23 يونيو 2025·4 دقيقة
فصل التخزين عن الحوسبة في Snowflake: الأداء والنظام البيئي
تعرف كيف شهّرت Snowflake بفصل التخزين عن الحوسبة، كيف غيّر ذلك معايير التحجيم والتكلفة، ولماذا يهمّ النظام البيئي بقدر السرعة.
تعرف كيف شهّرت Snowflake بفصل التخزين عن الحوسبة، كيف غيّر ذلك معايير التحجيم والتكلفة، ولماذا يهمّ النظام البيئي بقدر السرعة.
ساهمت Snowflake في شيوع فكرة بسيطة لكن ذات أثر واسع في مستودعات البيانات السحابية: فصل تخزين البيانات عن حوسبة الاستعلام. هذا الفصل يغيّر نقطتين مؤلمتين يوميتين لفرق البيانات — كيف تتوسع المستودعات وكيف تدفع مقابلها.
بدلاً من التعامل مع المستودع كـ "صندوق" واحد ثابت (حيث المزيد من المستخدمين، المزيد من البيانات، أو استعلامات أكثر تعقيداً تتصارع على نفس الموارد)، يتيح نموذج Snowflake تخزين البيانات مرة واحدة وتشغيل كمية الحوسبة المناسبة عند الحاجة. النتيجة غالباً هي وقت إجابة أسرع، أقل اختناقات أثناء فترات الذروة، وتحكم أوضح في ما يدفع نقوداً (ومتى).
يشرح هذا المنشور، بلغة مبسطة، ماذا يعني فعلاً فصل التخزين عن الحوسبة — وكيف يؤثر ذلك على:
سنشير أيضاً إلى أماكن لا يحل فيها النموذج كل شيء سحرياً — لأن بعض مفاجآت التكلفة والأداء تنبع من تصميم أحمال العمل، لا من المنصة نفسها.
منصة سريعة ليست القصة الكاملة. للعديد من الفرق، يعتمد وقت تحقيق القيمة على ما إذا كان بإمكانك ربط المستودع بسهولة بالأدوات التي تستخدمها بالفعل — خطوط ETL/ELT، لوحات BI، أدوات الفهرسة/الحوكمة، ضوابط الأمان، ومصادر بيانات الشركاء.
يمكن أن يقصّر نظام Snowflake البيئي (بما في ذلك أنماط مشاركة البيانات وتوزيع شبيه بالسوق) مهل التنفيذ ويقلِّل الحاجة لهندسة مخصّصة. يغطي هذا المنشور كيف يبدو "عمق النظام البيئي" على أرض الواقع، وكيف تقيمه لمؤسستك.
هذا الدليل موجه إلى قادة البيانات، المحللين، وصانعي القرار غير المتخصّصين — أي شخص يحتاج إلى فهم المزايا والمساومات وراء معماريّة Snowflake، التحجيم، التكلفة، وخيارات التكامل دون الغرق في مصطلحات البائع.
بنيت مستودعات البيانات التقليدية على فرضية بسيطة: تشتري (أو تستأجر) كمية ثابتة من العتاد، ثم تشغّل كل شيء على نفس الصندوق أو العنقود. نجح ذلك عندما كانت الأحمال قابلة للتنبؤ والنمو تدريجياً — لكنّه خلق حدوداً هيكلية عندما تسارعت أحجام البيانات وعدد المستخدمين.
في النظم المحلية (والنشر السحابي المبكّر "رفع ونقل")، كان الشكل عادةً كالتالي:
حتى عندما قدّم البائعون "عقدات"، ظل النمط الأساسي كما هو: التوسعة عادةً تعني إضافة عقد أكبر أو أكثر إلى بيئة مشتركة.
يصنع هذا التصميم بعض الصعوبات الشائعة:
لأن هذه المستودعات كانت مرتبطة ارتباطاً وثيقاً ببيئاتها، نمت التكاملات غالباً بشكل عضوي: سكربتات ETL مخصّصة، موصلات مبنية يدويّاً، وخطوط أنابيب لمرة واحدة. كانت تعمل — حتى يتغير مخطط، أو ينتقل نظام مصدّر، أو يُدخل أداة جديدة. أصبح الحفاظ على التشغيل شعوراً بالصيانة المتواصلة بدلاً من التقدّم المستقر.
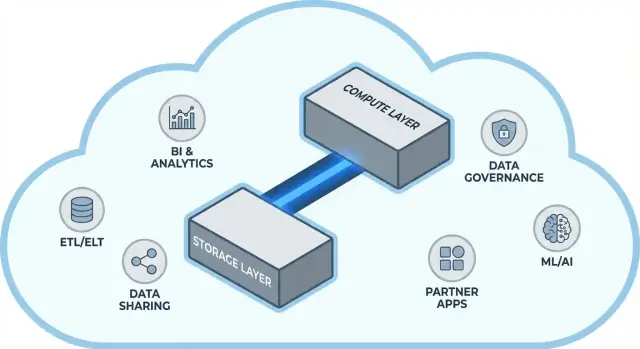
غالباً ما تربط مستودعات البيانات التقليدية وظيفتين مختلفتين جداً: التخزين (مكان وجود بياناتك) والحوسبة (القدرة التي تقرأ، تربط، تجمع، وتكتب تلك البيانات).
التخزين يشبه مخزن البقالة طويل الأمد: الجداول، الملفات، والميتاداتا محفوظة بأمان وبشكل اقتصادي، مصممة لتكون دائمة ومتاحة دائماً.
الحوسبة تشبه طاقم المطبخ: مجموعة المعالجات والذاكرة التي "تطهو" استعلاماتك — تشغّل SQL، تفرز، تمسح، تبني النتائج، وتتعامل مع مستخدمين متعددين في آن واحد.
تفصل Snowflake هذين الأمرين حتى تستطيع تعديل كل منهما دون إجبار الآخر على التغيير.
عملياً، يغيّر هذا العمليات اليومية: لم تعد مضطراً لـ "شراء حوسبة زائدة" لأن التخزين ينمو، ويمكنك عزل أحمال العمل (مثلاً المحللون مقابل مهام ETL) حتى لا تبطئ بعضها البعض.
هذا الفصل قوي، لكنه ليس سحرياً.
القيمة تكمن في التحكم: دفع مقابل التخزين والحوسبة بشروطهما الخاصة، ومطابقة كل منهما مع ما تحتاجه الفرق فعلاً.
أسهل طريقة لفهم Snowflake أنها ثلاث طبقات تعمل معاً، لكن يمكنها أن تتوسع بشكل مستقل.
جداولك في النهاية تُخزّن كملفات بيانات في تخزين كائنات مزود السحابة (مثل S3، Azure Blob، أو GCS). Snowflake يدير صيغ الملفات، الضغط، والتنظيم نيابةً عنك. لا تقوم "بتوصيل أقراص" أو تحديد أحجام وحدات تخزين — ينمو التخزين مع نمو البيانات.
الحوسبة تأتي على شكل مخازن افتراضية: عناقيد مستقلة من CPU/الذاكرة تنفّذ الاستعلامات. يمكنك تشغيل مخازن متعددة مقابل نفس البيانات في الوقت نفسه. هذه هي الفارق الرئيسي عن الأنظمة القديمة التي تميل فيها الأحمال الثقيلة إلى التقاتل على نفس مجموعة الموارد.
طبقة خدمات منفصلة تتعامل مع "عقل" النظام: المصادقة، تجزئة الاستعلام وتحسينه، إدارة المعاملات/الميتاداتا، والتنسيق. تقرّر هذه الطبقة كيف تُنفّذ الاستعلام بكفاءة قبل أن تلمس الحوسبة البيانات.
عند إرسال SQL، تحلل طبقة الخدمات الاستعلام، تبني خطة تنفيذ، ثم تسلّم الخطة إلى مخزن افتراضي مختار. يقرأ المخزن الملفات الضرورية فقط من تخزين الكائنات (ويستفيد من التخزين المخبأ عند الإمكان)، يعالجها، ويُرجع النتائج — دون نقل بياناتك الأساسية إلى المخزن بشكل دائم.
إذا شغّل عدة أشخاص استعلامات في نفس الوقت، يمكنك إما:
هذا هو الأساس المعماري لأداء Snowflake والتحكُّم في مشكلة "الجيران المزعجين" (noisy neighbor).
التحوّل العملي الكبير لدى Snowflake هو أنك تتحجّم الحوسبة بشكل مستقل عن البيانات. بدلاً من القول "المستودع يكبر"، تحصل على قدرة لضبط الموارد لكل حمل عمل دون نسخ الجداول أو إعادة تقسيم الأقراص أو جدول زمن للتوقف.
في Snowflake، "المخزن الافتراضي" هو محرك الحوسبة الذي يشغّل الاستعلامات. يمكنك تغيير حجمه (مثلاً من Small إلى Large) في ثوانٍ، وتبقى البيانات في مكانها في التخزين المشترك. هذا يجعل ضبط الأداء غالباً سؤالاً بسيطاً: "هل هذا الحمل يحتاج قوة أكبر الآن؟"
يتيح هذا أيضاً دفعات مؤقتة: ارفع الحجم لغلق نهاية الشهر، ثم أعده عندما تنتهي الذروة.
غالباً ما تضطر الأنظمة التقليدية إلى مشاركة نفس الحوسبة بين فرق مختلفة، ما يحول ساعات الذروة إلى طابور عند الكاشير.
يمكّنك Snowflake من تشغيل مخازن منفصلة لكل فريق أو حمل عمل — على سبيل المثال، واحد للمحللين، واحد للوحات المعلومات، وواحد لـ ETL. بما أن هذه المخازن تقرأ نفس البيانات الأساسية، تقل مشكلة "لوحاتي أبطأت تقريرك" وتصبح الأداء أكثر توقعاً.
الحوسبة المرنة ليست نجاحاً تلقائياً. الأخطاء الشائعة تشمل:
التغيير الصافي: الانتقال من مشاريع بنية تحتية إلى قرارات تشغيل يومية بشأن التحجيم والتزامن.
وعد Snowflake "ادفع مقابل ما تستخدمه" هو في الأساس عدّادان يعملان بالتوازي:
من هذا الفصل تأتي التوفيرات المحتملة: يمكنك الاحتفاظ بكمية كبيرة من البيانات بتكلفة معقولة مع تشغيل الحوسبة فقط عند الحاجة.
معظم الإنفاق "غير المتوقع" ينبع من سلوك الحوسبة لا من حجم التخزين. المحركات الشائعة تشمل:
فصل التخزين عن الحوسبة لا يجعل الاستعلامات فعّالة تلقائياً — SQL السيئ لا يزال يحرق الاعتمادات بسرعة.
لا تحتاج إلى قسم مالي لإدارة ذلك — فقط بعض الضوابط البسيطة:
باستخدام جيد، يكافئ النموذج الانضباط: حوسبة قصيرة المدة ومناسبة الحجم مع نمو تخزين متوقع.
تعامل Snowflake مع المشاركة كشيء تُصمّمه داخل المنصة — لا كحَلّ يلتحم لاحقاً على شكل تصديرات أو إسقاطات ملفات أو مهام ETL لمرة واحدة.
بدلاً من إرسال مقتطفات حول العالم، يمكن لـ Snowflake أن يسمح لحساب آخر باستعلام نفس البيانات الأساسية عبر "مشاركة" آمنة. في كثير من السيناريوهات، لا تحتاج البيانات إلى التكرار في مستودع ثانٍ أو دفعها إلى تخزين الكائنات للتنزيل. يرى المستهلك قاعدة البيانات/الجدول المشترك كما لو كان محلياً، بينما يبقى المزود متحكماً بما يكشف عنه.
هذا النهج "المفصول" له قيمة لأنه يقلل من انتشار البيانات، يسرّع الوصول، ويخفض عدد خطوط الأنابيب التي تحتاج إلى بنائها وصيانتها.
مشاركة مع الشركاء والعملاء: يمكن للبائع نشر مجموعات بيانات مُنقّحة للعملاء (مثل تحليلات الاستخدام أو بيانات مرجعية) بحدود واضحة — فقط المخططات والجداول/العروض المصرح بها.
مشاركة داخلية بحسب المجال: يمكن للفرق المركزية أن تعرض مجموعات بيانات معتمدة للمنتج والمالية والعمليات دون جعل كل فريق يبني نسخاً خاصة به. يدعم ذلك ثقافة "مجموعة أرقام واحدة" مع السماح للفرق بتشغيل حوسبتها الخاصة.
التعاون المُدار: يمكن للمشاريع المشتركة (مثل مع وكالة، مورد، أو شركة فرعية) العمل على مجموعة بيانات مشتركة مع إخفاء أعمدة حسّاسة وتسجيل الدخول.
المشاركة ليست "ضبط وانسِ". ما زلت بحاجة إلى:
Snowflake يخزن بياناتك في تخزين كائنات السحابة ويشغّل الاستعلامات على مجموعات حوسبة منفصلة تسمى "المخازن الافتراضية" (virtual warehouses). ونظراً لفصل التخزين عن الحوسبة، يمكنك تكبير/تصغير الحوسبة أو إضافة مخازن دون نقل أو تكرار البيانات الأساسية.
يقلل Snowflake التنافس على الموارد. يمكنك عزل أحمال العمل بوضعها على مخازن افتراضية مختلفة (مثل BI مقابل ETL)، أو استخدام مخازن متعددة-عنقودية لزيادة الحوسبة عند الذروة. هذا يساعد على تجنّب طابور الانتظار الناتج عن وجود "عنقود مشترك واحد" كما في أنظمة MPP التقليدية.
لا يحدث ذلك تلقائياً. الحوسبة المرنة تمنحك تحكّماً، لكن لا بدّ من وجود ضوابط:
استعلامات SQL سيئة أو تحديثات لوحات التحكم المستمرة أو مخازن مُشغَّلة دائماً لا تزال قادرة على رفع التكاليف.
عادةً ما يُفصل الفاتورة إلى عنصرين رئيسيين:
بهذا يصبح واضحاً ما الذي يكلفك الآن (الحوسبة) وما الذي ينمو تدريجياً (التخزين).
المسبّبات الشائعة للمفاجآت في الإنفاق عادةً عملية وليس حجم بيانات:
بعض الضوابط العملية (الإيقاف التلقائي، مراقبات الموارد، الجداول الزمنية) توفر وفورات ملموسة.
هو التأخير الناتج عن استئناف مخزن كان مُعلَّقاً. إذا كانت أحمال العمل نادرة، فإن الإيقاف التلقائي يوفر تكلفة لكنه قد يضيف تأخيراً صغيراً في أول استعلام بعد فترة خمول. لواجهات المستخدم الحسّاسة، فكّر في مخزن مخصّص بحجم ملائم بدل الدورات المتكررة من الإيقاف/الاستئناف.
المخزن الافتراضي هو عنقود حوسبة مستقل ينفّذ SQL. الممارسات الجيدة تشمل تخصيص المخازن حسب الجمهور/الغرض، مثلاً:
هذا يعزل الأداء ويُسهِّل تخصيص تكلفة الملكية.
غالباً نعم. تمكّنك الميزة الأمنية للمشاركة في Snowflake من السماح لحساب آخر باستعلام البيانات التي تكشف عنها (جداول/عروض) دون تصدير ملفات أو بناء خطوط أنابيب إضافية. مع ذلك تحتاج لحوكمة قوية—تحديد ملكية، مراجعات وصول، وسياسات للحقول الحسّاسة—كي تبقى المشاركة مسيطرة وقابلة للتدقيق.
لأن وقت التسليم غالباً ما يهيمن عليه أعمال التكامل والتشغيل وليس سرعة الاستعلام فقط. نظام بيئي قوي يقلّل العمل المُخصّص عبر:
ذلك يُسرّع مواعيد التنفيذ ويخفض عبء الصيانة بعد الإطلاق.
نفّذ تجربة صغيرة وواقعية (عادةً 2–4 أسابيع):
إذا أردت مساعدة في تقدير الإنفاق، ابدأ من /pricing، ولإرشادات الهجرة والحوكمة تصفّح /blog.