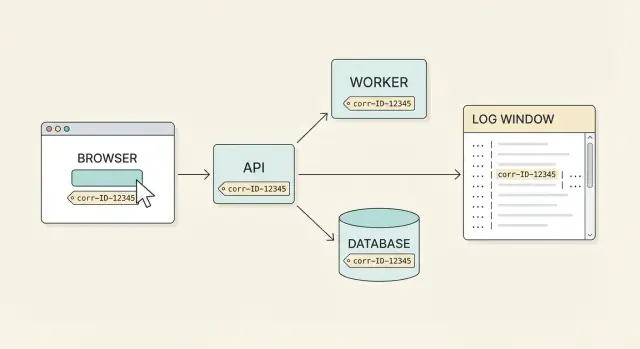
Warum Correlation IDs für den Support wichtig sind
Support bekommt selten einen sauberen Bug-Report. Ein Nutzer sagt: "Ich habe auf Bezahlen geklickt und es ist fehlgeschlagen", aber dieser eine Klick kann Browser, API-Gateway, Payment-Service, Datenbank und einen Hintergrundjob betreffen. Jeder Teil protokolliert seinen eigenen Ausschnitt der Geschichte zu unterschiedlichen Zeiten auf unterschiedlichen Maschinen. Ohne ein gemeinsames Label raten Sie, welche Logzeilen zusammengehören.
Eine Correlation ID ist dieses gemeinsame Label. Es ist eine einzelne ID, die an eine Benutzeraktion (oder einen logischen Workflow) angehängt wird und jede Anfrage, jeden Retry und jeden Service-Hop mitträgt. Mit echter End-to-End-Abdeckung können Sie bei einer Nutzerbeschwerde beginnen und die vollständige Timeline über Systeme hinweg zusammenziehen.
Manche verwechseln ein paar ähnliche IDs. Hier die klare Trennung:
- Correlation ID: gruppiert alles, was zu einer Aktion gehört (z. B. „Einstellungen speichern").
- Request ID: identifiziert eine einzelne HTTP-Anfrage. Retries erzeugen neue Request-IDs.
- Trace ID: von verteilten Tracing-Tools verwendet; ähnliches Ziel, oft von Tracing-Bibliotheken generiert.
- Session ID: identifiziert eine Benutzersitzung über viele Aktionen; für das Debuggen eines einzelnen Vorfalls zu breit.
Wie gutes Verhalten aussieht, ist einfach: ein Nutzer meldet ein Problem, Sie fragen nach der Correlation ID, die in der UI angezeigt wird (oder in einem Support-Screen), und jedes Teammitglied kann die komplette Geschichte in Minuten finden. Sie sehen die Frontend-Anfrage, die API-Antwort, die Backend-Schritte und das Datenbankergebnis — alles miteinander verknüpft.
Legen Sie Konventionen für Correlation IDs fest
Bevor Sie etwas erzeugen, einigen Sie sich auf ein paar Regeln. Wenn jedes Team einen anderen Header-Namen oder ein anderes Logfeld wählt, bleibt der Support trotzdem beim Raten.
Starten Sie mit einem kanonischen Namen und verwenden Sie ihn überall. Eine übliche Wahl ist ein HTTP-Header wie X-Correlation-Id sowie ein strukturiertes Logfeld wie correlation_id. Wählen Sie eine Schreibweise und ein Casing, dokumentieren Sie es und stellen Sie sicher, dass Ihr Reverse-Proxy oder Gateway den Header nicht umbenennt oder verwirft.
Wählen Sie ein Format, das sich leicht erzeugen lässt und unbedenklich in Tickets und Chats geteilt werden kann. UUIDs funktionieren gut, weil sie eindeutig und unauffällig sind. Halten Sie die ID kurz genug zum Kopieren, aber nicht so kurz, dass Kollisionsrisiken steigen. Konsistenz ist wichtiger als Raffinesse.
Entscheiden Sie außerdem, wo die ID sichtbar sein muss, damit Menschen sie tatsächlich nutzen können. In der Praxis bedeutet das: sie sollte in Requests, Logs und Fehlerausgaben enthalten sein und in dem Tool durchsuchbar sein, das Ihr Team verwendet.
Definieren Sie, wie lange eine ID leben sollte. Ein guter Default ist eine Benutzeraktion, z. B. „auf Bezahlen geklickt" oder „Profil gespeichert." Bei längeren Workflows, die über Services und Queues springen, behalten Sie dieselbe ID, bis der Workflow endet, und starten dann eine neue für die nächste Aktion. Vermeiden Sie „eine ID für die ganze Session", weil Suchen schnell zu laut werden.
Eine harte Regel: niemals personenbezogene Daten in die ID packen. Keine E-Mails, Telefonnummern, Benutzer-IDs oder Bestellnummern. Wenn Sie diesen Kontext brauchen, loggen Sie ihn in separaten Feldern mit passenden Datenschutzkontrollen.
Die ID im Frontend erzeugen (praktischer Ansatz)
Der einfachste Ort, um eine Correlation ID zu starten, ist der Moment, in dem der Nutzer eine Aktion beginnt, die Ihnen wichtig ist: Klick auf "Speichern", Absenden eines Formulars oder Start eines Flows, der mehrere Anfragen auslöst. Wenn Sie warten, bis das Backend sie erstellt, verlieren Sie oft den ersten Teil der Geschichte (UI-Fehler, Retries, abgebrochene Requests).
Verwenden Sie ein zufälliges, eindeutiges Format. UUID v4 ist eine gängige Wahl, weil sie sich leicht erzeugen lässt und kaum Kollisionen hat. Halten Sie die ID undurchsichtig (keine Benutzernamen, E-Mails oder Zeitstempel), damit Sie keine persönlichen Daten in Headern und Logs leaken.
Eine ID für einen Workflow erzeugen und behalten
Behandeln Sie einen „Workflow" als eine Benutzeraktion, die mehrere Requests auslösen kann: validieren, hochladen, Datensatz anlegen und dann Listen aktualisieren. Erzeugen Sie eine ID, wenn der Workflow startet, und behalten Sie sie, bis der Workflow endet (Erfolg, Fehler oder Abbruch durch den Nutzer). Ein einfaches Muster ist, sie im Component-State oder in einem leichten Request-Context-Objekt zu speichern.
Wenn der Nutzer dieselbe Aktion zweimal startet, erzeugen Sie für den zweiten Versuch eine neue Correlation ID. So kann der Support zwischen „gleicher Klick, erneut versucht" und „zwei separate Einreichungen" unterscheiden.
Fügen Sie sie jeder Request hinzu, die zu diesem Workflow gehört
Hängen Sie die ID an jeden API-Call, den der Workflow auslöst, üblicherweise via Header wie X-Correlation-ID. Wenn Sie einen gemeinsamen API-Client verwenden (Fetch-Wrapper, Axios-Instanz etc.), übergeben Sie die ID einmal und lassen den Client sie in alle Calls einfügen.
const correlationId = crypto.randomUUID();
await api.post('/orders', payload, {
headers: { 'X-Correlation-ID': correlationId }
});
await api.get('/orders/summary', {
headers: { 'X-Correlation-ID': correlationId }
});
Wenn Ihre UI Hintergrundanfragen macht, die nichts mit der Aktion zu tun haben (Polling, Analytics, Auto-Refresh), verwenden Sie die Workflow-ID nicht für diese. Halten Sie Correlation IDs fokussiert, damit eine ID eine Geschichte erzählt.
Die ID zuverlässig durch Ihre APIs leiten
Sobald Sie eine Correlation ID im Browser erzeugt haben, ist die Aufgabe simpel: sie muss mit jeder Anfrage das Frontend verlassen und unverändert an jeder API-Grenze ankommen. Genau hier bricht es am häufigsten, wenn Teams neue Endpunkte, Clients oder Middleware hinzufügen.
Der sicherste Default ist ein HTTP-Header in jedem Call (z. B. X-Correlation-Id). Header lassen sich an einer Stelle hinzufügen (Fetch-Wrapper, Axios-Interceptor, mobile Networking-Layer) und erfordern keine Payload-Änderungen.
Bei Cross-Origin-Requests stellen Sie sicher, dass Ihre API diesen Header erlaubt. Ansonsten kann der Browser ihn stillschweigend blockieren und Sie glauben fälschlicherweise, Sie würden ihn senden.
Wenn Sie die ID in der Query-String oder im Request-Body übergeben müssen (manche Drittanbieter-Tools oder Datei-Uploads erzwingen das), bleiben Sie konsistent und dokumentieren es. Wählen Sie ein Feld und verwenden Sie es überall. Mischen Sie nicht correlationId, requestId und cid je nach Endpoint.
Retries sind eine weitere häufige Falle. Ein Retry sollte dieselbe Correlation ID behalten, wenn es dieselbe Benutzeraktion ist. Beispiel: ein Nutzer klickt "Speichern", das Netzwerk bricht ab, Ihr Client versucht den POST erneut. Support sollte eine verbundene Spur sehen, nicht drei unzusammenhängende. Ein neuer Nutzerklick (oder ein neuer Hintergrundjob) sollte eine neue ID bekommen.
Für WebSockets inkludieren Sie die ID in der Nachrichtenhülle, nicht nur im initialen Handshake. Eine Verbindung kann viele Benutzeraktionen transportieren.
Ein einfacher Zuverlässigkeits-Check:
- Ein gemeinsamer Client-Helper fügt den Header bei jeder Anfrage hinzu.
- Retries verwenden dieselbe ID für dieselbe Aktion.
- Fallbacks im Body/Query nutzen ein dokumentiertes Feld.
- WebSocket-Nachrichten enthalten ein explizites
correlationId-Feld.
Verhalten am API-Entry-Point definieren
Generieren Sie Code, den Sie exportieren können
Behalten Sie die Kontrolle, während Koder.ai Ihren React-, Go- und Postgres-Stack generiert.
Ihr API-Edge (Gateway, Load Balancer oder der erste Web-Service, der Traffic empfängt) ist der Ort, an dem Correlation IDs entweder verlässlich werden oder zum Rätsel werden. Behandeln Sie diesen Entry-Point als Quelle der Wahrheit.
Akzeptieren Sie eine eingehende ID, wenn der Client eine sendet, aber gehen Sie nicht davon aus, dass sie immer vorhanden ist. Wenn sie fehlt, erzeugen Sie sofort eine neue und verwenden Sie sie für den Rest der Anfrage. So bleibt alles funktional, selbst wenn einige Clients älter oder falsch konfiguriert sind.
Führen Sie eine leichte Validierung durch, damit schlechte Werte Ihre Logs nicht verschmutzen. Bleiben Sie permissiv: prüfen Sie Länge und erlaubte Zeichen, aber vermeiden Sie strenge Formate, die echten Traffic ablehnen. Erlauben Sie z. B. 16–64 Zeichen und Buchstaben, Zahlen, Bindestrich und Unterstrich. Falls der Wert die Validierung nicht besteht, ersetzen Sie ihn durch eine frische ID und fahren fort.
Machen Sie die ID für den Aufrufer sichtbar. Geben Sie sie immer in Antwort-Headern zurück und fügen Sie sie in Fehlerbodies ein. So kann ein Nutzer sie aus der UI kopieren oder ein Support-Mitarbeiter danach fragen und genau die Logspur finden.
Eine praktische Edge-Policy sieht so aus:
- Lesen Sie
X-Correlation-ID (oder Ihren gewählten Header) aus der Anfrage.
- Falls fehlend oder ungültig, erzeugen Sie eine neue ID und hängen Sie sie an den Request-Context.
- Fügen Sie
X-Correlation-ID zu jeder Antwort hinzu, auch bei Fehlern.
- Bei JSON-Fehlern geben Sie die ID im Payload zurück.
Ein Beispiel für ein Fehler-Payload (was Support in Tickets und Screenshots sehen sollte):
{
"error": {
"code": "PAYMENT_FAILED",
"message": "We could not confirm the payment.",
"correlation_id": "c3a8f2d1-9b24-4c61-8c4a-2a7c1b9c2f61"
}
}
Die ID über Backend-Services weiterreichen
Sobald eine Anfrage Ihr Backend erreicht, behandeln Sie die Correlation ID als Teil des Request-Context, nicht als etwas, das Sie in einer Global-Variable parken. Globals brechen, sobald Sie zwei Anfragen gleichzeitig bearbeiten oder wenn asynchrone Arbeit nach der Antwort fortgesetzt wird.
Eine skalierbare Regel: jede Funktion, die loggen oder einen weiteren Service aufrufen kann, sollte den Context erhalten, der die ID enthält. In Go-Services bedeutet das üblicherweise, context.Context durch Handler, Business-Logik und Client-Code zu reichen.
Wenn Service A Service B aufruft, kopieren Sie dieselbe ID in die ausgehende Anfrage. Erzeugen Sie nicht mittendrin eine neue, es sei denn, Sie behalten das Original als separates Feld (z. B. parent_correlation_id). Wenn Sie IDs ändern, verliert der Support den einen Faden, der die Geschichte verbindet.
Propagation wird oft an einigen vorhersehbaren Stellen vergessen: Background-Jobs, die während einer Anfrage gestartet werden, Retries in Client-Libraries, später ausgelöste Webhooks und Fan-Out-Calls. Jede asynchrone Nachricht (Queue/Job) sollte die ID tragen, und jede Retry-Logik sollte sie preservieren.
Logs sollten strukturiert sein mit einem stabilen Feldnamen wie correlation_id. Wählen Sie eine Schreibweise und verwenden Sie sie überall. Vermeiden Sie ein Gemisch aus requestId, req_id und traceId, es sei denn, Sie definieren auch eine klare Zuordnung.
Wenn möglich, fügen Sie die ID auch in die Datenbank-Sichtbarkeit ein. Ein praktischer Ansatz ist, sie in Query-Kommentare oder Session-Metadaten aufzunehmen, sodass langsame Query-Logs sie zeigen. Wenn jemand meldet: „Speichern hat 10 Sekunden gehangen", kann Support nach correlation_id=abc123 suchen und den API-Log, den Downstream-Call und die eine langsame SQL-Anweisung sehen, die die Verzögerung verursacht hat.
Die ID in für Menschen nutzbaren Logs einbinden
Eine Correlation ID hilft nur, wenn Menschen sie finden und ihr folgen können. Machen Sie sie zu einem erstklassigen Logfeld (nicht vergraben im Nachrichtentext) und halten Sie den Rest des Logeintrags über Services hinweg konsistent.
Logfelder, die die ID nützlich machen
Kombinieren Sie die Correlation ID mit einer kleinen Menge Felder, die beantworten: wann, wo, was und wer (auf eine user-sichere Art). Für die meisten Teams bedeutet das:
timestamp (mit Zeitzone)service und env (api, worker, prod, staging)route (oder Operationsname) und methodstatus und duration_ms- eine user-sichere Kennung (z. B.
account_id oder ein gehashter Benutzer-ID, nicht eine E-Mail)
Damit kann Support per ID suchen, bestätigen, dass es die richtige Anfrage ist, und sehen, welcher Service sie behandelt hat.
Was bei Start, Erfolg und Fehler geloggt werden sollte
Zielen Sie auf ein paar aussagekräftige Breadcrumbs pro Anfrage, nicht auf ein Transkript.
- Start: correlation ID, Route, user-sichere Kennung und wichtige Inputs (zusammengefasst).
- Erfolg: correlation ID, Status, Dauer und ein kurzes Ergebnis (z. B.
rows=12).
- Fehler: correlation ID, Fehlerart, sichere Kontextinfos und wo es passiert ist (Handler, Dependency).
Um laute Logs zu vermeiden, halten Sie Debug-Level-Details standardmäßig aus. Protokollieren Sie nur Ereignisse, die helfen zu beantworten: „Wo ist es fehlgeschlagen?" Wenn eine Zeile nicht hilft, das Problem zu lokalisieren oder die Auswirkungen zu messen, gehört sie wahrscheinlich nicht in Info-Logs.
Redaktion ist genauso wichtig wie Struktur. Niemals PII in die Correlation ID oder in Logs schreiben: keine E-Mails, Namen, Telefonnummern, vollständige Adressen oder rohe Tokens. Falls Sie einen Nutzer identifizieren müssen, loggen Sie eine interne ID oder einen Einweg-Hash.
Beispiel: Einen Nutzerbericht von UI bis zur Datenbank nachverfolgen
Machen Sie Logs standardmäßig durchsuchbar
Fügen Sie jedem Logeintrag einen konsistenten correlation_id-Feldnamen über alle Services hinzu.
Ein Nutzer schreibt an den Support: „Checkout ist fehlgeschlagen, als ich auf Bezahlen geklickt habe." Die beste Anschlussfrage ist einfach: „Können Sie die Correlation ID einfügen, die auf dem Fehlerbildschirm angezeigt wird?" Sie antworten mit cid=9f3c2b1f6a7a4c2f.
Support hat jetzt einen Griff, der UI, API und Datenbankarbeit verbindet. Ziel ist, dass jede Logzeile für diese Aktion dieselbe ID trägt.
Support sucht in den Logs nach 9f3c2b1f6a7a4c2f und sieht den Ablauf:
frontend INFO cid=9f3c2b1f6a7a4c2f event="checkout_submit" cart=3 items
api INFO cid=9f3c2b1f6a7a4c2f method=POST path=/api/checkout user=1842
api ERROR cid=9f3c2b1f6a7a4c2f msg="payment failed" provider=stripe status=502
Von dort folgt ein Ingenieur derselben ID in den nächsten Hop. Wichtig ist, dass Backend-Service-Aufrufe (und Queue-Jobs) die ID ebenfalls weitergeben.
payments INFO cid=9f3c2b1f6a7a4c2f action="charge" amount=49.00 currency=USD
payments ERROR cid=9f3c2b1f6a7a4c2f err="timeout" upstream=stripe timeout_ms=3000
db INFO cid=9f3c2b1f6a7a4c2f query="insert into failed_payments" rows=1
Jetzt ist das Problem konkret: der Payments-Service ist nach 3 Sekunden getimed-out und ein Fehlerdatensatz wurde geschrieben. Der Engineer kann letzte Deploys prüfen, bestätigen, ob Timeout-Einstellungen geändert wurden, und nachsehen, ob Retries stattfinden.
Um die Schleife zu schließen, führen Sie vier Checks durch:
- Beheben Sie die Ursache (z. B. Timeout anpassen und einen sicheren Retry hinzufügen).
- Stellen Sie sicher, dass nutzerseitige Fehler die Correlation ID anzeigen.
- Achten Sie auf neue Logs mit demselben Fehlerbild, aber unterschiedlichen IDs.
- Bestätigen Sie, dass die ID jeden Hop überlebt (inklusive Worker und Queue-Nachrichten).
Häufige Fehler und wie man sie vermeidet
Der schnellste Weg, Correlation IDs nutzlos zu machen, ist, die Kette zu unterbrechen. Die meisten Fehler entstehen durch kleine Entscheidungen, die beim Aufbau harmlos wirken, beim Support aber problematisch werden.
Ein klassischer Fehler ist, an jeder Stelle eine neue ID zu generieren. Wenn der Browser eine ID sendet, sollte Ihr API-Gateway sie behalten, nicht ersetzen. Wenn Sie wirklich eine interne ID brauchen (für eine Queue-Nachricht oder einen Hintergrundjob), bewahren Sie das Original als Parent-Feld, damit die Geschichte weiterhin verbunden ist.
Eine weitere Lücke ist unvollständiges Logging. Teams fügen die ID im ersten API hinzu, vergessen sie aber in Worker-Prozessen, geplanten Jobs oder in der Datenbankzugriffsschicht. Das Ergebnis ist eine Sackgasse: Sie sehen, wie die Anfrage ins System kommt, aber nicht, wohin sie danach ging.
Vermeiden Sie das "Naming-Chaos"
Selbst wenn die ID überall existiert, kann das Suchen schwerfallen, wenn jeder Service einen anderen Feldnamen oder ein anderes Format nutzt. Wählen Sie einen Namen und bleiben Sie dabei (z. B. correlation_id) über Frontend, APIs und Logs hinweg. Wählen Sie auch ein Format (oft eine UUID) und behandeln Sie es als case-sensitiv, damit Copy-Paste zuverlässig ist.
Verlieren Sie die ID nicht, wenn etwas schiefgeht. Wenn eine API 500 oder eine Validierungsfehler zurückgibt, fügen Sie die Correlation ID in die Fehlerantwort (und idealerweise in einen Response-Header) ein. So kann ein Nutzer sie in den Support-Chat einfügen und Ihr Team kann sofort den gesamten Pfad nachverfolgen.
Ein schneller Test: Kann eine Support-Person mit einer ID beginnen und ihr durch jede beteiligte Logzeile folgen, einschließlich Fehlern?
Schnell-Checkliste, um End-to-End-Abdeckung zu verifizieren
Erstellen Sie eine einfache Support-Konsole
Erstellen Sie einen internen Bildschirm, um Vorfälle in Sekunden per Correlation ID zu durchsuchen.
Nutzen Sie das als Sanity-Check, bevor Sie dem Support sagen: „Sucht einfach die Logs." Das funktioniert nur, wenn jeder Hop denselben Regeln folgt.
Muss-bestanden-Checks
- Sie haben ein ID-Format und einen Header-Namen, die überall verwendet werden (Frontend, Gateway, APIs, Worker).
- Das Frontend erzeugt (oder empfängt) die ID zu Beginn einer Benutzeraktion und behält sie stabil, bis die Aktion endet.
- Ihr API-Entry-Point erzeugt eine ID, wenn sie fehlt, und gibt sie immer in Response-Headern zurück.
- Jeder Backend-Service enthält
correlation_id in request-bezogenen Logs als strukturiertes Feld.
- On-Call kann eine ID in die Log-Suche einfügen und in Minuten den gesamten Pfad sehen: Edge-Request, Auth, Service-Calls, DB-Operation und Retries.
Wenn ein Check fehlschlägt, so beheben Sie ihn
Wählen Sie die kleinste Änderung, die die Kette intakt hält.
- Falls IDs mittendrin wechseln, vermeiden Sie das Erzeugen neuer IDs in internen Services. Behalten Sie die originale
correlation_id und fügen Sie bei Bedarf ein separates span_id hinzu.
- Falls Logs das Feld vermissen, fügen Sie Logging-Middleware hinzu, damit Ingenieure es nicht manuell in jeden Logeintrag schreiben müssen.
- Falls Support die ID nicht erhält, sorgen Sie dafür, dass die UI sie auf Fehlerbildschirmen anzeigt und dass das Gateway sie in jeder Antwort zurückspielt.
Ein schneller Test, der Lücken aufdeckt: Öffnen Sie DevTools, lösen Sie eine Aktion aus, kopieren Sie die Correlation ID aus der ersten Anfrage und bestätigen Sie, dass Sie denselben Wert in jeder zugehörigen API-Anfrage und in jeder entsprechenden Logzeile sehen.
Nächste Schritte: In den Build-Prozess einbetten
Correlation IDs helfen nur, wenn alle sie auf dieselbe Weise, jedes Mal, nutzen. Behandeln Sie das Verhalten zu Correlation IDs wie einen erforderlichen Bestandteil des Shippings, nicht als nettes Logging-Upgrade.
Fügen Sie einen kleinen Traceability-Check in Ihre Definition of Done für jeden neuen Endpoint oder jede neue UI-Aktion ein. Decken Sie ab, wie die ID erstellt (oder wiederverwendet) wird, wo sie während des Flows lebt, welcher Header sie trägt und was jeder Service tut, wenn der Header fehlt.
Eine leichte Checkliste reicht meist aus:
- Frontend: erzeugen oder wiederverwenden einer ID pro Benutzeraktion und anhängen an jede API-Aufruf dieser Aktion.
- API-Entry-Point: Header akzeptieren, validieren oder generieren und dann in der Antwort zurückgeben.
- Backend: an Downstream-Services und Jobs weitergeben und in Logs aufnehmen.
- Logging: denselben Feldnamen verwenden (z. B.
correlation_id) über Apps und Services hinweg.
- Reviews: PRs ablehnen, die Endpunkte hinzufügen ohne Tests, die beweisen, dass die ID in Logs erscheint.
Der Support braucht außerdem ein einfaches Script, damit das Debuggen schnell und wiederholbar ist. Entscheiden Sie, wo die ID für Nutzer sichtbar ist (z. B. ein "Copy debug ID"-Button in Fehlerdialogen), und schreiben Sie auf, wonach der Support fragen soll und wo zu suchen ist.
Bevor Sie sich in Produktion darauf verlassen, führen Sie einen gestagten Flow durch, der echtes Nutzungsverhalten nachbildet: klicken Sie einen Button, lösen Sie einen Validierungsfehler aus und schließen Sie dann die Aktion ab. Bestätigen Sie, dass Sie derselben ID vom Browser-Request über API-Logs in jeden Hintergrund-Worker und bis zu den Datenbank-Call-Logs folgen können, falls Sie diese aufzeichnen.
Wenn Sie Apps auf Koder.ai bauen, hilft es, Ihre Correlation ID-Header- und Logging-Konventionen in Planning Mode zu schreiben, damit generierte React-Frontends und Go-Services von Haus aus konsistent starten.