Was dieser Beitrag mit x86‑Dominanz meint
Wenn Leute „x86“ sagen, meinen sie meist eine Familie von CPU‑Instruktionen, die mit Intels 8086‑Chip begann und sich über Jahrzehnte entwickelte. Diese Instruktionen sind die grundlegenden Verben, die ein Prozessor versteht — addieren, vergleichen, Daten verschieben usw. Dieser Instruktionssatz wird als ISA (Instruction Set Architecture) bezeichnet. Du kannst die ISA als die „Sprache“ sehen, die Software letztlich sprechen muss, um auf einem bestimmten CPU‑Typ zu laufen.
Laienverständliche Definitionen
x86: Der gebräuchlichste ISA in PCs während der letzten ~40 Jahre, hauptsächlich von Intel und auch von AMD umgesetzt.
Abwärtskompatibilität: Die Fähigkeit neuerer Computer, ältere Software (teilweise jahrzehntealte Programme) weiter auszuführen, ohne größere Neuentwicklungen zu verlangen. Nicht in jedem Fall perfekt, aber die Leitidee in der PC‑Welt: „Deine Sachen sollten weiterhin funktionieren."
Was „Dominanz“ in diesem Beitrag bedeutet
„Dominanz“ ist hier nicht nur ein Leistungsanspruch. Es ist ein praktischer, kumulativer Vorteil über mehrere Dimensionen:
- Volumen: Enorme Stückzahlen an x86‑Chips in Desktops, Laptops und Servern.
- Software‑Support: Einer der umfangreichsten Kataloge an Apps, Spielen, Unternehmenssoftware und Entwicklerwerkzeugen, die zuerst (oder am besten) für x86 gebaut wurden.
- Mindshare: Die Standardannahme — bei Käufern, IT‑Abteilungen und Entwicklern — dass ein „normaler Computer“ x86 ist, sofern nicht anders angegeben.
Diese Kombination verstärkt sich gegenseitig: Mehr Geräte ziehen mehr Software an; mehr Software zieht mehr Geräte an.
Weg von einer dominanten ISA zu wechseln ist nicht wie ein einzelnes Bauteil austauschen. Es kann Anwendungen, Treiber (für Drucker, GPUs, Audio, Nischenperipherie), Entwickler‑Toolchains und sogar alltägliche Gewohnheiten (Imaging‑Prozesse, IT‑Skripte, Sicherheitsagenten, Deployment‑Pipelines) stören oder komplizieren. Viele dieser Abhängigkeiten sind unsichtbar, bis etwas ausfällt.
Umfang der Diskussion
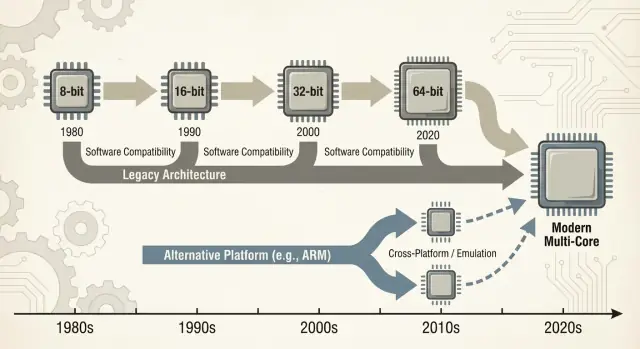
Dieser Beitrag konzentriert sich hauptsächlich auf PCs und Server, wo x86 lange Standard war. Wir werden auch neuere Verschiebungen — besonders ARM‑Transitions — betrachten, weil sie moderne, leicht vergleichbare Lektionen darüber liefern, was glatt läuft, was nicht, und warum „einfach neu kompilieren“ selten die ganze Antwort ist.
Wie die PC‑Ära die Bühne für x86 bereitete
Der frühe PC‑Markt begann nicht mit einem großen Architekturplan — er begann mit praktischen Zwängen. Unternehmen wollten erschwingliche, in großen Stückzahlen verfügbare und leicht wartbare Maschinen. Das trieb Anbieter zu CPUs und Bauteilen, die zuverlässig beschaffbar waren, mit Standard‑Peripherie paarten und ohne aufwändige Eigenentwicklung zu Systemen zusammengestellt werden konnten.
Erschwingliche CPUs + Standardkomponenten
IBMs ursprüngliches PC‑Design setzte stark auf handelsübliche Komponenten und einen relativ kostengünstigen Intel‑8088‑artigen Prozessor. Diese Wahl machte den „PC“ weniger zu einem einzelnen Produkt und mehr zu einem Rezept: eine CPU‑Familie, ein Satz Erweiterungssteckplätze, ein Tastatur/Display‑Ansatz und ein reproduzierbarer Software‑Stack.
Klone, Zweitquellen und ein größerer Markt
Als der IBM PC Nachfrage bewies, erweiterte sich der Markt durch Klone. Firmen wie Compaq zeigten, dass man kompatible Maschinen bauen konnte, die dieselbe Software ausführen — und sie zu unterschiedlichen Preisen verkaufen konnte.
Ebenso wichtig war Second‑Source‑Fertigung: Mehrere Zulieferer konnten kompatible Prozessoren oder Komponenten liefern. Für Käufer reduzierte das das Risiko, auf einen einzigen Hersteller zu setzen. Für OEMs erhöhte es Angebot und Wettbewerb und beschleunigte die Adoption.
„Es läuft dieselben Programme“ wurde zur Kaufregel
In diesem Umfeld wurde Kompatibilität zum Merkmal, das Käufer verstanden und schätzten. Käufer mussten nicht wissen, was ein Instruktionssatz ist; sie mussten nur wissen, ob Lotus 1‑2‑3 (und später Windows‑Anwendungen) liefen.
Softwareverfügbarkeit wurde schnell zu einer einfachen Kaufheuristik: Wenn es dieselben Programme ausführt wie andere PCs, ist es eine sichere Wahl.
Standards verstärkten die Dynamik im Hintergrund
Hardware‑ und Firmware‑Konventionen leisteten viel unsichtbare Arbeit. Gemeinsame Busse und Erweiterungsansätze — zusammen mit BIOS/Firmware‑Erwartungen und gemeinsamen Systemverhalten — machten es leichter, dass Hardwarehersteller und Softwareentwickler „den PC“ als stabile Plattform anvisierten.
Diese Stabilität half, x86 als die Standardbasis für ein wachsendes Ökosystem zu verankern.
Der Software‑Ökosystem‑Flywheel
x86 gewann nicht allein wegen Taktraten oder cleverer Chips. Es gewann, weil Software den Nutzern folgte und Nutzer der Software — ein wirtschaftlicher Netzwerkeffekt, der sich über die Zeit verstärkt.
Der Netzwerkeffekt: mehr Nutzer → mehr Apps → mehr Nutzer
Wenn eine Plattform früh führend ist, sehen Entwickler ein größeres Publikum und klarere Einnahmepfade. Das erzeugt mehr Anwendungen, besseren Support und mehr Drittanbieter‑Addons. Diese Verbesserungen machen die Plattform für die nächste Käuferwelle noch attraktiver.
Wiederhole diese Schleife über Jahre, und die „Standard“‑Plattform wird schwer zu verdrängen — selbst wenn Alternativen technisch attraktiv sind.
Das ist der Grund, warum Plattformtransitionen nicht nur ein CPU‑Problem sind. Es geht darum, ein ganzes Ökosystem neu aufzubauen: Apps, Installer, Update‑Kanäle, Peripherie, IT‑Prozesse und das kollektive Know‑how von Millionen Nutzern.
Unternehmen behalten oft kritische Anwendungen lange: kundenspezifische Datenbanken, interne Tools, ERP‑Addons, branchenspezifische Software und Workflows, die „einfach funktionieren“. Eine stabile x86‑Zielplattform bedeutete:
- Planbare Upgrades (neue PCs laufen weiterhin alte Software)
- Längere Hardwarelebenszyklen
- Weniger Überraschungen für Helpdesks und Trainingsbudgets
Selbst wenn eine neue Plattform geringere Kosten oder bessere Leistung versprach, überwog oft das Risiko, einen umsatzrelevanten Workflow zu zerstören.
Wie Entwicklerprioritäten der installierten Basis und Supportkosten folgen
Entwickler optimieren selten für die „beste“ Plattform im Vakuum. Sie optimieren für die Plattform, die die Supportlast minimiert und die Reichweite maximiert.
Wenn 90 % deiner Kunden auf x86 Windows sind, testest du dort zuerst, lieferst dort zuerst und behebst dort am schnellsten Bugs. Eine zweite Architektur zu unterstützen bedeutet zusätzliche Build‑Pipelines, größere QA‑Matrizen, mehr „bei mir läuft’s“-Debugging und mehr Supportskripte.
Das Ergebnis ist eine sich selbst verstärkende Kluft: Die führende Plattform bekommt tendenziell bessere Software, schneller.
Ein einfaches Beispiel: Buchhaltungssoftware und Druckertreiber
Stell dir ein kleines Unternehmen vor. Ihre Buchhaltungssoftware ist x86‑only, integriert mit einem Jahrzehnt an Vorlagen und einem Payroll‑Plugin. Außerdem nutzen sie einen bestimmten Etikettendrucker und einen Dokumentenscanner mit zickigen Treibern.
Schlage nun einen Plattformwechsel vor. Selbst wenn die Kern‑Apps vorhanden sind, zählen die Randstücke: der Druckertreiber, das Scanner‑Utility, das PDF‑Plugin, das Bank‑Import‑Modul. Diese „langweiligen“ Abhängigkeiten sind Must‑Haves — und wenn sie fehlen oder fehlerhaft sind, kommt die Migration ins Stocken.
Das ist der Flywheel‑Effekt: Die gewinnende Plattform akkumuliert eine lange Kompatibilitätssammlung, auf die alle stillschweigend angewiesen sind.
Abwärtskompatibilität als Produktstrategie
Abwärtskompatibilität war nicht nur ein nettes Feature von x86 — sie wurde zur bewussten Produktstrategie. Intel hielt den x86‑ISA hinreichend stabil, sodass Software von Jahren zuvor weiterlief, während sich fast alles darunter änderte.
Mikroarchitektur entwickelt sich; ISA bleibt größtenteils
Der zentrale Unterschied ist, was kompatibel blieb. Die ISA definiert die Maschinenbefehle, auf die Programme bauen; Mikroarchitektur ist, wie ein Chip diese Befehle ausführt.
Intel konnte von einfachen Pipelines zu Out‑of‑Order‑Ausführung wechseln, größere Caches einbauen, Branch‑Prediction verbessern oder neue Fertigungsprozesse einführen — ohne Entwickler zu zwingen, ihre Apps neu zu schreiben.
Diese Stabilität erzeugte eine mächtige Erwartung: Neue PCs sollten alte Software sofort ausführen.
Mehr Leistung hinzufügen, ohne alten Code zu brechen
x86 sammelte neue Fähigkeiten schrittweise. Instruktions‑Erweiterungen wie MMX, SSE, AVX und spätere Features wurden additiv hinzugefügt: Alte Binärdateien funktionierten weiterhin, neuere Apps konnten neue Instruktionen erkennen und nutzen, wenn vorhanden.
Selbst große Übergänge wurden durch Kompatibilitätsmechanismen abgefedert:
- Legacy‑Modi, die ältere Ausführungsumgebungen bewahren (z. B. 16‑Bit‑ und 32‑Bit‑Kompatibilität in späteren Prozessoren).
- Protected und Long Mode‑Designs, die modernen Betriebssystemen erlauben, mehr Speicher und Sicherheitsfeatures zu nutzen und zugleich alte Anwendungen zu unterstützen.
- Virtualisierungs‑Erweiterungen (wie Intel VT‑x), die es erleichtern, ältere OSes oder isolierte Workloads effizient laufen zu lassen.
Der Trade‑off: Legacy wird zur Einschränkung
Der Nachteil ist Komplexität. Die Unterstützung jahrzehntelangen Verhaltens bedeutet mehr CPU‑Modi, mehr Randfälle und eine höhere Validierungs‑Last. Jede neue Generation muss beweisen, dass sie noch die Anwendungen, Treiber oder Installer von gestern ausführt.
Mit der Zeit wird „nicht die bestehenden Apps zu brechen“ von einer Richtlinie zu einer strategischen Einschränkung: Sie schützt die installierte Basis, macht aber radikale Plattformänderungen — neue ISAs, neue Systemdesigns, neue Annahmen — viel schwerer zu rechtfertigen.
Die Wintel‑Schleife: OS, Hardware und OEM‑Anreize
„Wintel“ war nicht nur ein griffiger Begriff für Windows und Intel‑Chips. Es beschrieb eine sich selbst verstärkende Schleife, in der jeder Teil der PC‑Industrie davon profitierte, am gleichen Default‑Ziel festzuhalten: Windows auf x86.
Warum Windows + x86 zum Standard‑App‑Ziel wurde
Für die meisten Consumer‑ und Business‑Softwareanbieter war die praktische Frage nicht „Was ist die beste Architektur?“, sondern „Wo sind die Kunden und wie sehen die Support‑Anrufe aus?"
Windows‑PCs waren weit verbreitet in Haushalten, Büros und Schulen und meist x86‑basiert. Dafür zu liefern maximierte Reichweite und minimierte Überraschungen.
Sobald eine kritische Masse von Anwendungen Windows + x86 voraussetzte, hatten neue Käufer einen weiteren Grund, genau das zu wählen: Ihre Must‑Have‑Programme liefen bereits dort. Das machte die Plattform für die nächste Entwicklerwelle noch attraktiver.
OEMs, Peripherie und der Treiber‑Flywheel
PC‑Hersteller (OEMs) haben Erfolg, wenn sie viele Modelle schnell bauen, Komponenten von mehreren Lieferanten beziehen und Maschinen ausliefern, die „einfach funktionieren“. Eine gemeinsame Windows + x86‑Basis vereinfachte das.
Peripherie‑Hersteller folgten dem Volumen. Wenn die meisten Käufer Windows‑PCs nutzen, priorisieren Drucker, Scanner, Audio‑Interfaces, WLAN‑Chips und andere Geräte Windows‑Treiber zuerst. Bessere Treiberverfügbarkeit verbesserte das Windows‑PC‑Erlebnis, was OEMs half, mehr Geräte zu verkaufen, wodurch das Volumen hoch blieb.
Beschaffungsrealität: Geringstes Risiko gewinnt oft
Korporative und staatliche Einkäufe belohnen Vorhersehbarkeit: Kompatibilität mit bestehenden Apps, beherrschbare Support‑Kosten, Hersteller‑Garantie und erprobte Deployment‑Tools.
Selbst wenn Alternativen attraktiv sind, gewinnt oft die risikoärmste Wahl, weil sie Schulungen reduziert, Randfälle vermeidet und in etablierte IT‑Prozesse passt.
Das Ergebnis war keine Verschwörung, sondern eine Reihe alignierter Anreize — jeder Teilnehmer wählte den Weg mit weniger Reibung — und schuf Momentum, das Plattformwechsel ungewöhnlich schwer macht.
Die Kontrolle über den Code behalten
Erhalten Sie den Source‑Code‑Export, damit Ihr Team alles in Ihrem Repo behalten kann.
Ein „Plattformwechsel“ ist nicht nur der Austausch einer CPU. Es ist ein Paketwechsel: ISA der CPU, Betriebssystem, Compiler/Toolchain, die Apps baut, und die Treiber‑Schicht, die Hardware funktionsfähig macht. Ändert man einen dieser Punkte, stört man oft die anderen.
Die versteckten Abhängigkeiten, die erst bei Fehlern sichtbar werden
Die meisten Ausfälle sind keine dramatischen „die App startet nicht“‑Fehler. Es ist der Tod durch tausend Schnitte:
- Installer und Updater, die eine bestimmte Windows‑Version, Registry‑Struktur oder x86‑Runtime annehmen.
- Kopierschutz und Lizenzmanager, gebunden an Hardware‑IDs, Kernel‑Treiber oder low‑level Timing‑Annahmen.
- Plugins, Add‑ins und Extensions (z. B. CAD‑Plugins, Audio‑VSTs, Browser‑Helpers) kompiliert für eine Architektur.
- Makros und Automatisierungen in Office‑Dokumenten, ERP‑Bildschirmen oder hausinternen Skripten, die auf exakte Pfade, COM‑Objekte oder veraltete APIs setzen.
Selbst wenn die Kernanwendung neu gebaut wird, funktioniert die umgebende „Klebe‑Software“ möglicherweise nicht.
Peripherie: der Upgrade‑Blocker, den niemand einplant
Drucker, Scanner, Etikettendrucker, spezialisierte PCIe/USB‑Karten, medizinische Geräte, POS‑Hardware und USB‑Dongles leben und sterben an Treibern. Wenn der Anbieter weg ist — oder kein Interesse hat — existiert möglicherweise kein Treiber für das neue OS oder die neue Architektur.
In vielen Unternehmen kann ein 200‑$‑Gerät eine Flotte von 2.000‑$‑PCs blockieren.
Das Long‑Tail‑Softwareproblem
Der größte Blocker sind oft „kleine“ interne Tools: eine kundenspezifische Access‑Datenbank, eine Excel‑Makromappe, eine 2009 geschriebene VB‑App, ein Nischen‑Fertigungs‑Utility, das drei Leute nutzen.
Diese Dinge stehen nicht auf Roadmaps, sind aber geschäftskritisch. Plattformwechsel scheitern, wenn der Long Tail nicht migriert, getestet und verantwortet wird.
Die wirkliche Ökonomie des Wechsels
Ein Plattformwechsel wird nicht nur an Benchmarks gemessen. Er wird danach beurteilt, ob die Gesamtrechnung — Geld, Zeit, Risiko und verlorenes Momentum — unter dem wahrgenommenen Nutzen bleibt. Für die meisten Menschen und Organisationen ist diese Rechnung höher, als sie von außen wirkt.
Die Rechnung der Nutzer: Zeit, Gewohnheiten und „kleine“ Fehler
Für Nutzer beginnen die Wechselkosten mit dem Offensichtlichen (neue Hardware, neue Peripherie, neue Garantien) und verlagern sich schnell ins Unordentliche: Umgewöhnung, Rekonfiguration von Workflows und erneute Validierung täglicher Werkzeuge.
Selbst wenn eine App „läuft“, können Details anders sein: ein Plugin lädt nicht, ein Druckertreiber fehlt, ein Makro verhält sich anders, Anti‑Cheat einer Spielesoftware schlägt an oder ein Nischen‑Zubehör funktioniert nicht mehr. Jede einzelne Störung ist klein; zusammen können sie den Wert des Upgrades aufzehren.
Die Rechnung der Anbieter: QA‑Explosion und Supportlast
Anbieter bezahlen für Plattformwechsel durch eine sich ausdehnende Testmatrix. Es geht nicht nur um „startet es?“, sondern um:
- verschiedene OS‑Versionen und Update‑Kanäle
- unterschiedliche CPU‑Generationen und Feature‑Sets
- Treiber, Firmware und Sicherheitstools
- Unternehmensrichtlinien und Lockdown‑Modi
Jede zusätzliche Kombinationsmöglichkeit fügt QA‑Aufwand, mehr Dokumentation und mehr Support‑Tickets hinzu. Ein Übergang kann eine vorhersehbare Release‑Routine in einen permanenten Incident‑Response‑Zustand verwandeln.
Entwickler schultern Kosten für Portierung von Bibliotheken, Umschreiben performance‑kritischen Codes (oft handoptimiert für ein ISA) und Neubau automatisierter Tests. Das Schwierigste ist Vertrauen wiederherzustellen: zu beweisen, dass der neue Build korrekt, schnell genug und stabil unter realen Lasten ist.
Der versteckte Killer: Opportunitätskosten
Migrationsarbeit konkurriert direkt mit neuen Features. Wenn ein Team zwei Quartale damit verbringt, Dinge wieder einfach „zum Laufen“ zu bringen, sind das zwei Quartale ohne Produktverbesserung.
Viele Organisationen wechseln nur, wenn die alte Plattform sie wirklich blockiert — oder die neue so überzeugend ist, dass sie diesen Trade‑off rechtfertigt.
Brücken: Emulation, Übersetzung und Virtualisierung
Einen Full‑Stack‑Neuaufbau testen
Starten Sie ein React‑Admin‑Panel mit einer Go‑API und PostgreSQL für realistische Tests.
Wenn eine neue CPU‑Architektur kommt, fragen Nutzer nicht nach Instruktionssätzen — sie fragen, ob ihre Apps noch öffnen. Deshalb sind „Brücken“ wichtig: Sie lassen neue Maschinen alte Software laufen, bis das Ökosystem aufholt.
Emulation vs. Übersetzung: alte Apps am Leben halten
Emulation imitiert eine ganze CPU in Software. Am kompatibelsten, aber meist am langsamsten, weil jede Instruktion „nachgespielt“ wird, statt nativ ausgeführt zu werden.
Binärübersetzung (oft dynamisch) schreibt Abschnitte x86‑Codes in die nativen Instruktionen der neuen CPU um, während das Programm läuft. So liefern viele moderne Übergänge eine Day‑One‑Story: Installiere deine existierenden Apps, und eine Kompatibilitätsschicht übersetzt im Hintergrund.
Der Wert ist einfach: Neue Hardware kaufen, ohne auf alle Vendoren warten zu müssen.
Warum das nie perfekt ist
Kompatibilitätsschichten funktionieren meist für Mainstream‑Apps gut — und kämpfen an den Rändern:
- Performance‑Kliffs: Ein Workload kann ok sein, bis er schwere SIMD‑Nutzung, JIT‑Compiler oder enge Loops erreicht, die schlecht übersetzt werden.
- Randfälle: Kopierschutz, niedrige Timing‑Annahmen oder selbstmodifizierender Code können scheitern.
- Treiber und Kernel‑Komponenten: Du kannst eine App übersetzen, aber einen fehlenden Druckertreiber oder eine Legacy‑Kernel‑Erweiterung nicht „übersetzen“.
Hardware‑Support ist oft der eigentliche Blocker.
Virtualisierung: teilweise Brücke für Business‑Software
Virtualisierung hilft, wenn du eine ganze Legacy‑Umgebung brauchst (ein bestimmtes Windows‑Release, ein altes Java‑Stack, eine Line‑of‑Business‑App). Es ist operativ sauber — Snapshots, Isolation, einfaches Rollback — aber abhängig davon, was virtualisiert wird.
VMs derselben Architektur sind nahezu native; plattformübergreifende VMs fallen meist auf Emulation zurück und verlangsamen.
Wann ist „gut genug“ tatsächlich gut genug?
Eine Brücke reicht meist für Office‑Apps, Browser und Alltagsproduktivität — wo „schnell genug“ genügt. Risikoreicher ist sie bei:
- spezialisierten Peripheriegeräten und Treibern
- latenzkritischen Audio/Video‑Pipelines
- High‑Performance‑Computing oder schwerer Grafik
In der Praxis kaufen Brücken Zeit, aber sie eliminieren selten die Migrationsarbeit vollständig.
Leistung, Energie und der Workload‑Mix
CPU‑Argumente klingen oft wie ein einzelner Score: „Schneller gewinnt.“ Tatsächlich gewinnt eine Plattform, wenn sie zu den Gerätekonditionen und den tatsächlich ausgeführten Workloads passt.
x86 wurde für PCs teilweise deshalb zum Default, weil es starke Spitzenleistung bei Netzstrom lieferte und die Industrie alles andere darum herum baute.
Spitzenleistung vs. Energieeffizienz
Desktop‑ und Laptop‑Käufer honorierten historisch flinkes interaktives Verhalten: Apps starten, Code kompilieren, Gaming, große Tabellen. Das treibt Hersteller zu hohen Boost‑Clocks, breiten Kernen und aggressivem Turbo — großartig, wenn man Watt freigeben kann.
Energieeffizienz ist ein anderes Spiel. Wenn dein Produkt von Batterie, Wärme, Lüftergeräusch oder dünnem Gehäuse limitiert ist, ist die beste CPU diejenige, die „genug“ Arbeit pro Watt leistet, konstant, ohne zu drosseln.
Effizienz geht über Energiesparen hinaus: Es geht darum, innerhalb thermischer Grenzen zu bleiben, damit Leistung nicht nach einer Minute zusammenbricht.
Warum Mobile andere Architekturen favorisierte
Phones und Tablets leben in engen Energiegrenzen und sind kostenempfindlich bei massivem Volumen. Das belohnte Designs, die auf Effizienz, integrierte Komponenten und vorhersehbares thermisches Verhalten optimiert sind.
Es schuf auch ein Ökosystem, in dem OS, Apps und Silicon zusammen unter Mobile‑First‑Annahmen evolvierten.
Server: Zuverlässigkeit und Reife schlagen rohe Geschwindigkeit
Im Rechenzentrum ist die CPU‑Wahl selten nur Benchmark‑Entscheidung. Betreiber achten auf Zuverlässigkeitsfeatures, lange Supportfenster, stabile Firmware, Monitoring und ein reifes Ökosystem aus Treibern, Hypervisoren und Management‑Tools.
Selbst wenn eine neue Architektur auf Perf/Watt attraktiv aussieht, kann das Risiko operativer Überraschungen den Vorteil überwiegen.
Moderne Server‑Workloads sind divers: Web‑Serving belohnt hohen Durchsatz und effizientes Skalieren; Datenbanken belohnen Speicherbandbreite, Latenz‑Konsistenz und erprobte Tuning‑Praktiken; AI verlagert Wert zunehmend zu Beschleunigern und Software‑Stacks.
Wenn sich der Mix ändert, kann auch die siegreiche Plattform wechseln — aber nur, wenn das umgebende Ökosystem nachkommt.
Eine neue CPU‑Architektur kann technisch exzellent sein und trotzdem scheitern, wenn die Alltagswerkzeuge das Bauen, Ausliefern und Unterstützen von Software nicht erleichtern. Für die meisten Teams ist „Plattform“ nicht nur der Instruktionssatz — es ist die komplette Auslieferungspipeline.
Compiler, Debugger, Profiler und Kernbibliotheken prägen Entwicklerverhalten. Wenn die besten Compiler‑Flags, Stacktraces, Sanitizer oder Performance‑Tools spät kommen (oder sich anders verhalten), zögern Teams, Releases darauf zu setzen.
Schon kleine Lücken zählen: eine fehlende Bibliothek, ein wackeliges Debugger‑Plugin oder langsamere CI‑Builds können aus „wir könnten es portieren“ ein „wir machen’s dieses Quartal nicht“ machen. Wenn die x86‑Toolchain in IDEs, Build‑Systemen und CI‑Templates der Default ist, zieht der geringste Widerstand zurück zur bekannten Plattform.
Distribution ist Reibung, keine Theorie
Software erreicht Nutzer durch Packaging‑Konventionen: Installer, Updater, Repositories, App‑Stores, Container und signierte Binaries. Ein Plattformwechsel zwingt unbequeme Fragen auf:
- Liefern wir separate Builds (x86 und ARM), ein „universelles“ Paket oder verlassen wir uns auf Übersetzung?
- Installieren sich bestehende Plugins/Treiber sauber?
- Sind Code‑Signing, Notarisierung und automatische Updates architekturübergreifend konsistent?
Wenn Distribution chaotisch wird, steigen Supportkosten — und viele Anbieter vermeiden das.
Enterprise‑Management ist ein harter Gatekeeper
Unternehmen kaufen Plattformen, die sie großflächig verwalten können: Imaging, Device Enrollment, Policies, Endpoint‑Security, EDR‑Agenten, VPN‑Clients und Compliance‑Reporting. Wenn eines dieser Tools auf einer neuen Architektur zurückliegt, stocken Piloten.
„Bei mir läuft’s“ ist irrelevant, wenn IT es nicht deployen und sichern kann.
Die echte Kennzahl: Release‑Geschwindigkeit
Entwickler und IT kommen bei einer praktischen Frage zusammen: Wie schnell können wir liefern und supporten? Tooling und Distribution beantworten diese Frage oft viel entscheidender als rohe Benchmarks.
Eine praktische Methode, Teams Migrationen zu erleichtern, ist die Verkürzung der Zeit zwischen Idee und testbarem Build — besonders beim Validieren derselben App über verschiedene Umgebungen (x86 vs. ARM, unterschiedliche OS‑Images oder Deployment‑Ziele).
Plattformen wie Koder.ai fügen sich in diesen Workflow ein, indem sie Teams erlauben, reale Anwendungen per Chat‑Interface zu generieren und zu iterieren — häufig mit React‑Frontend, Go‑Backends und PostgreSQL‑Datenbanken (plus Flutter für Mobile). Für Plattform‑Transitions sind zwei Fähigkeiten besonders relevant:
- Schnelles Prototyping und Rebuilds, wenn interne Tools, Admin‑Panels oder Long‑Tail‑Utilities neu erstellt werden müssen, die keinen klaren Besitzer haben.
- Snapshots und Rollback, um Änderungen sicher zu testen, während man mehrere Architekturen, Toolchains und Deployment‑Umgebungen jongliert.
Da Koder.ai Source‑Code‑Export unterstützt, kann es außerdem als Brücke zwischen Experiment und konventioneller Engineering‑Pipeline dienen — praktisch, wenn man schnell sein muss, aber am Ende wartbaren Code in eigener Kontrolle haben möchte.
Jüngste Lektionen aus ARM‑Transitions
Vermeiden, Bewährtes zu zerstören
Experimentieren Sie sicher mit Snapshots und Rollbacks, während Sie heikle Änderungen prüfen.
ARMs Vorstoß in Laptops und Desktops ist ein nützlicher Realitätscheck dafür, wie schwer Plattformtransitionen wirklich sind. Auf dem Papier ist das Versprechen einfach: bessere Leistung pro Watt, leisere Geräte, längere Akkulaufzeit.
In der Praxis hängt Erfolg weniger vom CPU‑Kern ab als von allem Drum‑und‑Dran — Apps, Treiber, Distribution und wer die Macht hat, Anreize zu koordinieren.
Apple: Kontrolle reduziert die „Unbekannten"
Apples Wechsel von Intel zu Apple Silicon funktionierte größtenteils, weil Apple den ganzen Stack kontrolliert: Hardware‑Design, Firmware, Betriebssystem, Entwicklerwerkzeuge und primäre App‑Vertriebswege.
Diese Kontrolle erlaubte einen sauberen Bruch, ohne auf Dutzende unabhängiger Partner warten zu müssen.
Sie ermöglichte auch eine koordinierte „Brücken“‑Phase: Entwicklern wurden klare Ziele gegeben, Nutzer bekamen Kompatibilitätswege, und Apple konnte Druck auf wichtige Anbieter ausüben, native Builds zu liefern. Selbst wenn manche Apps nicht nativ waren, blieb die Nutzererfahrung häufig akzeptabel, weil der Übergangsplan als Produkt entworfen war — nicht nur als Prozessor‑Tausch.
Windows on ARM: Partner, Timing und Lücken
Windows on ARM zeigt die andere Seite. Microsoft kontrolliert das Hardware‑Ökosystem nicht vollständig, und Windows‑PCs hängen stark von OEM‑Entscheidungen und einer langen Tail von Gerätetreibern ab.
Das erzeugt häufige Ausfallpunkte:
- Treiber: Drucker, Audio‑Interfaces, Unternehmensperipherie und „One‑Off“‑Geräte können die Adoption blockieren.
- App‑Lücken: Manche Profi‑Tools kommen spät oder nie, und Plug‑ins/Add‑ons können der versteckte Blocker sein.
- Timing‑Anreize: OEMs wetten nicht groß, ohne Nachfrage; Nutzer fordern Geräte nicht, bis Kompatibilität sicher erscheint.
Fazit: gewinnende Übergänge sind organisatorisch, nicht nur technisch
ARMs jüngste Fortschritte verstärken eine Kernlektion: Kontrolle über mehr Teile des Stacks beschleunigt und vereinfacht Übergänge.
Wenn man auf Partner angewiesen ist, braucht man ungewöhnlich starke Koordination, klare Upgrade‑Pfade und einen Grund für jeden Teilnehmer — Chip‑Vendor, OEM, Entwickler und IT‑Käufer —, gleichzeitig zu handeln.
Plattformwechsel scheitern aus langweiligen Gründen: Die alte Plattform funktioniert weiterhin, alle haben bereits dafür bezahlt (Geld und Gewohnheiten), und die "Randfälle" sind es, in denen wirkliche Geschäfte leben.
Signale, dass ein Wechsel wirklich hält
Eine neue Plattform setzt sich meist nur durch, wenn drei Dinge zusammenkommen:
Erstens: Der Nutzen ist für normale Käufer offensichtlich — nicht nur für Ingenieure: bessere Akkulaufzeit, deutlich niedrigere Kosten, neue Formfaktoren oder ein massiver Leistungssprung für gängige Aufgaben.
Zweitens: Es gibt einen glaubwürdigen Kompatibilitätsplan: gute Emulation/Übersetzung, einfache „Universal“‑Builds und klare Pfade für Treiber, Peripherie und Enterprise‑Tools.
Drittens: Die Anreize sind entlang der Kette ausgerichtet: OS‑Vendor, Chip‑Vendor, OEMs und App‑Entwickler sehen Vorteile und haben Gründe, die Migration zu priorisieren.
Wie Firmen das Risiko reduzieren
Erfolgreiche Übergänge sehen weniger wie ein Schalterumlegen aus und mehr wie kontrollierte Überlappungen. Phasenweise Rollouts (erst Pilotgruppen), Dual‑Builds (alt + neu) und Telemetrie (Crash‑Raten, Performance, Feature‑Nutzung) helfen, Probleme früh zu entdecken.
Ebenso wichtig: ein publiziertes Support‑Fenster für die alte Plattform, klare interne Deadlines und ein Plan für „kann noch nicht migrieren“‑Nutzer.
Eine praktische Checkliste, bevor man wechselt
- Teste deine kritischen Apps (inkl. Plugins und Makros), nicht nur die Schlagzeilen‑Software.
- Validiere Peripherie und Treiber: Docks, Drucker, Scanner, Audio‑Interfaces, Sicherheitsschlüssel.
- Bestätige Sicherheit und Management: Festplattenverschlüsselung, EDR, VPN, Device‑Management, Compliance‑Policies.
- Führe Performance‑Tests mit realen Workloads durch (Build‑Zeiten, Video‑Exporte, Datenanalysen) plus Akku und Thermik.
Die ausgewogene Sicht
x86 hat weiterhin enormes Momentum: Jahrzehnte der Kompatibilität, fest verankerte Unternehmens‑Workflows und breite Hardware‑Optionen.
Aber der Druck wächst — durch neue Anforderungen: Energieeffizienz, engere Integration, AI‑fokussierte Rechenleistung und einfachere Geräteflotten. Die härtesten Kämpfe drehen sich nicht um rohe Geschwindigkeit; sie drehen sich darum, den Wechsel sicher, vorhersehbar und lohnenswert zu machen.