zykluszeit so sehr komprimieren, dass es leicht wird, „Antworten“ zu deployen, die in Wirklichkeit Artefakte davon sind, wie du gefragt, wen du gefragt oder was du zuerst gebaut hast.
Häufige Wege, wie schnelle Loops Teams täuschen
Einige Fallstricke tauchen immer wieder auf:
- Leading Questions: „Würdest du das nutzen?“ bringt oft höfliche Ja‑Antworten. Bevorzuge Fragen zu echtem Verhalten: „Wann hast du das zuletzt getan…?“
- Cherry‑picked Feedback: Ein begeisterter Nutzer kann zehn stille Nicht‑Nutzer überstimmen, wenn du nicht aufpasst.
- Overfitting auf einen Nutzer: Ein Prototyp, der an einen Workflow angepasst ist, bricht, sobald du die Stichprobe erweiterst.
Wann Geschwindigkeit die Qualität schädigt
Schnelles Iterieren kann die Qualität in zwei Wegen reduzieren: du akkumulierst versteckte Tech‑Debt (schwerer später zu ändern) und akzeptierst schwache Evidenz („es funktionierte bei mir“ wird zu „es funktioniert“). Das Risiko ist nicht, dass der Prototyp hässlich ist — das Risiko ist, dass deine Entscheidung auf Rauschen basiert.
Praktische Schutzmaßnahmen, die Lernen echt halten
Halte die Schleife schnell, aber setze Guardrails bei „Measure“ und „Learn“:
- Erfolgsmetriken vorab definieren bevor du den Prototyp zeigst. Selbst eine oder zwei Metriken (Aktivierungsrate, Task‑Completion, Time‑to‑Value) sind besseren als vibes.
- Entscheidungslog führen: Hypothese → Experiment → Ergebnis → Entscheidung. Das verhindert nachträgliches Umschreiben der Geschichte.
- Build vom Urteil trennen: Timeboxe den Build, dann halte an und reviewe die Evidenz mit frischen Augen (idealerweise jemand, der es nicht implementiert hat).
Ethik: Behandle Experimente wie echte Interaktionen
Setze klare Erwartungen: Sag Nutzer:innen, was ein Prototyp ist, welche Daten du sammelst und was als Nächstes passiert. Halte das Risiko minimal (keine sensiblen Daten ohne Notwendigkeit), ermögliche einfaches Opt‑Out und vermeide Dark‑Patterns, die Nutzer zu einem gewünschten „Erfolg“ drängen. Schnelles Lernen ist keine Entschuldigung für Überraschungen.
Team‑Workflow: Wie man um vibe‑coded Experimente herum zusammenarbeitet
Vibe coding funktioniert am besten, wenn das Team es als koordiniertes Experiment behandelt, nicht als Solo‑Sprint. Das Ziel ist, schnell gemeinsam vorzugehen und dabei die wenigen Dinge zu schützen, die später nicht einfach „repariert“ werden können.
Klare Rollen: eine Frage, ein Flow, ein schneller Build
Beginne mit Zuständigkeiten für die Kernteile:
- PM: formuliert das Lernziel („Welche Entscheidung ermöglicht dieses Experiment?“), definiert Erfolgssignale und schreibt Annahmen in klarer Sprache.
- Designer: gestaltet den Nutzerflow und die minimale UI, die den Test kohärent erscheinen lässt (Copy, Schlüsselbildschirme, Empty‑States).
- Engineer: optimiert für Geschwindigkeit und Sicherheit — wählt den einfachsten Weg zu funktionierender Software, richtet Guardrails ein und stellt die Messbarkeit sicher.
Diese Aufteilung hält das Experiment fokussiert: Der PM schützt das Warum, der Designer schützt die Nutzererfahrung, der Engineer schützt das Wie.
Grenzen: Was jedes Mal geprüft werden muss
Schnelles Iterieren braucht dennoch eine kurze, nicht verhandelbare Checkliste. Erfordere Prüfung für:
- Sicherheit und Permissions (Auth, Zugriffskontrolle, Secrets)
- Datenhandhabung (PII, Retention, Analytics‑Consent)
- Marke und rechtliche Risiken (öffentliche Aussagen, regulierte Copy)
Alles andere darf für eine Lernschleife „gut genug“ sein.
Timeboxed Discovery‑Sprints mit Demo‑Ausrichtung
Führe Discovery‑Sprints (2–5 Tage) mit zwei fixen Ritualen durch:
- 15‑minütiges tägliches Check‑in: was wir gebaut haben, was wir messen, was sich geändert hat.
- Demo am Ende (immer): zeige das funktionierende Artefakt, die Metrik‑Ansicht und die unterstützende Entscheidung.
Stakeholder mit konkreten Artefakten einbinden
Stakeholder bleiben dran, wenn sie Fortschritt sehen können. Teile:
- Ein einseitiges Experiment‑Briefing (Frage, Audience, Pass/Fail)
- Einen klickbaren Prototyp oder Live‑Link
- Eine kurze „Results‑Note“ mit Screenshots, Zahlen und der Empfehlung
Konkrete Artefakte reduzieren Meinungsstreitigkeiten — und machen „Geschwindigkeit“ vertrauenswürdig.
Vibe coding ist am einfachsten, wenn dein Stack „Etwas bauen, es an ein paar Leute ausliefern, lernen“ zur Default‑Route macht — nicht zum Spezialprojekt.
Ein leichtgewichtiger Prototype‑Stack
Eine praktische Basis sieht so aus:
- Komponentenbibliothek/Designsystem (auch klein): gemeinsame Buttons, Formulare, Empty‑States. Entfernt 80% der UI‑Reibung.
- Feature‑Flags: Experimente sicher deployen, gezielt Kohorten ansteuern und ohne Redeploy zurückrollen.
- Analytics: ein Event‑Stream mit kurzer Namenskonvention (z. B.
exp_signup_started). Tracke nur, was die Hypothese beantwortet.
- Error‑Tracking: erkenne, wenn „schnell“ versehentlich „kaputt“ wird und bewahre Vertrauen.
Wenn du bereits ein Produkt anbietest, halte diese Tools konsistent über Experimente hinweg, damit Teams das Rad nicht neu erfinden.
Wenn du einen KI‑unterstützten Build‑Workflow verwendest, hilft es, wenn das Tool schnelles Scaffolding, iterative Änderungen und sichere Rollbacks unterstützt. Zum Beispiel ist Koder.ai eine Vibe‑Coding‑Plattform, auf der Teams Web‑, Backend‑ und Mobile‑Prototypen über eine Chat‑Schnittstelle erstellen können — nützlich, wenn du schnell von Hypothese zu einem testbaren React‑Flow kommen willst und dann ohne Tage an Setup iterieren möchtest. Features wie Snapshots/Rollback und Planning‑Mode können schnelle Experimente sicherer wirken lassen (besonders bei parallelen Varianten).
Vom Prototyp zur Produktion: neu schreiben, härten oder verwerfen
Entscheide früh, welchen Weg ein Experiment gehen soll:
- Neu schreiben: wenn das Ziel war, einen Workflow zu lernen, nicht Architektur zu validieren.
- Härten: wenn das Experiment deutlich zu einem Kernfeature wird (Tests, Typen, Accessibility, Performance‑Budgets hinzufügen).
- Verwerfen: wenn das Ergebnis negativ oder mehrdeutig ist — rette es nicht mit erweitertem Scope.
Mache die Entscheidung beim Kickoff explizit und überprüfe sie nach der ersten Lern‑Meilenstein.
Technische Schuld sichtbar halten (ohne zu verlangsamen)
Nutze eine kleine Checkliste neben dem Experiment‑Ticket:
- Welche Ecken wurden abgeschnitten (Validierung, Auth, Edge‑Cases)?
- Welche Daten sind unzuverlässig (Sample‑Bias, fehlende Events)?
- Was würde bei 10× Nutzung brechen?
- Was muss getan werden, bevor ein breiter Rollout möglich ist?
Sichtbarkeit schlägt Perfektion: Das Team bleibt schnell und niemand wird später überrascht.
Ein einfacher Playbook‑Ablauf, um deine Schleife jetzt zu komprimieren
Das ist ein wiederholbarer 7–14‑Tage‑Zyklus, den du mit Vibe‑Coding (KI‑unterstütztes Programmieren + schnelles Prototyping) ausführen kannst, um unsichere Ideen in klare Entscheidungen zu verwandeln.
Der 7–14‑Tage‑Loop (mit Checkpoints)
Tag 1 — Setze die Wette (Learn → Build‑Kickoff): Wähle eine Annahme, die, wenn sie falsch ist, die Idee nicht wertvoll macht. Schreib die Hypothese und die Erfolgsmetrik.
Tage 2–4 — Bau einen testbaren Prototyp (Build): Liefere die kleinste Experience, die ein echtes Signal erzeugen kann: ein klickbarer Flow, ein Fake‑Door oder eine dünne End‑to‑End‑Slice.
Checkpoint (Ende Tag 4): Kann ein Nutzer die Kernaufgabe in unter 2 Minuten abschließen? Wenn nicht, reduziere den Scope.
Tage 5–7 — Instrumentieren + rekrutieren (Measure‑Setup): Füge nur die Events hinzu, die du wirklich brauchst, und führe 5–10 Sessions oder einen kleinen In‑Product‑Test durch.
Checkpoint (Ende Tag 7): Hast du vertrauenswürdige Daten und zitierfähige Notizen? Wenn nicht, repariere die Messung bevor du weiterbaust.
Tage 8–10 (optional) — Einmal iterieren: Mache eine gezielte Änderung, die das größte Drop‑off oder die größte Verwirrung adressiert.
Tage 11–14 — Entscheiden (Learn): Wähle: weiter, pivotieren oder stoppen. Halte fest, was du gelernt hast und was als Nächstes getestet werden soll.
Kopierbare Templates
Hypothesis statement
We believe that [target user] who [context] will [do desired action]
when we provide [solution], because [reason].
We will know this is true when [metric] reaches [threshold] within [timeframe].
Metric table
Primary metric: ________ (decision driver)
Guardrail metric(s): ________ (avoid harm)
Leading indicator(s): ________ (early signal)
Data source: ________ (events/interviews/logs)
Success threshold: ________
Experiment brief
Assumption under test:
Prototype scope (what’s in / out):
Audience + sample size:
How we’ll run it (sessions / in-product / survey):
Risks + mitigations:
Decision rule (what we do if we win/lose):
(Beachte: Die obigen Codeblöcke dürfen unverändert bleiben — sie sind Vorlagen.)
Von ad hoc zu einem Discovery‑System
Starte ad hoc (einmalige Prototypen) → werde wiederholbar (gleicher 7–14‑Tage‑Rhythmus) → erreiche verlässlich (standardisierte Metriken + Entscheidungsregeln) → entwickle dich zu systematisch (gemeinsames Annahmen‑Backlog, wöchentliche Reviews und eine Bibliothek vergangener Experimente).
Dein nächster Schritt
Wähle eine Annahme jetzt, fülle die Hypothesen‑Vorlage aus und plane den Checkpoint an Tag 4. Führe ein Experiment diese Woche durch — und lass das Ergebnis (nicht die Aufregung) entscheiden, was du als Nächstes baust.