27. Aug. 2025·7 Min
Go-Worker-Pools für Hintergrundjobs: Wiederholungen, Abbruch, Herunterfahren
Go-Worker-Pools helfen kleinen Teams, Hintergrundjobs mit Wiederholungen, Abbruch und sauberem Herunterfahren mittels einfacher Muster auszuführen, bevor schwere Infrastruktur hinzugefügt wird.
Warum Hintergrundjobs schnell unübersichtlich werden
In einem kleinen Go-Service beginnt Hintergrundarbeit oft mit einem einfachen Ziel: die HTTP-Antwort schnell zurückgeben und die langsamen Aufgaben danach erledigen. Das kann das Versenden von E-Mails, das Skalieren von Bildern, das Synchronisieren mit einer API, das Neuaufbauen von Suchindizes oder das Erstellen nächtlicher Reports sein.
Das Problem ist, dass diese Jobs echte Produktionsarbeit sind – nur ohne die Schutzmaßnahmen, die Anfragenverarbeitung normalerweise bietet. Eine von einem HTTP-Handler gestartete goroutine fühlt sich zunächst in Ordnung an, bis während einer Aufgabe ein Deploy passiert, eine Upstream-API langsamer wird oder dieselbe Anfrage wiederholt wird und den Job doppelt auslöst.
Die ersten Schmerzpunkte sind vorhersehbar:
- Hängende Jobs: ein Aufruf blockiert und die Worker kommen nicht weiter.
- Doppelte Arbeit: Retries auf HTTP-Ebene führen zum erneuten Ausführen desselben Jobs.
- Kein Shutdown-Plan: der Prozess beendet sich und Arbeit geht verloren oder bleibt halb erledigt.
- Stille Fehler: Fehler werden einmal protokolliert (oder gar nicht) und verschwinden.
- Retry-Stürme: fehlerhafte Jobs wiederholen sofort und überlasten Abhängigkeiten.
Genau hier hilft ein kleines, explizites Muster wie ein Go-Worker-Pool. Es macht Parallelität zu einer bewussten Wahl (N Worker), verwandelt „mach das später“ in einen klaren Job-Typ und gibt dir einen zentralen Ort, um Retries, Timeouts und Abbrüche zu handhaben.
Beispiel: Eine SaaS-App muss Rechnungen verschicken. Du willst nach einem Batch-Import nicht 500 gleichzeitige Sends und du willst nicht dieselbe Rechnung erneut versenden, weil eine Anfrage wiederholt wurde. Ein Worker-Pool erlaubt dir, den Durchsatz zu begrenzen und „Rechnung #123 senden" als verfolgte Arbeitseinheit zu behandeln.
Ein Worker-Pool ist nicht das richtige Werkzeug, wenn du dauerhafte, prozessübergreifende Garantien brauchst. Müssen Jobs Abstürze überleben, für die Zukunft geplant werden oder von mehreren Diensten verarbeitet werden, brauchst du wahrscheinlich eine echte Queue plus persistenten Speicher für den Job-Status.
Das Worker-Pool-Modell einfach erklärt
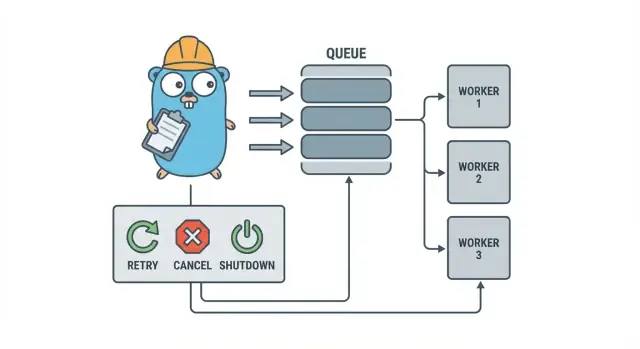
Ein Go-Worker-Pool ist bewusst langweilig: Arbeit in eine Queue legen, eine feste Anzahl Worker daraus ziehen lassen und sicherstellen, dass das Ganze sauber stoppen kann.
Die Grundbegriffe:
- Job: eine Arbeitseinheit wie „dieses Bild skalieren“ oder „diese Rechnung per E-Mail senden".
- Queue: wo Jobs warten.
- Worker: eine goroutine, die wiederholt einen Job nimmt und ausführt.
- Dispatcher: der Teil, der Jobs annimmt und in die Queue einspeist.
In vielen In-Process-Designs ist ein Go channel die Queue. Ein gepufferter Channel kann eine begrenzte Anzahl Jobs halten, bevor Produzenten blockieren. Dieses Blockieren ist Backpressure und verhindert oft, dass dein Service unbegrenzt Arbeit annimmt und bei Traffic-Spitzen den Speicher aufbraucht.
Die Puffergröße verändert das Verhalten des Systems. Ein kleiner Puffer macht Druck schnell sichtbar (Aufrufer warten früher). Ein größerer Puffer glättet kurze Spitzen, kann aber Überlast verbergen, bis es zu spät ist. Es gibt keine perfekte Zahl, nur eine Zahl, die zu der Menge an Wartebereitschaft passt, die du tolerieren kannst.
Du wählst auch, ob die Pool-Größe fest ist oder sich ändern kann. Feste Pools sind leichter zu durchdenken und halten den Ressourcenverbrauch vorhersehbar. Auto-skalierende Worker helfen bei ungleichmäßigem Load, fügen aber Entscheidungen hinzu, die gepflegt werden müssen (wann skalieren, um wie viel, und wann zurückskalieren).
Schließlich bedeutet „ack“ in einem In-Process-Pool normalerweise einfach „der Worker hat den Job beendet und keinen Fehler zurückgegeben." Es gibt keinen externen Broker, der die Lieferung bestätigt, also definiert dein Code, was „fertig" ist und was passiert, wenn ein Job fehlschlägt oder abgebrochen wird.
Designziele: Wiederholungen, Abbruch und sauberes Herunterfahren
Mechanisch ist ein Worker-Pool einfach: eine feste Anzahl Worker laufen, man füttert sie mit Jobs und verarbeitet diese. Der Wert liegt in der Kontrolle: vorhersehbare Parallelität, klares Fehlerhandling und ein Shutdown-Pfad, der nicht Arbeit halb erledigt liegen lässt.
Drei Ziele halten kleine Teams handhabbar:
- Parallelität begrenzen, damit ein Spike nicht die Datenbank oder eine externe API schrottet.
- Verlieren von Arbeit vermeiden (oder zumindest genau wissen, was verworfen wurde und warum).
- Debuggbar bleiben: jeder Job sollte durch Logs und einige Zähler nachvollziehbar sein.
Die meisten Fehler sind langweilig, aber du willst sie trotzdem unterschiedlich behandeln:
- Transiente Fehler (Netzwerkstörungen, Rate Limits), die wiederholt werden sollten.
- Permanente Fehler (falsche Eingabe, fehlender Datensatz), die nicht erneut versucht werden sollten.
- Timeouts (eine Abhängigkeit hängt), die gekappt werden müssen, damit Worker nicht verstopfen.
Abbruch ist nicht dasselbe wie „Error“. Es ist eine Entscheidung: ein Nutzer hat abgebrochen, ein Deploy hat deinen Prozess ersetzt oder dein Service fährt herunter. In Go behandle Abbruch als erstklassiges Signal mit Kontextabbruch und sorge dafür, dass jeder Job es vor dem Start teurer Arbeit und an einigen sicheren Punkten während der Ausführung überprüft.
Sauberes Herunterfahren ist der Punkt, an dem viele Pools auseinanderfallen. Entscheide früh, was „sicher" für deine Jobs bedeutet: beendest du laufende Arbeit oder stoppst du schnell und führst später neu aus? Ein praktischer Ablauf ist:
- Keine neuen Jobs mehr annehmen.
- Den Workern sagen, sie sollen nach ihrem aktuellen Job stoppen (oder sofort stoppen).
- Bis zu einer Frist warten und dann hart beenden.
Wenn du diese Regeln früh definierst, bleiben Retries, Abbrüche und Shutdowns überschaubar statt sich in ein eigenes Framework zu verwandeln.
Schritt für Schritt: einen einfachen Worker-Pool bauen
Ein Worker-Pool ist nur eine Gruppe von goroutines, die Jobs aus einem Channel ziehen und ausführen. Wichtig ist, die Basics vorhersehbar zu machen: wie ein Job aussieht, wie Worker stoppen und wie du weißt, dass alle Arbeiten beendet sind.
Beginne mit einem einfachen Job-Typ. Gib ihm eine ID (für Logs), eine Nutzlast (was verarbeitet werden soll), einen Attempt-Zähler (später für Retries nützlich), Zeitstempel und einen Platz für job-spezifische Kontextdaten.
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := \u00026Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i \u0003c size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case \u0003c-p.ctx.Done():
return
case job, ok := \u0003c-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case \u0003c-p.ctx.Done():
return context.Canceled
case p.jobs \u0003c- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
Einige praktische Entscheidungen, die du sofort triffst:
- Wähle eine Queue-Größe basierend darauf, wie viel Warten du tolerieren kannst.
- Entscheide, was Backpressure für Aufrufer bedeutet: blockieren, einen Fehler zurückgeben oder verwerfen.
- Halte
Stop()undWait()getrennt, damit du zuerst die Aufnahme stoppen und dann auf laufende Arbeit warten kannst.
Retries hinzufügen, ohne es in ein Framework zu verwandeln
Retries sind nützlich, aber auch der Punkt, an dem Worker-Pools kompliziert werden. Halte das Ziel eng: wiederhole nur, wenn ein weiterer Versuch realistisch Erfolg haben kann, und hör schnell auf, wenn nicht.
Beginne damit, zu entscheiden, was retrybar ist. Temporäre Probleme (Netzwerkstörungen, Timeouts, „try again later"-Antworten) sind meist retrybar. Permanente Probleme (falsche Eingabe, fehlender Datensatz, Berechtigungsfehler) nicht.
Eine kleine Retry-Policy reicht meist aus:
- Markiere Fehler als retrybar oder nicht (z. B. durch einen
Retryable(err)-Wrapper). - Setze eine Max-Anzahl Versuche (oft 3 bis 5). Danach verbrennst du meist nur Zeit.
- Verwende exponentielles Backoff mit Jitter, damit Jobs nicht synchron wiederholen.
- Begrenze die Verzögerung (z. B. niemals länger als 30 Sekunden schlafen).
- Logge Retries mit Attempt-Nummer, nächster Verzögerung und Job-ID.
Backoff muss nicht kompliziert sein. Eine gängige Form ist: delay = min(base * 2^(attempt-1), max) und dann Jitter hinzufügen (randomize um +/- 20%). Jitter ist wichtig, weil sonst viele Worker gleichzeitig fehlschlagen und synchron wiederholen.
Wo sollte die Verzögerung stattfinden? Für kleine Systeme ist es in Ordnung, innerhalb des Workers zu schlafen, aber das belegt einen Worker-Slot. Wenn Retries selten sind, ist das akzeptabel. Sind Retries häufig oder die Verzögerungen lang, erwäge, den Job mit einem "run after"-Timestamp wieder in die Queue zu stellen, damit Worker mit anderer Arbeit beschäftigt bleiben.
Beim endgültigen Fehlschlag sei explizit. Speichere den fehlgeschlagenen Job (und den letzten Fehler) zur Überprüfung, logge genug Kontext zum Replay oder schiebe ihn in eine Dead-Letter-Liste, die regelmäßig geprüft wird. Vermeide stille Drops. Ein Pool, der Fehler versteckt, ist schlimmer als keine Retries.
Abbruch und Timeouts, die Arbeit wirklich stoppen
Verdiene Credits für deinen nächsten Build
Veröffentliche einen kurzen Bericht und erhalte Credits, die du bei Koder.ai nutzen kannst.
Worker-Pools fühlen sich nur dann sicher an, wenn du sie stoppen kannst. Die einfachste Regel ist: übergib ein context.Context durch jede Schicht, die blockieren kann. Das gilt für Submission, Ausführung und Aufräumen.
Ein praktisches Setup nutzt zwei Zeitgrenzen:
- Ein Timeout pro Job, damit eine Aufgabe nicht ewig einen Worker belegt.
- Ein Shutdown-Timeout, damit der Prozess auch dann exitten kann, wenn sich einige Jobs nicht kooperativ verhalten.
Kontext-Ende durchgängig verwenden
Gib jedem Job seinen eigenen Kontext, abgeleitet vom Kontext des Workers. Dann muss jeder langsame Aufruf (DB, HTTP, Queues, Dateisystem) diesen Kontext verwenden, damit er früh zurückkehren kann.
func worker(ctx context.Context, jobs \u0003c-chan Job) {
for {
select {
case \u0003c-ctx.Done():
return
case job, ok := \u0003c-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
Wenn Run deine DB oder eine API aufruft, verwende den Kontext in diesen Aufrufen (z. B. QueryContext, NewRequestWithContext oder Client-Methoden, die Kontext akzeptieren). Ignorierst du ihn an einer Stelle, wird der Abbruch nur „best effort" und versagt meist genau dann, wenn du ihn brauchst.
Teilarbeit und „sichere zum Wiederholen"-Schritte
Abbruch kann mitten im Job passieren, also gehe von teilweiser Arbeit aus. Strebe idempotente Schritte an, damit erneute Ausführungen nicht zu Duplikaten führen. Häufige Ansätze sind: eindeutige Schlüssel für Inserts (oder Upserts) verwenden, Fortschrittsmarker schreiben (started/done), Ergebnisse vor dem Fortsetzen speichern und ctx.Err() zwischen Schritten prüfen.
Behandle Shutdown wie eine Frist: keine neuen Jobs annehmen, Worker-Kontexte abbrechen und nur bis zum Shutdown-Timeout auf in-flight-Jobs warten.
Sauberes Herunterfahren: was tun, wenn der Prozess schließen muss
Ein sauberes Herunterfahren hat ein Ziel: keine neue Arbeit annehmen, die laufende Arbeit zum Stoppen bringen und das System nicht in einem seltsamen Zustand zurücklassen.
Beginne mit Signalen. In den meisten Deployments siehst du lokal SIGINT und von Prozessmanagern oder Containerruntimes SIGTERM. Nutze einen Shutdown-Kontext, der bei Signalankunft abgebrochen wird, und gib ihn an Pool und Job-Handler weiter.
Stoppe dann das Annehmen neuer Jobs. Lass Aufrufer nicht ewig blockieren, wenn sie versuchen, in einen Channel zu schreiben, den niemand mehr liest. Halte Submissions hinter einer einzigen Funktion, die ein geschlossenes Flag prüft oder auf den Shutdown-Kontext selektiert, bevor sie sendet.
Entscheide, was mit der bereits in der Queue befindlichen Arbeit passiert:
- Drain: beende, was bereits in der Queue ist, lehne neue Submissions ab.
- Drop: verwerfe alles, was noch nicht gestartet wurde.
Draining ist sicherer für Dinge wie Zahlungen und E-Mails. Droppen ist ok für „nice to have"-Tasks wie das Neuberechnen eines Caches.
Eine praktische Shutdown-Sequenz:
- SIGINT/SIGTERM abfangen und einen gemeinsamen Kontext abbrechen.
- Submissions stoppen (den Submit-Pfad schließen, nicht unbedingt den Work-Channel).
- Worker je nach Kontext beenden oder fertig werden lassen.
- Mit einer WaitGroup auf Worker warten.
- Eine Deadline durchsetzen und dann exitten.
Die Deadline ist wichtig. Gib z. B. in-flight-Jobs 10 Sekunden Zeit, um zu stoppen. Danach loggst du, was noch läuft, und beendest den Prozess. Das macht Deploys vorhersehbar und vermeidet hängende Prozesse.
Logging und einfache Metriken für Worker-Pools
Snapshot bevor du die Concurrency änderst
Speichere einen Snapshot, bevor du Concurrency oder Retry-/Shutdown-Logik änderst, und rolle bei Bedarf zurück.
Wenn ein Worker-Pool kaputtgeht, dann selten laut. Jobs werden langsamer, Retries stapeln sich und jemand meldet, dass „nichts passiert". Logging und ein paar Basiszähler machen daraus eine klare Geschichte.
Gib jedem Job eine stabile ID (oder generiere eine bei der Submission) und nimm sie in jede Logzeile auf. Halte die Logs konsistent: eine Zeile, wenn ein Job startet, eine, wenn er fertig ist, und eine bei Fehlern. Wenn du retriest, logge Attempt-Nummer und die nächste Verzögerung.
Eine einfache Log-Form:
- start: job_id, worker_id, attempt, kind
- finish: job_id, worker_id, attempt, duration_ms
- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
Metriken können minimal bleiben und trotzdem viel bringen. Tracke Queue-Länge, in-flight-Jobs, erfolgreiche und fehlgeschlagene Jobs und Job-Latenz (mindestens Durchschnitt und Maximum). Wenn die Queue-Länge immer steigt und die in-flight-Anzahl am Worker-Count hängt, bist du gesättigt. Wenn Submitter beim Senden in den Job-Channel blockieren, erreicht Backpressure den Aufrufer. Das ist nicht immer schlecht, sollte aber bewusst passieren.
Wenn „Jobs hängen", prüfe, ob der Prozess noch Jobs empfängt, ob die Queue-Länge wächst, ob Worker leben und welche Jobs am längsten laufen. Lange Laufzeiten deuten meist auf fehlende Timeouts, langsame Abhängigkeiten oder eine Retry-Schleife hin, die nicht stoppt.
Ein realistisches Beispiel: eine kleine SaaS-Background-Queue
Stell dir eine kleine SaaS vor, in der eine Bestellung auf PAID wechselt. Direkt nach der Zahlung musst du eine Rechnungs-PDF senden, den Kunden per E-Mail benachrichtigen und dein internes Team informieren. Diese Arbeit soll nicht den Web-Request blockieren. Das ist ein guter Anwendungsfall für einen Worker-Pool, weil die Arbeit wichtig ist, das System aber noch klein.
Die Job-Payload kann minimal sein: gerade genug, um den Rest aus der Datenbank zu laden. Der API-Handler schreibt eine Zeile wie jobs(status='queued', type='send_invoice', payload, attempts=0) in derselben Transaktion wie das Order-Update, dann pollt eine Hintergrundschleife nach queued Jobs und schiebt sie in den Worker-Channel.
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
Wenn ein Worker ihn aufnimmt, ist der Happy Path einfach: lade die Bestellung, generiere die Rechnung, rufe den E-Mail-Provider auf und markiere den Job als erledigt.
Retries sind der Punkt, an dem das Ganze ernst wird. Hat dein E-Mail-Provider einen temporären Ausfall, willst du nicht, dass 1.000 Jobs für immer fehlschlagen oder den Provider jede Sekunde hammern. Ein praktischer Ansatz ist:
- Netzwerkfehler und 5xx-Antworten als retrybar behandeln.
- Exponentielles Backoff mit Max-Delay verwenden (z. B. 5s, 15s, 45s, 2m).
- Attempts begrenzen (z. B. 10) und den Job dann als fehlgeschlagen markieren.
- Den letzten Fehler speichern, damit der Support sieht, was passierte.
Während des Ausfalls bewegen sich Jobs von queued zu in_progress und dann zurück zu queued mit einem zukünftigen Ausführungszeitpunkt. Sobald der Provider wieder da ist, leert sich der Rückstau von selbst.
Stell dir jetzt ein Deploy vor. Du sendest SIGTERM. Der Prozess sollte keine neue Arbeit mehr annehmen, aber tun, was bereits in Arbeit ist. Das Polling stoppen, den Worker-Channel nicht weiter füttern und mit einer Deadline auf Worker warten. Jobs, die fertig werden, werden als done markiert. Jobs, die beim Ablauf der Frist noch laufen, sollten wieder auf queued gesetzt werden (oder mit einem Watchdog in progress belassen) damit sie nach dem Neustart aufgenommen werden können.
Häufige Fehler und Fallen
Die meisten Bugs in Hintergrundverarbeitung stecken nicht in der Job-Logik. Sie entstehen durch Koordinationsfehler, die nur unter Last oder beim Shutdown auftreten.
Eine klassische Falle ist, einen Channel von mehr als einem Ort zu schließen. Das führt zu einem Panic, der schwer zu reproduzieren ist. Wähle einen Besitzer pro Channel (meist der Producer) und lass nur diesen close(jobs) aufrufen.
Retries sind ein weiteres Feld, in dem gute Absichten zu Ausfällen führen. Wenn du einfach alles wiederholst, wiederholst du auch permanente Fehler. Das verschwendet Zeit, erhöht Load und kann ein kleines Problem zum Incident machen. Klassifiziere Fehler und setze klare Retry-Grenzen.
Duplikate passieren selbst bei sorgfältigem Design. Worker können mitten im Job abstürzen, ein Timeout kann nach Abschluss feuern oder du kannst beim Deploy neu einreihen. Ist der Job nicht idempotent, führen Duplikate zu echtem Schaden: zwei Rechnungen, zwei Willkommens-E-Mails, zwei Rückerstattungen.
Die häufigsten Fehler:
- Einen Channel aus mehreren Goroutinen schließen.
- Permanente Fehler wiederholen statt sie sichtbar zu machen.
- Kein Idempotency-Key, sodass Duplikate doppelte Seiteneffekte verursachen.
- Unbegrenzte In-Memory-Queues, die so lange wachsen, bis der Speicher voll ist.
context.Contextignorieren, sodass Arbeit nach Start des Shutdowns weiterläuft.
Unbegrenzte Queues sind besonders tückisch. Eine Arbeits-Spitze kann sich still und leise im RAM stapeln. Bevorzuge einen begrenzten Channel-Puffer und entscheide, was passiert, wenn er voll ist: blockieren, verwerfen oder einen Fehler zurückgeben.
Kurze Checkliste vor dem Deploy
Wechsle zu einer PostgreSQL-Job-Queue
Verwandle In-Process-Jobs in eine einfache PostgreSQL-Queue, ohne deine Handler umzuschreiben.
Bevor du einen Worker-Pool in Produktion schickst, solltest du den Job-Lebenszyklus laut beschreiben können. Wenn dich jemand fragt „Wo ist dieser Job gerade?", sollte die Antwort kein Ratespiel sein.
Eine praktische Pre-Flight-Checkliste:
- Du kannst jeden Zustand und Übergang benennen: queued, picked up, running, finished, failed (und was es dazwischen verschiebt).
- Concurrency ist ein einzelner Schalter (z. B.
workerCount) und seine Änderung erfordert keinen Code-Rewrite. - Retries sind begrenzt: max attempts sind klar, Backoff wächst und permanente Fehler landen irgendwo bewusst.
- Shutdown-Verhalten ist bewiesen: du stoppst Intake, lässt in-flight-Jobs fertig werden und hast eine harte Timeout-Grenze.
- Logs beantworten die Basics: Job-ID, Attempt-Nummer, Dauer und Fehlergrund.
Führe vor dem Release einen realistischen Drill durch: 100 „send receipt email"-Jobs enqueuen, 20 absichtlich fehlschlagen lassen und dann den Service mitten in der Ausführung neu starten. Du solltest sehen, dass Retries wie erwartet ablaufen, keine doppelten Seiteneffekte entstehen und der Abbruch bei Ablauf der Frist wirklich Arbeit stoppt.
Wenn etwas unscharf ist, verschärfe es jetzt. Kleine Fixes hier sparen später Tage.
Nächste Schritte: wann schwerere Infrastruktur nötig ist (und wann nicht)
Ein einfacher In-Process-Pool reicht oft, solange ein Produkt jung ist. Sind deine Jobs „nice to have" (E-Mails, Cache-Refresh, Reports generieren) und du kannst sie neu ausführen, hält ein Worker-Pool das System leicht verständlich.
Anzeichen, dass du aus dem In-Process-Pool herausgewachsen bist
Achte auf diese Druckpunkte:
- Du betreibst mehrere App-Instanzen und willst, dass nur eine davon einen Job übernimmt.
- Du brauchst Haltbarkeit (Jobs müssen Abstürze und Deploys überleben).
- Du brauchst eine Audit-Spur: wer hat was queued, wann lief es und was war das Ergebnis.
- Du brauchst Backpressure-Kontrollen über Services hinweg, nicht nur im Prozess.
- Du brauchst strikte Zeitplanung oder lange Verzögerungen (Stunden/Tage) mit zuverlässigem Wecken.
Wenn nichts davon zutrifft, fügen schwerere Tools oft mehr Komplexität als Nutzen hinzu.
Gradual migrieren ohne Rewrite
Das beste Sicherheitsnetz ist eine stabile Job-Schnittstelle: eine kleine Payload, eine ID und ein Handler, der ein klares Ergebnis zurückgibt. Dann kannst du das Queue-Backend später austauschen (vom In-Memory-Channel auf eine Datenbanktabelle und erst danach auf eine dedizierte Queue), ohne Business-Logik zu ändern.
Ein praktischer Zwischenschritt ist ein kleiner Go-Service, der Jobs aus PostgreSQL liest, sie mit einem Lock claimed und den Status aktualisiert. So bekommst du Haltbarkeit und grundlegende Auditierbarkeit und behältst die gleiche Worker-Logik.
Wenn du schnell prototypen willst, kann Koder.ai (koder.ai) einen Go + PostgreSQL-Starter aus einem Chat-Prompt generieren, inklusive einer Background-Jobs-Tabelle und einer Worker-Schleife. Snapshots und Rollbacks können helfen, während du Retries und Shutdown-Verhalten einstellst.