10. Okt. 2025·8 Min
Redis für Ihre Anwendungen: Muster, Fallstricke und Tipps
Lernen Sie praktische Wege, Redis in Ihren Apps zu nutzen: Caching, Sessions, Queues, Pub/Sub und Rate Limiting — dazu Skalierung, Persistenz, Monitoring und Fallstricke.
Lernen Sie praktische Wege, Redis in Ihren Apps zu nutzen: Caching, Sessions, Queues, Pub/Sub und Rate Limiting — dazu Skalierung, Persistenz, Monitoring und Fallstricke.
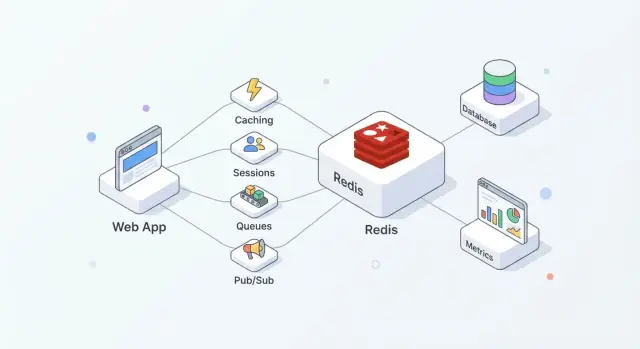
Redis ist ein In-Memory-Datenspeicher, der oft als gemeinsame „schnelle Schicht“ für Anwendungen eingesetzt wird. Teams schätzen ihn, weil die Einführung unkompliziert ist, häufige Operationen extrem schnell beantwortet werden und Redis flexibel genug ist, mehrere Aufgaben zu übernehmen (Cache, Sessions, Zähler, Queues, Pub/Sub), ohne für jede Funktion ein neues System einzuführen.
In der Praxis funktioniert Redis am besten, wenn Sie es als Geschwindigkeit + Koordination betrachten, während Ihre primäre Datenbank die Quelle der Wahrheit bleibt.
Eine gängige Aufstellung sieht so aus:
Diese Aufteilung hält die Datenbank auf Korrektheit und Dauerhaftigkeit fokussiert, während Redis hochfrequente Lese-/Schreibzugriffe absorbiert, die sonst Latenz oder Load erhöhen würden.
Richtig eingesetzt liefert Redis einige praktische Ergebnisse:
Redis ersetzt nicht die primäre Datenbank. Wenn Sie komplexe Abfragen, langfristige Speicher-Garantien oder analytisches Reporting brauchen, gehört das in die Datenbank.
Gehen Sie außerdem nicht davon aus, dass Redis „standardmäßig dauerhaft“ ist. Wenn der Verlust selbst weniger Sekunden inakzeptabel ist, benötigen Sie sorgfältige Persistenz-Einstellungen — oder ein anderes System — basierend auf Ihren Wiederherstellungsanforderungen.
Redis wird oft als "Key-Value-Store" beschrieben, aber nützlicher ist die Vorstellung eines sehr schnellen Servers, der kleine Datenstücke nach Namen halten und manipulieren kann (der Key). Dieses Modell fördert vorhersehbare Zugriffs-Muster: normalerweise wissen Sie genau, was Sie wollen (eine Session, eine gecachte Seite, einen Zähler), und Redis kann das in einem Roundtrip holen oder aktualisieren.
Redis hält Daten im RAM, weshalb es in Mikro- bis Millisekunden antwortet. Der Kompromiss ist, dass RAM begrenzt und teurer als Festplatte ist.
Entscheiden Sie früh, ob Redis:
Redis kann Daten auf die Festplatte persistieren (RDB-Snapshots und/oder AOF-Append-only-Logs), aber Persistenz erhöht den Schreibaufwand und zwingt Sie zu Durability-Entscheidungen (z. B. „schnell, kann eine Sekunde verlieren“ vs. „langsamer, aber sicherer“). Behandeln Sie Persistenz als Regler, den Sie entsprechend der geschäftlichen Auswirkungen einstellen, nicht als automatisch gesetztes Häkchen.
Redis führt Befehle größtenteils in einem einzelnen Thread aus, was einschränkend klingt, bis man zwei Dinge bedenkt: Operationen sind typischerweise klein, und es gibt keinen Locking-Overhead zwischen mehreren Worker-Threads. Solange Sie teure Befehle und übergroße Nutzlasten vermeiden, kann dieses Modell unter hoher Konkurrenz extrem effizient sein.
Ihre App spricht über TCP mit Redis und verwendet Client-Bibliotheken. Nutzen Sie Connection-Pooling, halten Sie Requests klein und bevorzugen Sie Batching/Pipelining, wenn Sie mehrere Operationen benötigen.
Planen Sie Timeouts und Retries ein: Redis ist schnell, aber Netzwerke sind es nicht immer, und Ihre Anwendung sollte sich bei hoher Last oder temporärem Redis-Ausfall graceful degradieren.
Wenn Sie einen neuen Service bauen und diese Basics schnell standardisieren wollen, kann eine Plattform wie Koder.ai helfen, eine React + Go + PostgreSQL-Anwendung vorzuskizzieren und dann Redis-gestützte Features (Caching, Sessions, Rate Limiting) per Chat-getriebener Workflow hinzuzufügen — dabei können Sie den Quellcode exportieren und überall ausführen.
Caching hilft nur, wenn es eine klare Verantwortung gibt: wer füllt ihn, wer invalidiert ihn und was „gut genug“ an Frische bedeutet.
Cache-Aside bedeutet, dass Ihre Anwendung — nicht Redis — die Lese-/Schreiblogik kontrolliert.
Typischer Ablauf:
Redis ist ein schneller Key-Value-Store; Ihre App entscheidet, wie sie serialisiert, versioniert und Einträge auslaufen lässt.
Eine TTL ist genauso sehr eine Produktentscheidung wie eine technische. Kurze TTLs reduzieren Staleness, erhöhen aber die Datenbanklast; lange TTLs sparen Arbeit, riskieren aber veraltete Ergebnisse.
Praktische Tipps:
user:v3:123), damit alte Caches neue Codepfade nicht brechen.Wenn ein heißer Key abläuft, können viele Anfragen gleichzeitig Misses erzeugen.
Gängige Abwehrmaßnahmen:
Gute Kandidaten sind API-Antworten, teure Abfrageergebnisse und berechnete Objekte (Empfehlungen, Aggregationen). Das Cachen kompletter HTML-Seiten kann funktionieren, aber seien Sie vorsichtig bei Personalisierung und Berechtigungen — cachen Sie lieber Fragmente, wenn benutzerspezifische Logik im Spiel ist.
Redis ist ein praktischer Ort für kurzlebige Login-Zustände: Session-IDs, Refresh-Token-Metadaten und „Dieses Gerät merken“-Flags. Ziel ist, Auth schnell zu machen und gleichzeitig Lebensdauer und Widerruf von Sessions strikt zu kontrollieren.
Ein gängiges Muster ist: Ihre App gibt eine zufällige Session-ID aus, speichert einen kompakten Datensatz in Redis und gibt die ID als HTTP-only Cookie an den Browser zurück. Bei jeder Anfrage schauen Sie den Session-Key nach und hängen Identität und Berechtigungen an den Request-Context.
Redis funktioniert hier gut, weil Session-Reads häufig sind und Session-Ablauf eingebaut ist.
Designen Sie Keys so, dass sie leicht zu scannen und zu widerrufen sind:
sess:{sessionId} → Session-Payload (userId, issuedAt, deviceId)user:sessions:{userId} → Set aktiver Session-IDs (optional, für „aus allen Geräten ausloggen“)Setzen Sie eine TTL auf sess:{sessionId}, die zur Lebensdauer Ihrer Session passt. Wenn Sie Sessions rotieren (empfohlen), erzeugen Sie eine neue Session-ID und löschen die alte sofort.
Vorsicht bei "sliding expiration" (TTL bei jeder Anfrage verlängern): das kann Sessions bei stark genutzten Accounts unendlich am Leben halten. Ein sicherer Kompromiss ist, die TTL nur zu verlängern, wenn sie kurz vor dem Ablauf steht.
Um ein einzelnes Gerät auszuloggen, löschen Sie sess:{sessionId}.
Um über alle Geräte auszuloggen, können Sie entweder:
user:sessions:{userId} löschen, oderuser:revoked_after:{userId}-Zeitstempel führen und jede Session, die davor ausgestellt wurde, als ungültig behandelnDie Zeitstempel-Methode vermeidet große Fan-out-Deletes.
Speichern Sie so wenig wie möglich in Redis — bevorzugen Sie IDs statt personenbezogener Daten. Speichern Sie niemals Klarpasswörter oder langlebige Secrets. Wenn Sie Token-bezogene Daten speichern müssen, speichern Sie Hashes und verwenden enge TTLs.
Begrenzen Sie, wer sich mit Redis verbinden kann, erzwingen Sie Authentifizierung und halten Sie Session-IDs stark entropisch, um Erraten zu verhindern.
Rate Limiting ist eine Domäne, in der Redis glänzt: schnell, über App-Instanzen geteilt und mit atomaren Operationen, die Zähler unter hoher Last konsistent halten. Nützlich ist es zum Schutz von Login-Endpunkten, teuren Suchanfragen, Passwort-Zurücksetzen-Workflows und jeder API, die abgekratzt oder brute-forced werden kann.
Fixed Window ist das einfachste Modell: „100 Anfragen pro Minute.“ Sie zählen Anfragen im aktuellen Minuten-Bucket. Einfach, erlaubt aber Burst-Boundary-Probleme (z. B. 100 bei 12:00:59 und dann 100 bei 12:01:00).
Sliding Window glättet die Grenzen, indem es die letzten N Sekunden/Minuten betrachtet statt nur den aktuellen Bucket. Gerechter, kostet aber meist mehr (z. B. Sorted Sets oder mehr Buchhaltung).
Token Bucket eignet sich für Burst-Verhalten. Benutzer „verdienen“ Tokens über die Zeit bis zu einem Maximum; jede Anfrage verbraucht ein Token. Das erlaubt kurze Bursts bei gleichzeitiger Durchsetzung einer durchschnittlichen Rate.
Ein gängiges Fixed-Window-Muster ist:
INCR key, um einen Zähler zu erhöhenEXPIRE key window_seconds, um TTL zu setzen/zurückzusetzenDie Schwierigkeit ist, es sicher zu machen. Wenn Sie INCR und EXPIRE als separate Aufrufe ausführen, kann ein Absturz dazwischen Keys ohne Ablauf erzeugen.
Sichere Ansätze sind:
INCR ausführt und EXPIRE nur setzt, wenn der Counter neu erstellt wird.SET key 1 EX <ttl> NX zur Initialisierung verwenden und danach INCR ausführen (oft ebenfalls in ein Skript verpackt, um Rennen zu vermeiden).Atomare Operationen sind besonders wichtig bei Traffic-Spitzen: ohne sie können zwei Requests denselben verbleibenden Kontingentwert „sehen“ und beide durchkommen.
Die meisten Apps brauchen mehrere Schichten:
rl:user:{userId}:{route})Für burstige Endpunkte hilft ein Token-Bucket oder ein großzügiger Fixed-Window-Ansatz plus ein kurzes „Burst“-Fenster, um legitime Spitzen wie Seitenladevorgänge oder mobile Reconnects nicht zu bestrafen.
Entscheiden Sie vorab, was „sicher“ bedeutet:
Ein häufiger Kompromiss ist fail-open für risikoarme Routen und fail-closed für sensitive Routen (Login, Passwort-Reset, OTP), zusammen mit Monitoring, damit Sie sofort merken, wenn Rate-Limiting ausfällt.
Redis kann Hintergrundjobs antreiben, wenn Sie eine leichte Queue für E-Mails, Bildgrößenänderungen, Daten-Syncs oder periodische Tasks benötigen. Entscheidend ist die Wahl der passenden Datenstruktur und klare Regeln für Retries und Fehlerbehandlung.
Lists sind die einfachste Queue: Producer LPUSH, Worker BRPOP. Einfach, aber Sie benötigen zusätzliche Logik für „in-flight“ Jobs, Retries und Visibility-Timeouts.
Sorted Sets sind ideal, wenn Scheduling wichtig ist. Nutzen Sie den Score als Timestamp (oder Priorität), und Worker holen den nächsten fälligen Job. Gut für verzögerte Jobs und Prioritätswarteschlangen.
Streams sind oft die beste Standardwahl für dauerhafte Arbeitsverteilung. Sie unterstützen Consumer-Groups, behalten eine Historie und ermöglichen mehreren Workern Koordination, ohne eigenes „Processing-List“-Design.
Bei Streams-Consumer-Groups liest ein Worker eine Nachricht und bestätigt sie später mit ACK. Wenn ein Worker abstürzt, bleibt die Nachricht pending und kann von einem anderen Worker übernommen werden.
Für Retries verfolgen Sie Versuchszähler (im Payload oder in einem Nebenkey) und nutzen exponentielles Backoff (oft über ein Sorted Set als Retry-Schedule). Nach einer maximalen Versuchsanzahl verschieben Sie den Job in eine Dead-Letter-Queue (ein anderer Stream oder eine Liste) zur manuellen Prüfung.
Gehen Sie davon aus, dass Jobs zweimal laufen können. Machen Sie Handler idempotent durch:
job:{id}:done) mit SET ... NX vor SeiteneffektenHalten Sie Payloads klein (große Daten extern speichern und Referenzen übergeben). Fügen Sie Backpressure ein, indem Sie Queue-Längen begrenzen, Producer verlangsamen, wenn Lag wächst, und Worker entsprechend der Auslastung skalieren.
Redis Pub/Sub ist die simpelste Möglichkeit, Events zu broadcasten: Publisher senden eine Nachricht an einen Channel, und jeder verbundene Subscriber erhält sie sofort. Es gibt kein Polling — nur ein leichtgewichtiges Push-Modell, das sich gut für Echtzeit-Updates eignet.
Pub/Sub ist stark, wenn Ihnen Geschwindigkeit und Fan-Out wichtiger sind als garantierte Lieferung:
Ein nützliches Bild: Pub/Sub ist wie ein Radiosender. Wer eingeschaltet ist, hört die Sendung; niemand erhält automatisch eine Aufnahme.
Pub/Sub hat wichtige Kompromisse:
Deshalb ist Pub/Sub ungeeignet für Workflows, bei denen jedes Event garantiert verarbeitet werden muss.
Wenn Sie Dauerhaftigkeit, Retries, Consumer-Groups oder Backpressure-Handling brauchen, sind Redis Streams in der Regel die bessere Wahl. Streams speichern Events, unterstützen Acknowledgements und erleichtern Recovery nach Neustarts — näher an einer leichtgewichtigen Message-Queue.
In echten Deployments haben Sie mehrere App-Instanzen, die subscriben. Ein paar praktische Tipps:
app:{env}:{domain}:{event} (z. B. shop:prod:orders:created).notifications:global und sprechen Sie Benutzer gezielt mit notifications:user:{id} an.So bleibt Pub/Sub ein schnelles Event-Signal, während Streams (oder eine andere Queue) Events handhaben, die Sie sich nicht leisten können zu verlieren.
Die Wahl der Redis-Datenstruktur betrifft nicht nur „was funktioniert“, sondern beeinflusst Speicherverbrauch, Abfragegeschwindigkeit und wie einfach Ihr Code langfristig bleibt. Eine gute Regel: Wählen Sie die Struktur passend zu den Fragen, die Sie später stellen wollen (Lese-Muster), nicht nur danach, wie Sie die Daten aktuell ablegen.
INCR/DECR.SISMEMBER und einfache Mengenoperationen.Redis-Operationen sind auf Befehlsebene atomar, sodass Sie Zähler sicher inkrementieren können ohne Race-Conditions. Pageviews und Rate-Limit-Zähler nutzen typischerweise Strings mit INCR plus Ablauf.
Leaderboards sind ein Bereich, in dem Sorted Sets glänzen: Sie aktualisieren Scores mit ZINCRBY und holen die Top-Spieler effizient mit ZREVRANGE, ohne alle Einträge scannen zu müssen.
Wenn Sie viele Keys wie user:123:name, user:123:email, user:123:plan erstellen, erhöhen Sie Overhead pro Key und erschweren das Key-Management.
Ein Hash wie user:123 mit Feldern (name, email, plan) hält zusammengehörige Daten an einem Ort und reduziert typischerweise die Key-Anzahl. Teilupdates sind einfacher (ein Feld aktualisieren statt einen JSON-String komplett neu zu schreiben).
Im Zweifelsfall modellieren Sie eine kleine Stichprobe und messen den Speicherverbrauch, bevor Sie sich für eine Struktur bei hohem Volumen entscheiden.
Redis ist zwar oft „in-memory“, aber Sie haben Wahlmöglichkeiten dafür, was beim Node-Restart, vollem Datenträger oder Serverausfall passiert. Die richtige Konfiguration hängt davon ab, wie viele Daten Sie verlieren können und wie schnell Sie wiederhergestellt sein müssen.
RDB-Snapshots speichern einen punktuellen Dump Ihres Datensets. Sie sind kompakt und laden beim Start schnell, was Neustarts beschleunigt. Nachteilig ist, dass die letzten Schreibvorgänge seit dem Snapshot verloren gehen können.
AOF (Append-Only File) protokolliert Schreiboperationen beim Auftreten. Das reduziert typischerweise potenziellen Datenverlust, weil Änderungen kontinuierlicher aufgezeichnet werden. AOF-Dateien können größer werden, und das Replaying beim Start kann länger dauern — Redis kann AOF jedoch rewriten/compacten, um das handhabbar zu halten.
Viele Teams betreiben beides: Snapshots für schnellere Neustarts und AOF für bessere Schreib-Dauerhaftigkeit.
Persistenz ist nicht umsonst. Festplattenschreibungen, AOF-fsync-Policies und Hintergrund-Rewrite-Operationen können Latenzspitzen erzeugen, wenn Ihr Storage langsam oder ausgelastet ist. Andererseits macht Persistenz Neustarts weniger beängstigend: ohne Persistenz bedeutet ein unbeabsichtigter Neustart ein leeres Redis.
Replikation hält Kopien der Daten auf Replicas, damit Sie beim Ausfall des Primärs failover können. Ziel ist in der Regel Verfügbarkeit zuerst, nicht perfekte Konsistenz. Bei Ausfall können Replikate hinterherhinken, und ein Failover kann die letzten bestätigten Schreibvorgänge verlieren.
Bevor Sie etwas tun, notieren Sie zwei Werte:
Nutzen Sie diese Ziele, um RDB-Frequenz, AOF-Settings und die Frage nach Replikaten/automatischem Failover zu wählen — abgestimmt auf die Rolle von Redis (Cache, Session-Store, Queue oder primärer Datenspeicher).
Ein einzelner Redis-Knoten kann erstaunlich weit kommen: einfach zu betreiben, leicht zu verstehen und oft schnell genug für viele Caching-, Session- oder Queue-Workloads.
Skalierung wird nötig, wenn Sie harte Limits erreichen — in der Regel Speicherobergrenze, CPU-Sättigung oder ein Single Point of Failure, den Sie nicht akzeptieren können.
Erwägen Sie zusätzliche Knoten, wenn eine oder mehrere dieser Bedingungen zutreffen:
Ein praktischer erster Schritt ist oft, Workloads zu trennen (zwei unabhängige Redis-Instanzen), bevor Sie in einen Cluster wechseln.
Sharding bedeutet, Ihre Keys über mehrere Redis-Nodes zu verteilen, sodass jeder Node nur einen Teil der Daten speichert. Redis Cluster ist Redis’ eingebaute Lösung dafür: der Keyspace wird in Slots geteilt, und jeder Node besitzt einige dieser Slots.
Der Gewinn ist mehr Gesamtspeicher und höhere aggregierte Durchsatzleistung. Der Nachteil ist zusätzliche Komplexität: Multi-Key-Operationen sind eingeschränkt (Keys müssen auf demselben Shard liegen), und Troubleshooting hat mehr bewegliche Teile.
Selbst bei „gleichmäßigem“ Sharding kann Traffic ungleich verteilt sein. Ein einzelner populärer Key (ein „Hot Key") kann einen Node überlasten, während andere untätig sind.
Gegenmaßnahmen: kurze TTLs mit Jitter, den Wert auf mehrere Keys aufteilen (Key-Hashing) oder Zugriffs-Muster redesignen, damit Reads verteilt werden.
Ein Redis Cluster verlangt einen cluster-aware Client, der Topologie entdeckt, Requests zum richtigen Node routet und Redirects bei Slot-Moves folgt.
Prüfen Sie vor der Migration:
Skalierung funktioniert am besten als geplante Evolution: validieren Sie mit Load-Tests, instrumentieren Sie Key-Latenz und migrieren Sie Traffic schrittweise statt alles auf einmal umzuschalten.
Redis wird oft als „interne Infrastruktur“ behandelt — und genau deshalb ist es ein häufiges Ziel: ein offener Port kann zu Datenleck oder Angreifer-kontrolliertem Cache führen. Behandeln Sie Redis als sensible Infrastruktur, auch wenn Sie nur „temporäre“ Daten speichern.
Beginnen Sie mit aktivierter Authentifizierung und nutzen Sie ACLs (Redis 6+). ACLs erlauben Ihnen:
Vermeiden Sie, ein Passwort für alle Komponenten zu teilen. Verteilen Sie stattdessen pro-Service Credentials und halten Sie Berechtigungen eng.
Die wirksamste Kontrolle ist, nicht erreichbar zu sein. Binden Sie Redis an eine private Schnittstelle, platzieren Sie es in einem privaten Subnet und beschränken Sie eingehenden Traffic mit Security Groups/Firewalls auf die Dienste, die ihn benötigen.
Nutzen Sie TLS, wenn Redis-Traffic Host-Grenzen überschreitet, die Sie nicht komplett kontrollieren (Multi-AZ, geteilte Netzwerke, Kubernetes-Nodes oder Hybrid-Umgebungen). TLS verhindert Sniffing und Credential-Diebstahl und rechtfertigt den geringen Overhead für Sessions, Tokens oder benutzerbezogene Daten.
Sperren Sie Befehle ab, die bei Missbrauch großen Schaden anrichten können. Beispiele, die Sie über ACLs einschränken oder deaktivieren sollten: FLUSHALL, FLUSHDB, CONFIG, SAVE, DEBUG und EVAL (oder zumindest vorsichtig mit Scripting umgehen). Das Umbenennen von Befehlen (rename-command) kann helfen, aber ACLs sind typischerweise klarer und leichter auditierbar.
Lagern Sie Redis-Credentials in Ihrem Secrets-Manager (nicht im Code oder Container-Images) und planen Sie Rotation. Rotation ist am einfachsten, wenn Clients Credentials ohne Redeploy neu laden können oder wenn Sie während der Transition zwei gültige Credentials unterstützen.
Wenn Sie eine praktische Checkliste möchten, halten Sie eine in Ihren Runbooks neben /blog/monitoring-troubleshooting-redis bereit.
Redis fühlt sich oft „ok“ an … bis der Traffic kippt, Speicher ansteigt oder ein langsamer Befehl alles blockiert. Ein leichtgewichtiges Monitoring und ein klares Incident-Checklist verhindern die meisten Überraschungen.
Beginnen Sie mit einer kleinen, erklärbaren Menge:
Wenn etwas „langsam“ ist, bestätigen Sie das mit Redis-eigenen Tools:
KEYS, SMEMBERS oder großen LRANGE-Aufrufen ist ein häufiges Warnsignal.Wenn Latenz steigt, aber CPU in Ordnung aussieht, prüfen Sie Netzwerk-Sättigung, übergroße Payloads oder blockierte Clients.
Planen Sie Wachstum, indem Sie Headroom vorhalten (üblich sind 20–30% freien Speicher) und Annahmen nach Launches oder Feature-Flags überprüfen. Betrachten Sie „dauerhafte Evictions“ als Ausfall, nicht als Warnung.
Während eines Incidents prüfen Sie (in dieser Reihenfolge): Memory/Evictions, Latenz, Client-Connections, Slowlog, Replikations-Lag und letzte Deploys. Notieren Sie die häufigsten Ursachen und beheben Sie sie dauerhaft — nur Alerts reichen nicht.
Wenn Ihr Team schnell iteriert, hilft es, diese operativen Erwartungen in den Entwicklungs-Workflow einzubetten. Mit Koder.ais Planungsmodus und Snapshots/Rollbacks können Sie Redis-gestützte Features (Caching, Rate Limiting) prototypisch testen, Lasttests durchführen und Änderungen sicher zurückrollen — und die Implementierung gleichzeitig im Code-Repository behalten.
Redis eignet sich am besten als gemeinsam genutzte, In-Memory-„Schnellschicht“ für:
Nutzen Sie Ihre primäre Datenbank für dauerhafte, autoritative Daten und komplexe Abfragen. Betrachten Sie Redis als Beschleuniger und Koordinator, nicht als System of Record.
Nein. Redis kann zwar persistieren, ist aber nicht „standardmäßig dauerhaft“. Wenn Sie komplexe Abfragen, starke Durability-Garantien oder Analytics/Reporting benötigen, bleiben diese Daten in Ihrer primären Datenbank.
Wenn der Verlust selbst weniger Sekunden unakzeptabel ist, gehen Sie nicht davon aus, dass Redis-Persistenz ohne sorgfältige Konfiguration ausreicht (oder ziehen Sie für diesen Workload ein anderes System in Betracht).
Treffen Sie die Entscheidung anhand von akzeptablem Datenverlust und Neustartverhalten:
Schreiben Sie zuerst Ihre RPO-/RTO-Ziele auf und passen Sie dann die Persistenz entsprechend an.
Beim Cache-Aside liegt die Logik in Ihrer Anwendung:
Das passt, wenn Ihre Anwendung gelegentliche Misses tolerieren kann und Sie einen klaren Plan für Ablauf/Invalidierung haben.
Wählen Sie TTLs nach Nutzerwirkung und Backend-Last:
user:v3:123), wenn die Cache-Struktur sich ändern kann.Wenn Sie unsicher sind, beginnen Sie mit kürzeren TTLs, messen die Datenbanklast und passen dann an.
Nutzen Sie eine oder mehrere der folgenden Methoden:
Diese Muster verhindern synchronisierte Cache-Misses, die Ihre Datenbank überlasten können.
Eine gängige Vorgehensweise ist:
sess:{sessionId} mit einer TTL speichern, die der Sitzungslaufzeit entspricht.user:sessions:{userId} als Set aktiver Session-IDs für „aus allen Geräten ausloggen“ führen.Vermeiden Sie das verlängernde Setzen der TTL bei jeder Anfrage („sliding expiration“), außer Sie steuern es sorgfältig (z. B. nur verlängern, wenn kurz vor Ablauf).
Verwenden Sie atomare Updates, damit Zähler nicht hängen bleiben oder Rennen entstehen:
INCR und EXPIRE als separate, ungeschützte Aufrufe aus.Scopen Sie Keys sinnvoll (per-User, per-IP, per-Route) und entscheiden Sie im Voraus, ob Sie bei Ausfall von Redis "fail-open" oder "fail-closed" wollen — besonders für sensible Endpunkte wie Login.
Wählen Sie je nach Anforderungen:
LPUSH/BRPOP): einfach, aber Sie müssen Retries, In-Flight-Tracking und Timeouts selbst bauen.Verwenden Sie Pub/Sub für schnelle Broadcasts in Echtzeit, bei denen ein Verpassen akzeptabel ist (Presence, Live-Dashboards). Es bietet:
Wenn jedes Event verarbeitet werden muss, bevorzugen Sie Redis Streams für Dauerhaftigkeit, Consumer-Groups, Retries und Backpressure. Sichern Sie Redis operativ mit ACLs/Netzwerkisolation und verfolgen Sie Latenz/Evictions; halten Sie ein Runbook wie bereit.
Halten Sie Job-Payloads klein; große Blobs extern speichern und nur Referenzen übergeben.
/blog/monitoring-troubleshooting-redis