16. Jan. 2026·8 Min
Dokumentzentrierte Workflows: Datenmodell und UI‑Muster
Dokumentzentrierte Workflows erklärt mit praktischen Datenmodellen und UI‑Mustern für Versionen, Vorschauen, Metadaten und klare Statuszustände.
Dokumentzentrierte Workflows erklärt mit praktischen Datenmodellen und UI‑Mustern für Versionen, Vorschauen, Metadaten und klare Statuszustände.
Eine App ist dokumentzentriert, wenn das Dokument selbst das Produkt ist, das Nutzer erstellen, prüfen und benötigen. Die Erfahrung dreht sich um Dateien wie PDFs, Bilder, Scans und Belege — nicht um ein Formular, bei dem eine Datei nur ein Anhang ist.
In dokumentzentrierten Workflows arbeiten Menschen tatsächlich im Dokument: sie öffnen es, prüfen, was sich geändert hat, fügen Kontext hinzu und entscheiden, was als Nächstes passiert. Kann dem Dokument nicht vertraut werden, wird die App nutzlos.
Die meisten dokumentzentrierten Apps brauchen früh ein paar Kernbildschirme:
Die Probleme treten schnell auf. Nutzer laden denselben Beleg doppelt hoch. Jemand bearbeitet ein PDF und lädt es ohne Erklärung neu hoch. Ein Scan hat kein Datum, keinen Händler und keinen Besitzer. Wochen später weiß niemand, welche Version genehmigt wurde oder worauf die Entscheidung beruhte.
Eine gute dokumentzentrierte App fühlt sich schnell und verlässlich an. Nutzer sollten diese Fragen in Sekunden beantworten können:
Diese Klarheit kommt von Definitionen. Bevor Sie Bildschirme bauen, legen Sie fest, was in Ihrer App „Version“, „Vorschau“, „Metadaten“ und „Status“ bedeutet. Sind diese Begriffe vage, bekommen Sie Duplikate, verwirrende Historien und Prüfabläufe, die nicht zur realen Arbeit passen.
Die UI wirkt oft einfach (eine Liste, ein Viewer, ein paar Buttons), aber das Datenmodell trägt die Last. Sind die Kernobjekte richtig, werden Audit‑Historie, schnelle Vorschauen und verlässliche Freigaben deutlich einfacher.
Beginnen Sie damit, den „Dokumentdatensatz“ vom „Dateiinhalt“ zu trennen. Der Datensatz ist das, worüber Nutzer sprechen (Rechnung von ACME, Taxibeleg). Der Inhalt sind die Bytes (PDF, JPG), die ersetzt, nachverarbeitet oder verschoben werden können, ohne die Bedeutung des Dokuments in der App zu verändern.
Eine praktische Menge an Objekten zum Modellieren:
Entscheiden Sie, was eine ID bekommt, die sich nie ändert. Eine nützliche Regel ist: Document‑ID lebt ewig, während Files und Previews regenerierbar sind. Auch Versionen brauchen stabile IDs, weil Menschen auf „wie es gestern aussah“ verweisen und Sie eine Audit‑Spur benötigen.
Modellieren Sie Beziehungen explizit. Ein Document hat viele Versions. Jede Version kann mehrere Previews haben (verschiedene Größen oder Formate). So bleiben Listenseiten schnell, weil sie leichtgewichtige Preview‑Daten laden können, während Detailseiten die volle Datei nur bei Bedarf nachladen.
Beispiel: Ein Nutzer lädt ein zerknittertes Belegfoto hoch. Sie erstellen ein Document, speichern die originale File, generieren ein Thumbnail Preview und legen Version 1 an. Später lädt der Nutzer einen klareren Scan hoch. Das wird Version 2, ohne Kommentare, Genehmigungen oder Suche, die am Document hängen, zu unterbrechen.
Menschen erwarten, dass ein Dokument sich im Laufe der Zeit ändert, ohne „in ein anderes Objekt zu verwandeln“. Der einfachste Weg, das zu ermöglichen, ist Identität (Document) vom Inhalt (Version und Files) zu trennen.
Beginnen Sie mit einer stabilen document_id, die sich nie ändert. Selbst wenn der Nutzer dasselbe PDF erneut hochlädt, ein verschwommenes Foto ersetzt oder einen korrigierten Scan hochlädt, sollte es derselbe Document‑Datensatz bleiben. Kommentare, Zuweisungen und Audit‑Logs hängen sauber an einer dauerhaften ID.
Behandeln Sie jede sinnvolle Änderung als neue version‑Zeile. Jede Version sollte erfassen, wer sie erstellt hat und wann, plus Speicherverweise (File‑Key, Checksumme, Größe, Seitenanzahl) und abgeleitete Artefakte (OCR‑Text, Preview‑Bilder), die genau zu dieser Datei gehören. Vermeiden Sie „In‑Place‑Editieren“. Das wirkt anfangs einfacher, zerstört aber die Nachverfolgbarkeit und macht Fehler schwer rückgängig zu machen.
Für schnelle Lesezugriffe halten Sie ein current_version_id auf dem Document. Die meisten Bildschirme brauchen nur „die neueste“, so dass Sie nicht bei jedem Laden die Versionen sortieren müssen. Wenn Sie die Historie brauchen, laden Sie Versionen separat und zeigen eine saubere Timeline.
Rollbacks sind nur ein Pointer‑Wechsel. Statt etwas zu löschen, setzen Sie current_version_id zurück auf eine ältere Version. Das ist schnell, sicher und hält die Audit‑Spur intakt.
Um die Historie verständlich zu halten, protokollieren Sie, warum jede Version existiert. Ein kleines, konsistentes reason‑Feld (plus eine optionale Notiz) verhindert eine Timeline voller mysteriöser Updates. Übliche Gründe sind re‑upload replacement, scan cleanup, OCR correction, redaction und approval edit.
Beispiel: Ein Finanzteam lädt ein Belegfoto hoch, ersetzt es durch einen klareren Scan und korrigiert anschließend OCR, damit der Gesamtbetrag lesbar ist. Jeder Schritt ist eine neue Version, aber das Document bleibt ein Element im Postfach. War die OCR‑Korrektur falsch, ist ein Rollback ein Klick, weil Sie nur current_version_id wechseln.
In dokumentzentrierten Workflows ist die Vorschau oft das zentrale Element, mit dem Nutzer interagieren. Sind Vorschauen langsam oder unzuverlässig, wirkt die gesamte App kaputt.
Behandeln Sie die Vorschau‑Generierung als separaten Job, nicht als etwas, auf das der Upload‑Bildschirm warten muss. Speichern Sie zuerst die Originaldatei, geben Sie die Kontrolle an den Nutzer zurück und generieren Sie dann im Hintergrund Previews. Das hält die UI reaktiv und macht Wiederholungen sicher.
Speichern Sie mehrere Vorschaugrößen. Eine Größe passt niemals überall: ein kleines Thumbnail für Listen, ein mittleres Bild für Split‑Views und Vollseiten‑Bilder für die Detailprüfung (seitenweise bei PDFs).
Verfolgen Sie den Preview‑Zustand explizit, damit die UI immer weiß, was angezeigt werden kann: pending, ready, failed und needs_retry. Halten Sie die Labels UI‑freundlich, aber die Zustände klar im Datenmodell.
Um das Rendern schnell zu halten, cachen Sie abgeleitete Werte zusammen mit dem Preview‑Record, statt sie bei jedem View neu zu berechnen. Übliche Felder sind Seitenzahl, Preview‑Breite und ‑Höhe, Rotation (0/90/180/270) und optional „beste Seite für Thumbnail“.
Designen Sie für langsame und unordentliche Dateien. Eine 200‑seitige eingescanntes PDF oder ein zerknittertes Belegfoto kann Zeit benötigen. Nutzen Sie progressives Laden: Zeigen Sie die erste fertige Seite sofort, und füllen Sie den Rest nach.
Beispiel: Ein Nutzer lädt 30 Belegfotos hoch. Die Listenansicht zeigt Thumbnails als „pending“, dann wechselt jede Karte auf „ready“, sobald die Vorschau fertig ist. Scheitern einige wegen korrupten Bildern, bleiben sie sichtbar mit einer klaren Retry‑Aktion, statt zu verschwinden oder den ganzen Batch zu blockieren.
Metadaten verwandeln einen Haufen Dateien in etwas, das Sie durchsuchen, sortieren, prüfen und genehmigen können. Sie helfen Menschen, einfache Fragen schnell zu beantworten: Was ist das? Von wem kommt es? Ist es gültig? Was soll als Nächstes passieren?
Eine praktische Methode, Metadaten sauber zu halten, ist sie nach Herkunft zu trennen:
Diese Kategorien vermeiden spätere Streitereien. Ist ein Gesamtbetrag falsch, sehen Sie, ob er aus OCR oder einer manuellen Änderung stammt.
Bei Belegen und Rechnungen zahlt sich eine kleine, konsistente Feldmenge aus (gleiche Benennung, gleiche Formate). Übliche Ankerfelder sind vendor, date, total, currency und document_number. Halten Sie sie zunächst optional. Leute laden unvollständige Scans und verschwommene Fotos hoch, und das Blockieren von Fortschritt, weil ein Feld fehlt, verlangsamt den Workflow.
Behandeln Sie unbekannte Werte als erstklassig. Verwenden Sie explizite Zustände wie null/unknown und geben Sie ggf. einen Grund (fehlende Seite, unleserlich, nicht anwendbar). So kann das Dokument weiterbewegt werden und Prüfende sehen trotzdem, was Aufmerksamkeit braucht.
Speichern Sie auch Herkunft und Confidence für extrahierte Felder. Die Quelle kann Nutzer, OCR, Import oder API sein. Confidence kann ein 0–1‑Score oder eine kleine Gruppe wie high/medium/low sein. Hat OCR „$18.70“ mit niedriger Confidence gelesen, weil die letzte Ziffer verschmiert ist, kann die UI das hervorheben und um Bestätigung bitten.
Mehrseitige Dokumente brauchen eine zusätzliche Entscheidung: Was gehört zum ganzen Dokument, was zu einer einzelnen Seite. Totalbeträge und Händler gehören meist zum Dokument. Seitenbezogene Notizen, Redaktionen, Rotation und Seitenklassifikation gehören oft auf Seitenebene.
Status beantwortet eine Frage: „Wo befindet sich dieses Dokument im Prozess?“ Halten Sie es klein und langweilig. Wenn Sie bei jedem Wunsch einen neuen Status hinzufügen, enden Sie mit Filtern, denen niemand vertraut.
Eine praktische Menge an Geschäftsstatus, die reale Entscheidungen abbildet:
Halten Sie „processing“ aus dem Geschäftsstatus heraus. OCR‑Läufe und Preview‑Generierung beschreiben, was das System tut, nicht was eine Person als Nächstes tun sollte. Speichern Sie das als getrennte Verarbeitungszustände.
Trennen Sie außerdem Zuweisung von Status (assignee_id, team_id, due_date). Ein Dokument kann Approved sein und trotzdem für Follow‑Up zugewiesen bleiben, oder Needs review ohne aktuellen Besitzer.
Protokollieren Sie die Status‑Historie, nicht nur den aktuellen Wert. Ein einfaches Log wie (from_status, to_status, changed_at, changed_by, reason) ist hilfreich, wenn jemand fragt: „Wer hat diesen Beleg abgelehnt und warum?“
Legen Sie schließlich fest, welche Aktionen in welchem Status erlaubt sind. Halten Sie Regeln einfach: Imported kann zu Needs review wechseln; Approved ist schreibgeschützt, es sei denn, eine neue Version wird erstellt; Rejected kann wieder geöffnet werden, muss aber den vorherigen Grund behalten.
Die meiste Zeit wird damit verbracht, eine Liste zu scannen, ein Element zu öffnen, ein paar Felder zu korrigieren und weiterzugehen. Gute UI macht diese Schritte schnell und vorhersehbar.
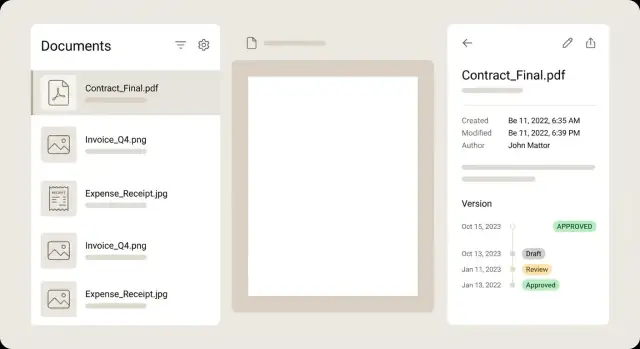
Für die Dokumentliste behandeln Sie jede Zeile wie eine Zusammenfassung, damit Nutzer entscheiden können, ohne jede Datei zu öffnen. Eine starke Zeile zeigt ein kleines Thumbnail, einen klaren Titel, ein paar Schlüsselfelder (Händler, Datum, Gesamt), ein Status‑Badge und eine dezente Warnung, wenn etwas Aufmerksamkeit braucht.
Halten Sie die Detailansicht ruhig und gut scanbar. Ein häufiges Layout ist Vorschau links und Metadaten rechts, mit Edit‑Kontrollen neben jedem Feld. Nutzer sollten zoomen, rotieren und Seiten blättern können, ohne ihren Platz im Formular zu verlieren. Wurde ein Feld aus OCR extrahiert, zeigen Sie eine kleine Confidence‑Hinweis, und idealerweise heben Sie im Preview den Bereich hervor, wenn das Feld fokussiert ist.
Versionen funktionieren besser als Timeline, nicht als Dropdown. Zeigen Sie wer was wann geändert hat und lassen Sie Nutzer jede frühere Version im Read‑Only Modus öffnen. Bieten Sie Vergleiche an, die sich auf Metadatenunterschiede konzentrieren (Betrag geändert, Händler korrigiert), statt Pixel‑für‑Pixel PDF‑Diffs zu erzwingen.
Der Prüfmodus sollte auf Geschwindigkeit optimiert sein. Ein keyboard‑first Triage‑Flow reicht oft: schnelle Approve/Reject‑Aktionen, schnelle Korrekturen für gängige Felder und ein kurzes Kommentarfeld für Ablehnungen.
Leere Zustände sind wichtig, weil Dokumente häufig in Bearbeitung sind. Statt eines leeren Feldes erklären Sie, was passiert: „Vorschau wird erstellt“, „OCR läuft“ oder „Für diesen Dateityp gibt es noch keine Vorschau“.
Ein einfacher Workflow fühlt sich an wie „hochladen, prüfen, genehmigen“. Unter der Haube funktioniert er am besten, wenn Sie die Datei selbst (Versionen und Previews) vom geschäftlichen Sinn (Metadaten und Status) trennen.
Der Nutzer lädt ein PDF, Foto oder Belegscan hoch und sieht es sofort im Postfach. Warten Sie nicht auf abgeschlossene Verarbeitung. Zeigen Sie Dateiname, Upload‑Zeit und ein klares Badge wie „Processing“. Wenn Sie die Quelle kennen (E‑Mail‑Import, Handy‑Kamera, Drag‑and‑Drop), zeigen Sie diese ebenfalls an.
Beim Upload erstellen Sie einen Document‑Datensatz (das langlebige Objekt) und einen Version‑Datensatz (diese spezifische Datei). Setzen Sie current_version_id auf die neue Version. Speichern Sie preview_state = pending und extraction_state = pending, damit die UI ehrlich kommunizieren kann, was bereit ist.
Die Detailansicht sollte sofort öffnen, aber einen Platzhalter‑Viewer und eine klare Meldung „Vorschau wird vorbereitet“ zeigen, statt eines kaputten Frames.
Ein Hintergrundjob erstellt Thumbnails und eine anzeigbare Vorschau (Seitenbilder für PDFs, skalierte Bilder für Fotos). Ein anderer Job extrahiert Metadaten (Händler, Datum, Gesamt, Währung, Dokumenttyp). Wenn ein Job fertig ist, aktualisieren Sie nur dessen Zustand und Zeitstempel, sodass Sie Fehler neu versuchen können, ohne alles andere zu berühren.
Halten Sie die UI kompakt: zeigen Sie Preview‑Zustand, Daten‑Zustand und heben Sie Felder mit niedriger Confidence hervor.
Wenn die Vorschau bereit ist, korrigieren Prüfer Felder, fügen Notizen hinzu und bewegen das Dokument durch Geschäftsstatus wie Imported → Needs review → Approved (oder Rejected). Protokollieren Sie, wer was wann geändert hat.
Lädt ein Prüfer eine korrigierte Datei hoch, wird daraus eine neue Version und das Document geht automatisch in Needs review zurück.
Exporte, Buchhaltungs‑Synchronisationen oder interne Reports sollten von current_version_id und dem genehmigten Metadaten‑Snapshot lesen, nicht von „letzter Extraktion“. So verhindern Sie, dass ein halbverarbeiteter Re‑Upload Zahlen verändert.
Dokumentzentrierte Workflows scheitern aus langweiligen Gründen: frühe Abkürzungen werden zum täglichen Ärger, sobald Leute Duplikate hochladen, Fehler korrigieren oder fragen: „Wer hat das wann geändert?"
Die Bezeichnung der Datei als Identität des Dokuments zu behandeln, ist ein Klassiker. Namen ändern sich, Nutzer laden erneut hoch und Kameras erzeugen Duplikate wie IMG_0001. Geben Sie jedem Document eine stabile ID und behandeln Sie den Dateinamen als Label.
Das Überschreiben der Originaldatei bei Ersatz führt ebenfalls zu Problemen. Es wirkt einfacher, aber Sie verlieren die Audit‑Spur und können später grundlegende Fragen nicht mehr beantworten (was war genehmigt, was wurde bearbeitet, was wurde versendet). Halten Sie das Binary unveränderlich und fügen Sie stattdessen einen neuen Version‑Datensatz hinzu.
Statusverwirrung schafft subtile Bugs. „OCR läuft“ ist nicht dasselbe wie „Needs review“. Verarbeitungszustände beschreiben, was das System tut; Geschäftsstatus beschreibt, was eine Person als Nächstes tun soll. Wird das vermischt, landen Dokumente in falschen Buckets.
UI‑Entscheidungen können ebenfalls Reibung erzeugen. Blockieren Sie den Bildschirm nicht, bis Vorschauen generiert sind — Nutzer empfinden die App sonst als langsam, auch wenn der Upload erfolgreich war. Zeigen Sie das Dokument sofort mit einem klaren Platzhalter, und tauschen Sie Thumbnails aus, sobald sie fertig sind.
Zuletzt werden Metadaten unzuverlässig, wenn Sie Werte ohne Provenienz speichern. Stamme der Gesamtbetrag aus OCR, geben Sie das an. Bewahren Sie Zeitstempel auf.
Eine kurze Checkliste:
Beispiel: In einer Beleg‑App lädt ein Nutzer ein klareres Foto hoch. Versionieren Sie es, behalten Sie das alte Bild, markieren Sie OCR als Reprocessing und setzen Sie das Document auf Needs review, bis ein Mensch den Betrag bestätigt.
Dokumentzentrierte Workflows fühlen sich „fertig“ an, wenn Menschen dem, was sie sehen, vertrauen können und sich erholen können, wenn etwas schiefgeht. Testen Sie vor dem Launch mit unordentlichen, echten Dokumenten (verschwommene Belege, rotierte PDFs, wiederholte Uploads).
Fünf Prüfungen, die die meisten Überraschungen aufdecken:
Ein schneller Realitätscheck: Bitten Sie jemanden, drei ähnliche Belege zu prüfen und absichtlich bei einem einen falschen Wert zu machen. Kann die Person die aktuelle Version erkennen, den Status verstehen und den Fehler in unter einer Minute beheben, sind Sie nah dran.
Monatliche Belegerstattungen sind ein klares Beispiel für dokumentzentrierte Arbeit. Eine Mitarbeiterin lädt Belege hoch, dann prüfen zwei Personen: zuerst die Führungskraft, dann die Buchhaltung. Der Beleg ist das Produkt; Ihre App steht oder fällt mit Versionierung, Vorschauen, Metadaten und klaren Status.
Jamie lädt ein Foto eines Taxibelegs hoch. Ihr System erstellt Document #1842 mit Version v1 (der Originaldatei), einem Thumbnail und einer Vorschau sowie Metadaten wie merchant, date, currency, total und einem OCR‑Confidence‑Score. Das Document startet in Imported und wechselt zu Needs review, sobald Vorschau und Extraktion fertig sind.
Später lädt Jamie denselben Beleg aus Versehen erneut hoch. Eine Dublettenprüfung (Datei‑Hash plus ähnliche Händler/Datum/Total) kann eine einfache Wahl anzeigen: „Sieht aus wie Duplikat von #1842. Anhängen oder verwerfen?“ Hängt sie an, speichern Sie es als weitere File, die mit demselben Document verknüpft ist, so behalten Sie einen Review‑Thread und einen Status.
Während der Prüfung sieht die Führungskraft die Vorschau, Schlüsselwerte und Warnungen. OCR hat den Gesamtbetrag als $18.00 geraten, das Bild zeigt aber klar $13.00. Jamie korrigiert den Betrag. Überschreiben Sie nicht die Historie. Erstellen Sie Version v2 mit aktualisierten Feldern, behalten Sie v1 unverändert und protokollieren Sie „Total corrected by Jamie“.
Wenn Sie diesen Workflow schnell bauen wollen, kann Koder.ai (koder.ai) Ihnen helfen, die erste Version der App aus einem Chat‑Plan zu generieren, aber die gleiche Regel gilt: Definieren Sie zuerst die Objekte und Zustände, und lassen Sie dann die Bildschirme folgen.
Praktische nächste Schritte:
Eine dokumentzentrierte App behandelt das Dokument als das zentrale Objekt, an dem Nutzer arbeiten — nicht als bloße Anlage. Nutzer müssen es öffnen können, ihm vertrauen, verstehen, was sich geändert hat, und auf Basis dieses Dokuments entscheiden, was als Nächstes passiert.
Beginnen Sie mit einem Postfach/ einer Liste, einer Dokumentdetailansicht mit schneller Vorschau, einem einfachen Prüfbereich für Genehmigen/Ablehnen/Änderungen anfordern und einer Möglichkeit zum Export oder Teilen. Diese vier Bildschirme decken die häufige Schleife Finden → Öffnen → Entscheiden → Weitergeben ab.
Modellieren Sie einen stabilen Document‑Datensatz, der nie verändert wird, und speichern Sie die eigentlichen Bytes als separate File‑Objekte. Fügen Sie dann Version hinzu als Snapshot, der ein Dokument mit einer spezifischen Datei (und deren abgeleiteten Ergebnissen) verbindet. Diese Trennung erhält Kommentare, Zuweisungen und Historie, auch wenn die Datei ersetzt wird.
Jede sinnvolle Änderung sollte eine neue Version werden, statt die Datei zu überschreiben. Halten Sie ein current_version_id auf dem Dokument für schnelle „aktuelle“-Abfragen und speichern Sie eine Timeline älterer Versionen für Audit und Rollback. So vermeiden Sie Verwirrung darüber, was genehmigt wurde und warum.
Generieren Sie Vorschauen asynchron, nachdem die Originaldatei gespeichert wurde, damit Uploads sofort zurückgegeben werden und Wiederholungen sicher sind. Verfolgen Sie Zustände wie pending/ready/failed, damit die UI ehrlich ist, und speichern Sie mehrere Größen, damit Listen leichtgewichtig bleiben und Detailansichten scharf sind.
Speichern Sie Metadaten in drei Buckets: System (Dateiname, Größe, Typ), Extrahiert (OCR‑Felder und Confidence) und Nutzereingabe (Korrekturen, Tags, Notizen). Dokumentieren Sie die Herkunft, damit klar ist, ob ein Wert von OCR oder einem Menschen stammt, und zwingen Sie nicht alle Felder bereits am Anfang auszufüllen.
Verwenden Sie eine kleine Menge an Geschäftsstatus, die beschreiben, was eine Person als Nächstes tun soll: Imported, Needs review, Approved, Rejected, Archived. Verarbeiten Sie systeminterne Status (z. B. OCR läuft, Vorschau generiert) getrennt, damit Dokumente nicht in einem Status „steckenbleiben“, der Menschliches und Maschinelles vermischt.
Speichern Sie unveränderliche File‑Checksummen und vergleichen Sie sie beim Upload; ergänzen Sie das mit einem zweiten Check über Schlüsselwerte wie Händler/Datum/Betrag, wenn verfügbar. Beim Erkennen eines Duplikats bieten Sie die Wahl: an denselben Dokumentthread anhängen oder verwerfen, damit die Prüfhistorie nicht gesplittet wird.
Führen Sie ein Status‑Historienprotokoll mit wer was wann und warum geändert hat, und machen Sie Versionen über eine Timeline lesbar. Rollback ist eine Pointer‑Änderung zurück zu einer älteren Version, kein Löschen — so können Sie schnell wiederherstellen und die Audit‑Spur behalten.
Definieren Sie zuerst die Objekte und Zustände, und lassen Sie dann die UI folgen. Wenn Sie Koder.ai nutzen, um eine App aus einem Chat‑Plan zu generieren, seien Sie explizit bei Document/Version/File, Vorschau‑ und Extraktionszuständen sowie Statusregeln, damit die erzeugten Bildschirme sauberes Workflow‑Verhalten widerspiegeln.